thông tin (IR - Information Retrieval) để đo lường mức độ tương đồng giữa truy vấn người dùng Q và các câu trong văn bản. MMR được tính theo công thức:
MMR arg max Sim D ,Q1max Sim
D , D
(2.41)
D C S 1 i
D S
2 i j
Có thể bạn quan tâm!
-
![Một Kiến Trúc Cnn Cho Bài Toán Phân Loại Ảnh [84]](https://tailieuthamkhao.com/uploads/2022/06/10/nghien-cuu-phat-trien-mot-so-phuong-phap-tom-tat-van-ban-su-dung-ky-6-1-120x90.jpg)
![Một Kiến Trúc Cnn Cho Bài Toán Phân Loại Ảnh [84]](data:image/svg+xml,%3Csvg%20xmlns=%22http://www.w3.org/2000/svg%22%20viewBox=%220%200%2075%2075%22%3E%3C/svg%3E) Một Kiến Trúc Cnn Cho Bài Toán Phân Loại Ảnh [84]
Một Kiến Trúc Cnn Cho Bài Toán Phân Loại Ảnh [84] -
 Các Mô Hình Ngôn Ngữ Dựa Trên Học Sâu Được Huấn Luyện Trước
Các Mô Hình Ngôn Ngữ Dựa Trên Học Sâu Được Huấn Luyện Trước -
![Mô Hình Biểu Diễn Các Bước Chưng Cất Được Huấn Luyện Trước Của Các Mô Hình Bert Thu Nhỏ [111]](https://tailieuthamkhao.com/uploads/2022/06/10/nghien-cuu-phat-trien-mot-so-phuong-phap-tom-tat-van-ban-su-dung-ky-8-1-120x90.jpg) Mô Hình Biểu Diễn Các Bước Chưng Cất Được Huấn Luyện Trước Của Các Mô Hình Bert Thu Nhỏ [111]
Mô Hình Biểu Diễn Các Bước Chưng Cất Được Huấn Luyện Trước Của Các Mô Hình Bert Thu Nhỏ [111] -
 Kết Quả Thử Nghiệm Một Số Phương Pháp Tóm Tắt Văn Bản Cơ Sở. Ký Hiệu ‘*’ Thể Hiện Phương Pháp Được Triển Khai Thử Nghiệm Trên Các Bộ
Kết Quả Thử Nghiệm Một Số Phương Pháp Tóm Tắt Văn Bản Cơ Sở. Ký Hiệu ‘*’ Thể Hiện Phương Pháp Được Triển Khai Thử Nghiệm Trên Các Bộ -
 Các Kết Quả Thử Nghiệm Của Các Mô Hình Xây Dựng
Các Kết Quả Thử Nghiệm Của Các Mô Hình Xây Dựng -
 Giá Trị Các Siêu Tham Số Và Thời Gian Huấn Luyện Các Mô Hình Xây Dựng
Giá Trị Các Siêu Tham Số Và Thời Gian Huấn Luyện Các Mô Hình Xây Dựng
Xem toàn bộ 185 trang tài liệu này.
trong đó:
i
j
- C là tập các văn bản (các câu) cho trước.
- S là tập các văn bản (các câu) đã chọn.
- Q là câu truy vấn của người dùng.
- Sim1 là độ tương đồng giữa câu đang xét Di và câu truy vấn Q.
- Sim2 là độ tương đồng giữa câu đang xét Di với mỗi câu đã được chọn Dj trong tập S (Sim2 có thể bằng Sim1).
- λ là một tham số tự chọn (λ [0; 1]). Tham số λ được điều chỉnh theo yêu cầu của từng bài toán, nếu bản tóm tắt yêu cầu các thông tin xung quanh câu truy vấn thì
λ được điều chỉnh với giá trị nhỏ hơn, và ngược lại nếu bản tóm tắt muốn tập trung vào sự đa dạng từ các văn bản thì λ được điều chỉnh với giá trị lớn hơn.
