Trong mỗi bước huấn luyện, mô hình Skip-Gram chỉ nhận một từ đầu vào nhưng có nhiều đầu ra cho một từ đầu vào. Các thử nghiệm thực tế cho thấy mô hình Skip-Gram hoạt động tốt hơn đối với những từ ít gặp, còn mô hình CBoW lại hoạt động tốt hơn đối với những từ phổ biến.
2.2.3. Mô hình BERT
2.2.3.1. Giới thiệu
Mô hình BERT [102] là mô hình biểu diễn mã hóa hai chiều dựa trên Transformer, được thiết kế cho lớp bài toán biểu diễn ngôn ngữ trong NLP của Google. Mô hình BERT được phát triển để huấn luyện các véc tơ biểu diễn văn bản thông qua ngữ cảnh 2 chiều. Véc tơ biểu diễn sinh ra từ mô hình BERT được kết hợp với các lớp bổ sung đã tạo ra các mô hình hiệu quả cho các nhiệm vụ trong xử lý ngôn ngữ tự nhiên như: Đưa điểm đánh giá hiểu ngôn ngữ chung (GLUE - General Language Understanding Evaluation) đạt 80,5% (tăng 7,7%), bộ dữ liệu hỏi đáp SQuAD v2.0 (SQuAD - Stanford Question Answering Dataset) với điểm F1 (F1 - score) đạt 83,1% (tăng 5,1%),...v...v... Mô hình BERT khắc phục được các nhược điểm của các phương pháp trước đây bằng cách tạo các biểu diễn theo ngữ cảnh dựa trên các từ phía trước và phía sau để tạo ra một mô hình ngôn ngữ với ngữ nghĩa phong phú hơn.
Mô hình BERT được huấn luyện trước trên một kho ngữ liệu văn bản lớn không gán nhãn là sự kết hợp của BooksCorpus (800 triệu từ) [103] và Wikipedia tiếng Anh (2.500 triệu từ), tổng cộng ~16GB văn bản không nén và được tinh chỉnh bằng cách sử dụng dữ liệu được gán nhãn của các nhiệm vụ phía sau.
2.2.3.2. Kiến trúc BERT
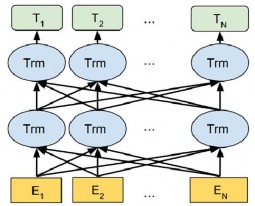
Hình 2.17. Kiến trúc mô hình BERT [102]
BERT sử dụng Transformer [97] được biểu diễn trong Hình 2.17 (với: Ei là biểu diễn các mã hóa từ (word embedding), Trm là các véc tơ biểu diễn trung gian cho mỗi từ tại mỗi tầng Transformer tương ứng, Ti là véc tơ biểu diễn cho mỗi từ đầu ra cuối cùng). Trong kiến trúc của BERT, L là số lớp Transformer, H là kích thước của
lớp ẩn và A là số đầu ở lớp chú ý (heads attention). Có 2 kích thước mô hình BERT là:
- BERTBASE (L = 12, H = 768, A = 12, với 110 triệu tham số (110M)).
- BERTLARGE (L = 24, H = 1.024, A = 16, với 340 triệu tham số (340M)).
Mỗi lớp thực hiện tính toán multi-head attention trên biểu diễn từ của lớp trước để tạo ra một biểu diễn trung gian mới. Tất cả các biểu diễn trung gian này có cùng kích thước.
