3.3.3.2. Tiền xử lý dữ liệu
Trước hết, các bộ dữ liệu CNN và Baomoi xử lý tách riêng phần tiêu đề, phần nội dung, phần tóm tắt và đánh số thứ tự cho các câu. Các bộ dữ liệu tiếng Anh (DUC 2001, DUC 2002 và CNN) được xử lý tách câu sử dụng thư viện nltk13, bộ dữ liệu Baomoi được xử lý tách câu sử dụng thư viện VnCoreNLP. Sau đó, các câu của mỗi bộ dữ liệu được gán nhãn dựa vào tối đa tổng R-2 và R-L (vì thực nghiệm cho độ chính xác tốt hơn so với tối đa tổng R-1 và R-2) sử dụng thư viện rouge-
score 0.0.4.
3.3.3.3. Thiết kế thử nghiệm
a) Thử nghiệm mô hình công bố trên các bộ dữ liệu DUC 2001 và DUC 2002
Trước hết, luận án thử nghiệm lại mô hình trong [129] trên 2 bộ dữ liệu DUC 2001 and DUC 2002 (bộ dữ liệu DUC 2001 sử dụng để huấn luyện, bộ DUC 2002 sử dụng để đánh giá mô hình) để ghi nhận các kết quả của mô hình đã công bố trong cùng điều kiện hạ tầng cơ sở thử nghiệm với mô hình đề xuất vì đây là mô hình tóm tắt giống với mô hình tóm tắt đề xuất. Các kết quả độ đo R-1, R-2 thu được tương ứng là 41,83%, 16,78% (mô hình trong [129] không đánh giá độ đo R-L nên luận án không ghi nhận lại kết quả độ đo R-L khi thử nghiệm).
b) Thử nghiệm các mô hình xây dựng
Luận án triển khai xây dựng bốn mô hình để lựa chọn mô hình tóm tắt văn bản đề xuất. Mô hình ban đầu với việc sử dụng mô hình mBERT được huấn luyện trước để véc tơ hóa văn bản đầu vào (mô hình mBERT hỗ trợ cho cả tiếng Anh và tiếng Việt), mạng CNN để trích rút các đặc trưng của câu, lớp FC để tính toán xác suất các câu được chọn và đặc trưng TF-IDF. Chi tiết các mô hình như sau đây.
(i) Mô hình 1 (mBERT + CNN + FC + TF-IDF): Sử dụng mô hình mBERT kết hợp với mạng CNN, lớp FC và đặc trưng TF-IDF để huấn luyện mô hình tính xác suất được chọn của các câu đưa vào bản tóm tắt.
(ii) Mô hình 2 (mBERT + CNN + Encoder-Decoder + FC+TF-IDF): Mô hình 1 kết hợp với bộ Encoder-Decoder để liên kết các câu trong cùng một văn bản nhằm đánh giá hiệu quả của việc sử dụng kết hợp bộ Encoder-Decoder trong mô hình.
(iii) Mô hình 3 (mBERT + CNN + FC + TF-IDF + MMR): Mô hình 1 kết hợp với phương pháp MMR để loại bỏ các thông tin trùng lặp để đánh giá hiệu quả của việc sử dụng phương pháp MMR trong mô hình (mô hình này được xây dựng sử dụng mô hình 1 để giảm độ phức tạp cho mô hình).
(iv) Mô hình 4 (mBERT + CNN + Encoder-Decoder + FC + TF-IDF + MMR):
Mô hình 2 kết hợp với phương pháp MMR để loại bỏ các thông tin trùng lặp.
Các mô hình này được thử nghiệm trên bộ dữ liệu CNN để lựa chọn mô hình tốt nhất làm mô hình tóm tắt văn bản đề xuất. Các mô hình được huấn luyện sử dụng Google Colab với cấu hình máy chủ 25GB RAM, GPU V100 được cung cấp bởi hãng Google. Các mô hình này được huấn luyện với hệ số học khởi tạo ban đầu là 2.10-3 qua 10 epoch, batch size là 32, thời gian huấn luyện xấp xỉ 29 tiếng (với bộ dữ liệu CNN) và xấp xỉ 63 tiếng (với bộ dữ liệu Baomoi). Sau mỗi epoch, hệ số học sẽ được tự động giảm 10% sử dụng cơ chế scheduling của thư viện PyTorch cho
đến epoch cuối cùng.