MMR có giá trị càng lớn có nghĩa là câu đang xét vừa có liên quan đến truy vấn vừa có độ tương đồng càng nhỏ so với các câu đã chọn trước đó.
Phương pháp MMR áp dụng cho bài toán tóm tắt văn bản: Để áp dụng phương pháp MMR cho nhiệm vụ tóm tắt văn bản, độ đo MMR được định nghĩa lại theo công thức sau:
MMR arg max .Sim s , D1 max Sim
s , s
(2.42)
trong đó:
1 i
si DS
s j S
2 i j
- D là văn bản đầu vào chứa tập các câu ứng viên cho bản tóm tắt.
- S là tập các câu đã được chọn đưa vào bản tóm tắt.
- si là câu đang xét, sj là mỗi câu đã được đưa vào bản tóm tắt S.
- λ là tham số tự chọn (λ [0; 1]).
- Sim1, Sim2 là độ tương đồng giữa hai câu u và v, được tính theo công thức:
tf tf idf 2
wu
tf
w ,u w
idf
2
Sim1 u, vSim2
u, v
wv w ,u w ,v w
(2.43)
với: tfw,u là tần suất xuất hiện của từ w trong câu u, idfw là độ quan trọng của từ w.
Mục đích của việc áp dụng phương pháp MMR là để loại bỏ thông tin dư thừa trong bản tóm tắt. Để thực hiện được điều này, cần thực hiện ba bước sau:
- Bước 1: Xác định chủ đề chính của các văn bản đầu vào.
- Bước 2: Tìm các câu có liên quan đến các chủ đề chính.
- Bước 3: Loại bỏ những câu dư thừa là những câu có độ tương đồng với các câu hiện có trong bản tóm tắt lớn hơn một giá trị ngưỡng nhất định.
Phương pháp MMR đề xuất: Trong công thức (2.42), đại lượng Sim1(si,D) biểu diễn độ tương đồng giữa câu đang xét si với văn bản D hay nói cách khác Sim1(si,D) biểu diễn độ quan trọng của câu si nên khi thay đại lượng Sim1(si,D) bằng xác suất được chọn của câu đã cho kết quả tốt hơn trong thực nghiệm nên phương pháp MMR đề xuất được định nghĩa lại theo công thức:
MMR arg max . probability
1max Sim
s , s
(2.44)
siDS
i s j S
2 i j
với:
probabilityi
là xác suất được chọn của câu si, λ là tham số tự chọn (λ [0; 1]).
Ngoài ra, các giá trị này đều thuộc khoảng [0; 1] nên việc tính toán MMR cũng hiệu quả hơn nên phương pháp MMR này được sử dụng để lựa chọn câu đưa vào bản tóm tắt.
2.6. Kết luận chương 2
Trong chương này, luận án đã trình bày một số kiến thức nền tảng liên quan đến đề tài nghiên cứu như sau:
- Các kỹ thuật học sâu cơ sở được sử dụng để phát triển các mô hình tóm tắt văn bản hiệu quả. Các kỹ thuật này cho thấy khả năng và thế mạnh của các mô hình học sâu sử dụng trong bài toán tóm tắt văn bản.
- Các mô hình ngôn ngữ dựa trên học sâu được huấn luyện trước như phương pháp word2vec, mô hình BERT và các phiên bản của mô hình BERT.
- Các kỹ thuật học tăng cường Deep Q-Learning, tìm kiếm Beam, phương pháp MMR loại bỏ thông tin trùng lặp trong bản tóm tắt. Các phương pháp này được sử dụng trong các giai đoạn huấn luyện mô hình, sinh bản tóm tắt và đánh giá chất lượng của bản tóm tắt của các phương pháp tóm tắt văn bản được đề xuất.
Các kiến thức nền tảng liên quan trong chương 2 được trình bày trong các công trình nghiên cứu đã công bố của luận án. Các kiến thức trình bày trong chương này là cơ sở nền tảng để luận án đề xuất và phát triển các nghiên cứu trong các chương tiếp theo. Trong chương 3, luận án sẽ nghiên cứu và đề xuất phát triển các mô hình tóm tắt đơn văn bản hướng trích rút áp dụng cho tóm tắt văn bản tiếng Anh và tiếng Việt.
