2.1.2. Mạng nơ ron tích chập
2.1.2.1. Giới thiệu mạng nơ ron tích chập
Mạng nơ ron tích chập (CNN - Convolutional Neural Network) [81,82,83,84] là một trong những mô hình học sâu phổ biến hiện nay giúp chúng ta xây dựng được những ứng dụng thống thông minh với độ chính xác cao, đặc biệt là trong xử lý ảnh, xử lý tiếng nói, xử lý âm thanh,… Đây là một trong những mạng nơ ron truyền thẳng đặc biệt, xử lý dữ liệu dạng lưới. Mạng CNN là một mạng nơ ron đơn giản sử dụng phép tích chập trong các phép nhân ma trận tại ít nhất một trong các lớp của nó. Trong CNN, các lớp liên kết với nhau thông qua cơ chế tích chập (convolution). Lớp tiếp theo là kết quả nhân chập từ lớp trước đó nên ta có được các kết nối cục bộ. Mỗi lớp được áp dụng một bộ lọc khác nhau. Trong quá trình huấn luyện, CNN sẽ tự động học các tham số cho các bộ lọc. Hình 2.2 minh họa một kiến trúc CNN trong bài toán phân loại ảnh.
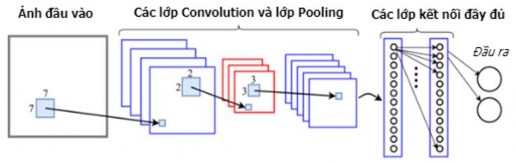
Hình 2.2. Một kiến trúc CNN cho bài toán phân loại ảnh [84]
Kiến trúc mạng CNN gồm các lớp cơ bản sau:
Lớp tích chập (Convolution): Đây là lớp quan trọng nhất trong mạng thể hiện ý tưởng xây dựng của mạng. Lớp này sử dụng một bộ lọc xếp chồng vào một vùng trong ma trận dữ liệu và thực hiện tính toán nhân chập giữa bộ lọc và giá trị dữ liệu trong vùng mà nó xếp chồng. Bộ lọc sẽ lần lượt được dịch chuyển theo một giá trị bước trượt (stride) chạy dọc theo ma trận dữ liệu và quét dữ liệu. Các trọng số ban đầu của bộ lọc được khởi tạo ngẫu nhiên và được điều chỉnh trong quá trình huấn luyện mô hình.
Lớp kích hoạt phi tuyến (ReLU - Rectified Linear Unit): Lớp ReLU thường được thiết kế ngay sau lớp tích chập. Lớp này thực hiện chuyển toàn bộ các giá trị âm trong kết quả của lớp tích chập thành giá trị 0, để tạo tính phi tuyến cho mô hình.
Có thể bạn quan tâm!
-

 Ý Nghĩa Khoa Học Và Ý Nghĩa Thực Tiễn
Ý Nghĩa Khoa Học Và Ý Nghĩa Thực Tiễn -
 Ví Dụ Minh Họa Một Văn Bản Tóm Tắt Của Văn Bản Tiếng Anh
Ví Dụ Minh Họa Một Văn Bản Tóm Tắt Của Văn Bản Tiếng Anh -
 Các Phương Pháp Tóm Tắt Văn Bản Hướng Trích Rút Cơ Sở
Các Phương Pháp Tóm Tắt Văn Bản Hướng Trích Rút Cơ Sở -
 Các Mô Hình Ngôn Ngữ Dựa Trên Học Sâu Được Huấn Luyện Trước
Các Mô Hình Ngôn Ngữ Dựa Trên Học Sâu Được Huấn Luyện Trước -
![Mô Hình Biểu Diễn Các Bước Chưng Cất Được Huấn Luyện Trước Của Các Mô Hình Bert Thu Nhỏ [111]](https://tailieuthamkhao.com/uploads/2022/06/10/nghien-cuu-phat-trien-mot-so-phuong-phap-tom-tat-van-ban-su-dung-ky-8-1-120x90.jpg) Mô Hình Biểu Diễn Các Bước Chưng Cất Được Huấn Luyện Trước Của Các Mô Hình Bert Thu Nhỏ [111]
Mô Hình Biểu Diễn Các Bước Chưng Cất Được Huấn Luyện Trước Của Các Mô Hình Bert Thu Nhỏ [111] -
 Phát Triển Các Phương Pháp Tóm Tắt Đơn Văn Bản Hướng Trích Rút
Phát Triển Các Phương Pháp Tóm Tắt Đơn Văn Bản Hướng Trích Rút
Xem toàn bộ 185 trang tài liệu này.