13 https://www.nltk.org/
Các kết quả thử nghiệm của các mô hình thu được như ở Bảng 3.7 dưới đây.
CNN | |||
R-1 | R-2 | R-L | |
Mô hình 1 (mBERT + CNN + FC + TF-IDF) | 31,62 | 12,01 | 28,57 |
Mô hình 2 (mBERT + CNN + Encoder-Decoder + FC + TF-IDF) | 31,95 | 12,69 | 28,76 |
Mô hình 3 (mBERT + CNN + FC + TF-IDF + MMR) | 32,54 | 12,60 | 29,52 |
Mô hình 4 (mBERT + CNN + Encoder-Decoder + FC + TF-IDF + MMR) | 32,67 | 13,04 | 29,53 |
Có thể bạn quan tâm!
-
![Mô Hình Biểu Diễn Các Bước Chưng Cất Được Huấn Luyện Trước Của Các Mô Hình Bert Thu Nhỏ [111]](https://tailieuthamkhao.com/uploads/2022/06/10/nghien-cuu-phat-trien-mot-so-phuong-phap-tom-tat-van-ban-su-dung-ky-8-1-120x90.jpg)
![Mô Hình Biểu Diễn Các Bước Chưng Cất Được Huấn Luyện Trước Của Các Mô Hình Bert Thu Nhỏ [111]](data:image/svg+xml,%3Csvg%20xmlns=%22http://www.w3.org/2000/svg%22%20viewBox=%220%200%2075%2075%22%3E%3C/svg%3E) Mô Hình Biểu Diễn Các Bước Chưng Cất Được Huấn Luyện Trước Của Các Mô Hình Bert Thu Nhỏ [111]
Mô Hình Biểu Diễn Các Bước Chưng Cất Được Huấn Luyện Trước Của Các Mô Hình Bert Thu Nhỏ [111] -
 Phát Triển Các Phương Pháp Tóm Tắt Đơn Văn Bản Hướng Trích Rút
Phát Triển Các Phương Pháp Tóm Tắt Đơn Văn Bản Hướng Trích Rút -
 Kết Quả Thử Nghiệm Một Số Phương Pháp Tóm Tắt Văn Bản Cơ Sở. Ký Hiệu ‘*’ Thể Hiện Phương Pháp Được Triển Khai Thử Nghiệm Trên Các Bộ
Kết Quả Thử Nghiệm Một Số Phương Pháp Tóm Tắt Văn Bản Cơ Sở. Ký Hiệu ‘*’ Thể Hiện Phương Pháp Được Triển Khai Thử Nghiệm Trên Các Bộ -
 Giá Trị Các Siêu Tham Số Và Thời Gian Huấn Luyện Các Mô Hình Xây Dựng
Giá Trị Các Siêu Tham Số Và Thời Gian Huấn Luyện Các Mô Hình Xây Dựng -
![Mô Hình Tóm Tắt Đơn Văn Bản Hướng Tóm Lược Cơ Sở [128]](https://tailieuthamkhao.com/uploads/2022/06/10/nghien-cuu-phat-trien-mot-so-phuong-phap-tom-tat-van-ban-su-dung-ky-13-1-120x90.jpg) Mô Hình Tóm Tắt Đơn Văn Bản Hướng Tóm Lược Cơ Sở [128]
Mô Hình Tóm Tắt Đơn Văn Bản Hướng Tóm Lược Cơ Sở [128] -
 Mẫu Tóm Tắt Gồm Bản Tóm Tắt Tham Chiếu, Bản Tóm Tắt Của Mô Hình Trong
Mẫu Tóm Tắt Gồm Bản Tóm Tắt Tham Chiếu, Bản Tóm Tắt Của Mô Hình Trong
Xem toàn bộ 185 trang tài liệu này.