Chương 3. PHÁT TRIỂN CÁC PHƯƠNG PHÁP TÓM TẮT ĐƠN VĂN BẢN HƯỚNG TRÍCH RÚT
Trong chương này, luận án đề xuất phát triển ba mô hình tóm tắt đơn văn bản hướng trích rút sử dụng các mô hình học sâu BERT – mô hình biểu diễn ngôn ngữ huấn luyện trước được sử dụng để sinh các véc tơ biểu diễn cho các câu của văn bản cần tóm tắt. Luận án đề xuất kết hợp mô hình BERT với mô hình phân loại sử dụng mạng nơ ron như MLP, CNN, mô hình seq2seq kết hợp với các đặc trưng của văn bản để dự đoán các câu quan trọng hoặc không quan trọng dựa trên xác suất được chọn của câu. Các câu đầu ra của mô hình phân loại tiếp tục được đánh giá, loại bỏ trùng lặp sử dụng các đặc trưng của văn bản và phương pháp MMR để lựa chọn câu đưa vào bản tóm tắt. Hai mô hình được xây dựng dựa trên các ý tưởng trên được đặt tên là RoPhoBERT_MLP_ESDS và mBERT_CNN_ESDS. Bên cạnh hai mô hình trên, luận án đề xuất một phương pháp kết hợp kỹ thuật học tăng cường Deep Q- Learning vào mô hình tóm tắt văn bản sử dụng kỹ thuật học sâu để tối ưu hàm mục tiêu trong quá trình huấn luyện. Mô hình này có tên là mBERT- Tiny_seq2seq_DeepQL_ESDS. Ba mô hình tóm tắt đề xuất được thử nghiệm trên các bộ dữ liệu CNN/Daily Mail cho tóm tắt văn bản tiếng Anh và Baomoi cho tóm tắt văn bản tiếng Việt.
3.1. Giới thiệu bài toán và hướng tiếp cận
Tóm tắt đơn văn bản hướng trích rút tạo bản tóm tắt bằng cách trích xuất ra những câu quan trọng, mang đầy đủ thông tin của văn bản nguồn. Bản tóm tắt cần ngắn gọn, cô đọng và cung cấp các thông tin phù hợp nhất, giúp con người nắm bắt được nội dung của văn bản mà không cần phải đọc nó.
Bài toán tóm tắt đơn văn bản hướng trích rút được phát biểu như sau: Cho một
văn bản D được biểu diễn là
D (s1, s2 ,..., si ,...., sN ) , trong đó i 1, N , si
là câu thứ
i trong văn bản, N là số câu của văn bản (hay độ dài của văn bản). Nhiệm vụ của bài
toán tóm tắt đơn văn bản hướng trích rút là tạo ra một bản tóm tắt S o gồm M câu
S o (so , so ,..., so ,...., so ) , trong đó: so D,i 1,M
biểu diễn nội dung chính của
1 2 i M i
văn bản (M < N).
Luận án tiếp cận theo hướng xem bài toán tóm tắt đơn văn bản hướng trích rút
như bài toán phân loại văn bản. Với mỗi câu
si D , sẽ dự đoán nhãn
yi {0,1}
với: nhãn “1” biểu diễn câu
s S o
( si thuộc văn bản tóm tắt đầu ra), nhãn “0” biểu
i
diễn câu s S o . Gọi p( y | s , D,) là xác suất chọn nhãn y với điều kiện đầu vào
i i i i
si D và là tập tham số của mô hình cần xây dựng. Mô hình được huấn luyện để
ước lượng xác suất
p( yi | si , D,)
thỏa mãn điều kiện nếu câu si
có độ tương quan
với văn bản D lớn hơn độ tương quan của câu sj
với văn bản D thì
p(1| si , D,) p(1| s j , D,) . Mô hình sử dụng để ước lượng xác suất p( yi | si , D,)
này được xây dựng dựa trên mạng nơ ron nhân tạo. Sau đó, bản tóm tắt
S o (so , so ,..., so ,...., so ) được tạo ra bằng việc chọn tập gồm M câu có điểm MMR
1 2 i M
cao nhất được tính toán dựa trên xác suất
p(1| si , D,) .
