câu đã có trong bản tóm tắt nhỏ nhất), trong đó mỗi
câu được chọn thỏa mãn:
v V , 1 cosines,v1
2
sim ; với:
V là tập các câu đã được chọn vào bản tóm tắt, s là
câu đang xem xét đưa vào bản tóm tắt, tương đồng giữa 2 câu.
6: Return;
sim
là ngưỡng độ
Phương pháp dựa trên trung tâm áp dụng cho bài toán tóm tắt văn bản loại bỏ được các thông tin trùng lặp trong bản tóm tắt. Tuy nhiên, chất lượng của bản tóm tắt còn phụ thuộc vào việc chọn các giá trị ngưỡng sent , sim và phương pháp này chưa xét đến độ tương đồng về ngữ nghĩa giữa các câu.
5.2.3. Mô hình tóm tắt đa văn bản đề xuất
5.2.3.1. Xây dựng các mô hình tóm tắt
Xuất phát từ mô hình ban đầu sử dụng thuật toán phân cụm K-means, các mô hình được phát triển bằng việc kết hợp mô hình ban đầu với các phương pháp khác và đặc trưng vị trí câu trong văn bản. Mỗi mô hình đều được phân tích, thử nghiệm và đánh giá kết quả để chọn mô hình tóm tắt hiệu qủa nhất.
Mô hình 1: Thuật toán phân cụm K-means kết hợp vị trí tương đối của câu.
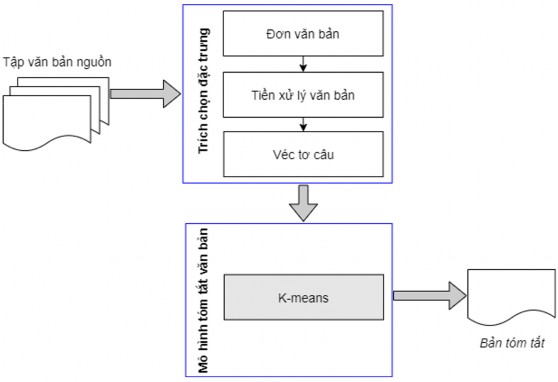
Hình 5.1. Mô hình sử dụng thuật toán phân cụm K-means kết hợp vị trí tương đối của câu
Mô hình tóm tắt đa văn bản có đầu vào là tập các câu được biểu diễn dưới dạng các véc tơ. Tập các câu này sẽ có các câu tương đồng với nhau nên ta có thể phân chia các câu này thành các cụm (mỗi cụm gồm các câu tương tự với nhau).
Từ ý tưởng này, trước hết mô hìnhg áp dụng thuật toán phân cụm K-means để phân cụm các câu đầu vào. Mỗi câu đầu vào được tách thành các từ, mỗi từ được véc tơ hóa bằng phương pháp word2vec sử dụng mô hình CBoW. Mô hình này được huấn luyện với tập các từ được lấy từ các câu đầu vào, véc tơ đầu ra của một từ có số chiều là 256. Do đầu ra của mô hình word2vec là một véc tơ biểu diễn cho từng từ nên để véc tơ hóa câu sử dụng word2vec, mô hình thực hiện tính tổng các véc tơ từ trong câu để được một véc tơ câu có số chiều là 256.
Sau khi áp dụng thuật toán K-means, các câu đã được phân chia vào các cụm. Để lựa chọn các câu từ một cụm, dựa vào khoảng cách của câu đó đến tâm của cụm, khoảng cách càng gần thì khả năng chọn câu đó vào bản tóm tắt càng cao. Bên cạnh đó, mỗi cụm mang một ý nghĩa riêng nên ta chỉ cần chọn một câu duy nhất đại diện cho cụm để đưa vào bản tóm tắt. Do đó, số cụm ban đầu được lấy bằng số lượng câu mong muốn trong bản tóm tắt.