Bảng 3.7. Các kết quả thử nghiệm của các mô hình xây dựng
Với các kết quả thử nghiệm của các mô hình xây dựng, có thể thấy mô hình tóm tắt văn bản sử dụng mBERT, CNN, lớp FC và đặc trưng TF-IDF (mô hình 1) đã cho kết quả khả quan và tốt hơn các phương pháp như LexRank, TextRank, LEAD trên cùng bộ dữ liệu CNN (Bảng 3.1). Trong mô hình 2, bộ Encoder-Decoder được kết hợp vào mô hình đã cho kết quả tốt hơn (các độ đo R-1, R-2 và R-L tương ứng tăng lần lượt là 0,33%; 0,68% và 0,16%). Trong mô hình 3, việc kết hợp MMR vào mô hình 1 để loại bỏ thông tin dư thừa trong bản tóm tắt đã cho kết quả tốt hơn so với mô hình 1, thậm chí kết quả R-1, R-L cũng tốt hơn so với mô hình 2. Trong mô hình 4, với việc kết hợp MMR vào mô hình 2 đã cho kết quả tốt hơn so với mô hình
2. Những điều này cho thấy việc sử dụng bộ Encoder-Decoder, đặc trưng TF-IDF, kết hợp phương pháp MMR đã làm tăng hiệu quả cho mô hình tóm tắt. Các kết quả thử nghiệm trong Bảng 3.7 cho thấy vai trò quan trọng của đặc trưng TF-IDF, bộ Decoder-Encoder, MMR trong mô hình tóm tắt văn bản. Các kết quả này chứng tỏ mô hình tóm tắt văn bản đề xuất sử dụng mBERT, CNN, Decoder-Encoder, FC, đặc trưng TF-IDF và MMR (mô hình 4) cho các kết quả tốt hơn rò rệt so với các mô hình còn lại, do đó mô hình 4 được chọn làm mô hình tóm tắt đề xuất.
c) Thử nghiệm mô hình đề xuất trên bộ dữ liệu DUC 2001 và DUC 2002
Tiếp theo, mô hình đề xuất được triển khai thử nghiệm trên hai bộ dữ liệu DUC 2001 và DUC 2002 để đánh giá và so sánh hiệu quả của mô hình đề xuất với các mô hình hiện đại khác trên cùng các bộ dữ liệu (bộ dữ liệu DUC 2001 được sử dụng để huấn luyện, bộ dữ liệu DUC 2002 được sử dụng để đánh giá mô hình). Các kết quả độ đo R-1, R-2 và R-L thu được tương ứng là 48,29%; 23,40% và 43,80%. Bảng 3.8 dưới đây trình bày kết quả thử nghiệm của mô hình đề xuất và các mô hình hiện đại khác trên hai bộ dữ liệu DUC 2001 and DUC 2002. Các kết quả trong bảng này cho thấy mô hình đề xuất hiệu quả hơn so với các mô hình còn lại.
DUC 2001/DUC 2002 | |||
R-1 | R-2 | R-L | |
Laugier và cộng sự [129] | 42,48 | 16,96 | - |
Laugier và cộng sự [129]* | 41,83 | 16,78 | - |
mBERT+CNN+Encoder-Decoder+FC+TF- IDF+MMR | 48,29 | 23,40 | 43,80 |
Bảng 3.8. Kết quả thử nghiệm các phương pháp trên bộ dữ liệu DUC 2001 và DUC 2002. Ký hiệu ‘*’, ‘-’ biểu diễn các phương pháp được thử nghiệm, không được thử nghiệm trên các bộ dữ liệu tương ứng
d) Thử nghiệm mô hình đề xuất trên bộ dữ liệu Baomoi
Cuối cùng, mô hình đề xuất được thử nghiệm trên bộ dữ liệu Baomoi cho tóm tắt tiếng Việt, các kết quả độ đo R-1, R-2 và R-L thu được lần lượt là 54,67%; 25,26% và 37,48%. Các kết quả thử nghiệm cho thấy mô hình đề xuất hiệu quả hơn so với các mô hình đã thử nghiệm cho tóm tắt văn bản tiếng Việt trên cùng bộ dữ liệu Baomoi trong Bảng 3.1 ở trên, đồng thời cũng chỉ ra rằng mô hình đề xuất có thể áp dụng hiệu quả cho tóm tắt văn bản tiếng Việt.