Mục tiêu đặt ra là xây dựng và huấn luyện mô hình để tìm sao cho xác suất
p(1| si , D,)
lớn nhất với
s S o . Điều này tương đương với việc tối thiểu hóa
i
hàm mất mát cross - entropy sau:
N
L() log p( yi | si , D,)
i1
(3.1)
Các nghiên cứu gần đây thường sử dụng các kỹ thuật học sâu để phát triển các mô hình giải quyết vấn đề này nhằm xây dựng các hệ thống tóm tắt văn bản có độ chính xác cao. Tuy nhiên, vấn đề biểu diễn văn bản đầu vào là một yếu tố quan trọng quyết định hiệu quả của các mô hình tóm tắt văn bản.
Trong các mô hình biểu diễn văn bản, BERT là mô hình hiệu quả nhất do nó dựa trên mô hình học thông tin 2 chiều và cơ chế chú ý của Transformer. Các mô hình BERT huấn luyện trước (pre-trained BERT) [102] được huấn luyện với các tập ngữ liệu lớn của ngôn ngữ, cho phép học ra được mô hình ngôn ngữ một cách chính xác nhất. Trên cơ sở đó, các ứng dụng xử lý ngôn ngữ dựa trên học sâu không cần phải huấn luyện lại với bộ ngữ liệu lớn nữa mà có thể tận dụng mô hình BERT huấn luyện trước để đưa ra biểu diễn giàu thông tin nhất của văn bản đầu vào. Các mô hình tóm tắt văn bản dựa trên học sâu khi sử dụng BERT để biểu diễn văn bản đầu vào đều đem lại hiệu quả cao như [117,118,119]. Vì lý do đó, BERT cũng được sử dụng trong các mô hình đề xuất để véc tơ hóa văn bản.
Một vấn đề đặt ra với các mô hình tóm tắt trích rút là việc trùng lặp câu trong bản tóm tắt. Lý do là khi một câu được xác định là quan trọng thì câu có nội dung tương tự với nó cũng là câu quan trọng. Vì vậy, mô hình cần có cơ chế loại bỏ câu trùng lặp. Phương pháp MMR được sử dụng để loại bỏ thông tin trùng lặp và lựa chọn câu đưa vào bản tóm tắt.
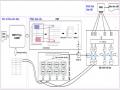
Do đó, luận án đề xuất khung xử lý chung cho các mô hình tóm tắt đơn văn bản hướng trích rút bao gồm các mô đun sau:

Hình 3.1. Khung xử lý chung cho các mô hình tóm tắt đơn văn bản hướng trích rút đề xuất
Trong chương này, luận án sẽ phát triển ba mô hình phân loại dựa trên các kỹ thuật học sâu khác nhau, để từ đó phát triển ba mô hình tóm tắt đơn văn bản hướng trích rút tương ứng. Các mô hình đó được trình bày chi tiết trong các phần dưới đây.
