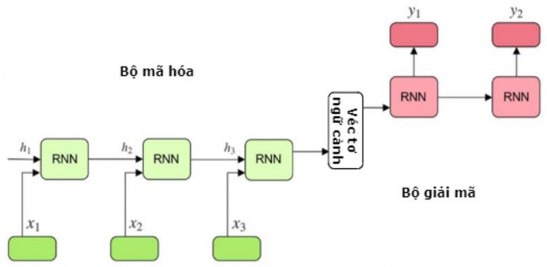
Hình 2.10. Mô hình mạng chuỗi sang chuỗi [92]
Trong mô hình seq2seq, bộ mã hóa đọc vào một câu là một chuỗi véc tơ
x (x1, x2 ,....xT ) . Với mỗi từ xt
(với
t 1,T ), mạng RNN mã hóa sẽ xử lý trả ra
một véc tơ ht
mang thông tin về từ đó và trình tự của nó với các từ phía trước. Kết
quả của quá trình xử lý cả câu là một véc tơ ngữ cảnh cuối cùng c.
Có thể bạn quan tâm!
-

 Ví Dụ Minh Họa Một Văn Bản Tóm Tắt Của Văn Bản Tiếng Anh
Ví Dụ Minh Họa Một Văn Bản Tóm Tắt Của Văn Bản Tiếng Anh -
 Các Phương Pháp Tóm Tắt Văn Bản Hướng Trích Rút Cơ Sở
Các Phương Pháp Tóm Tắt Văn Bản Hướng Trích Rút Cơ Sở -
![Một Kiến Trúc Cnn Cho Bài Toán Phân Loại Ảnh [84]](https://tailieuthamkhao.com/uploads/2022/06/10/nghien-cuu-phat-trien-mot-so-phuong-phap-tom-tat-van-ban-su-dung-ky-6-1-120x90.jpg) Một Kiến Trúc Cnn Cho Bài Toán Phân Loại Ảnh [84]
Một Kiến Trúc Cnn Cho Bài Toán Phân Loại Ảnh [84] -
![Mô Hình Biểu Diễn Các Bước Chưng Cất Được Huấn Luyện Trước Của Các Mô Hình Bert Thu Nhỏ [111]](https://tailieuthamkhao.com/uploads/2022/06/10/nghien-cuu-phat-trien-mot-so-phuong-phap-tom-tat-van-ban-su-dung-ky-8-1-120x90.jpg) Mô Hình Biểu Diễn Các Bước Chưng Cất Được Huấn Luyện Trước Của Các Mô Hình Bert Thu Nhỏ [111]
Mô Hình Biểu Diễn Các Bước Chưng Cất Được Huấn Luyện Trước Của Các Mô Hình Bert Thu Nhỏ [111] -
 Phát Triển Các Phương Pháp Tóm Tắt Đơn Văn Bản Hướng Trích Rút
Phát Triển Các Phương Pháp Tóm Tắt Đơn Văn Bản Hướng Trích Rút -
 Kết Quả Thử Nghiệm Một Số Phương Pháp Tóm Tắt Văn Bản Cơ Sở. Ký Hiệu ‘*’ Thể Hiện Phương Pháp Được Triển Khai Thử Nghiệm Trên Các Bộ
Kết Quả Thử Nghiệm Một Số Phương Pháp Tóm Tắt Văn Bản Cơ Sở. Ký Hiệu ‘*’ Thể Hiện Phương Pháp Được Triển Khai Thử Nghiệm Trên Các Bộ
Xem toàn bộ 185 trang tài liệu này.
htf xt,ht1
(2.20)
cq {h1,h2,....hT}
(2.21)
trong đó: ht là trạng thái ẩn ở bước t; f , q là các hàm phi tuyến. Kết quả của quá
trình mã hóa là
q{h1,h2,....hT}
là véc tơ trạng thái ẩn cuối cùng.