Bảng 3.9 biểu diễn một mẫu tóm tắt gồm bản tóm tắt tham chiếu của con người và bản tóm tắt đầu ra của mô hình đề xuất mBERT_CNN_ESDS trên bộ dữ liệu CNN. Văn bản nguồn của mẫu tóm tắt này xem Phụ lục C.2trong phần Phụ lục.
Bản tóm tắt của mô hình đề xuất mBERT_CNN_ESDS Panama City, Panama (CNN) Ending a decades-long standstill in U.S.-Cuba relations, President Barack Obama met for an hour Saturday with his Cuban counterpart Raul Castro, the first time the two nations' top leaders have sat down for substantive talks in more than 50 years. The meeting in a small conference room on the sidelines of the Summit of the Americas came as the two countries work to end the Cold War enmity that had led to a total freeze of diplomatic ties. "The Cold War has been over for a long time," Obama said during opening remarks at the summit Saturday. |
Bảng 3.9. Một mẫu tóm tắt trên bộ dữ liệu CNN
Bảng 3.10 biểu diễn một mẫu tóm tắt gồm bản tóm tắt tham chiếu của con người và bản tóm tắt đầu ra của mô hình đề xuất mBERT_CNN_ESDS trên bộ dữ liệu Baomoi. Văn bản nguồn của mẫu tóm tắt này xem Phụ lục C.2trong phần Phụ lục.
Bản tóm tắt của hệ thống mBERT_CNN_ESDS Theo đó, vào khoảng thời gian trên, khi chiếc xe con mang BKS: 37A-048.45 đang điều khiển xe lưu thông theo hướng Bắc - Nam bất ngờ lao lên dải phân cách làn đường ô tô và xe máy. Các nhân viên của trạm soát vé cầu Bến Thuỷ đã phải ra điều tiết giao thông, tránh ùn tắc nghiêm trọng trên tuyến đường. |
Bảng 3.10. Một mẫu tóm tắt trên bộ dữ liệu Baomoi
Từ các kết quả thử nghiệm trên, có thể thấy mô hình tóm tắt đơn văn bản hướng trích rút đề xuất mBERT_CNN_ESDS đã đạt được hiệu quả cao cho tóm tắt văn bản tiếng Anh và tiếng Việt.
3.3.4. Đánh giá và so sánh kết quả
Kết qủa thử nghiệm của mô hình đề xuất được đánh giá và so sánh với kết quả của các phương pháp đã thử nghiệm và các phương pháp hiện đại khác đã công bố trên cùng các bộ dữ liệu tương ứng. Bảng 3.11 dưới đây là kết quả đánh giá so sánh hiệu quả của các phương pháp và mô hình đề xuất.
CNN | Baomoi | |||||
R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
LexRank* | 22,9 | 6,6 | 17,2 | 38,5 | 17,0 | 28,9 |
TextRank* | 26,0 | 7,3 | 19,2 | 44,7 | 19,2 | 32,9 |
LEAD* | 29,0 | 10,7 | 19,3 | 46,5 | 20,3 | 30,8 |
Cheng and Lapata [125] | 28,4 | 10,0 | 25,0 | - | - | - |
LEAD [125] | 29,1 | 11,1 | 25,9 | - | - | - |
REFRESH [125] | 30,4 | 11,7 | 26,9 | - | - | - |
mBERT + CNN + FC+ TF- IDF | 31,62 | 12,01 | 28,57 | - | - | - |
mBERT + CNN + Encoder- Decoder + FC + TF-IDF | 31,95 | 12,69 | 28,76 | - | - | - |
mBERT + CNN + FC + TF- IDF + MMR | 32,54 | 12,60 | 29,52 | - | - | - |
mBERT + CNN + Encoder- Decoder+FC + TF-IDF +MMR | 32,67 | 13,04 | 29,53 | 54,67 | 25,26 | 37,48 |
Bảng 3.11. So sáng và đánh giá hiệu quả của các phương pháp. Ký hiệu ‘*’, ‘-’ biểu diễn các phương pháp được thử nghiệm, không được thử nghiệm trên các bộ dữ liệu tương ứng
Kết quả trong Bảng 3.11 cũng chỉ ra rằng mô hình đề xuất có kết quả tốt hơn đáng kể so với các phương pháp đã thực hiện thử nghiệm và các phương pháp hiện đại khác đã công bố trên hai bộ dữ liệu CNN và Baomoi tương ứng. Điều đó chứng tỏ mô hình đề xuất mBERT_CNN_ESDS đã đạt hiệu quả cao cho tóm tắt văn bản tiếng Anh và tiếng Việt hướng trích rút.
