trained PhoBERT để tạo ra các véc tơ chỉ mục của các token của câu, sau đó các véc tơ chỉ mục này được đưa vào mô hình pre-trained PhoBERT để thu được các véc tơ mã hóa từ của các câu.
Cuối cùng, các véc tơ mã hóa từ của mỗi câu được xử lý sử dụng hàm avgPooling1d của thư viện PyTorch9 để sinh ra một véc tơ câu 768 chiều được sử dụng làm đầu vào cho mô hình phân loại sử dụng mạng MLP.
3.2.3.3. Thiết kế thử nghiệm
a) Thử nghiệm một số phương pháp tóm tắt văn bản cơ bản
Trước hết, luận án thực hiện cài đặt thử nghiệm một số phương pháp tóm tắt văn bản cơ bản trên cả hai bộ dữ liệu CNN và Baomoi để có cơ sở so sánh với mô hình đề xuất. Đây là các phương pháp tóm tắt đơn văn hướng trích rút đã công bố cho kết quả khá tốt. Thư viện rouge-score 0.0.4 được sử dụng để đánh giá hiệu quả của các mô hình tóm tắt. Kết qủa thử nghiệm thu được như ở Bảng 3.1 dưới đây.
CNN | Baomoi | |||||
R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
LexRank* | 22,9 | 6,6 | 17,2 | 38,5 | 17,0 | 28,9 |
TextRank* | 26,0 | 7,3 | 19,2 | 44,7 | 19,2 | 32,9 |
LEAD* | 29,0 | 10,7 | 19,3 | 46,5 | 20,3 | 30,8 |
Có thể bạn quan tâm!
-
 Các Mô Hình Ngôn Ngữ Dựa Trên Học Sâu Được Huấn Luyện Trước
Các Mô Hình Ngôn Ngữ Dựa Trên Học Sâu Được Huấn Luyện Trước -
![Mô Hình Biểu Diễn Các Bước Chưng Cất Được Huấn Luyện Trước Của Các Mô Hình Bert Thu Nhỏ [111]](https://tailieuthamkhao.com/uploads/2022/06/10/nghien-cuu-phat-trien-mot-so-phuong-phap-tom-tat-van-ban-su-dung-ky-8-1-120x90.jpg) Mô Hình Biểu Diễn Các Bước Chưng Cất Được Huấn Luyện Trước Của Các Mô Hình Bert Thu Nhỏ [111]
Mô Hình Biểu Diễn Các Bước Chưng Cất Được Huấn Luyện Trước Của Các Mô Hình Bert Thu Nhỏ [111] -
 Phát Triển Các Phương Pháp Tóm Tắt Đơn Văn Bản Hướng Trích Rút
Phát Triển Các Phương Pháp Tóm Tắt Đơn Văn Bản Hướng Trích Rút -
 Các Kết Quả Thử Nghiệm Của Các Mô Hình Xây Dựng
Các Kết Quả Thử Nghiệm Của Các Mô Hình Xây Dựng -
 Giá Trị Các Siêu Tham Số Và Thời Gian Huấn Luyện Các Mô Hình Xây Dựng
Giá Trị Các Siêu Tham Số Và Thời Gian Huấn Luyện Các Mô Hình Xây Dựng -
![Mô Hình Tóm Tắt Đơn Văn Bản Hướng Tóm Lược Cơ Sở [128]](https://tailieuthamkhao.com/uploads/2022/06/10/nghien-cuu-phat-trien-mot-so-phuong-phap-tom-tat-van-ban-su-dung-ky-13-1-120x90.jpg) Mô Hình Tóm Tắt Đơn Văn Bản Hướng Tóm Lược Cơ Sở [128]
Mô Hình Tóm Tắt Đơn Văn Bản Hướng Tóm Lược Cơ Sở [128]
Xem toàn bộ 185 trang tài liệu này.