2.2.3.3. Biểu diễn đầu vào
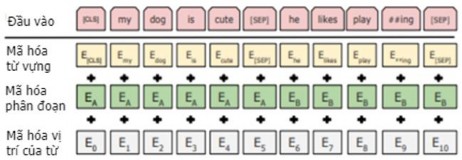
Hình 2.18. Biểu diễn đầu vào của mô hình BERT [102]
Đầu vào (Input): Có thể là một câu hoặc một cặp 2 câu ghép nối thành một chuỗi các từ (token). Hai câu này được biểu diễn là một chuỗi đầu vào duy nhất với các token đặc biệt được thêm vào để phân biệt chúng như sau:
CLS, x1, x2 ,..., xM ,SEP, y1, y2 ,..., xN ,EOS
trong đó: x1, x2,…, xN; y1, y2,..., yM là 2 câu có M từ và N từ tương ứng; CLS, SEP là các token được thêm vào đầu câu, cuối câu thứ nhất tương ứng; EOS là token thêm vào kết thúc chuỗi và thỏa mãn điều kiện M + N < T (với T là độ dài lớn nhất của chuỗi (512 token)). Một ví dụ minh họa biểu diễn đầu vào của BERT như trong Hình 2.18 ở trên.
Mã hóa từ vựng (Token Embeddings): Vai trò của lớp này là chuyển đổi các từ thành véc tơ biểu diễn có kích thước cố định là 768 chiều.
Mã hóa phân đoạn (Segment Embeddings): BERT có thể lấy các cặp câu làm đầu vào cho các tác vụ nên nó học các mã hóa khác nhau cho câu thứ nhất và câu thứ hai để mô hình phân biệt chúng. Ví dụ: các tokens đánh dấu “EA” thuộc về câu A và tương tự “EB” thuộc về câu B.
Mã hóa vị trí của từ (Position Embeddings): BERT học và sử dụng mã hóa vị
trí để chỉ ra vị trí của các từ trong câu. Mã hóa vị trí (position embedding) được thêm vào để khắc phục hạn chế của Transformer.
Với mỗi từ, véc tơ biểu diễn đầu vào được tính bằng tổng của 3 thành phần: mã hóa từ, mã hóa loại câu và mã hóa vị trí của từ trong câu tương ứng.
BERT sử dụng các mã hóa từ WordPiece [104] với bộ từ vựng có 30.000 từ và sử dụng ký hiệu “##” làm dấu phân tách để lấy từ gốc (ví dụ: từ “playing” được phân tách thành “play” và “##ing”).
2.2.3.4. Biểu diễn đầu ra
Với mỗi từ thứ i ( i 1, N ) của chuỗi đầu vào, đầu ra là véc tơ Ti biểu diễn cho từ đầu vào tương ứng.
2.2.3.5. BERT được huấn luyện trước
BERT được huấn luyện trước (pre-trained BERT) với 2 nhiệm vụ dự đoán không giám sát là: Mô hình dự đoán từ bị che (Masked LM - Masked Language Model) và dự đoán câu tiếp theo (NSP - Next Sentence Prediction). Khi huấn luyện mô hình BERT, Masked LM và NSP được huấn luyện cùng nhau để giảm thiểu giá trị hàm lỗi.
Mô hình dự đoán từ bị che (Masked LM): Một tập các token ngẫu nhiên trong chuỗi đầu vào được thay thế bằng token đặc biệt gọi là token bị che [MASK]. Nhiệm vụ của Masked LM là dự đoán các token bị che dựa trên ngữ cảnh của các từ không bị che trong chuỗi. BERT chọn 15% token trong mỗi chuỗi đầu vào để thay thế bằng token [MASK], 80% các tokens đã chọn này được thay thế bằng [MASK], 10% giữ nguyên và 10% được thay thế bằng các token trong từ vựng. Dự đoán các từ đầu ra yêu cầu:
- Thêm một lớp phân loại trên đầu ra của bộ mã hóa.
- Nhân các véc tơ đầu ra với ma trận mã hóa, chuyển chúng thành kích thước từ vựng.
- Tính xác suất của mỗi từ trong từ vựng với hàm softmax.