Đối với các câu trong bản tóm tắt, thực hiện đánh số “vị trí tương đối” cho từng câu, sắp xếp các câu theo thứ tự nhất định và câu nào có vị trí tương đối nhỏ hơn sẽ được đưa vào bản tóm tắt trước. Vị trí tương đối của câu được tính bằng vị trí trung bình của cụm chính là trung bình cộng của vị trí các câu trong cụm.
Mô hình 1 được biểu diễn như trong Hình 5.1 ở trên.
Mô hình 2: Thuật toán phân cụm K-means kết hợp vị trí câu
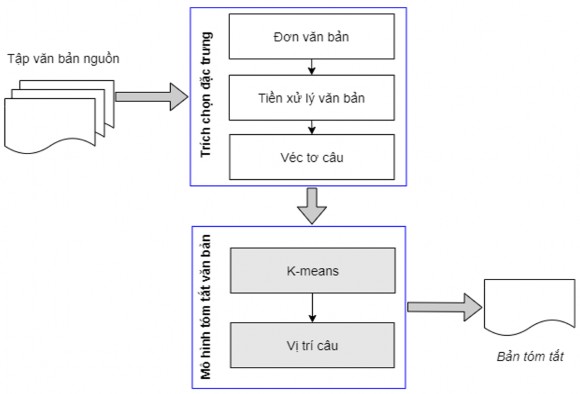
Hình 5.2. Mô hình sử dụng thuật toán phân cụm K-means kết hợp vị trí câu
Phương pháp lựa chọn các câu đưa vào bản tóm tắt trong mô hình 1 có những hạn chế nhất định vì vị trí tương đối của câu hay giá trị trung bình vị trí các câu của
cụm không phản ánh đúng vị trí của câu đó trong văn bản. Do đó, mô hình kết hợp thuật toán phân cụm K-means với đặc trưng vị trí câu trong văn bản để khắc phục hạn chế này. Các câu có vị trí câu thấp hơn sẽ được đánh trọng số cao hơn và các câu có vị trí câu thấp hơn trong văn bản sẽ được đưa vào bản tóm tắt trước.
Mô hình 2 được biểu diễn như trong Hình 5.2 ở trên.
Mô hình 3: Thuật toán phân cụm K-means kết hợp MMR và vị trí câu
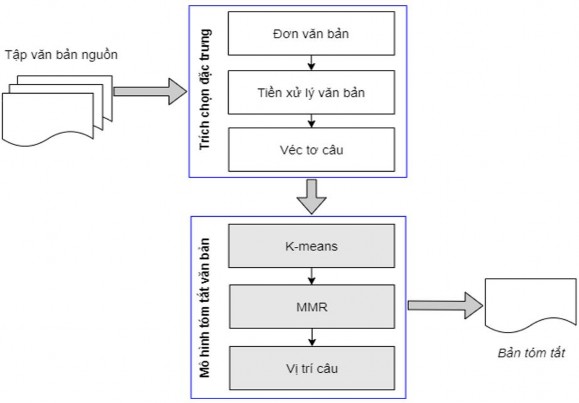
Hình 5.3. Mô hình sử dụng thuật toán phân cụm K-means kết hợp MMR và vị trí câu
Việc lựa chọn số cụm bằng số câu của bản tóm tắt trong mô hình sử dụng thuật toán phân cụm K-means có thể làm giảm chất lượng của bản tóm tắt khi số cụm được chọn nhỏ. Khi số cụm tăng lên thì chất lượng của bản tóm tắt sẽ tăng lên nên ta có thể lựa chọn số cụm lớn hơn số câu mong muốn của bản tóm tắt nhưng khi đó vấn đề đặt ra là chọn câu từ cụm nào và loại bỏ câu từ cụm nào. Để giải quyết vấn đề này, ta có thể loại bỏ các câu có thông tin dư thừa nhất so với các câu đã được chọn vào bản tóm tắt hiện thời. Phương pháp MMR có thể loại bỏ các câu dư thừa trong tập các câu ứng cử viên, do đó phương pháp MMR được kết hợp vào mô hình để loại bỏ các câu dư thừa trước khi kết hợp với đặc trưng vị trí câu.