Bảng 3.1. Kết quả thử nghiệm một số phương pháp tóm tắt văn bản cơ sở. Ký hiệu ‘*’ thể hiện phương pháp được triển khai thử nghiệm trên các bộ dữ liệu tương ứng
b) Thử nghiệm các mô hình xây dựng
Luận án triển khai xây dựng bốn mô hình tóm tắt sử dụng các mô hình được huấn luyện trước để mã hóa văn bản đầu vào, đó là mô hình mã hóa câu phổ biến (USE - Universal Sentence Encoder) (sử dụng mô hình USE dựa trên kiến trúc Transformer (USE_T) vì mô hình này cho kết quả tốt hơn các mô hình còn lại trong các nghiên cứu [123,124]) và các mô hình tối ưu của mô hình BERT (RoBERTa cho tiếng Anh, PhoBERT cho tiếng Việt). Chi tiết các mô hình xây dựng như sau:
(i) Mô hình 1 (USE_T + MLP): Sử dụng mô hình USE_T kết hợp với mạng MLP để huấn luyện mô hình tính xác suất được chọn của các câu đầu vào để lựa chọn các câu đưa vào bản tóm tắt.
(ii) Mô hình 2 (USE_T + MLP + MMR + Vị trí câu): Mô hình 1 kết hợp với MMR và đặc trưng vị trí câu để lựa chọn câu đưa vào bản tóm tắt.
(iii) Mô hình 3 (RoBERTa/PhoBERT + MLP): Sử dụng mô hình RoBERTa (đối với CNN) và PhoBERT (đối với Baomoi) kết hợp với mạng MLP để huấn luyện mô hình tính xác suất được chọn của các câu đầu vào để lựa chọn các câu đưa vào bản tóm tắt.
(iv) Mô hình 4 (RoBERTa/PhoBERT + MLP + MMR + Vị trí câu): Mô hình 3 kết hợp với MMR và vị trí câu để lựa chọn câu đưa vào bản tóm tắt.
Bốn mô hình này được triển khai thử nghiệm, trong đó mô hình 1 và 2 được thử nghiệm trên bộ dữ liệu CNN (do USE_T không hỗ trợ cho tiếng Việt). Mô hình 3 và 4 được thử nghiệm trên cả hai bộ dữ liệu CNN và Baomoi, để lựa chọn mô hình tốt nhất làm mô hình đề xuất. Thư viện Tensorflow10 được sử dụng để kế thừa mô hình
9 https://github.com/pytorch/pytorch
10 https://www.tensorflow.org/hub/
USE_T, thư viện Transformers để kế thừa mô hình RoBERTa, PhoBert with Transformers để kế thừa mô hình PhoBERT và thư viện PyTorch để xây dựng mô hình phân loại MLP. Mô hình MLP được huấn luyện với hệ số học khởi tạo ban đầu là 2.10-3. Sau mỗi epoch, hệ số học sẽ được tự động giảm 10% sử dụng cơ chế scheduling của thư viện PyTorch cho đến hết epoch cuối cùng. Các mô hình được huấn luyện sử dụng Google Colab với cấu hình máy chủ GPU V100, 25GB RAM được cung cấp bởi Google. Các siêu tham số được cài đặt và thời gian huấn luyện (giờ) của các mô hình được trình bày trong Bảng 3.2 dưới đây.
Epochs | Batch size | Bộ dữ liệu | Thời gian huấn luyện | |
Mô hình 1 (USE_T + MLP) | 6 | 50 | CNN | 6 |
Mô hình 2 (USE_T + MLP + MMR + Vị trí câu) | 6 | 50 | CNN | 6 |
Mô hình 3 (RoBERTa/PhoBERT + MLP) | 6 | 256 | CNN | 8 |
Mô hình 4 (RoBERTa/PhoBERT + MLP + MMR + Vị trí câu) | 6 | 256 | CNN | 8 |
Mô hình 3 (RoBERTa/PhoBERT + MLP) | 7 | 256 | Baomoi | 48 |
Mô hình 4 (RoBERTa/PhoBERT + MLP + MMR + Vị trí câu) | 7 | 256 | Baomoi | 48 |
Bảng 3.2. Giá trị các siêu tham số và thời gian huấn luyện các mô hình xây dựng
Kết quả thử nghiệm của các mô hình được trình bày như trong Bảng 3.3 dưới đây.