Dự đoán câu tiếp theo (NSP): Nhiệm vụ này sẽ tạo ra hai nhãn “Position” và “Negative”. Mô hình nhận các cặp câu làm đầu vào và học cách dự đoán nếu câu thứ hai trong cặp là câu tiếp theo trong văn bản nguồn thì nhãn “Position” được tạo ra. Nhãn “Negative” được tạo ra nếu câu thứ hai là một câu ngẫu nhiên từ kho ngữ liệu văn bản.
Ví dụ: Giả sử cần huấn luyện trước mô hình BERT sử dụng kho ngữ liệu văn bản có 100.000 câu. Như vậy, ta có 50.000 mẫu huấn luyện (mỗi mẫu là cặp 2 câu) làm dữ liệu huấn luyện.
- Với 50% cặp câu này, câu thứ 2 là câu tiếp theo của câu thứ nhất trong văn bản, các nhãn được tạo ra là “Position”.
- Với 50% cặp câu còn lại, câu thứ 2 là một câu ngẫu nhiên từ bộ dữ liệu, các nhãn này ký hiệu là “Negative”.
2.2.3.6. Tinh chỉnh BERT
Tùy thuộc vào hiệm vụ phía sau của các bài toán, BERT sẽ được tinh chỉnh (fine-tuning) với các bộ dữ liệu huấn luyện của các nhiệm vụ phía sau để tạo ra mô hình ngữ nghĩa phù hợp hơn cho các nhiệm vụ đó. Mô hình sử dụng hai chiến lược tinh chỉnh:
(i) Đóng băng một vài lớp trước đó để đóng băng các trọng số đã học được từ mô hình được huấn luyện trước (chỉ cập nhật trọng số ở một số lớp cao hơn) để tăng tốc độ huấn luyện của mô hình;
(ii) Giảm tỉ lệ học (learning rate) để tăng độ chính xác cho mô hình.
2.2.4. Các phiên bản chủ yếu của mô hình BERT
2.2.4.1. Mô hình BERT đã ngôn ngữ
Các mô hình pre-trained BERT [102] đã công bố chỉ hỗ trợ cho các nhiệm vụ xử lý đơn ngôn ngữ tiếng Anh trong xử lý ngôn ngữ tự nhiên. Dựa trên các mô hình pre-trained BERT, các mô hình BERT đa ngôn ngữ (mBERT - BERT multilingual)
[105] tương ứng đã được phát triển trong đó có tiếng Việt. Kiến trúc của các mô hình mBERT dựa trên kiến trúc của các mô hình pre-trained BERT tương ứng. Có hai mô hình mBERT dựa trên các mô hình BERT-Base là BERT-Base, Multilingual Cased (104 ngôn ngữ, 12 lớp, 768 chiều, 12 đầu attention, 110 triệu tham số) và BERT-Base, Multilingual Uncased (102 ngôn ngữ, 12 lớp, 768 chiều, 12 đầu attention, 110 triệu tham số). Các mô hình mBERT được huấn luyện trên trang Wikipedia gồm 104 ngôn ngữ với bộ từ vựng tương ứng thay vì chỉ được huấn luyện trên bộ dữ liệu đơn ngữ tiếng Anh với bộ từ vựng tiếng Anh tương ứng như các mô hình BERT.