Lớp lấy mẫu (Pooling): Thực hiện lấy mẫu dữ liệu, lớp này thường được thiết kế sau lớp tích chập và lớp ReLU để làm giảm kích thước dữ liệu đầu ra mà vẫn giữ được các thông tin quan trọng của dữ liệu đầu vào. Lớp Pooling sử dụng một cửa sổ trượt quét qua toàn bộ ma trận dữ liệu, mỗi lần trượt theo một bước trượt (stride) cho trước. Khi cửa sổ trượt trên dữ liệu, chỉ có một giá trị được xem là giá trị đại diện cho thông tin dữ liệu tại vùng đó (giá trị mẫu) được giữ lại. Các phương thức phổ biến trong lớp Pooling là Max Pooling (lấy giá trị lớn nhất), Min Pooling (lấy
giá trị nhỏ nhất) và Average Pooling (lấy giá trị trung bình). Hình 2.3 minh họa việc tính toán với phương thức Avarage Pooling và Max Pooling.
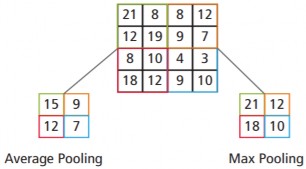
Hình 2.3. Tính toán với phương thức Average Pooling và Max Pooling [82]
Lớp kết nối đầy đủ (FC - Fully Connected): Lớp này giống như lớp trong mạng nơ ron truyền thống, các giá trị dữ liệu được liên kết đầy đủ vào các nút trong lớp tiếp theo. Sau khi dữ liệu được xử lý và trích rút đặc trưng từ các lớp trước đó thì kích thước dữ liệu đã giảm rất nhiều nên có thể sử dụng mạng nơ ron truyền thống để phân loại dữ liệu. Lớp FC đóng vai trò như mô hình phân lớp.
2.1.2.2. Mạng CNN cho bài toán xử lý ngôn ngữ tự nhiên
Mạng CNN sử dụng để trích chọn các đặc trưng của văn bản cho các nhiệm vụ trong xử lý ngôn ngữ tự nhiên được mô tả trong [85]. Mô hình CNN sử dụng nhiều bộ lọc (với các kích thước cửa sổ khác nhau) để thu được nhiều đặc trưng. Các đặc trưng này tạo thành lớp sát lớp trên cùng (penultimate) và được chuyển đến lớp FC với hàm kích hoạt softmax để trả ra phân phối xác suất của các câu.
Quá trình trích xuất một đặc trưng từ một bộ lọc được mô tả chi tiết như sau:
m
Cho xi ∈ là véc tơ từ m chiều tương ứng với từ thứ i trong câu. Một câu có độ
dài n (thêm khoảng trắng nếu cần) được biểu diễn là:
x1n x1 x2 x3...xn
(2.1)
![]()
trong đó: ⊕ là phép ghép nối. Một cách tổng quát, ký hiệu xii+j biểu diễn cách
ghép nối các từ
xi , xi1, xi1,..., xij . Phép tích chập với bộ lọc w ∈ hm được áp
dụng cho một cửa sổ có h từ để tạo ra một đặc trưng mới. Đặc trưng ci được tạo ra
từ một cửa sổ các từ
xiih1 được biểu diễn là:
ci
f (w.xiih1 b)
(2.2)
với b ∈ ![]() là các phần tử độ lệch (bias) và f là hàm phi tuyến. Bộ lọc này được áp dụng cho tất cả các cửa sổ từ có thể có trong câu {x1h, x2h+1,..., xn−h+1n} để tạo ra một bản đồ đặc trưng (feature map)
là các phần tử độ lệch (bias) và f là hàm phi tuyến. Bộ lọc này được áp dụng cho tất cả các cửa sổ từ có thể có trong câu {x1h, x2h+1,..., xn−h+1n} để tạo ra một bản đồ đặc trưng (feature map)
c [c1,c2 ,c3,...,cnh1]
(2.3)
với c ∈ ![]() n−h+1. Sau đó, áp dụng phép toán Max Pooling [86] trên bản đồ đặc trưng
n−h+1. Sau đó, áp dụng phép toán Max Pooling [86] trên bản đồ đặc trưng
và lấy giá trị lớn nhất cˆ max{c} là đặc trưng tương ứng với mỗi bộ lọc.