CNN | Baomoi | |||||
R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
USE_T + MLP | 28,9 | 10,3 | 19,3 | - | - | - |
USE_T + MLP + MMR + Vị trí câu | 30,1 | 11,5 | 20,1 | - | - | - |
RoBERTa/PhoBERT + MLP | 31,36 | 11,69 | 28,22 | 52,509 | 24,695 | 37,794 |
RoBERTa/PhoBERT + MLP + MMR + Vị trí câu | 32,18 | 12,31 | 28,87 | 52,511 | 24,696 | 37,796 |
Bảng 3.3. Kết quả thử nghiệm của các mô hình xây dựng. Ký hiệu ‘-’ biểu diễn mô hình mà luận án không thử nghiệm trên bộ dữ liệu tương ứng
Với kết quả thử nghiệm của các mô hình, mặc dù mô hình tóm tắt đơn văn bản sử dụng mô hình USE_T và MLP (mô hình 1) chưa xử lý loại bỏ các câu trùng lặp nhưng đã cho kết quả khả quan và tốt hơn các phương pháp tóm tắt cơ bản như LexRank, TextRank trên cùng bộ dữ liệu CNN. Việc kết hợp phương pháp MMR, vị trí câu để loại bỏ các câu trùng lặp của mô hình 2 đã cho kết quả tốt hơn mô hình
1. Mô hình 3 sử dụng mô hình RoBERTa/PhoBERT (tương ứng với các bộ dữ liệu CNN và Baomoi) và MLP, mặc dù chưa xử lý loại bỏ các câu trùng lặp nhưng đã cho kết quả tốt hơn nhiều so với các mô hình 1 và 2, chứng tỏ mô hình tóm tắt sử dụng mô hình RoBERTa/PhoBERT hiệu quả hơn so với mô hình sử dụng mô hình
USE_T trên cùng bộ dữ liệu CNN. Bên cạnh đó, mô hình 3 cũng đã cho kết quả tốt hơn so với các mô hình tóm tắt cơ bản LexRank, TextRank và LEAD đã được cài đặt thử nghiệm trên bộ dữ liệu Baomoi (Bảng 3.1). Mô hình tóm tắt văn bản sử dụng mô hình RoBERTa/PhoBERT, MLP, MMR và đặc trưng vị trí câu (mô hình
4) đã loại bỏ được các thông tin trùng lặp và cho các kết quả tốt hơn rò rệt so với mô hình 3 trên cả 2 bộ dữ liệu CNN ch tiếng Anh và Baomoi cho tiếng Việt.
Các kết quả thử nghiệm cho thấy rằng mô hình 4 cho kết quả tốt nhất trong các mô hình đã thử nghiệm. Các độ đo R-1, R-2 và R-L tương ứng tăng lần lượt là 0,82%; 0,62% và 0,65% trên bộ CNN và 0,002%, 0,001% và 0,002% trên bộ dữ liệu Baomoi so với kết quả của mô hình 3. Trên bộ Baomoi, ta thấy các kết quả thử nghiệm của mô hình 4 chỉ tăng một tỷ lệ nhỏ so với mô hình 3 là do mô hình đã chọn số lượng câu cho bản tóm tắt nhỏ (do đặc điểm của bộ dữ liệu Baomoi nên mô hình chọn số câu cho bản tóm tắt là 2 câu), nhưng dù sao kết quả cũng cho thấy mô hình 4 là mô hình tốt nhất và được chọn làm mô hình tóm tắt đơn văn bản đề xuất.