Tập các câu kết quả từ phương pháp MMR được đưa vào bản tóm tắt theo trình tự dựa trên đặc trưng vị trí câu. Như vậy, bản tóm tắt đầu ra vừa khắc phục được hạn chế khi lựa chọn số cụm nhỏ, vừa giảm được các câu dư thừa trong bản tóm tắt.
Mô hình 3 được biểu diễn như trong Hình 5.3 ở trên.
Mô hình 4: Thuật toán phân cụm K-means kết hợp phương pháp dựa trên trung tâm (Centroid-based), MMR và vị trí câu
Trong các cụm được tính toán bởi thuật toán phân cụm K-means, có những cụm chỉ gồm những câu chứa ít thông tin (thậm chí không chứa thông tin) nên không cần
đưa các câu này vào bản tóm tắt. Do đó, mô hình kết hợp thuật toán phân cụm K- means với độ trung tâm (Centroid-based) của câu trước khi kết hợp với phương pháp MMR và vị trí câu để loại bỏ các câu chứa ít thông tin hoặc không chứa thông tin. Mô hình 4 được biểu diễn như trong Hình 5.4 dưới đây.
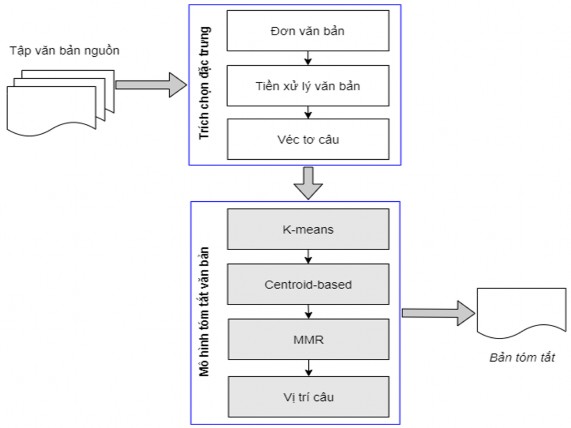
Hình 5.4. Mô hình sử dụng thuật toán phân cụm K-means kết hợp Centroid-based, MMR và vị trí câu
Các mô hình này đều được triển khai thử nghiệm (kết quả thử nghiệm được trình bày chi tiết trong phần 5.2.4) dưới đây. Các kết quả thử nghiệm cho thấy mô hình 4 cho kết quả tốt nhất nên mô hình 4 được chọn làm mô hình tóm tắt đa văn bản hướng trích rút đề xuất (mô hình Kmeans_Centroid_EMDS).
5.2.3.2. Mô hình tóm tắt đa văn bản hướng trích rút đề xuất Kmeans_Centroid_EMDS
Mô hình tóm tắt đa văn bản hướng trích rút đề xuất Kmeans_Centroid_EMDS
được biểu diễn như trong Hình 5.5, bao gồm hai mô đun chính:
Trích chọn đặc trưng: Mô đun này thực hiện kết hợp các văn bản đầu vào thành một văn bản duy nhất, tiền xử lý dữ liệu tập văn bản đầu vào để loại bỏ các ký tự đặc biệt, lấy gốc từ,... tiếp theo tập văn bản được tách thành tập các câu trước khi được biểu diễn dưới dạng véc tơ, sau đó tập các câu này được véc tơ hóa làm đầu vào cho mô hình tóm tắt văn bản ở giai đoạn tiếp theo.
Mô hình tóm tắt văn bản: Mô đun này nhận các véc tơ câu đầu vào và sinh ra một bản tóm tắt bằng cách trích rút các câu có nhiều thông tin nhất. Mô hình đề xuất sử dụng thuật toán phân cụm K-means kết hợp với phương pháp dựa trên trung tâm,
MMR và vị trí câu trong văn bản nguồn được xây dựng dựa trên các mô hình đã xây dựng (mỗi mô hình đều được thử nghiệm, phân tích và đánh giá kết quả để tìm ra mô hình hiệu quả nhất).