Sau khi có được véc tơ ngữ cảnh c, mạng RNN giải mã sẽ dự đoán từ
yt dựa
T
trên véc tơ ngữ cảnh c và tất cả các từ được dự đoán trước đó của cả câu sau quá trình giải mã được tính theo công thức:
p( y) pyt | {y1, y2 ,....yt1}, c
t 1
với xác suất của mỗi từ:
p yt | {y1, y2 ,....yt1}, cg yt 1, st ,...., c
y1, y2 ,....yt 1 . Xác suất
(2.22)
(2.23)
trong đó: g là một hàm phi tuyến,
yt xác suất đầu ra và st
là trạng thái ẩn của RNN.
Véc tơ ngữ cảnh c được sử dụng với ý nghĩa là tất cả dữ liệu trước đó được sử dụng để dự đoán từ tiếp theo.
Các bộ mã hóa và bộ giải mã trong mô hình seq2seq có thể được thực thi sử dụng các mạng khác nhau như mạng LSTM, biLSTM, GRU, biGRU và CNN.
2.1.6. Cơ chế chú ý
Khi chuỗi đầu vào dài thì kiến trúc bộ mã hóa - bộ giải mã trong mạng seq2seq có thể bị phá vỡ vì ở mỗi bước chỉ có một véc tơ ngữ cảnh c giao tiếp giữa bộ mã hóa và bộ giải mã mà véc tơ này phải mã hóa cho toàn bộ chuỗi đầu vào, có thể dẫn đến hiện tượng biến mất gradient. Để khắc phục nhược điểm này, cơ chế chú ý
(attention) [93] cho phép bộ giải mã tập trung vào các phần khác nhau từ đầu ra của bộ mã hóa. Hình 2.11 minh họa cơ chế chú ý trong việc sinh từ mục tiêu từ câu nguồn.
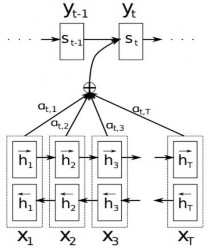
Hình 2.11. Mô hình minh họa cơ chế chú ý sinh từ mục tiêu
(x1, x2 ,....xT ) [93]
yt từ câu nguồn
Trong cơ chế này, định nghĩa mỗi xác suất có điều kiện trong công thức (2.22)
là:
p yi | {y1, y2 ,....yi1}, xg yi1, si ,....,ci
(2.24)
với: si là một trạng thái ẩn của RNN tại thời điểm i ( i 1,T ), được tính theo công thức:
sif si1,yi1,ci
Ở đây, mỗi xác suất có điều kiện trên một véc tơ ngữ cảnh riêng biệt
(2.25)
ci tương
ứng với mỗi từ mục tiêu yi . Véc tơ ngữ cảnh ci phụ thuộc vào chuỗi trạng thái
h1,h2,...., hTmà bộ mã hóa ánh xạ với câu đầu vào. Mỗi trạng thái hi
chứa thông
tin của toàn bộ câu với sự chú ý tới các thành phần xung quanh từ thứ i của câu đầu
vào. Sau đó, véc tơ ngữ cảnh theo công thức:
T
ci được tính bằng tổng trọng số của các trạng thái hi
ci ij hj j 1
trong đó: trọng số ij của mỗi trạng thái
hj được tính theo công thức:
(2.26)
softmax(e
) hay
exp(eij )
(2.27)
ij ij
ij T
exp(eik )
k 1
với: eij a si1, hj
là mô hình căn chỉnh cho biết độ tương quan giữa từ đầu vào
thứ j của bộ mã hóa và đầu ra tại vị trí i của bộ giải mã. Điểm căn chỉnh
eij
được
tính toán dựa trên trạng thái ẩn đích
si1
của RNN và trạng thái ẩn hj
của câu đầu
vào. Mô hình căn chỉnh đơn giản nhất được tham số hóa bởi một mạng nơ ron truyền thẳng với hàm tính điểm căn chỉnh có dạng:
a(s , h ) vT tanh(W [s ; h ])
(2.28)
i1 j align align i 1 j
với: Walign, valign là các tham số học của mô hình căn chỉnh.