Bảng 3.4 biểu diễn một mẫu tóm tắt gồm bản tóm tắt tham chiếu của con người và bản tóm tắt đầu ra của mô hình tóm tắt đề xuất RoPhoBERT_MLP_ESDS trên bộ dữ liệu CNN. Văn bản nguồn của mẫu tóm tắt này xem Phụ lục C.1trong phần Phụ lục.
Bản tóm tắt của mô hình RoPhoBERT_MLP_ESDS Lois Lilienstein, co-star of "Sharon, Lois & Bram's Elephant Show" — the Canadian preschool show that ran on Nickelodeon during the early 1990s — has died, aged 78. Her son, David Lilienstein, told CBC News that his mother died in Toronto on Wednesday night from a rare form of cancer first diagnosed last October. "She knew it was happening, she was at peace with it, and she died very peacefully and not in pain," he told the Canadian broadcaster. |
Bảng 3.4. Một mẫu tóm tắt trên bộ dữ liệu CNN
Bảng 3.5 biểu diễn một mẫu tóm tắt gồm bản tóm tắt tham chiếu của con người và bản tóm tắt đầu ra của mô hình tóm tắt đề xuất RoPhoBERT_MLP_ESDS trên bộ dữ liệu Baomoi. Văn bản nguồn của mẫu tóm tắt này xem Phụ lục C.1trong phần Phụ lục.
Bản tóm tắt của mô hình RoPhoBERT_MLP_ESDS Theo thoả thuận tạm thời ký kết hồi tháng 11/2013, Iran đồng ý giảm hoặc đóng băng một số hoạt động hạt nhân trong |
sáu tháng để đổi lại việc phương Tây giảm bớt trừng phạt hiện nay và không áp đặt thêm trừng phạt mới. Đàm phán giữa Iran với Nhóm P 5+1 từ ngày 18-20/2 tại Vienne là nỗ lực của sáu cường quốc trong việc tìm kiếm một thoả thuận toàn diện cuối cùng liên quan tới chương trình hạt nhân gây tranh cãi của Tehran trước thời điểm thoả thuận sơ bộ hết hiệu lực vào tháng Bảy tới.
Bảng 3.5. Một mẫu tóm tắt trên bộ dữ liệu Baomoi
Như vậy, các kết quả thử nghiệm trên hai bộ dữ liệu CNN và Baomoi cho thấy mô hình tóm tắt đơn văn bản hướng trích rút đề xuất RoPhoBERT_MLP_ESDS đã cho kết quả tốt cho tóm tắt văn bản tiếng Anh và tiếng Việt.
3.2.4. Đánh giá và so sánh kết quả
Để đảm bảo tính khách quan, kết quả thử nghiệm của mô hình tóm tắt đơn văn bản đề xuất được so sánh với kết quả thử nghiệm của các phương pháp khác mà luận án đã thực hiện hiện thử nghiệm và các phương pháp hiện đại khác đã công bố trên cùng bộ dữ liệu CNN và Baomoi tương ứng. Kết quả so sánh và đánh giá hiệu quả của các phương pháp được trình bày trong Bảng 3.6.