2.2.4.2. Mô hình RoBERTa
Liu và cộng sự [106] đã đề xuất các mô hình tối ưu của mô hình pre-trained BERT [102] tương ứng là RoBERTa (Robustly optimized BERT approach) và đạt được kết quả tốt hơn mô hình pre-trained BERT đã công bố. Mô hình RoBERTa có kiến trúc giống mô hình pre-trained BERT tương ứng. Những điểm thay đổi chủ yếu của mô hình RoBERTa được tóm tắt như sau: RoBERTa được huấn luyện trên
nhiều dữ liệu hơn so với pre-trained BERT (tổng cộng 160GB văn bản là sự kết hợp của các bộ dữ liệu: BOOKCORPUS [103] plus English WIKIPEDIA, CC-NEWS1, OPENWEBTEXT2, STORIES [107], thời gian huấn luyện mô hình lâu hơn với
500.000 bước. Phương pháp huấn luyện RoBERTa cũng được thay đổi so với mô hình BERT là loại bỏ nhiệm vụ dự đoán câu tiếp theo (NSP - Next Sentence Prediction) nên không bị mất mát NSP, RoBERTa được huấn luyện sử dụng cơ chế che động (Dynamic Masking) nên các từ bị che (masked token) sẽ được sinh ra khi câu được đưa vào mô hình (mô hình BERT sử dụng cơ chế che tĩnh (Static Masking)), mô hình RoBERTa được huấn luyện với kích thước lô dữ liệu (batch size) lớn hơn giúp chống nhiễu tốt hơn trong quá trình huấn luyện, và sử dụng thuật toán BPE mức byte (byte-level BPE) lớn hơn [108]. Độ dài tối đa của véc tơ câu sau khi mã hóa là 512. Mô hình RoBERTa được huấn luyện theo kiến trúc của mô hình BERTLARGE (L = 24; H = 1024; A = 16; 355 triệu tham số). Mô hình được tối ưu với bộ tối ưu Adam [109].
2.2.4.3. Mô hình PhoBERT
PhoBERT [110] là mô hình tối ưu của mô hình BERT được huấn luyện trước dành riêng cho tiếng Việt, đã đạt được hiệu quả cao trong các nhiệm vụ xử lý ngôn ngữ tiếng Việt. Tóm tắt những điểm thay đổi chính của PhoBERT như sau: PhoBERT được phát triển với hai phiên bản PhoBERTBASE và PhoBERTLARGE, sử
1 https: //commoncrawl.org/2016/10/newsdataset-available
2 https://Skylion007.github.io/OpenWebTextCorpus
dụng các kiến trúc giống như các kiến trúc của mô hình BERTBASE và BERTLARGE tương ứng. Phương pháp huấn luyện trước của PhoBERT dựa trên mô hình RoBERTa để tối ưu phương pháp huấn luyện trước BERT. PhoBERT được huấn luyện trước trên bộ dữ liệu gồm 20GB văn bản không nén sau khi làm sạch (bộ dữ liệu này là sự kết hợp của hai kho văn bản là kho văn bản Wikipedia tiếng Việt (~1Gb) và kho văn bản (~19Gb) của kho tin tức tiếng Việt 40Gb sau khi lọc các tin tức trùng lặp3). Đối với mô hình PhoBERT, bộ dữ liệu huấn luyện trước được xử lý tách từ trước khi mã hóa bằng thuật toán BPE [108] (do tiếng Việt có từ ghép mà BPE không nhận biết được). Độ dài tối đa của véc tơ câu sau khi mã hóa là 256 nhỏ hơn so với mô hình RoBERTa. Mô hình cũng được tối ưu với bộ tối ưu Adam
[109].