Điểm căn chỉnh
eij
cũng có thể được tính toán dựa vào trạng thái ẩn hiện tại si
theo công thức eij a(si , hj ) với các phương pháp sau:
- Phương pháp của Graves và cộng sự [94]:
a(si , hj ) cosin(si , hj )
(2.29)
- Phương pháp của Luong và cộng sự [95]: Điểm căn chỉnh thu được bởi một hàm tính điểm dựa trên nội dung được tính theo một trong ba công thức sau:
vT
tanh(W [s ; h ])
a(s , h )
align align i j
i j i j
sT h
(2.30)
sT W h
i align j
Ngoài ra, Luong và cộng sự [95] còn đề xuất một hàm dựa trên vị trí (location-
based) mà ij được tính toán từ duy nhất trạng thái ẩn đích
ij softmax(Walign si )
si là:
(2.31)
Với mục tiêu cải thiện hiệu quả của các cơ chế chú ý áp dụng cho mô hình seq2seq, Luong và cộng sự [95] đã phát triển hai cơ chế chú ý là: chú ý toàn cục (global) và chú ý cục bộ (local). Tại mỗi thời điểm, chú ý toàn cục xem xét tất cả các từ nguồn, trong khi chú ý cục bộ chỉ xem xét một tập con các từ nguồn khi dự đoán từ mục tiêu. Các cơ chế chú ý này chủ yếu khác nhau về phương pháp tính
toán điểm căn chỉnh
sau:
eij
và véc tơ căn chỉnh ij khi tính toán véc tơ ngữ cảnh ci
như
- Chú ý toàn cục: Véc tơ căn chỉnh có kích thước thay đổi ij được tính theo
công thức (2.27) và điểm căn chỉnh
pháp trong công thức (2.30).
eij
được xác định theo một trong ba phương
- Chú ý cục bộ: Cơ chế này dựa trên các cơ chế chú ý cứng (hard attention) và chú ý mềm (soft attention) trong [96] và chỉ chú ý đến một số vị trí nguồn để tạo ra mỗi từ mục tiêu. Véc tơ căn chỉnh ij được tạo ra bằng cách sử dụng một cửa sổ có
tâm đặt tại vị trí căn chỉnh
qi là: [qi D, qi D]
(với D là giá trị tự chọn theo kinh
nghiệm). Chú ý cục bộ có hai biến thể tùy thuộc vào vị trí căn chỉnh qi
toán trong 2 trường hợp sau:
được tính
+ Căn chỉnh đơn điệu: Khi câu nguồn và câu đích được căn chỉnh đơn điệu
thì vị trí căn chỉnh qi i và véc tơ căn chỉnh ij được xác định theo công thức (2.27) ở trên.
+ Căn chỉnh dự đoán: Dự đoán vị trí căn chỉnh qi
dựa trên các tham số học
Wq, vq của mô hình và độ dài S của câu nguồn, được tính theo công thức:
q S.sigmoid (vT tanh(W s ))
(2.32)
i q q i
Theo kết quả của hàm sigmoid thì
qi [0, S]. Để ưu tiên các vị trí căn chỉnh gần
qi , một phân bố Gaussian được đặt xung quanh qi
toán theo công thức:
và véc tơ căn chỉnh ij được tính
2
(s qi )
ijsoftmax a(si, hj).exp
22
(2.33)
với: là độ lệch chuẩn được chọn là D ,
2
qi là một số thực, s là số nguyên nằm
trong phạm vi cửa sổ có tâm đặt tại vị trí qi , véc tơ ij có kích thước cố định bằng
(2.D + 1).
Ý tưởng gần đây về cơ chế chú ý để học ra mối tương quan của từ đang xét với các từ trong câu là cơ chế tự chú ý [97]. Cơ chế tự chú ý được mô tả chi tiết trong phần dưới đây.
2.1.7. Cơ chế tự chú ý và mô hình Transformer
2.1.7.1. Cơ chế tự chú ý
Cơ chế tự chú ý (self-attention) được sử dụng để giúp cho mô hình nắm bắt được sự liên quan giữa các từ trong một câu, cho phép mô hình xác định được các từ có liên quan với một từ cho trước và sau đó thông tin sẽ được mã hóa dựa trên tất cả các từ đó.