CNN | Baomoi | |||||
R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
LexRank* | 22,9 | 6,6 | 17,2 | 38,5 | 17,0 | 28,9 |
TextRank* | 26,0 | 7,3 | 19,2 | 44,7 | 19,2 | 32,9 |
LEAD* | 29,0 | 10,7 | 19,3 | 46,5 | 20,3 | 30,8 |
Cheng và Lapata [125] | 28,4 | 10,0 | 25,0 | - | - | - |
LEAD [125] | 29,1 | 11,1 | 25,9 | - | - | - |
REFRESH [125] | 30,4 | 11,7 | 26,9 | - | - | - |
USE_T + MLP* | 28,9 | 10,3 | 19,3 | - | - | - |
USE_T + MLP + MMR + Vị trí câu* | 30,1 | 11,5 | 20,1 | - | - | - |
RoBERTa/PhoBERT+ MLP* | 31,36 | 11,69 | 28,22 | 52,509 | 24,695 | 37,794 |
RoBERTa/PhoBERT + MLP + MMR + Vị trí câu | 32,18 | 12,31 | 28,87 | 52,511 | 24,696 | 37,796 |
Bảng 3.6. So sánh và đánh giá hiệu quả các phương pháp. Ký hiệu ‘*’,‘-’ biểu diễn các phương pháp được thử nghiệm, không được thử nghiệm trên các bộ dữ liệu tương ứng
Kết quả trong Bảng 3.6 cho thấy đặc trưng vị trí câu và xác suất được chọn của câu có vai trò quan trọng trong hệ thống tóm tắt văn bản. Kết quả trong Bảng 3.6 cũng cho thấy mô hình tóm tắt đơn văn bản hướng trích rút đề xuất có kết quả tốt hơn đáng kể so với các phương pháp đã thử nghiệm và các phương pháp hiện đại khác đã công bố trên hai bộ dữ liệu CNN và Baomoi tương ứng. Kết quả này chứng tỏ rằng mô hình tóm tắt đề xuất sử dụng các mô hình tối ưu RoBERTa/PhoBERT của mô hình BERT được huấn luyện trước để mã hóa văn bản đầu vào, MLP, MMR, đặc trưng vị trí câu và xác suất được chọn của câu đã đạt được hiệu quả tốt cho tóm tắt văn bản tiếng Anh và tiếng Việt.
3.3. Mô hình tóm tắt đơn văn bản hướng trích rút mBERT_CNN_ESDS
3.3.1. Giới thiệu mô hình
Các kỹ thuật học dựa trên mạng nơ ron sâu được áp dụng cho các mô hình tóm tắt văn bản hướng trích rút tạo ra các bản tóm tắt chất lượng cao với lượng dữ liệu mẫu lớn. Tuy nhiên, khi lượng dữ liệu mẫu không đủ lớn, các mô hình này đã bộc lộ những hạn chế nhất định ảnh hưởng đến chất lượng của bản tóm tắt đầu ra. Trong phần này, với mục tiêu phát triển một mô hình tóm tắt văn bản duy nhất có thể áp dụng hiệu quả cho cả tóm tắt văn bản tiếng Anh và tiếng Việt, luận án sử dụng cùng một mô hình để véc tơ hóa các câu của văn bản đầu vào một cách tốt nhất cho cả văn bản tiếng Anh và tiếng Việt để tạo điều kiện thuận lợi cho mô hình phân loại chính xác. Mô hình đề xuất tận dụng lợi thế véc tơ hóa từ theo ngữ cảnh của mô hình BERT đa ngôn ngữ (mBERT) [105] được huấn luyện trước để tạo ra các véc tơ từ và kết hợp đặc trưng TF-IDF làm đầu vào cho mô hình phân loại câu gồm mạng nơ ron tích chập, mô hình seq2seq và lớp mạng nơ ron kết nối đầy đủ (FC - Fully Connected). Các kết quả đầu ra của mô hình phân loại câu được xử lý loại bỏ các thông tin dư thừa bằng phương pháp MMR để tạo ra bản tóm tắt cuối cùng. Mô hình đề xuất được thử nghiệm tóm tắt cho văn bản tiếng Anh và tiếng Việt trên hai bộ dữ liệu CNN và Baomoi tương ứng. Các kết quả thử nghiệm cho thấy mô hình đề xuất đạt kết quả tốt hơn so với các phương pháp hiện đại khác được thử nghiệm trên cùng bộ dữ liệu tương ứng.
3.3.2. Mô hình tóm tắt văn bản đề xuất
Mô hình tóm tắt đơn văn bản hướng trích rút đề xuất gồm ba mô đun chính: Véc tơ hóa từ, phân loại câu và sinh bản tóm tắt, được biểu diễn như trong Hình 3.4.