3.4. Mô hình tóm tắt đơn văn bản hướng trích rút mBERT-Tiny_ seq2seq_DeepQL_ESDS
3.4.1. Giới thiệu mô hình
Mô hình pre-trained BERT [102] và các phiên bản mô hình pre-trained BERT biểu diễn văn bản đầu vào theo ngữ cảnh hai chiều áp dụng vào các mô hình tóm tắt văn bản đã mạng lại kết quả cao. Tuy nhiên, các mô hình này yêu cầu chi phí tính toán lớn và tốn nhiều bộ nhớ nên rất khó thực thi trong điều kiện ràng buộc về tài nguyên. Để giải quyết vấn đề này, dựa trên các mô hình pre-trained BERT, các mô hình BERT thu nhỏ [111] (có kích thước nhỏ hơn, thời gian xử lý tính toán nhanh hơn, tốn ít bộ nhớ hơn và hiệu quả đạt được xấp xỉ các mô hình pre-trained BERT)
đã được phát triển để có thể áp dụng cho các mô hình tóm tắt trên các thiết bị hạn chế về tài nguyên. Bên cạnh đó, mạng GRU, biGRU [89,90] (trong các biến thể của mạng RNN thì mạng GRU, biGRU có kiến trúc đơn giản hơn so với mạng LSTM [87], biLSTM [89]) áp dụng trong các nhiệm vụ xử lý ngôn ngữ tự nhiên cũng như bài toán tóm tắt văn bản đã tạo ra các mô hình có hiệu quả thấp hơn không đáng kể, nhưng thời gian thực thi nhanh hơn rất nhiều và cần ít bộ nhớ cho xử lý tính toán hơn. Trong phần này, luận án phát triển một phương pháp tóm tắt văn bản thực thi hiệu quả trong điều kiện ràng buộc về tài nguyên sử dụng mô hình BERT thu gọn (BERT-Tiny) [111] để mã hóa văn bản tiếng Anh và BERT đa ngôn ngữ (mBERT)
[105] để mã hóa văn bản tiếng Việt. Mô hình phân loại câu được xây dựng sử dụng mạng CNN [85], mô hình seq2seq với bộ mã hóa văn bản sử dụng mạng biGRU và bộ trích rút câu sử dụng mạng GRU. Bộ trích rút câu được huấn luyện sử dụng kỹ thuật học tăng cường Deep Q-Learning (DeepQL) để tăng hiệu quả cho mô hình tính xác suất được chọn của các câu, từ đó cải thiện hiệu quả cho mô hình tóm tắt. Các kết quả đầu ra của mô hình phân loại câu được xử lý loại bỏ các thông tin dư thừa sử dụng phương pháp MMR để sinh bản tóm tắt đầu ra. Phương pháp đề xuất được thử nghiệm trên hai bộ dữ liệu CNN (tiếng Anh) và Baomoi (tiếng Việt) tương ứng. Các kết quả thử nghiệm cho thấy phương pháp đề xuất đạt được kết quả tốt và có thể áp dụng hiệu quả cho tóm tắt văn bản tiếng Anh và tiếng Việt.