Self-attention nhận đầu vào là ba véc tơ được tạo ra từ cùng một chuỗi: Q - véc tơ lưu trữ thông tin từ cần tìm kiếm (kích thước dk), K - véc tơ biểu diễn thông tin các từ trong câu so sánh với từ cần tìm kiếm (kích thước dk) và V - véc tơ biểu diễn nội dung của các từ (kích thước dv) trong chuỗi. Quá trình tính toán self-attention có thể được mô tả qua các bước như sau:
- Bước 1: Tính các ma trận Q, K, V bằng cách nhân véc tơ mã hóa từ của các từ đầu vào với các ma trận trọng số học tương ứng.
- Bước 2: Tính tích vô hướng của hai ma trận Q, K với mục đích so sánh giữa câu Q và K để học mối tương quan
- Bước 3: Chuẩn hóa các giá trị đã tính được về khoảng [0; 1] sử dụng hàm softmax (với ý nghĩa bằng 1 khi câu Q giống với K, ngược lại thì bằng 0).
- Bước 4: Kết quả trả ra được tính bằng tích vô hướng của ma trận vừa tính toán ở trên với ma trận V theo công thức:
![]()
T
Attention(Q, K ,V ) softmax( QK )V
dk
(2.34)
2.1.7.2. Kiến trúc của Transformer
Mô hình Transformer [97] được đề xuất với khả năng tính toán song song và nắm bắt được phụ thuộc xa nhờ cơ chế self-attention đã đạt được hiệu quả cao trong các nhiệm vụ xử lý ngôn ngữ tự nhiên. Mô hình Transformer được biểu diễn trong Hình 2.12 dưới đây, bao gồm bộ mã hóa và bộ giải mã với các từ đầu vào được đưa vào mô hình đồng thời nên không có khái niệm bước, thay vào đó là cơ chế self- attention.
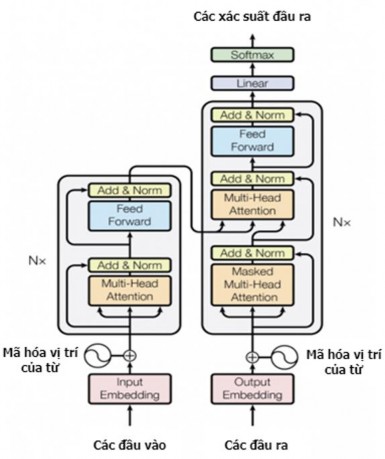
Hình 2.12. Mô hình Transformer [97]
Bộ mã hóa và bộ giải mã gồm các lớp xếp chồng lên nhau, mỗi lớp gồm 2 thành phần chính được mô tả như sau:
Mã hóa vị trí của từ (Positional Encoding): Do các từ được đưa vào đồng thời nhưng ta muốn biểu diễn được ngữ cảnh của từ nên cần thêm mã hóa vị trí của từ (PE - Positional Encoding) vào các mã hóa từ đầu vào (WE - word embedding) để thêm thông tin về vị trí của từ trong chuỗi (các PE có cùng kích thước với các WE để có thể thực hiện tính tổng được). Sau đó, biểu diễn của một từ được tính bằng cách cộng hai véc tơ PE và WE để đưa vào bộ mã hóa. PE của từ thứ i trong câu được tính như sau:
PE( pos,2i ) sin
pos
2i
10000dmod el
(2.35)
PE( pos,2i1) cos
pos
2i
10000dmod el
(2.36)
trong đó: pos là vị trí của từ trong câu, PE là giá trị phần tử thứ i trong véc tơ mã hóa từ có độ dài dmodel.