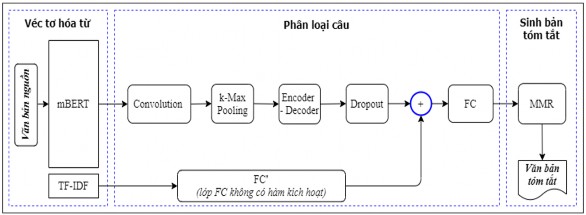
Hình 3.4. Mô hình tóm tắt văn bản hướng trích rút mBERT_CNN_ESDS
3.3.2.1. Véc tơ hóa từ
Trước tiên, mô đun xử lý tách câu của văn bản nguồn đầu vào, xử lý lấy 32 câu đầu tiên của mỗi văn bản để biểu diễn cho văn bản. Mỗi câu được xử lý lấy 64 từ đầu tiên để biểu diễn cho câu (nếu văn bản dài hơn sẽ được cắt bỏ phần sau, còn nếu
ngắn hơn sẽ được đệm thêm). Tập các câu này được xử lý bằng công cụ tokenizer của mô hình pre-trained mBERT sử dụng thư viện Transformers để tạo ra các véc tơ chỉ mục (index) của các từ của câu, sau đó các véc tơ chỉ mục này được đưa vào mô hình mBERT thu được các véc mã hóa từ của các câu (với cả 2 bộ dữ liệu). Mô hình sử dụng mô hình mBERT dựa trên kiến trúc của mô hình BERT-Base, Multilingual Cased tương ứng (L = 12, H = 768, A = 12, 110 triệu tham số) hỗ trợ cho 104 ngôn ngữ, trong đó có ngôn ngữ tiếng Việt. Trong quá trình huấn luyện, mô hình mBERT được đóng băng, không huấn luyện lại từ đầu mà chỉ huấn luyện tiếp mô hình (tinh chỉnh) trên các bộ dữ liệu thử nghiệm CNN và Baomoi tương ứng để có được biểu diễn tốt nhất cho văn bản nguồn đầu vào.
Các véc tơ từ này được sử dụng làm đầu vào cho lớp tích chập (lớp Convolution) của mô đun phân loại câu.
3.3.2.2. Phân loại câu
Mô đun này thực hiện tính xác suất của câu đầu vào được chọn đưa vào bản tóm tắt. Mô hình đề xuất sử dụng mạng CNN, kết hợp mô hình seq2seq (kiến trúc Encoder-Decoder), lớp dropout, lớp FC và kết hợp đặc trưng TF-IDF cho mô hình phân loại câu. Chi tiết mô hình phân loại được trình bày dưới đây.
Lớp Convolution và lớp k-Max Pooling: Do mô hình BERT chỉ trích rút được các đặc trưng của các từ trong một câu đưa vào mà không trích rút được các đặc trưng của cụm các câu liền nhau vì vậy mô hình đề xuất sử dụng mạng CNN để khắc phục vấn đề này vì cửa sổ trượt của mạng CNN sẽ trượt trên cụm các câu liền nhau để trích rút đặc trưng của cụm các câu để trích rút đặc trưng của văn bản. Mô hình sử dụng kiến trúc CNN [85] đã trình bày trong chương 2 và tinh chỉnh để áp dụng cho mô hình tóm tắt đơn văn bản đề xuất. Đầu vào của lớp Convolution là 1 tensor có định dạng (n, 1, D*L, H); trong đó: n là kích thước lô dữ liệu (batch size), D là số lượng câu của văn bản, L là độ dài của 1 câu, H là số chiều của 3 lớp ẩn cuối cùng của mBERT (do cho kết quả tốt nhất trong thực nghiệm).
