1.4. Các phương pháp tóm tắt văn bản hướng trích rút cơ sở
1.4.1. PageRank
PageRank [15] là thuật toán được sử dụng trong công cụ tìm kiếm của Google (Google Search). Về bản chất PageRank là phân bố xác suất, được sử dụng để biểu diễn khả năng khi một người bấm chuột ngẫu nhiên vào liên kết và sẽ dẫn tới trang Website đó. PageRank được tính theo công thức sau:
PageRank( p ) 1dd
PageRank( pj )
(1.23)
i N L( p )
p j M ( pi ) j
trong đó:
- N là tổng số trang.
- M ( pi ) là tập hợp các trang liên kết đến pi.
- d là hằng số (thông thường d được chọn bằng 0,85).
- PageRank( pi ) : là PageRank của pi.
- L( pj ) : là số lượng các liên kết trỏ ra trong pj.
1.4.2. TextRank
TextRank [14] là một thuật toán tóm tắt văn bản trích rút theo hướng tiếp cận không giám sát dựa trên đồ thị, được xây dựng dựa trên thuật toán PageRank. TextRank coi mỗi câu là một đỉnh trong đồ thị thay vì mỗi đỉnh là một trang Website như trong thuật toán PageRank và tính độ tương đồng giữa hai câu dựa vào số từ trùng của 2 câu. Sau đó, đưa ra một ngưỡng để chọn ra số câu liên quan của từng câu.
1.4.3. LexRank
LexRank [11] là một hướng tiếp cận không giám sát, trong đó sử dụng ý tưởng của thuật toán PageRank để xác định tầm quan trọng của các câu trong văn bản. LexRank sử dụng độ đo Cosine của các véc tơ tf-idf để xác định trọng số của một câu như sau:
tf tf idf 2
tf idf
Cosine(x, y)
wx, y w ,x w , y w
(1.24)
xi x
tf
xi ,x xi
idf
2
yi y
tf
yi , y yi
idf
2
trong đó:
- x, y: là hai câu cần đo độ tương đồng.
- tfw,x : là tần suất xuất hiện của từ w trong câu x.
- tfw, y : là tần suất xuất hiện của từ w trong câu y.
- idfw : là độ quan trọng của từ w.
Công thức này biểu diễn khoảng cách giữa hai câu x và y. Phép đo độ tương đồng này được sử dụng để xây dựng ma trận tương đồng là đồ thị tương đồng giữa các câu. LexRank đo lường độ quan trọng của các câu trong đồ thị bằng cách xem xét tầm quan trọng tương đối của nó với các câu lân cận. Để trích rút các câu quan
trọng nhất từ ma trận tương đồng, cần sử dụng một giá trị ngưỡng. Một giá trị ngưỡng được sử dụng để lọc ra các mối quan hệ giữa các câu có trọng số nhỏ hơn ngưỡng. Kết quả là một tập con của đồ thị tương đồng ban đầu và ta có thể chọn các nút có trọng số cao nhất. Một nút được chọn sẽ đại diện cho một câu tóm tắt của văn bản.
1.4.4. Lead-Based
Trong văn bản là tin tức, các câu ở đầu văn bản thường sẽ mang nhiều ý nghĩa quan trọng. Phương pháp Lead-k [6] chỉ đơn giản là lấy k (k: nguyên, dương) câu đầu tiên trong văn bản làm bản tóm tắt. Đây là phương pháp tóm tắt đơn giản nhưng có độ chính xác khá cao nên các nghiên cứu tóm tắt văn bản dạng tin tức thường chọn phương pháp Lead-k làm phương pháp cơ sở để đánh giá so sánh.
1.5. Các bộ dữ liệu thử nghiệm
Để có cơ sở lựa chọn số lượng câu hoặc số từ cho bản tóm tắt sinh ra của các mô hình tóm tắt đề xuất, các bộ dữ liệu sử dụng để thử nghiệm cho các mô hình đề xuất được phân tích thống kê các thông tin quan trọng và được trình bày như dưới đây. Thông tin về thời gian thu thập các bộ dữ liệu thử nghiệm và biểu đồ biểu diễn phân bố độ dài trung bình nội dung văn bản nguồn, văn bản bản tóm tắt tương ứng theo số câu, số từ của các bộ dữ liệu được trình bày chi tiết ở Phụ lục B trong phần Phụ lục.