2.2.4.4. Các mô hình BERT thu nhỏ
Các mô hình BERT thu nhỏ [111] là các mô hình BERT có kích thước nhỏ hơn, thời gian xử lý tính toán nhanh hơn, tốn ít bộ nhớ hơn và hiệu quả đạt được xấp xỉ các mô hình pre-trained BERT được phát triển để đáp ứng các yêu cầu ràng buộc về tài nguyên. Dựa trên các mô hình pre-trained BERT [102], các mô hình BERT thu nhỏ được phát triển theo mô hình “mạng dạy” - “mạng học” (“teacher” – “student”), trong đó mạng học là mô hình BERT thu nhỏ (BERT “học”) được huấn luyện trước để tái tạo lại hành vi và nhận chuyển giao tri thức từ mạng dạy lớn hơn (BERT “dạy”) là các mô hình BERTBASE, BERTLARGE được tinh chỉnh trên dữ liệu được gán nhãn của nhiệm vụ cụ thể thông qua kỹ thuật chưng cất tri thức (KD - Knowledge Distillation) [112,113]. Các mô hình BERT thu nhỏ được huấn luyện qua ba bước: Huấn luyện trước trên dữ liệu mô hình ngôn ngữ không gán nhãn để nắm bắt các đặc trưng ngôn ngữ từ kho ngữ liệu văn bản lớn; chưng cất trên dữ liệu chuyển giao không gán nhãn để tận dụng tối đa tri thức và được huấn luyện trên các nhãn mềm (phân phối dự đoán) được sinh bởi BERT “dạy”; tinh chỉnh trên dữ liệu được gán nhãn của tác vụ cụ thể nếu cần để xử lý vấn đề không tương thích giữa tập dữ liệu chuyển giao và tập dữ liệu gán nhãn của tác vụ cụ thể (Hình 2.19). Có 24 mô hình BERT thu nhỏ đã được phát triển như BERT-Tiny (với 2 lớp, 128 chiều, 4 triệu tham số), BERT-Mini (với 4 lớp, 256 chiều, 11 triệu tham số), BERT-Small (với 4 lớp, 512 chiều, 29 triệu tham số), BERT-Medium (với 8 lớp, 512 chiều, 41 triệu tham số), BERT-Base (với 12 lớp, 768 chiều, 110 triệu tham số),...v...v....
3 https://github.com/binhvq/news-corpus

Hình 2.19. Mô hình biểu diễn các bước chưng cất được huấn luyện trước của các mô hình BERT thu nhỏ [111]
2.3. Kỹ thuật học tăng cường Q-Learning
2.3.1. Học tăng cường Q-Learning
Học tăng cường (RL - Reinforcement Learning) [114] là một kỹ thuật học máy mà một tác tử học bằng cách tương tác với môi trường xung quanh để tối đa hóa điểm thưởng nhận được. Các yếu tố chính trong học tăng cường bao gồm: Tác tử tương tác với môi trường bằng các hành động. Sau mỗi hành động, môi trường trả lại cho tác tử một trạng thái và điểm thưởng tương ứng với trạng thái đó. Một chuỗi các trạng thái và hành động từ trạng thái bắt đầu đến trạng thái kết thúc được gọi là một tập (episode). Trong một tập, tác tử sẽ chọn ra các hành động tối ưu để tối đa hóa điểm thưởng nhận được sau mỗi tập. Cách mà tác tử chọn những hành động đó gọi là chiến lược và mục đích là tìm ra chiến lược tốt nhất. Hình 2.20 dưới đây mô tả tương tác giữa tác tử - môi trường.
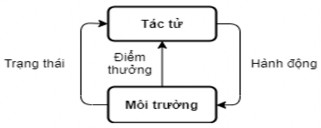
Hình 2.20. Mô hình học tăng cường
Tác tử sẽ thực thi một chuỗi hành động mà tạo ra tổng điểm thưởng lớn nhất dựa trên điểm thưởng mong muốn của mỗi hành động ở mỗi bước. Tổng điểm thưởng này còn được gọi là giá trị Q (Q-value), được tính theo công thức sau:
Q(s, a) r(s, a) max Q(s ', a)
a
(2.38)
trong đó: Q(s,a) là Q-value khi thực hiện hành động a tại trạng thái s, r(s,a) là điểm thưởng nhận được, s' là trạng thái kế tiếp, γ là hệ số tiêu hao (discount factor) kiểm soát sự đóng góp của điểm thưởng để đảm bảo càng "xa" đích thì Q-value càng nhỏ. Công thức (2.38) tạo ra một ma trận trạng thái - hành động được xem như một bảng tra cứu Q (Q-table). Với mỗi cặp trạng thái - hành động tác tử chỉ cần tìm hành động có Q-value lớn nhất bằng việc tra cứu bảng Q-table. Tuy nhiên, học tăng cường là một tiến trình ngẫu nhiên nên Q-value ở thời điểm (t-1) và thời điểm t sau
khi thực hiện hành động là khác nhau và giá trị này được tính theo công thức:
TD(a, s) r(s, a) max Q(s ', a ') Qt 1(s, a)
a '
với: a' là hành động kế tiếp, α là hệ số học.