Lớp Convolution sử dụng trong mô hình có n = 32, D = 32, L = 64, H = 3*768 (giá trị 768 là số chiều của véc tơ đầu ra của mô hình mBERT). Kích thước của các cửa sổ h (window size) sử dụng trong mô hình là 5 và 10 với bước trượt (stride window) là 1. Số lượng bộ lọc (filter) là 100 tương ứng với mỗi cửa sổ trượt ở trên. Lớp Convolution được tinh chỉnh sử dụng hàm kích hoạt mới mish11 được đề xuất trong [126], hàm này được chứng minh là có xu hướng cải thiện hiệu quả kiến trúc mạng nơ ron, được tính toán theo công thức (3.3) sau đây.
với:
f (x) x tanh(softplus(x)) x tanh(ln(1ex ))
softplus(x) ln(1ex )
(3.3)
(3.4)
Sau đó, cho qua lớp k-Max Pooling (áp dụng phép toán k-Max Pooling trong
[127] thay vì phép toán Max Pooling trong [86]). Phép toán k-Max Pooling được áp dụng trên mỗi bản đồ đặc trưng (feature map) để chọn ra k giá trị lớn nhất (đề xuất lấy giá trị k = 2) là đặc trưng tương ứng với mỗi bộ lọc, được véc tơ đầu ra có 400 chiều.
Kiến trúc CNN với k-Max Pooling (k = 2) cho câu “I would like to have a cup of tea” được trình bày như Hình 3.5 dưới đây.
11 https://github.com/digantamisra98/Mish
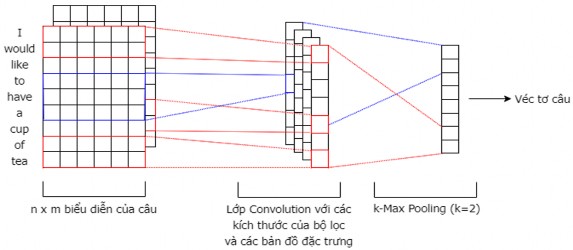
Hình 3.5. Kiến trúc lớp Convolution với k-Max Pooling (k = 2)
Mô hình Encoder-Decoder: Mô hình được xây dựng sử dụng kiến trúc bộ mã hóa - giải mã [92] với bộ mã hóa và giải mã sử dụng mạng biLSTM (mạng biLSTM đã trình bày trong chương 2). Mỗi biLSTM có 512 trạng thái ẩn x 2 chiều = 1.024 trạng thái ẩn để liên kết ngữ cảnh các câu trong văn bản. Các véc tơ đầu ra của lớp
k-Max Pooling
(s1, s2 ,..., sm )
được đưa qua bộ Encoder-Decoder và nhận được các
véc tơ câu đầu ra
(s' , s' ,..., s'
) có 1.024 chiều. Kiến trúc Encoder-Decoder đề xuất
1 2 m
của mô hình được biểu diễn như trong Hình 3.6 dưới đây.
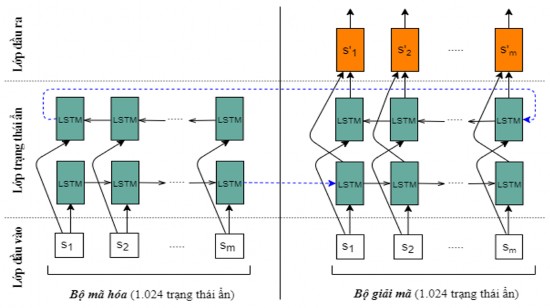
Hình 3.6. Kiến trúc mô hình Encoder-Decoder đề xuất
Lớp Dropout: Lớp FC dễ bị hiện tượng quá khớp nên mô hình xử lý đưa các véc tơ câu đầu ra của bộ Encoder-Decoder qua một lớp Dropout với tỉ lệ dropout p được chọn bằng 0,2 (p = 0,2) để giảm hiện tượng quá khớp trước khi véc tơ này được ghép nối với véc tơ đầu ra của lớp FC’ để đưa vào lớp FC tiếp theo sau trong mô hình phân loại câu.