3.2. Mô hình tóm tắt đơn văn bản hướng trích rút RoPhoBERT_MLP_ESDS
3.2.1. Giới thiệu mô hình
Các cách tiếp cận học máy và học sâu thường quy bài toán tóm tắt đơn văn bản hướng trích rút về bài toán phân loại câu với câu có nhãn 1 là câu được đưa vào bản tóm tắt và 0 nếu ngược lại. Vì vậy, việc xác định tập đặc trưng của câu trong bài toán này đóng vai trò quan trọng. Các cách tiếp cận học sâu giải quyết bài toán này bằng cách véc tơ hóa các câu của văn bản đầu vào dựa trên một mô hình ngôn ngữ đã được huấn luyện trước nào đó; sau đó sử dụng các mô hình học sâu phù hợp để trích ra được các đặc trưng câu. Một mô hình ngôn ngữ được huấn luyện trước trên tập ngữ liệu lớn các văn bản trên một ngôn ngữ cho phép hiểu được ngữ nghĩa của từ và biểu diễn từ trong không gian véc tơ ngữ nghĩa của ngôn ngữ đó. Hai mô hình ngôn ngữ sử dụng phổ biến hiện nay là word2vec và BERT. Nhược điểm của các mô hình huấn luyện dựa trên word2vec là có thể sinh ra véc tơ biểu diễn ngữ nghĩa cho một từ đầu vào mà không phụ thuộc đến ngữ cảnh xuất hiện từ đó. Vì một từ khi xuất hiện trong ngữ cảnh khác nhau có thể có nghĩa khác nhau nên cách tiếp cận trên có thể đưa ra cách biểu diễn từ không chính xác, dẫn đến ảnh hưởng đến kết quả tóm tắt của hệ thống. Trong khi đó, mô hình BERT không sinh ra véc tơ ngữ nghĩa của một từ đứng độc lập mà chỉ sinh ra véc tơ ngữ nghĩa của câu, dựa trên việc học mối liên hệ hai chiều giữa các từ trong câu đó. Vì vậy, véc tơ ngữ nghĩa của câu được sinh ra bởi mô hình BERT sẽ có độ tin cậy cao hơn so với khi sử dụng word2vec. Trong các ứng dụng về xử lý ngôn ngữ tự nhiên, việc sử dụng BERT thường đem lại kết quả vượt trội so với các cách tiếp cận khác. Vì vậy luận án sử dụng các mô hình tối ưu của BERT để biểu diễn câu đầu vào trong các mô hình tóm tắt văn bản bao gồm mô hình RoBERTa [106] cho tiếng Anh và mô hình PhoBERT
[110] cho tiếng Việt.
Với mô hình tóm tắt văn bản, véc tơ đặc trưng của các câu đầu vào này cần đi qua một bộ phân loại để xác định các câu quan trọng. Phương pháp SVM và MLP là các phương pháp phân loại dựa trên học máy đạt hiệu quả cao. Do MLP thường được sử dụng với đầu vào là véc tơ có kích thước lớn, khá phù hợp với đầu vào là véc tơ đặc trưng câu nói trên nên mô hình đề xuất sử dụng MLP trong bài toán này. Một vấn đề có thể xảy ra với kết quả đầu ra của bộ phân loại trên là nhiều câu có nội dung gần tương đồng đều có độ quan trong cao, dẫn đến trùng lặp nội dung trong bản tóm tắt. Để giải quyết vấn đề đó, luận án sử dụng phương pháp MMR để loại bỏ các thông tin trùng lặp đó. Bản tóm tắt được sinh ra dựa trên các câu quan trọng đã loại bỏ trùng lặp, được sắp xếp theo vị trí xuất hiện câu trong văn bản gốc. Dựa trên ý tưởng đó, luận án đề xuất mô hình tóm tắt văn bản được trình bày trong phần 3.2.2 dưới đây.
3.2.2. Mô hình tóm tắt văn bản đề xuất
Mô hình tóm tắt văn bản đề xuất gồm 3 mô đun chính: Véc tơ hóa văn bản, phân loại câu và sinh văn bản tóm tắt. Mô hình đề xuất được biểu diễn chi tiết trong Hình 3.2 dưới đây.