Trong mô hình tóm tắt đề xuất Kmeans_Centroid_EMDS, mô hình BoW sử dụng trọng số TF-IDF được sự dụng để véc tơ hóa văn bản đầu vào cho phương pháp Centroid-based. Một từ được coi là từ trung tâm nếu trọng số TF-IDF của từ lớn hơn giá trị ngưỡng cho trước, một câu được coi là trung tâm (có trọng số cao) được tạo thành bởi nhiều từ trung tâm. Từ ý tưởng này, hệ thống dựa vào độ trung tâm của các câu để xác định câu chứa nhiều thông tin và câu chứa ít thông tin. Tập các câu được chọn từ phương pháp Centroid-based được loại bỏ thông tin dư thừa sử dụng phương pháp MMR. Như vậy, bản tóm tắt thu được vừa giảm được thông tin dư thừa giữa các câu, vừa loại bỏ được các câu chứa ít thông tin hoặc không chứa thông tin. Tập các câu nhận được từ phương pháp MMR được đưa vào bản tóm tắt theo trình tự dựa trên đặc trưng vị trí câu.
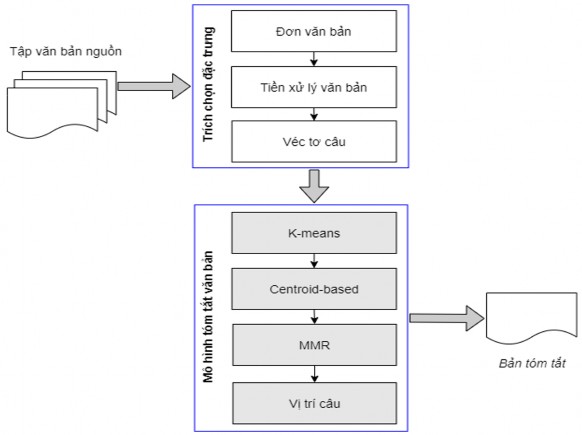
Hình 5.5. Mô hình tóm tắt đa văn bản hướng trích rút đề xuất Kmeans_Centroid_EMDS
5.2.4. Thử nghiệm mô hình và kết quả
5.2.4.1. Dữ liệu thử nghiệm
Mô hình được thử nghiệm trên tập dữ liệu Main task của bộ dữ liệu DUC 2007
[75] cho tiếng Anh và bộ dữ liệu Corpus_TMV [76] cho tiếng Việt. Việc thử nghiệm mô hình trên bộ dữ liệu Corpus_TMV để đánh giá hiệu quả mô hình đề xuất
đối với tóm tắt đa văn bản tiếng Việt và đảm bảo tính tổng quát của mô hình đề xuất đối với tóm tắt văn bản ngôn ngữ khác. Các văn bản trong bộ dữ liệu DUC 2007 được tiền xử lý để tách lấy nội dung, loại bỏ các ký tự đặc biệt, lấy từ gốc, loại bỏ các câu có số lượng từ quá nhỏ, loại bỏ từ dừng để giảm kích thước của bộ từ vựng nhằm cải thiện chất lượng của bản tóm tắt đầu ra của mô hình đề xuất. Các văn bản trong bộ dữ liệu Corpus_TMV được xử lý trích xuất từ các tệp tương ứng. Sau đó, xử lý tách câu và đánh số thứ tự cho các câu trong phần nội dung của mỗi văn bản.
5.2.4.2. Cài đặt các tham số
Các tham số sử dụng khi thử nghiệm các mô hình gồm:
- n_clusters: Số lượng các cụm trong thuật toán phân cụm K-means. Do đặc điểm của các bộ dữ liệu DUC 2007, Corpus_TMV khác nhau nên tham số này được cài đặt với các giá trị khác nhau cho mỗi bộ dữ liệu trong các mô hình.