Đặc trưng TF-IDF và lớp FC’: Nallapati và cộng sự [128] cho thấy hiệu quả của các đặc trưng sử dụng trong các mô hình tóm tắt văn bản nên đặc trưng TF-IDF được thêm cho mô hình để nâng cao hiệu quả của mô hình tóm tắt đề xuất. Do véc tơ TF-IDF có kích thước lớn (bằng kích thước của bộ từ vựng) nên mô hình sử dụng một lớp FC không có hàm kích hoạt (ký hiệu là lớp FC’) để giảm chiều của véc tơ TF-IDF (được xem như phép chiếu để giảm chiều của véc tơ TF-IDF) nhằm giảm độ phức tạp tính toán của mô hình. Do mô hình đề xuất giới hạn bộ từ vựng chỉ lấy
40.000 từ có tần suất xuất hiện cao nhất nên véc tơ TF-IDF cũng sẽ có số chiều là
40.000. Lớp FC’ có đầu vào bằng 40.000 tương ứng với số chiều của véc tơ TF- IDF, đầu ra là véc tơ có 128 chiều. Hệ thống sử dụng thư viện sklearn12 để tạo các véc tơ TF-IDF cho bộ dữ liệu đầu vào và thư viện Pytorch để xây dựng lớp FC’.
Phép toán ghép nối: Véc tơ đầu ra của lớp FC’ được ghép nối tiếp với véc tơ đầu ra của lớp Dropout bởi phép toán ghép nối (ký hiệu ) được một véc tơ có
1.152 chiều (bằng 1.024 + 128) là véc tơ đầu vào cho lớp FC với hàm kích hoạt softmax để thu được véc tơ đầu ra có 2 chiều là xác suất trả ra của hai nhãn ‘0’ – biểu diễn câu không được chọn và ‘1’ – biểu diễn câu được chọn.
Lớp FC: Mô hình sử dụng lớp FC có 1.152 chiều với hàm kích hoạt softmax để thu được véc tơ đầu ra có 2 chiều là xác suất được chọn của các câu.
3.3.2.3. Sinh bản tóm tắt
Các câu của văn bản đầu vào được sắp xếp theo thứ tự giảm dần theo xác suất được chọn. Các câu này được chọn để đưa vào tóm tắt cho đến khi đạt đến độ dài giới hạn tối đa của bản tóm tắt. Để loại bỏ thông tin dư thừa, mô hình sử dụng phương pháp MMR đề xuất theo công thức (2.44) trình bày ở chương 2 (với được chọn bằng 0,5) để đo độ tương đồng giữa các câu và loại bỏ các câu có độ tương đồng so với các câu hiện có trong văn bản tóm tắt lớn hơn một ngưỡng nhất định.
3.3.3. Thử nghiệm mô hình
3.3.3.1. Các bộ dữ liệu thử nghiệm
Mô hình được triển khai thử nghiệm cho hai ngôn ngữ khác nhau là tiếng Anh và tiếng Việt. Các bộ dữ liệu thử nghiệm đối với tiếng Anh gồm: DUC 2001 [72], DUC 2002 [73] và CNN [74]. Mục đích của việc thử nghiệm trên các bộ dữ liệu DUC 2001/DUC 2002 (bộ dữ liệu DUC 2001 sử dụng để huấn luyện, bộ dữ liệu DUC 2002 sử dụng để đánh giá mô hình) để có cơ sở so sánh với một phương pháp hiện đại khác gần với mô hình đề xuất nhất đã thử nghiệm trên hai bộ dữ liệu này. Mô hình thử nghiệm trên bộ dữ liệu CNN là để so sánh kết quả mô hình đề xuất với các mô hình hiện đại khác trong tóm tắt đơn văn bản hướng trích rút vì hiện nay các mô hình tóm tắt đơn văn bản hướng trích rút thường được thử nghiệm trên bộ dữ liệu CNN/Daily Mail. Việc thử nghiệm mô hình trên bộ dữ liệu Baomoi để đánh giá hiệu quả mô hình đề xuất đối với tóm tắt văn bản tiếng Việt và đảm bảo tính tổng quát của mô hình đề xuất đối với tóm tắt ngôn ngữ khác.
12 https://scikit-learn.org/