1.5.1. Các bộ dữ liệu văn bản tiếng Anh
1.5.1.1. Bộ dữ liệu CNN/Daily Mail
Bộ dữ liệu CNN/Daily Mail [71] gồm 312.085 bài báo tin tức (trong đó bộ CNN có 92.579 bài báo tin tức, bộ Daily Mail có 219.506 bài báo tin tức) được thu thập từ các báo CNN và Daily Mail, mỗi bài báo có các câu chính (highlights) đi kèm do người viết bài báo tự viết được sử dụng làm bản tóm tắt tham chiếu. Luận án sử dụng phương pháp phân chia bộ dữ liệu của Hermann và cộng sự [71] cho các tập dữ liệu huấn luyện, kiểm tra và đánh giá khi thử nghiệm các mô hình (Bảng 1.3). Các câu chính của mỗi văn bản được sử dụng làm cơ sở để đánh giá chất lượng bản tóm tắt của các mô hình thử nghiệm.
CNN | Daily Mail | |||||
Huấn luyện | Kiểm tra | Đánh giá | Huấn luyện | Kiểm tra | Đánh giá | |
Số lượng văn bản | 90.266 | 1.220 | 1.093 | 196.961 | 12.148 | 10.397 |
Kích thước từ vựng | 118.497 | 208.045 |
Có thể bạn quan tâm!
-

 Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 2
Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 2 -
 Ý Nghĩa Khoa Học Và Ý Nghĩa Thực Tiễn
Ý Nghĩa Khoa Học Và Ý Nghĩa Thực Tiễn -
 Ví Dụ Minh Họa Một Văn Bản Tóm Tắt Của Văn Bản Tiếng Anh
Ví Dụ Minh Họa Một Văn Bản Tóm Tắt Của Văn Bản Tiếng Anh -
![Một Kiến Trúc Cnn Cho Bài Toán Phân Loại Ảnh [84]](https://tailieuthamkhao.com/uploads/2022/06/10/nghien-cuu-phat-trien-mot-so-phuong-phap-tom-tat-van-ban-su-dung-ky-6-1-120x90.jpg) Một Kiến Trúc Cnn Cho Bài Toán Phân Loại Ảnh [84]
Một Kiến Trúc Cnn Cho Bài Toán Phân Loại Ảnh [84] -
 Các Mô Hình Ngôn Ngữ Dựa Trên Học Sâu Được Huấn Luyện Trước
Các Mô Hình Ngôn Ngữ Dựa Trên Học Sâu Được Huấn Luyện Trước -
![Mô Hình Biểu Diễn Các Bước Chưng Cất Được Huấn Luyện Trước Của Các Mô Hình Bert Thu Nhỏ [111]](https://tailieuthamkhao.com/uploads/2022/06/10/nghien-cuu-phat-trien-mot-so-phuong-phap-tom-tat-van-ban-su-dung-ky-8-1-120x90.jpg) Mô Hình Biểu Diễn Các Bước Chưng Cất Được Huấn Luyện Trước Của Các Mô Hình Bert Thu Nhỏ [111]
Mô Hình Biểu Diễn Các Bước Chưng Cất Được Huấn Luyện Trước Của Các Mô Hình Bert Thu Nhỏ [111]
Xem toàn bộ 185 trang tài liệu này.
Bảng 1.3. Phương pháp phân chia bộ dữ liệu CNN/Daily Mail
Bảng 1.4 là các thông tin thống kê tóm tắt của hai bộ dữ liệu CNN và Daily Mail theo số lượng câu và số lượng từ.
CNN | Daily Mail | ||
Văn bản nguồn | Số lượng câu trung bình | 31,86 | 26,24 |
Số lượng từ trung bình | 643,79 | 680,86 | |
Khoảng phân bố theo số câu | 14 19 | 13 40 | |
Khoảng phân bố theo số từ | 316 971 | 369 991 | |
Văn bản tóm tắt | Số lượng câu trung bình | 3,55 | 3,78 |
Số lượng từ trung bình | 41,67 | 50,44 | |
Khoảng phân bố theo số câu | 2 4 | 2 4 | |
Khoảng phân bố theo số từ | 32 50 | 30 70 |
Bảng 1.4. Thống kê các thông tin của hai bộ dữ liệu CNN và Daily Mail
Bộ dữ liệu này được sử dụng để thử nghiệm cho các mô hình tóm tắt đơn văn bản tiếng Anh hướng trích rút và hướng tóm lược đề xuất.