3.4.2. Mô hình tóm tắt văn bản đề xuất
Mô hình tóm tắt đơn văn bản hướng trích rút đề xuất bao gồm ba mô đun chính: Véc tơ hóa văn bản, phân loại câu, sinh bản tóm tắt được biểu diễn chi tiết trong Hình 3.7 dưới đây.
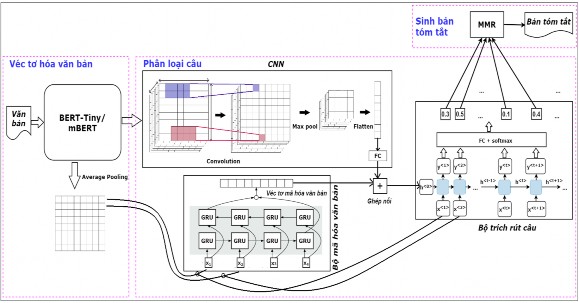
Hình 3.7. Mô hình tóm tắt văn bản hướng trích rút mBERT- Tiny_seq2seq_DeepQL_ESDS
3.4.2.1. Véc tơ hóa văn bản
Trước hết, văn bản đầu vào được xử lý tách câu. Mỗi văn bản được xử lý lấy 64 câu đầu tiên để biểu diễn cho văn bản. Sau đó, lấy 128 từ đầu tiên của mỗi câu để biểu diễn cho câu đó (đệm “0” nếu cần). Các câu này được mã hóa sử dụng các mô hình BERT-Tiny (với 2 lớp, 128 chiều, 4 triệu tham số), mBERT (với 12 lớp, 768 chiều, 110 triệu tham số) để thu được các véc tơ mã hóa từ 128 chiều, 768 chiều cho tiếng Anh, tiếng Việt tương ứng. Các véc tơ này được sử dụng làm đầu vào cho mạng CNN để trích rút các đặc trưng văn bản. Đồng thời, các véc tơ mã hóa từ của mỗi câu được xử lý bởi phép toán Average Pooling để sinh ra véc tơ mã hóa câu 128 chiều, 768 chiều tương ứng cho tiếng Anh, tiếng Việt, được sử dụng làm đầu vào cho bộ mã hóa văn bản và bộ trích rút câu trong mô hình seq2seq của mô đun phân loại câu.
3.4.2.2. Phân loại câu
Mục đích của mô đun là tính xác suất được chọn của các câu đưa vào bản tóm tắt. Để thực hiện nhiệm vụ này, mô đun phân loại câu được xây dựng gồm các thành phần chính sau đây.
(a) Mạng CNN: Kiến trúc mạng CNN [85] được sử dụng và hiệu chỉnh cho mô hình đề xuất. Kiến trúc mạng CNN đề xuất gồm 2 lớp tích chập (Convolution) với Kernel kích thước 4x4, lớp Convolution thứ nhất có 64 bộ lọc, lớp Convolution thứ hai có 16 bộ lọc. Sau mỗi lớp Convolution đều có một lớp Max Pool để giảm số lượng tham số cho mô hình. Để sinh đặc trưng cho xâu đầu vào, mô hình sử dụng một cửa sổ trượt trên một phần của câu và trên một vài câu cạnh nhau (được minh họa như trong Hình 3.7) thay vì trượt trên toàn bộ một câu và trên một số câu cạnh nhau rồi lấy Max Pooling như trong [125]. Sau khi trượt trên toàn bộ văn bản xong sẽ tạo ra một bản đồ đặc trưng (feature map). Sau đó, các feature map được áp dụng phép toán Max pool để giảm chiều, làm phẳng (Flatten), rồi đưa qua lớp mạng nơ ron kết nối đầy đủ (FC) không có hàm kích hoạt (được xem như phép chiếu để giảm chiều) có đầu vào là véc tơ 256 chiều, 1.024 chiều để thu được một véc tơ mã hóa văn bản 64 chiều, 256 chiều cho tiếng Anh, tiếng Việt tương ứng.
(b) Mô hình seq2seq: Mô hình seq2seq [92] gồm bộ mã hóa và bộ giải mã. Kiến trúc mô hình seq2seq đề xuất được xây dựng gồm bộ mã hóa văn bản và bộ trích rút câu. Cả hai thành phần này đều nhận đầu vào là tập gồm H véc tơ câu (với H là số lượng câu lớn nhất của văn bản).