(2.39)
Tại thời điểm t, ma trận Q(s,a) cần phải cập nhật trọng số dựa trên giá trị
TD(a,s) như sau:
Qt (s, a) Qt 1(s, a) TDt (a, s)
(2.40)
Quá trình này được gọi là học Q (Q-Learning) và thuật toán Q-Learning [114] học tất cả các giá trị Q(s,a) của môi trường bằng việc thử và cập nhật để xây dựng Q-table.
2.3.2. Thuật toán học tăng cường Deep Q-Learning
Thuật toán Q-Learning có nhược điểm là yêu cầu số lượng trạng thái xác định để kích thước bảng Q-table không quá lớn để có thể dự đoán được. Để giải quyết vấn đề này, kỹ thuật học tăng cường Deep Q-Learning [114] sử dụng mạng nơ ron (đầu vào là trạng thái, đầu ra là Q-value của tất cả các hành động) thay thế bảng Q- table để ước lượng các giá trị Q-value với từng cặp trạng thái - hành động. Deep Q- Learning khắc phục vấn đề qúa khớp (overfitting) của mạng nơ ron sử dụng kỹ thuật kinh nghiệm phát lại (Experience Replay) được mô tả như sau: Hệ thống sẽ lưu lại các trạng thái vào bộ nhớ thay vì mỗi trạng thái mạng cập nhật một lần, sau đó thực hiện lấy mẫu thành các lô (batch) và đưa vào mạng nơ ron.
Thuật toán học tăng cường Deep Q-Learning với kỹ thuật kinh nghiệm phát lại
[114] được tóm tắt sau đây.
Đầu vào: Các trạng thái s; Đầu ra: Các Q-value của các hành động tương ứng; Thuật toán: 1: Tác tử chọn hành động bằng một chiến lược và thực hiện hành động đó; 2: Môi trường trả lại trạng thái s' và điểm thưởng r là kết quả của hành động a và lưu bộ kinh nghiệm (experience) (s, a, r, s') vào bộ nhớ; 3: Thực hiện lấy mẫu các experience thành các lô (batch) và huấn luyện mạng nơ ron; 4: Lặp lại đến khi kết thúc M tập (episode); 5: Return; |
Có thể bạn quan tâm!
-
 Các Phương Pháp Tóm Tắt Văn Bản Hướng Trích Rút Cơ Sở
Các Phương Pháp Tóm Tắt Văn Bản Hướng Trích Rút Cơ Sở -
![Một Kiến Trúc Cnn Cho Bài Toán Phân Loại Ảnh [84]](https://tailieuthamkhao.com/uploads/2022/06/10/nghien-cuu-phat-trien-mot-so-phuong-phap-tom-tat-van-ban-su-dung-ky-6-1-120x90.jpg) Một Kiến Trúc Cnn Cho Bài Toán Phân Loại Ảnh [84]
Một Kiến Trúc Cnn Cho Bài Toán Phân Loại Ảnh [84] -
 Các Mô Hình Ngôn Ngữ Dựa Trên Học Sâu Được Huấn Luyện Trước
Các Mô Hình Ngôn Ngữ Dựa Trên Học Sâu Được Huấn Luyện Trước -
 Phát Triển Các Phương Pháp Tóm Tắt Đơn Văn Bản Hướng Trích Rút
Phát Triển Các Phương Pháp Tóm Tắt Đơn Văn Bản Hướng Trích Rút -
 Kết Quả Thử Nghiệm Một Số Phương Pháp Tóm Tắt Văn Bản Cơ Sở. Ký Hiệu ‘*’ Thể Hiện Phương Pháp Được Triển Khai Thử Nghiệm Trên Các Bộ
Kết Quả Thử Nghiệm Một Số Phương Pháp Tóm Tắt Văn Bản Cơ Sở. Ký Hiệu ‘*’ Thể Hiện Phương Pháp Được Triển Khai Thử Nghiệm Trên Các Bộ -
 Các Kết Quả Thử Nghiệm Của Các Mô Hình Xây Dựng
Các Kết Quả Thử Nghiệm Của Các Mô Hình Xây Dựng
Xem toàn bộ 185 trang tài liệu này.