1.5.1.2. Bộ dữ liệu DUC 2001 và DUC 2002
Hai bộ dữ liệu DUC 2001 [72] và DUC 2002 [73] được công bố bởi tổ chức NIST tại Hội thảo DUC. Các bộ dữ liệu này có thể sử dụng cho tóm tắt đơn văn bản và tóm tắt đa văn bản (gồm tóm tắt hướng trích rút và hướng tóm lược).
Bộ dữ liệu DUC 2001 gồm 297 văn bản nguồn được tổ chức thành 30 cụm, mỗi cụm bao gồm tập các văn bản nguồn, các bản tóm tắt khác nhau sử dụng cho tóm tắt đa văn bản (mỗi bản tóm tắt có độ dài được cố định lần lượt là 50, 100, 200 và 400 từ) và 1 bản tóm tắt sử dụng cho tóm tắt đơn văn bản có độ dài 100 từ. Bộ dữ liệu DUC 2002 gồm 567 văn bản nguồn được tổ chức thành 60 cụm, mỗi cụm bao gồm tập các văn bản nguồn, các bản tóm tắt khác nhau sử dụng cho tóm tắt đa văn bản (mỗi bản tóm tắt có độ dài được cố định lần lượt là 10, 50, 100, 200 và 400 từ) và 1 bản tóm tắt sử dụng cho tóm tắt đơn văn bản có độ dài 100 từ.
Luận án chỉ sử dụng 2 bộ dữ liệu này để thử nghiệm tóm tắt đơn văn bản hướng trích rút nên luận án sẽ đi phân tích thống kê các thông tin của văn bản nguồn, bản tóm tắt sử dụng cho tóm tắt đơn văn bản. Bảng 1.5 dưới đây là các thông tin thống kê của hai bộ dữ liệu theo số lượng câu và số lượng từ.
DUC 2001 | DUC 2002 | ||
Văn bản nguồn | Số lượng câu trung bình | 41.51 | 26,41 |
Số lượng từ trung bình | 887.12 | 534,71 | |
Khoảng phân bố theo số câu | 15 68 | 13 40 | |
Khoảng phân bố theo số từ | 321 1.453 | 278 791 | |
Văn bản tóm tắt | Số lượng câu trung bình | 4,69 | 5,30 |
Số lượng từ trung bình | 92,47 | 99,65 | |
Khoảng phân bố theo số câu | 3 6 | 4 7 | |
Khoảng phân bố theo số từ | 85 99 | 95 105 |
Bảng 1.5. Thống kê các thông tin tóm tắt của bộ dữ liệu DUC 2001 và DUC 2002 sử dụng cho tóm tắt đơn văn bản
Hai bộ dữ liệu này sẽ được sử dụng để thử nghiệm cho mô hình tóm tắt đơn văn bản tiếng Anh hướng trích rút đề xuất.
1.5.1.3. Bộ dữ liệu DUC 2004
Bộ dữ liệu DUC 2004 [74] được phát triển bởi tổ chức NIST gồm 50 cụm văn bản, mỗi cụm có trung bình 10 văn bản và có 4 bản tóm tắt đi kèm do các chuyên gia của NIST tạo ra.
Bảng 1.6 là các thông tin thống kê tóm tắt của bộ dữ liệu DUC 2004 theo số lượng câu và số lượng từ trên toàn bộ bộ dữ liệu.
Số lượng câu trung bình | Số từ trung bình | Khoảng phân bố theo số câu | Khoảng phân bố theo số từ | |
Văn bản nguồn | 25,45 | 564,12 | 11 41 | 211 917 |
Văn bản tóm tắt | 6,54 | 104,43 | 4 8 | 99 109 |
Bảng 1.6. Thống kê các thông tin tóm tắt của bộ dữ liệu DUC 2004
Bộ dữ liệu này sẽ được sử dụng để thử nghiệm cho mô hình tóm tắt đa văn bản tiếng Anh hướng tóm lược đề xuất.