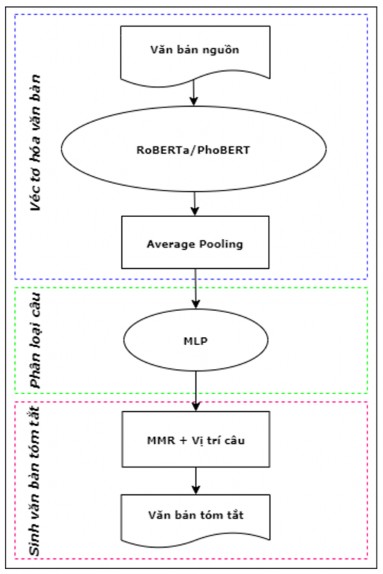
Hình 3.2. Mô hình tóm tắt đơn văn bản hướng trích rút RoPhoBERT_MLP_ESDS
3.2.2.1. Véc tơ hóa văn bản
Mô đun thực hiện mã hóa các câu của văn bản đầu vào sử dụng các mô hình tối ưu của mô hình pre-trained BERT, đó là mô hình RoBERTa [106] đối với tiếng Anh, mô hình PhoBERT [110] đối với tiếng Việt. Trước hết, mô đun xử lý tách câu của văn bản đầu vào và gán nhãn cho các câu. Tập các câu này được xử lý bằng công cụ tokenizer của mô hình RoBERTa (tiếng Anh), PhoBERT (tiếng Việt) để tạo ra các véc tơ chỉ mục (index vector) của các từ (token) của câu. Sau đó, các véc tơ chỉ mục này được đưa vào mô hình RoBERTa (tiếng Anh), PhoBERT (tiếng Việt) để thu được các véc tơ từ (token embedding) của các câu tương ứng. Cuối cùng, các véc tơ từ của mỗi câu (đối với cả 2 bộ dữ liệu) được xử lý bởi phép toán Average Pooling để sinh ra 1 véc tơ mã hóa câu tương ứng cho mỗi câu đầu vào, được sử dụng làm đầu vào cho mô hình phân loại sử dụng mạng MLP của mô đun huấn luyện.
Với tiếng Anh, mô hình đề xuất sử dụng mô hình RoBERTaBASE được kế thừa từ kho lưu trữ của thư viện Transformers4, độ dài véc tơ câu được lấy tối đa là 256 từ hay véc tơ câu có 256 chiều (nếu câu có độ dài < 256 sẽ được xử lý đệm thêm
cho đủ độ dài bằng 256), kích thước lô dữ liệu (batch size) là 256. Trong quá trình huấn luyện, mô hình RoBERTa được đóng băng và chỉ tinh chỉnh bằng cách huấn luyện tiếp trên bộ dữ liệu thử nghiệm CNN.
Với tiếng Việt, mô hình đề xuất sử dụng mô hình PhoBERTBASE được kế thừa từ kho lưu trữ của thư viện PhoBert with Transformers5, độ dài véc tơ câu cũng được lấy tối đa là 256 từ, batch size là 256. Trong quá trình huấn luyện, mô hình
RoBERTa cũng được đóng băng và chỉ tinh chỉnh bằng cách huấn luyện tiếp mô hình trên bộ dữ liệu thử nghiệm Baomoi.
3.2.2.2. Phân loại câu
Mô đun thực hiện tính xác suất của các câu đầu vào được chọn đưa vào bản tóm tắt. Mô hình sử dụng mạng nơ ron MLP được học bởi giải thuật lan truyền ngược [120,121]. Kiến trúc mạng và các tham số tối ưu của mạng MLP của mô hình phân loại được xây dựng dựa vào thực nghiệm (Hình 3.3) bao gồm:
Một lớp vào có 768 chiều không có hàm kích hoạt tại mỗi nơ ron để tương thích với số chiều đầu ra của các mô hình RoBERTa và PhoBERT.
Một lớp ẩn có 256 nơ ron với hàm kích hoạt ReLU tại mỗi nơ ron.
Một lớp ra gồm 2 nơ ron sử dụng hàm kích hoạt softmax để trả ra xác suất được chọn của các câu.
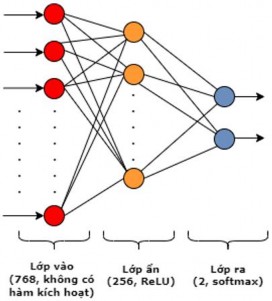
Hình 3.3. Kiến trúc mạng MLP đề xuất của mô hình
Mô hình được huấn luyện bởi thuật toán tối ưu AdamW [122] sử dụng các giá
trị mặc định của các tham số của thuật toán tối ưu đã cài đặt là 1 0,9;
2 0,999
và 108 .