2.1.3. Mạng nơ ron hồi quy
2.1.3.1. Mô hình mạng nơ ron hồi quy
Ý tưởng của mạng nơ ron hồi quy (RNN - Recurrent neural network) [87] là thiết kế một mạng nơ ron có khả năng xử lý được thông tin dạng chuỗi. Mạng nơ ron hồi quy là mô hình học sâu đã đạt được nhiều kết quả trong các nhiệm vụ xử lý ngôn ngữ tự nhiên (NLP - Natural language processing). RNN là một mô hình có nhớ (memory), có khả năng nhớ được thông tin đã tính toán trước đó. RNN thực hiện cùng một tác vụ cho tất cả các phần tử của một chuỗi với đầu ra phụ thuộc vào tính toán trước đó. Hình 2.4 biểu diễn mô hình mạng nơ ron hồi quy được triển khai chi tiết.
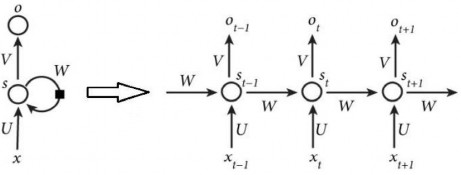
Hình 2.4. Mô hình mạng nơ ron hồi quy [87]
trong đó:
- xt là đầu vào tại bước t.
- st là trạng thái ẩn tại bước t (là bộ nhớ của mạng), được tính toán dựa trên các
trạng thái ẩn phía trước và đầu vào tại bước đó theo công thức:
stf UxtWst1
(2.4)
với: f là một hàm phi tuyến như hàm tanh, sigmoid hoặc ReLU. Để thực hiện phép toán cho phần tử ẩn đầu tiên ta khởi tạo thêm s-1 và giá trị khởi tạo thường được gán bằng 0.
- ot là đầu ra tại bước t, là một véc tơ xác suất các từ trong bộ từ vựng:
otsoftmax Vst
- Véc tơ đầu ra ot
sẽ được sử dụng cho những dự đoán tiếp theo.
(2.5)
2.1.3.2. Huấn luyện mạng nơ ron hồi quy
Nếu xét tại một thời điểm, hoạt động của RNN giống như mạng nơ ron truyền thống: Dữ liệu từ đầu vào sẽ được tính toán qua nhiều lớp và đưa đặc trưng thu được ra đầu ra. Tuy nhiên, RNN khác với mạng nơ ron truyền thống, việc đưa đặc trưng từ mẫu dữ liệu trước vào đầu vào của mẫu dữ liệu sau để học ra mối quan hệ là: Tại thời điểm t, RNN tính toán được đầu ra là ot, giá trị này sẽ được truyền vào lại mô hình tại thời điểm (t+1) để tính toán cho mẫu dữ liệu tiếp theo và được đầu ra ot+1.
RNN được huấn luyện bằng thuật toán lan truyền ngược nhưng việc lan truyền ngược là lan truyền ngược liên hồi (BPTT - Backpropagation Through Time) [80]. Do đó, thuật toán lan truyền ngược được thay đổi lại là: Hướng giảm của đạo hàm (gradient descent) tại mỗi đầu ra phụ thuộc vào các tính toán tại bước hiện tại và các bước trước đó (do bộ tham số trong RNN được sử dụng chung cho tất cả các bước). Với các bước phụ thuộc càng xa, việc học càng khó khăn vì xuất hiện vấn đề biến mất gradient/bùng nổ gradient (vanishing/exploding gradient).
Ví dụ: Để tính gradient descent tại bước t = 4, ta phải lan truyền ngược cả 3 bước phía trước, rồi cộng tổng gradient descent lại với nhau. Việc tính toán này được gọi là lan truyền ngược liên hồi.