1.5.1.4. Bộ dữ liệu DUC 2007
Bộ dữ liệu DUC 2007 [75] gồm hai tập dữ liệu là: Main task và Update task (pilot):
- Main task: Bao gồm 45 chủ đề, trong đó mỗi chủ đề nằm trong một thư mục riêng biệt. Mỗi chủ đề có trung bình 25 văn bản liên quan dưới dạng 25 tập tin, đi kèm với mỗi chủ đề là 4 bản tóm tắt khác nhau đến từ 4 đơn vị đánh giá NIST. Mỗi bản tóm tắt thể hiện đầy đủ thông tin của mỗi chủ đề. Các bản tóm tắt này sẽ được sử dụng để đánh giá chất lượng bản tóm tắt của các mô hình thử nghiệm.
- Update task (pilot): Khác với tập dữ liệu Main task, mỗi bản tóm tắt trong Update task chỉ chứa khoảng 100 từ với giả định rằng người dùng đã đọc qua một số văn bản trước đó rồi. Update task có xấp xỉ 10 chủ đề, mỗi chủ đề chứa 25 văn bản. Với mỗi chủ đề, các văn bản được sắp xếp theo trình tự thời gian và sau đó được phân chia thành 3 tập A, B và C. Trong 25 văn bản của mỗi chủ đề, có xấp xỉ 10 văn bản cho tập A, 8 văn bản cho tập B và 7 văn bản cho tập C.
Bảng 1.7 là các thông tin thống kê tóm tắt của tập dữ liệu Main task của bộ dữ liệu DUC 2007 theo số lượng câu và số lượng từ trên toàn bộ bộ dữ liệu.
Số lượng câu trung bình | Số từ trung bình | Khoảng phân bố theo số câu | Khoảng phân bố theo số từ | |
Văn bản nguồn | 20,78 | 421,84 | 4 36 | 114 728 |
Văn bản tóm tắt | 13,08 | 243,75 | 10 16 | 231 255 |
Bảng 1.7. Thống kê các thông tin tóm tắt của tập dữ liệu Main task của bộ dữ liệu DUC 2007
Bộ dữ liệu này sẽ được sử dụng để thử nghiệm các mô hình tóm tắt đa văn bản tiếng Anh hướng trích rút và hướng tóm lược đề xuất.
1.5.2. Các bộ dữ liệu văn bản tiếng Việt
1.5.2.1. Bộ dữ liệu Baomoi
Bộ dữ liệu cho tóm tắt văn bản tiếng Việt có tên là ‘Baomoi’. Bộ dữ liệu này được tạo ra bằng cách thu thập các bài báo từ trang báo điện tử Việt Nam (http://baomoi.com). Mỗi bài báo bao gồm ba phần: Tiêu đề, tóm tắt và bài báo. Do chưa có nguồn dữ liệu nào tốt hơn nên bộ dữ liệu Baomoi là lựa chọn tốt được sử dụng làm bộ dữ liệu thử nghiệm cho các mô hình tóm tắt đơn văn bản tiếng Việt vào thời điểm này. Bộ dữ liệu Baomoi có xấp xỉ 4GB dữ liệu bao gồm 1.000.847 văn bản (trong đó: 900.847 mẫu được sử dụng để huấn luyện, 50.000 mẫu để kiểm tra và 50.000 mẫu để đánh giá), được chia thành 1.000 bản ghi, mỗi bản ghi gồm hơn 1.000 văn bản được tách nhau bởi kí tự ‘#‘. Mỗi văn bản có cấu trúc gồm 3 phần:
- Phần tiêu đề: là đoạn đầu tiên, gồm 1 câu ngắn.
- Phần tóm tắt: là đoạn kế tiếp, gồm từ 1 đến 2 câu dài.
- Phần nội dung: là đoạn cuối cùng.
Phần nội dung và phần tóm tắt tương ứng được sử dụng làm văn bản nguồn và bản tóm tắt cho bài toán tóm tắt văn bản. Các phần này được sử dụng để huấn luyện và đánh giá độ chính xác cho các mô hình thử nghiệm.
Bảng 1.8 là các thông tin thống kê tóm tắt của bộ dữ liệu Baomoi theo số lượng câu và số lượng từ trên toàn bộ bộ dữ liệu.