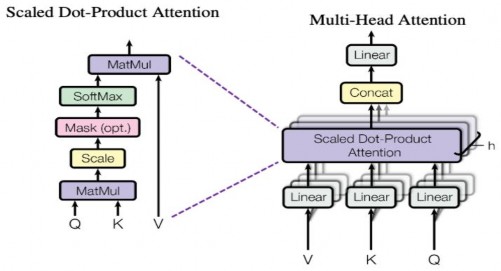
Hình 2.13. Scaled Dot-Product Attention và Multi-Head Attention [97]
Cơ chế chú ý nhiều “đầu” (Multi-Head Attention): Self-attention giúp cho mô hình thấy được mức độ chú ý của một từ tới các từ còn lại. Để chú ý vào các vị trí khác nhau, mô hình sử dụng cơ chế chú ý nhiều “đầu”. Cơ chế chú ý nhiều “đầu” gồm các lớp self-attention xếp chồng song song, mỗi lớp self-attention có một phép biến đổi tuyến tính riêng biệt từ cùng một đầu vào được gọi là “đầu”. Mỗi “đầu” sẽ cho kết quả riêng, các ma trận này được ghép nối với nhau, sau đó nhân với một ma trận tham số học để được một ma trận chú ý đầu ra duy nhất. Chú ý nhiều “đầu” được tính toán theo công thức:
MultiHead (Q, K,V ) Concat(head1, head2
,...., headh
)WO
(2.37)
trong đó:
head =Attention(QWQ , KWK ,VWV ) ,
Concat(head1, head2
,...., headh
) là
i i i i
phép ghép nối các đầu
headi , h là số đầu, các ma trận
i i i
WQ Rdmodel xdk , WK Rdmodel xdk , WV Rdmodel x dv
học.
vàWO Rhdv xdmodel
là các tham số
Multi-head attention ứng dụng trong mô hình Transformer như sau [98]:
Các lớp self-attention trong bộ mã hóa có ba véc tơ K, V và Q đến từ cùng một chuỗi đầu vào, chuỗi này là đầu ra của lớp trước đó của bộ mã hóa.
Trong lớp chú ý mã hóa - giải mã (encoder-decoder attention) thì cơ chế chú ý được sử dụng ở đây không phải là self-attention mà là attention. Các véc tơ K, V đến từ đầu ra của bộ mã hóa, còn véc tơ Q đến từ lớp giải mã trước đó của bộ giải mã.
Các lớp self-attention trong bộ giải mã cho phép mỗi vị trí trong bộ giải mã tham gia vào tất cả các vị trí trong bộ giải mã. Tuy nhiên, việc tính trọng số chú ý cần che đi một phần các vị trí đầu ra và được thực hiện bởi cơ chế scaled dot- product attention. Cơ chế scaled dot-product attention này tương tự như cơ chế dot- product attention nhưng có thêm hệ số tỉ lệ.
Trong bộ giải mã còn có lớp chú ý nhiều “đầu” bị che (Masked Multi-Head Attention). Về bản chất, lớp này là Multi-head attention. Ngoài ra, Transformer còn có các lớp cộng và chuẩn hóa (Add & Norm) và mạng nơ ron truyền thẳng (Feed Forward).
2.2. Các mô hình ngôn ngữ dựa trên học sâu được huấn luyện trước
2.2.1. Mã hóa từ
Mã hóa từ (Word embedding) là phương pháp phổ biến để biểu diễn các từ của văn bản. Mã hóa từ có khả năng nắm bắt được ngữ cảnh của một từ trong văn bản, sự tương đồng về ý nghĩa và ngữ pháp, mối quan hệ giữa một từ với các từ khác. Nó cung cấp các véc tơ biểu diễn dày đặc của các từ, đây là cải tiến so với các mô hình sử dụng tần suất xuất hiện của từ để sinh ra các véc tơ có kích thước lớn và thưa (chứa hầu hết các giá trị 0) để mô tả văn bản nhưng không phải ý nghĩa của các từ. Mã hóa từ sử dụng một thuật toán để huấn luyện tập các véc tơ dày đặc với giá trị liên tục, có độ dài cố định dựa trên khối lượng lớn các văn bản. Mỗi từ được biểu diễn bởi một điểm trong không gian mã hóa và được học dựa trên các từ xung quanh nó. Phương pháp mã hóa từ sử dụng cho các nhiệm vụ trong xử lý ngôn ngữ tự nhiên như tóm tắt văn bản, dịch máy,…đã đạt được hiệu quả cao. Có một số mô hình được sử dụng để học mã hóa từ như Word2vec, Glove, BERT,...