![]()
Bộ mã hóa văn bản:Mô hình sử dụng mạng biGRU [89,90] có 256 trạng thái ẩn (bằng 2*128 trạng thái ẩn) cho cả tiếng Anh và tiếng Việt. Đầu vào tại mỗi bước t là một véc tơ câu 128 chiều, 768 chiều tương ứng cho tiếng Anh, tiếng Việt biểu diễn cho câu xt. Sau H bước thu được 2 véc tơ trạng thái nhớ (cell-state) tương ứng của 2 lớp GRU chiều tiến và GRU chiều lùi (mỗi véc tơ có 128 chiều) mã hóa cho văn bản đầu vào. Hai véc tơ này được ghép nối với véc tơ đầu ra của mạng CNN bởi phép toán “ghép nối” (ký hiệu ) để thu được véc tơ có 320 chiều, 512 chiều cho tiếng Anh, tiếng Việt tương ứng, được sử dụng làm véc tơ trạng thái nhớ đầu vào cho bộ trích rút câu để tính xác suất lựa chọn của các câu.
Bộ trích rút câu:Mạng GRU [89,90] được sử dụng gồm 320 trạng thái ẩn, 512 trạng thái ẩn cho tiếng Anh, tiếng Việt tương ứng, số trạng thái ẩn bằng số chiều của véc tơ mã hóa câu sau phép toán ghép nối. Ở mỗi bước i, câu đầu vào xđược đệm với “0” nếu cần để đảm bảo độ dài câu bằng số trạng thái ẩn của mạng GRU, đầu ra ytương ứng được đưa qua lớp FC (với hàm kích hoạt softmax) nhận đầu vào là véc tơ 320 chiều, 512 chiều cho tiếng Anh, tiếng Việt tương ứng và đầu ra là véc tơ 2 chiều chứa xác suất được chọn của các câu.
3.4.2.3. Sinh bản tóm tắt
Xác suất được chọn của các câu từ bộ trích rút câu được sắp xếp theo thứ tự giảm dần. Các câu có xác suất cao sẽ được chọn đưa vào tóm tắt cho đến khi đạt độ dài giới hạn của bản tóm tắt. Phương pháp MMR đề xuất theo công thức (2.44) trình bày ở chương 2 (với được chọn bằng 0,5) để đo độ tương đồng giữa các câu nhằm loại bỏ thông tin dư thừa trong bản tóm tắt. Câu có độ tương đồng với các câu đã được chọn đưa vào bản tóm tắt lớn hơn một giá trị ngưỡng xác định sẽ không được đưa vào bản tóm tắt.
3.4.3. Huấn luyện mô hình với kỹ thuật học tăng cường
Trước hết, mô hình phân loại câu được huấn luyện để đảm bảo trạng thái ẩn đầu vào có đầy đủ các thông tin cần thiết của mô hình. Sau đó, bộ trích rút câu được huấn luyện tiếp để tăng tính hiệu quả cho mô hình tính xác suất được chọn của các câu sử dụng kỹ thuật học tăng cường Deep Q-Learning [114] đã trình bày ở Chương 2 với các siêu tham số được cài đặt như trong Bảng 3.12 sau đây.
Giá trị | Diễn giải | |
lrdecay | 0,9995 | Tham số điều chỉnh quá trình khám phá và tối ưu |
| 0,05 | Tham số để tránh chọn những câu quá khác biệt so với bản tóm tắt tham chiếu |
batch size | 64 | Kích thước lô dữ liệu |
(discount factor) | 0,95 | Hệ số tiêu hao |
Bảng 3.12. Bảng giá trị các siêu tham số cài đặt cho mô hình huấn luyện với kỹ thuật học tăng cường Deep Q-Learning
Mô hình huấn luyện với kỹ thuật học tăng cường Deep Q-Learning đề xuất được thiết lập như Hình 3.8 dưới đây. Các yếu tố quyết định trong học tăng cường là thông tin về trạng thái hiện tại, hành động tương ứng, điểm thưởng và chiến lược học được cài đặt như sau:
Trạng thái: Mỗi trạng thái st biểu diễn cho câu đang xét gồm hai thành phần: ht là trạng thái ẩn mã hóa cho các trạng thái trước cũng như các hành động trước đó, được tạo bởi mạng GRU của tác tử đang tương tác với môi trường; xt là mã hóa trạng thái đang xét, là véc tơ mã hóa câu đầu ra sau phép toán Average Pooling.