Số lượng câu trung bình | Số từ trung bình | Khoảng phân bố theo số câu | Khoảng phân bố theo số từ | |
Văn bản nguồn | 11,56 | 532,65 | 3 20 | 145 920 |
Văn bản tóm tắt | 1,28 | 38,90 | 1 2 | 22 55 |
Bảng 1.8. Thống kê các thông tin tóm tắt của bộ dữ liệu Baomoi
Bộ dữ liệu Baomoi được sử dụng để thử nghiệm cho các mô hình tóm tắt đơn văn bản tiếng Việt hướng trích rút và hướng tóm lược đề xuất của luận án.
1.5.2.2. Bộ dữ liệu 200 cụm
Bộ dữ liệu [76] gồm 200 cụm (trong luận án sẽ gọi là bộ dữ liệu Corpus_TMV), mỗi cụm dữ liệu bao gồm từ 2 đến 5 văn bản, trung bình 3,16 văn bản, 2 bản tóm tắt. Bộ dữ liệu được tạo thủ công bởi con người, trong đó việc xây dựng bộ dữ liệu được nhóm tác giả xử lý gồm hai bước:
- Thu thập và phân cụm các văn bản: Dữ liệu được thu thập từ trang baomoi.com và được phân bố trên khoảng từ 8 đến 10 chủ đề gồm thế giới, xã hội, văn hóa, khoa học và công nghệ, kinh tế, giải trí, thể thao, giáo dục, pháp luật, sức khỏe.
- Sinh bản tóm tắt: Bản tóm tắt cho các cụm văn bản được xây dựng bởi hai cộng tác viên độc lập.
Bảng 1.9 là các thông tin thống kê tóm tắt của bộ dữ liệu Corpus_TMV theo số lượng câu và số lượng từ trên toàn bộ bộ dữ liệu.
Số lượng câu trung bình | Số từ trung bình | Khoảng phân bố theo số câu | Khoảng phân bố theo số từ | |
Văn bản nguồn | 14,86 | 477,95 | 5 23 | 168 786 |
Văn bản tóm tắt | 4,71 | 178,56 | 3 6 | 125 231 |
Bảng 1.9. Thống kê các thông tin tóm tắt của bộ dữ liệu Corpus_TMV
Bộ dữ liệu này sẽ được sử dụng để thử nghiệm cho các mô hình tóm tắt đa văn bản tiếng Việt hướng trích rút và hướng tóm lược đề xuất.
1.5.2.3. Bộ dữ liệu ViMs
Bộ dữ liệu ViMs [77] gồm 300 cụm, mỗi cụm có trung bình 6,48 văn bản, số lượng văn bản trong mỗi cụm nằm trong khoảng từ 4 đến 10 văn bản cùng chủ đề và 2 bản tóm tắt tương ứng được tạo bởi 2 người khác nhau bảo đảm chất lượng bản tóm tắt tốt nhất có thể. Bộ dữ liệu được tạo thủ công bởi con người, trong đó việc xây dựng bộ dữ liệu được nhóm tác giả xử lý gồm hai bước:
- Thu thập và phân cụm các văn bản: Dữ liệu được nhóm tác giả thu thập từ trang news.google.com (Google News) tiếng Việt, nhóm tác giả chỉ thu thập từ các nguồn mở thay vì toàn bộ nguồn từ Google News (vì lý do bản quyền). Các văn bản thu thập gồm các chủ đề: thế giới, kinh tế, tin tức trong nước, giải trí, thể thao.
- Sinh bản tóm tắt: Hai người tóm tắt với sự hỗ trợ của phần mềm MDSWriter
[78] tạo ra bản tóm tắt cho các cụm văn bản đã thu thập.
Bảng 1.10 là các thông tin thống kê tóm tắt của bộ dữ liệu ViMs theo số lượng câu và số lượng từ trên toàn bộ bộ dữ liệu.
Số lượng câu trung bình | Số từ trung bình | Khoảng phân bố theo số câu | Khoảng phân bố theo số từ | |
Văn bản nguồn | 12,54 | 390,45 | 5 19 | 165 615 |
Văn bản tóm tắt | 5,35 | 220,94 | 3 7 | 144 296 |
Bảng 1.10. Thống kê các thông tin tóm tắt của bộ dữ liệu ViMs
Bộ dữ liệu này sẽ được sử dụng để thử nghiệm cho các mô hình tóm tắt đa văn bản tiếng Việt hướng trích rút và hướng tóm lược đề xuất.