4 https://huggingface.co/transformers
5 https://github.com/VinAIResearch/PhoBERT
3.2.2.3. Sinh văn bản tóm tắt
Trong văn bản tin tức, các câu ở vị trí đầu văn bản thường mang nhiều thông tin quan trọng hơn, các câu càng về cuối thì càng mang ít thông tin. Mô hình đề xuất sử dụng phương pháp MMR được định nghĩa lại cho mô hình này dựa trên các đặc trưng vị trí câu và xác suất được chọn của câu bằng cách thay đại lượng xác suất probabilityi của câu si trong công thức (2.44) ở chương 2 bằng thương của xác suất được chọn của câu chia cho đặc trưng vị trí câu để tận dụng lợi thế của vị trí câu và xác suất được chọn của câu và thử nghiệm đã cho kết quả tốt hơn so với cách lựa chọn theo xác suất của công thức MMR ban đầu. Phương pháp MMR mới đề xuất áp dụng cho mô hình tóm tắt được định nghĩa lại theo công thức sau:
MMR arg max . probability . 11 max Sim
i
s , s
(3.2)
siDS
positioni
s j S
2 i j
với: probabilityi, positioni tương ứng là xác suất được chọn, vị trí câu của câu si và giá trị của tham số λ được chọn bằng 0,5.
Có thể thấy vị trí câu và xác suất được chọn của câu không liên quan đến đại lượng tính toán độ tương đồng để có thể đưa vào cùng một biểu thức tính toán nhưng công thức tính MMR đề xuất này đã cho kết quả tốt hơn so với công thức tính MMR ban đầu trong thực nghiệm. Do đó, mô hình sẽ sử dụng công thức MMR đề xuất này khi lựa chọn câu đưa vào bản tóm tắt.
3.2.3. Thử nghiệm mô hình
3.2.3.1. Dữ liệu thử nghiệm
Mô hình RoPhoBERT_MLP_ESDS đề xuất được thử nghiệm trên bộ dữ liệu CNN đối với tiếng Anh và bộ dữ liệu Baomoi đối với tiếng Việt (chi tiết các bộ dữ liệu này được trình bày trong chương 1).
3.2.3.2. Tiền xử lý dữ liệu
Trước tiên, cả hai bộ dữ liệu CNN và Baomoi được xử lý tách riêng phần tiêu đề, phần tóm tắt, nội dung.
Với bộ dữ liệu CNN, văn bản đầu vào được tách câu sử dụng thư viện Stanford CoreNLP6. Để gán nhãn cho các câu, các câu này được so sánh với bản tóm tắt mẫu dựa vào tối đa tổng độ đo R-2 và R-L (vì thử nghiệm cho kết quả tốt hơn so với tổng độ đo R-1 và R-2) sử dụng thư viện rouge-score 0.0.47. Tiếp theo, tập các câu này được xử lý bằng tokenizer của mô hình pre-trained RoBERTa để tạo ra các véc tơ chỉ mục (index) của các từ (token) của câu, sau đó các véc tơ chỉ mục này được đưa vào mô hình pre-trained RoBERTa để thu được các véc tơ từ (token embeddings) của các câu.
Với bộ dữ liệu Baomoi, mô hình sử dụng thư viện VnCoreNLP8 để tách câu của văn bản đầu vào. Để gán nhãn cho các câu, các câu này cũng được so sánh với bản tóm tắt mẫu dựa vào tối đa tổng độ đo R-2 và R-L sử dụng thư viện rouge-score
0.0.4. Sau đó, tập các câu này được xử lý bằng công cụ tokenizer của mô hình pre-
6 https://stanfordnlp.github.io/CoreNLP
7 https://github.com/google-research/google-research/tree/master/rouge
8 https://github.com/vncorenlp/VnCoreNLP