2.2.2. Phương pháp Word2Vec
Phương pháp word2vec [99] là phương pháp thống kê có thể học hiệu quả mã hóa từ độc lập với một kho ngữ liệu văn bản cho trước. Đầu ra của word2vec là bộ phân lớp sử dụng hàm softmax [100]. Hàm softmax cho giá trị thuộc khoảng [0; 1] là xác suất của mỗi đầu ra, tổng các giá trị này bằng 1. Phương pháp word2vec thường kết hợp hai mô hình để học mã hóa từ là mô hình túi từ liên tục (CBoW - Continuous Bag of Words) [101] và mô hình Skip - Gram [101].
Mô hình CBoW: Lấy ngữ cảnh của mỗi từ làm đầu vào để cố gắng dự đoán ra từ tương ứng với ngữ cảnh này, nghĩa là CBoW học cách mã hóa từ bằng cách dự đoán từ hiện tại dựa trên ngữ cảnh của từ đó. Chi tiết như sau: CBoW sử dụng véc tơ mã hóa one - hot của từ đầu vào và tính toán lỗi đầu ra của mô hình so với véc tơ mã hóa one - hot của từ cần dự đoán. Trong quá trình dự đoán từ mục tiêu, mô hình có thể học được cách để biểu diễn véc tơ của từ mục tiêu này. Hình 2.14 là kiến trúc của mô hình CBoW với 1 từ làm ngữ cảnh để dự đoán từ tiếp theo.
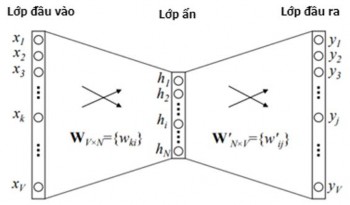
Hình 2.14. Mô hình CBoW với một từ làm ngữ cảnh để dự đoán từ tiếp theo [101]
với:
+ Lớp đầu vào là véc tơ được mã hóa dưới dạng véc tơ one-hot có kích thước V, lớp ẩn chứa N nơron, lớp đầu ra là một véc tơ có kích thước V.
+ WV×N là một ma trận trọng số với số chiều là V×N, ánh xạ lớp vào tới lớp ẩn.
+ W’N×V là ma trận trọng số với số chiều là N×V, ánh xạ các lớp ẩn tới lớp ra.
Các nơ ron trong lớp ẩn chỉ sao chép tổng trọng số của lớp vào sang lớp tiếp theo (không có các hàm kích hoạt sigmoid, tanh hay ReLU [100]), chỉ có hàm kích hoạt softmax tại các nơ ron trong lớp ra.
Ta cũng có thể sử dụng nhiều từ đầu vào làm ngữ cảnh để dự đoán ra từ tiếp theo thay vì chỉ sử dụng 1 từ làm ngữ cảnh, khi đó mô hình tổng quát được biểu diễn như trong Hình 2.15 dưới đây.
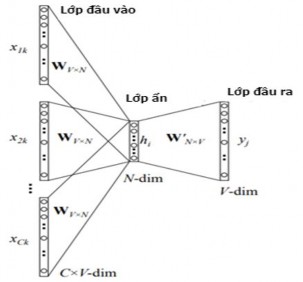
Hình 2.15. Mô hình CBoW với nhiều từ làm ngữ cảnh để dự đoán từ tiếp theo [101]
Mô hình này gồm ngữ cảnh của C từ nên khi tính toán các đầu vào lớp ẩn, mô hình tính trung bình véc tơ của C từ.
Mô hình Skip-Gram: Khác với mô hình CBoW, mô hình Skip-Gram học mã hóa từ bằng cách dự đoán các từ xung quanh cho một từ đầu vào, được biểu diễn trong Hình 2.16 dưới đây.
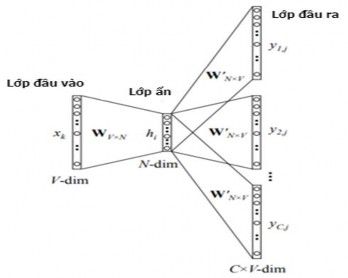
Hình 2.16. Mô hình Skip-Gram [101]