2.1.4. Các biến thể của RNN
Mạng RNN có nhược điểm là không thể nhớ dài hạn, nghĩa là RNN chỉ học được các trạng thái gần nên RNN được cải tiến bằng việc bổ sung các mô đun nhớ. Để khắc phục nhược điểm này, một số biến thể của RNN được nghiên cứu phát triển như mạng có nhớ dài - ngắn hạn (LSTM - Long short term memory network) [87], mạng LSTM hai chiều (biLSTM - Bidirectional long short term memory network) [88], mạng GRU (gated recurrent unit) và mạng GRU hai chiều (biGRU - Bidirectional gated recurrent unit) [89,90]. Mạng LSTM, GRU có khả năng học các phụ thuộc xa (long-term dependencies) theo một chiều, trong khi đó mạng biLSTM, biGRU có khả năng học các phụ thuộc xa theo hai chiều. Chi tiết được trình bày như dưới đây.
2.1.4.1. Mạng LSTM
Mạng LSTM bao gồm một tập các tế bào nhớ LSTM được kết nối hồi quy. Kiến trúc tổng quan một tế bào nhớ LSTM (LSTM cell) được biểu diễn như trong Hình 2.5 dưới đây.
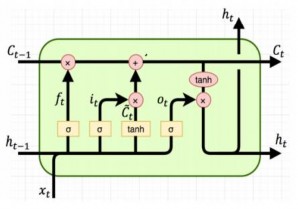
Hình 2.5. Kiến trúc tổng quan một tế bào nhớ LSTM (nguồn: [Internet])
Ngoài việc sử dụng đầu vào hiện tại
xt và trạng thái ẩn ở bước trước
ht 1
như
RNN, tế bào nhớ LSTM còn sử dụng thêm một đầu vào nữa là trạng thái nhớ (cell
state) ở bước trước
ct 1 . Trạng thái nhớ này là bộ nhớ của tế bào nhớ LSTM để lưu
trữ thông tin của các bước trước, do đó khắc phục được ảnh hưởng của nhớ ngắn hạn (short-term memory) của RNN. Kiến trúc một tế bào nhớ LSTM bao gồm:
Cổng quên (Forget gate) ( ft ): Quyết định thông tin của trạng thái nhớ ở bước
trước (t-1) có cần lưu giữ hay không. Thông tin từ
xt và
ht 1 được chuyển qua hàm
sigmoid và kết quả trả ra thuộc khoảng [0; 1]. Nếu kết quả trả ra gần bằng 1, nghĩa là thông tin cần giữ lại còn nếu kết quả trả ra gần bằng 0 thông tin cần loại bỏ.
Cổng vào (Input gate) ( it ): Cập nhật thông tin vào trạng thái nhớ. Thực hiện nhân kết quả trả ra của hàm sigmoid với kết quả trả ra của hàm tanh để quyết định thông tin của đầu vào hiện tại và trạng thái ẩn bước trước có nên được cập nhật vào trạng thái nhớ hay không.
Cổng ra (Output gate) ( ot ): Tính giá trị của trạng thái ẩn cho bước tiếp theo. Với việc sử dụng cổng quên và cổng vào, ta có thể tính được giá trị mới của trạng thái nhớ và từ đó kết hợp với đầu vào hiện tại và trạng thái ẩn bước trước để tính giá trị của trạng thái ẩn ở bước tiếp theo. Giá trị của trạng thái ẩn mới này chính là giá trị dự đoán.
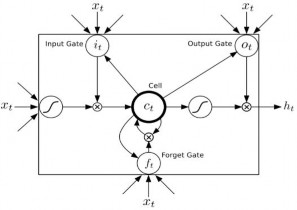
Hình 2.6. Chi tiết tế bào nhớ LSTM [91]
Chi tiết một tế bào nhớ LSTM (LSTM cell) [91] được biểu diễn trong Hình 2.6, được mô tả như sau: Tại mỗi bước t (với t = 1, 2,…, J), với một chuỗi đầu vào
x x1, x2 ,..., xJ thì:
- Đầu vào:
ct 1 ,
ht 1 ,
xt ; với:
xt là đầu vào ở trạng thái thứ 𝑡 và
ct 1 ,
ht 1 tương
ứng là trạng thái nhớ, trạng thái ẩn đầu ra của lớp trước đó.
- Đầu ra: ct , ht là trạng thái nhớ, trạng thái ẩn tương ứng.