2.4. Tìm kiếm Beam
Trong mô hình seq2seq, ở giai đoạn giải mã, bộ giải mã sẽ nhận đầu vào là kết quả được sinh ra tại bước trước đó (với bước đầu tiên, bộ giải mã nhận đầu vào là kết quả được sinh ra từ bộ mã hóa) để sinh ra bản tóm tắt mới. Trong bài toán tóm tắt văn bản, thông thường việc lựa chọn chuỗi đầu ra được thực hiện bởi các thuật toán tìm kiếm và quá trình này có thể sử dụng thuật toán tìm kiếm Beam [115] để tìm kiếm một chuỗi đầu ra tốt hơn.
Ý tưởng của thuật toán tìm kiếm Beam được tóm tắt như sau: Tại mỗi bước giải mã, thay vì chỉ lựa chọn từ có phân bố xác suất cao nhất thì chúng ta lựa chọn k từ (k gọi là kích thước tìm kiếm (beam_size)) có phân bố xác suất cao nhất để làm đầu vào cho bước giải mã tiếp theo. Quá trình này được lặp lại cho đến khi gặp ký hiệu kết thúc chuỗi. Khi đó, bản tóm tắt có trung bình xác suất cao nhất sẽ được chọn làm bản tóm tắt đầu ra cuối cùng. Ý tưởng của thuật toán tìm kiếm Beam [115] được tóm tắt sau đây.
Đầu vào: Độ rộng (Beam_size) k, phân bố xác suất; Đầu ra: Chuỗi đã được giải mã S = (y1, y2,..., yi,...yT); Thuật toán: 1: Chọn k từ có phân bố xác suất lớn nhất để tạo thành k chuỗi; 2: Lặp với mỗi chuỗi thực hiện: - Chọn từ có phân bố xác suất lớn nhất; - Đưa từ này vào chuỗi đang xét hiện tại; cho đến khi gặp điều kiện dừng (số lượng từ > số lượng từ giới hạn trước hoặc gặp ký hiệu kết thúc chuỗi); 3: Thu được k chuỗi (với mỗi chuỗi có xác suất được tính bằng tích các xác suất của các từ trong chuỗi); 4: Chọn chuỗi có xác suất đã tính được lớn nhất; 5: Return; |
Ví dụ: Khi chọn kích thước tìm kiếm beam_size = 3 thì tại mỗi bước giải mã, thuật toán sẽ giữ lại 3 từ có phân bố xác suất cao nhất, rồi lấy từng từ làm đầu vào cho bước giải mã tiếp theo. Quá trình được lặp lại cho đến khi gặp dấu kết thúc chuỗi. Lúc đó, chuỗi có trung bình xác suất cao nhất sẽ được chọn.
2.5. Phương pháp độ liên quan cận biên tối đa
Phương pháp độ liên quan cận biên tối đa (MMR - Maximal Marginal Relevance) [116] cho bài toán tóm tắt văn bản là hướng tiếp cận tập trung vào việc xác định chủ đề chính của văn bản (hoặc tập văn bản), từ đó dựa trên chủ đề chính để tìm ra những câu có liên quan. Phương pháp MMR loại bỏ các thông tin dư thừa dựa trên độ tương đồng của các câu trong tập ứng cử viên với các câu đã được chọn vào bản tóm tắt. Phương pháp MMR ban đầu được đề xuất cho bài toán tìm kiếm