Hành động: Có 2 hành động tương ứng dựa trên xác suất đầu ra của lớp FC đối với một trạng thái: “1” - chọn câu đang xét, “0” - không chọn câu đang xét.
Điểm thưởng: Ở trạng thái t, nếu không chọn câu đang xét sentt thì nhận điểm thưởng bằng 0. Nếu chọn câu đang xét sentt thì sẽ nhận điểm thưởng Rt bằng điểm
R-L (ký hiệu Rouge_L) của câu đang xét sentt so với bản tóm tắt hiện có D trừ đi một giá trị δ (để tránh chọn các câu quá khác biệt so với bản tóm tắt hiện có), được
tính theo công thức:
Rt Rouge _ L(sentt , D)
(3.5)
Chiến lược: Ở trạng thái st, tác tử thực hiện một hành động để chuyển đến trạng thái st+1, nhận điểm thưởng Rt từ môi trường và mục tiêu là tìm chiến lược có tổng điểm thưởng lớn nhất.
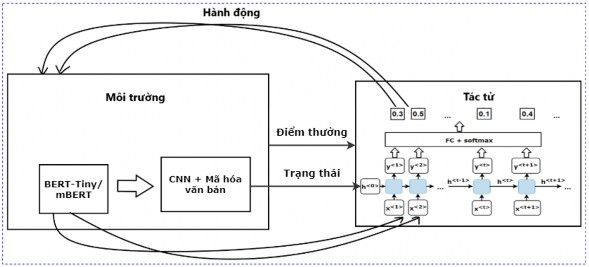
Hình 3.8. Mô hình huấn luyện với kỹ thuật học tăng cường Deep Q-Learning
3.4.4. Thử nghiệm mô hình
3.4.4.1. Các bộ dữ liệu thử nghiệm
Mô hình mBERT-Tiny_seq2seq_DeepQL_ESDS đề xuất được thử nghiệm trên bộ dữ liệu CNN cho tóm tắt văn bản tiếng Anh và bộ dữ liệu Baomoi cho tóm tắt văn bản tiếng Việt (chi tiết các bộ dữ liệu này được trình bày trong chương 1).
3.4.4.2. Tiền xử lý dữ liệu
Trước hết, các bộ dữ liệu CNN và Baomoi được xử lý tách riêng phần nội dung, tóm tắt và đánh số thứ tự cho các câu. Các thư viện Stanford CoreNLP, VnCoreNLP được sử dụng để tách câu của văn bản đầu vào cho bộ dữ liệu CNN, Baomoi tương ứng. Tiếp theo, các câu của mỗi bộ dữ liệu được gán nhãn dựa trên tối đa tổng của R-2 và R-L sử dụng thư viện rouge-score 0.0.4. Sau đó, các câu này được đưa vào mô hình BERT-Tiny, mBERT tương ứng để thu được các véc tơ mã hóa từ của các câu. Đồng thời, các véc tơ mã hóa từ của mỗi câu được xử lý sử dụng thư viện PyTorch thu được véc tơ mã hóa câu 128 chiều, 768 chiều cho tiếng Anh, tiếng Việt tương ứng để làm đầu vào cho mô hình phân loại câu.
3.4.4.3. Thiết kế thử nghiệm
Luận án triển khai xây dựng bốn mô hình và thử nghiệm trên hai bộ dữ liệu CNN và Baomoi để lựa chọn mô hình tóm tắt hiệu quả nhất cho phương pháp đề xuất. Chi tiết các mô hình được trình bày như sau đây.