- Mạng thực hiện tính toán chuỗi véc tơ ẩn đầu ra yt y1, y2 ,..., yT theo các công thức sau:
ht h1, h2 ,..., hJ và chuỗi véc tơ
ht H (Wxh xt Whhht 1 bh )
yt Why ht by
(2.6)
(2.7)
trong đó: H là hàm lớp ẩn (là tế bào nhớ LSTM), được tổng hợp bởi các hàm:
it (Wxi xt Whi ht 1 Wcict 1 bi )
ft (Wxf xt Whf ht 1 Wcf ct 1 bf )
(2.8)
(2.9)
ct
ft ct 1 it tanh(Wxc xt Whcht 1 bc )
(2.10)
ot (Wxo xt Whoht 1 Wcoct bo )
(2.11)
ht ot tanh(ct )
(2.12)
với:
+ 0 <
ft , it , ot
< 1.
+ σ là hàm sigmoid.
+ Các thành phần b (gồm bh , bi , bf , bc , bo ) biểu diễn các véc tơ độ lệch (bias) tương ứng (ví dụ: bh là véc tơ độ lệch trạng thái ẩn).
+ Các thành phần W biểu diễn các ma trận trọng số học tương ứng (ví dụ:
Wxh là ma trận trọng số học trạng thái ẩn đầu vào).
2.1.4.2. Mạng biLSTM
Việc dự đoán chính xác một từ trong một đoạn văn bản phụ thuộc không chỉ vào các thông tin phía trước của từ đang xét mà còn phụ thuộc vào các thông tin phía sau. Tuy nhiên, kiến trúc mạng LSTM một chiều chỉ có thể dự đoán từ hiện tại dựa trên thông tin của các từ phía trước nó bằng cách đọc câu đầu vào theo trình tự
từ đầu đến cuối (từ điểm đầu tiên
x1 đến điểm cuối
xJ ). Do đó, mạng biLSTM [88]
được đề xuất để tổng hợp mỗi từ không chỉ thông tin của từ phía trước mà còn cả thông tin của từ phía sau từ đó.
Hình 2.7 biểu diễn kiến trúc tổng quan của mạng biLSTM bao gồm: mạng LSTM chiều tiến và mạng LSTM chiều lùi.
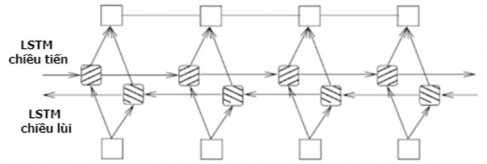
Hình 2.7. Kiến trúc tổng quan của mạng biLSTM [88]
![]()
![]()
- Chiều tiến h : Mạng LSTM đọc câu đầu vào theo thứ tự (từ toán trạng thái ẩn h1, h2,..., hJ.
x1 đến
xJ ) và tính
![]()
- Chiều lùi h : Mạng LSTM đọc câu đầu vào theo thứ tự ngược lại (từ xJ
quay
![]()
lui về x1) và tính toán trạng thái ẩn h1, h2,..., hJ.
Trạng thái ẩn ht cho mỗi từ xt
(với t 1, J ) được xác định bằng việc ghép nối
![]()
![]()
ht và ht được biểu diễn như sau:
hththt
Trạng thái ht
bao gồm thông tin tổng hợp của cả phía trước và phía sau từ
xt .
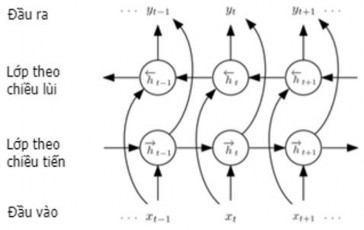
Hình 2.8. Minh họa biLSTM ở 3 bước (t-1), t và (t+1) [91]
Hình 2.8 minh họa biLSTM ở 3 bước (t-1), t và (t+1). Ở mỗi bước t, biLSTM
![]()
tính toán chuỗi ẩn theo chiều tiến ht
(với t = 1, 2,…,J-1, J), chuỗi ẩn theo chiều lùi
![]()
ht (với t = J, J-1, …,1), chuỗi đầu ra yt và cập nhật lớp đầu ra:
hy hy y
x h t hh h
x h t hh h
ht H (W x W ht 1 b ) ht H (W x W ht 1 b ) yt H (W ht W ht b )
(2.13)
(2.14)
(2.15)
2.1.4.3. Mạng GRU
Mạng GRU [89,90] được phát triển để nắm bắt phụ thuộc xa và khắc phục vấn đề biến mất độ dốc (vanishing gradient) thường xảy ra khi huấn luyện RNN. Mạng GRU bao gồm một tập các tế bào nhớ GRU được kết nối hồi quy. Một tế bào nhớ GRU có hai cổng điều khiển đó là: cổng cài đặt lại (reset gate) và cổng cập nhật (update gate) được kết hợp từ cổng quên (forget gate) và cổng vào (input gate) của tế bào nhớ LSTM, kết hợp trạng thái nhớ (cell state) và trạng thái ẩn nên kiến trúc của tế bào nhớ GRU đơn giản hơn tế bào nhớ LSTM, được biểu diễn như trong Hình 2.9. Cổng cài đặt lại xác định thông tin cần phải quên trong trạng thái ẩn của bước trước đó. Khi giá trị của cổng cài đặt lại gần bằng 0, thông tin của bước trước đó sẽ bị quên. Khi giá trị gần bằng 1, thông tin ẩn của bước trước đó được giữ lại trong thông tin nhớ hiện tại. Cổng cập nhật xác định thông tin ở trạng thái ẩn tại bước trước đó sẽ được đưa vào trạng thái ẩn hiện tại. Khi giá trị của cổng cập nhật gần bằng 0, thông tin ở trạng thái ẩn tại bước trước đó sẽ bị quên. Khi giá trị gần bằng 1, thông tin được giữ lại trong trạng thái ẩn hiện tại.