- ndim: Số chiều của véc tơ câu.
- : Tham số sử dụng trong phương pháp MMR.
- sent: Giá trị ngưỡng xác định sự giống nhau giữa một câu với véc tơ trung tâm, được sử dụng trong phương pháp dựa trên trung tâm.
- sim: Giá trị ngưỡng xác định sự giống nhau giữa hai câu, được sử dụng trong phương pháp dựa trên trung tâm.
- len_sum: Độ dài bản tóm tắt (số câu của bản tóm tắt).
Một yếu tố quan trọng trong thuật toán phân cụm K-means là xác định số lượng các cụm. Đối với bộ dữ liệu DUC 2007, trong mô hình 1 và 2, số lượng các cụm được lấy bằng số lượng câu trong bản tóm tắt là 13 (do độ dài của bản tóm tắt trong bộ dữ liệu DUC 2007 là xấp xỉ 250 từ, tương đương với 12 đến 13 câu nên số cụm được chọn là 13). Trong mô hình 3, số cụm được chọn lớn hơn là 21 cụm khi các câu trung tâm của một số cụm sẽ bị loại bỏ bởi phương pháp MMR. Trong mô hình 4, số cụm được chọn là 50 vì mô hình đề xuất muốn có nhiều câu được chọn hơn và có các phương pháp để chọn các câu tốt nhất đưa vào bản tóm tắt. Đối với bộ dữ liệu Corpus_TMV, số lượng các cụm được lấy cố định bằng 14 cụm trong cả 4 mô hình, số câu của bản tóm tắt được lấy là 5 câu (do độ dài bản tóm tắt của bộ dữ liệu Corpus_TMV xấp xỉ 5 câu), còn các tham số khác cũng được cài đặt giống như thử nghiệm mô hình trên bộ dữ liệu DUC 2007.
Bảng 5.1 dưới đây trình bày giá trị của các tham số sử dụng khi thử nghiệm các mô hình trên 2 bộ dữ liệu tương ứng.
n_clusters | ndim | | sent | sim | len_sum | Bộ dữ liệu | |
Mô hình 1 | 13 | 256 | - | - | - | 13 | DUC 2007 |
Mô hình 2 | 13 | 256 | - | - | - | 13 | DUC 2007 |
Mô hình 3 | 21 | 256 | 0,6 | - | - | 13 | DUC 2007 |
Mô hình 4 | 50 | 256 | 0,6 | 0,3 | 0,95 | 13 | DUC 2007 |
Mô hình 1 | 14 | 256 | - | - | - | 5 | Corpus_TMV |
Mô hình 2 | 14 | 256 | - | - | - | 5 | Corpus_TMV |
Mô hình 3 | 14 | 256 | 0,6 | - | - | 5 | Corpus_TMV |
Mô hình 4 | 14 | 256 | 0,6 | 0,3 | 0,95 | 5 | Corpus_TMV |
Có thể bạn quan tâm!