1.6. Kết luận chương 1
Với mục tiêu của đề tài, chương này đã trình bày một số kiến thức cơ sở liên quan đến đề tài nghiên cứu như sau:
- Tổng quan về bài toán tóm tắt văn bản và một số vấn đề liên quan như phân loại bài toán tóm tắt văn bản gồm tóm tắt đơn văn bản, tóm tắt đa văn bản, tóm tắt văn bản hướng trích rút, tóm tắt văn bản hướng tóm lược, các bước thực hiện trong tóm tắt văn bản, một số đặc trưng của văn bản thường được sử dụng trong các hệ thống tóm tắt văn bản. Các vấn đề này đã mở ra định hướng nghiên cứu cho luận án.
- Một số phương pháp đánh giá văn bản tóm tắt tự động.
- Các phương pháp ghép văn bản trong tóm tắt đa văn bản.
- Các phương pháp tóm tắt văn bản hướng trích rút cơ sở được sử dụng để so sánh với các mô hình tóm tắt văn bản đề xuất.
- Cuối cùng, luận án giới thiệu và phân tích các bộ dữ liệu được sử dụng để thử nghiệm cho các mô hình tóm tắt văn bản đề xuất.
Các kiến thức cơ sở liên quan trong chương 1 được trình bày trong các công trình nghiên cứu đã công bố của luận án. Các kiến thức trình bày trong chương này là cơ sở để đề xuất và phát triển các nghiên cứu của luận án. Trong chương 2, luận án sẽ trình bày các kiến thức nền tảng được sử dụng để phát triển các phương pháp tóm tắt văn bản đề xuất.
Chương 2. CÁC KIẾN THỨC NỀN TẢNG
Chương này trình bày các kiến thức nền tảng sử dụng để phát triển các phương pháp tóm tắt văn bản trong luận án bao gồm các kỹ thuật học sâu cơ sở như mạng Perceptron nhiều lớp, mạng nơ ron tích chập, mạng nơ ron hồi quy và các biến thể của mạng nơ ron hồi quy, cơ chế chú ý, mô hình Transformer, các mô hình ngôn ngữ dựa trên học sâu được huấn luyện trước như phương pháp word2vec, mô hình BERT, BERT đa ngôn ngữ, các mô hình tối ưu của BERT, BERT thu nhỏ để véc tơ hóa văn bản. Chương này cũng trình bày các thuật toán được sử dụng trong các mô hình tóm tắt đề xuất như học tăng cường Deep Q-Learning, tìm kiếm Beam, phương pháp MMR loại bỏ thông tin trùng lặp. Những kiến thức trình bày trong chương này là cơ sở cho việc phát triển các đề xuất trong các chương tiếp theo.
2.1. Các kỹ thuật học sâu cơ sở
2.1.1. Mạng Perceptron nhiều lớp
Mạng MLP là mạng nơ ron có một hoặc nhiều lớp ẩn thường được sử dụng trong các bài toán phân loại. Kiến trúc mạng MLP đơn giản nhất là mạng truyền thẳng. Hình 2.1 minh họa mô hình mạng MLP một lớp ẩn và mạng MLP nhiều lớp ẩn:
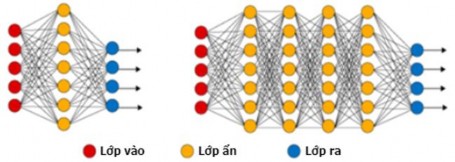
Hình 2.1. Mô hình mạng MLP một lớp ẩn và nhiều lớp ẩn [79]
Khi mạng nơ ron có nhiều lớp thì thời gian tính toán sẽ tăng lên đáng kể nên mạng MLP thường được huấn luyện bởi giải thuật lan truyền ngược (Back Propagation Algorithm) [80] để giảm thời gian huấn luyện. Mạng MLP với kiến trúc mạng linh hoạt đã đạt được độ hiệu quả cao trong các bài toán về xử lý văn bản, ảnh, video. Kiến trúc của mạng thường được xây dựng dựa vào kinh nghiệm thực tế và thực nghiệm.