![]()
Trong Hình 2.9, x là đầu vào của mạng hiện tại, z là cổng cập nhật, r là cổng cài
đặt lại, h ghi lại tất cả các thông tin quan trọng thông qua cổng cài đặt lại và thông tin đầu vào, h là trạng thái ẩn hiện tại.
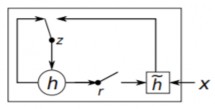
Hình 2.9. Chi tiết tế bào nhớ GRU [89]
Tại bước t, các giá trị này được tính toán theo các công thức sau:
zt (Wzhht 1 Wzx xt bz )
rt (Wrhht1 Wrx xt br )
ht tanh(Whx xt Whh (rt ht 1 ) bh )
ht zt ht (1zt ) ht 1
(2.16)
(2.17)
(2.18)
(2.19)
trong đó:
+ là phép nhân ma trận Hadamard (phép toán nhân element-wise).
+ σ là hàm sigmoid.
+ Các thành phần b (gồm bh , br , bz ) biểu diễn các véc tơ độ lệch tương ứng (ví dụ: bh là véc tơ độ lệch trạng thái ẩn).
+ Các thành phần W biểu diễn các ma trận trọng số tương ứng (ví dụ: Wzh là ma trận trọng số trạng thái ẩn cập nhật).
2.1.4.4. Mạng biGRU
Mạng GRU hai chiều (biGRU - Bidirectional GRU) [89,90] được cải tiến với kiến trúc hai lớp. Kiến trúc hai lớp này cung cấp cho lớp đầu ra của mạng các thông tin hoàn chỉnh theo ngữ cảnh của thông tin đầu vào tại mỗi bước. Kiến trúc tổng quan của mạng biGRU cũng giống như kiến trúc của mạng biLSTM gồm mạng theo chiều tiến và mạng theo chiều lùi nhưng chỉ khác là mỗi mạng này là mạng GRU thay vì mạng LSTM như trong mạng biLSTM.
2.1.5. Mô hình chuỗi sang chuỗi cơ bản
Mô hình chuỗi sang chuỗi (seq2seq - Sequence to Sequence) [92] là mô hình học sâu gồm hai thành phần chính được gọi là bộ mã hóa (encoder) và bộ giải mã (decoder) để sinh ra chuỗi đầu ra từ một chuỗi đầu vào. Bộ mã hóa sẽ mã hóa chuỗi đầu vào thành một véc tơ mã hóa (encoder vector) hay véc tơ ngữ cảnh (context vector) c có độ dài cố định. Bộ giải mã sẽ sinh lần lượt từng từ trong chuỗi đầu ra dựa trên véc tơ ngữ cảnh c và các từ được sinh ra trước đó cho đến khi gặp từ kết thúc câu. Trong mô hình tóm tắt văn bản tự động, tại mỗi bước giải mã ta tạo ra danh sách các từ ứng viên thay vì tìm ra xác suất lớn nhất của mỗi từ sinh ra tại bước mã hóa. Hình 2.10 minh họa một mô hình seq2seq được thực thi với bộ mã hóa và giải mã sử dụng mạng RNN.