-

 Giá Trị Các Siêu Tham Số Và Thời Gian Huấn Luyện Các Mô Hình Xây Dựng
Giá Trị Các Siêu Tham Số Và Thời Gian Huấn Luyện Các Mô Hình Xây Dựng -
![Mô Hình Tóm Tắt Đơn Văn Bản Hướng Tóm Lược Cơ Sở [128]](https://tailieuthamkhao.com/uploads/2022/06/10/nghien-cuu-phat-trien-mot-so-phuong-phap-tom-tat-van-ban-su-dung-ky-13-1-120x90.jpg) Mô Hình Tóm Tắt Đơn Văn Bản Hướng Tóm Lược Cơ Sở [128]
Mô Hình Tóm Tắt Đơn Văn Bản Hướng Tóm Lược Cơ Sở [128] -
 Mẫu Tóm Tắt Gồm Bản Tóm Tắt Tham Chiếu, Bản Tóm Tắt Của Mô Hình Trong
Mẫu Tóm Tắt Gồm Bản Tóm Tắt Tham Chiếu, Bản Tóm Tắt Của Mô Hình Trong -
 Các Mẫu Tóm Tắt Của Cụm D0716D Trong Bộ Dữ Liệu Duc 2007 Của Mô Hình Đề Xuất Và Con Người
Các Mẫu Tóm Tắt Của Cụm D0716D Trong Bộ Dữ Liệu Duc 2007 Của Mô Hình Đề Xuất Và Con Người -
 Các Giai Đoạn Huấn Luyện Mô Hình Tóm Tắt Đa Văn Bản Hướng Tóm Lược Đề Xuất Pg_Feature_Amds
Các Giai Đoạn Huấn Luyện Mô Hình Tóm Tắt Đa Văn Bản Hướng Tóm Lược Đề Xuất Pg_Feature_Amds -
 Mô Hình Tóm Tắt Đơn Văn Bản Hỗn Hợp Ext_Abs_Asds
Mô Hình Tóm Tắt Đơn Văn Bản Hỗn Hợp Ext_Abs_Asds
Xem toàn bộ 185 trang tài liệu này.
Bảng 5.1. Giá trị của các tham số sử dụng khi thử nghiệm các mô hình. Ký hiệu ‘-‘ biểu diễn mô hình không sử dụng các tham số tương ứng
5.2.4.3. Thiết kế thử nghiệm
a) Thử nghiệm các mô hình xây dựng
Bốn mô hình đã xây dựng được thử nghiệm trên hai bộ dữ liệu DUC 2007 và Corpus_TMV. Các kết quả thử nghiệm thu được như trong Bảng 5.2 dưới đây.
DUC 2007 | Corpus_TMV | |||||
R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
Mô hình 1 | 37,81 | 7,30 | 34,61 | 67,87 | 44,58 | 64,55 |
Mô hình 2 | 38,11 | 7,87 | 34,87 | 68,01 | 44,52 | 64,89 |
Mô hình 3 | 38,82 | 8,15 | 35,53 | 71,20 | 46,93 | 66,97 |
Mô hình 4 | 40,39 | 9,53 | 37,05 | 73,86 | 48,42 | 68,09 |
Bảng 5.2. Kết quả thử nghiệm các mô hình xây dựng trên hai bộ dữ liệu
Bảng 5.2 cho thấy mô hình sử dụng đặc trưng vị trí câu (mô hình 2) tốt hơn mô hình sử dụng vị trí câu tương đối (mô hình 1). Ngoài ra, vấn đề quan trọng là loại bỏ thông tin dư thừa của bản tóm tắt và phương pháp MMR là một giải pháp tốt cho mục đích này. Khi áp dụng phương pháp MMR, kết quả độ đo R-1 của mô hình 3 tăng lần lượt là 0,71% và 3,19% so với mô hình 2 tương ứng trên 2 bộ dữ liệu.
Kết quả trong Bảng 5.2 cũng chứng minh rằng phương pháp xử lý thông tin trùng lặp và loại bỏ các câu đại diện cho các cụm mà chứa ít thông tin hoặc không chứa thông tin (mô hình 4) đạt hiệu quả cao trong việc cải thiện chất lượng của bản tóm tắt đầu ra của mô hình tóm tắt. Kết quả độ đo R-1 trong thử nghiệm với mô hình 4 cao hơn lần lượt là 2,58% và 5,99% so với kết qủa của mô hình 1 trên 2 bộ dữ liệu tương ứng. Các độ đo R-2 và R-L của mô hình 4 cũng tốt hơn các mô hình còn lại. Có thể nói, mô hình 4 đã đạt được kết quả tốt nhất trong các mô hình đã xây dựng cho tóm tắt đa văn bản tiếng Anh, tiếng Việt nên mô hình này được chọn làm mô hình tóm tắt đa văn bản hướng trích rút đề xuất Kmeans_Centroid_EMDS.
b) Thử nghiệm các mô hình sử dụng các kỹ thuật phân cụm khác
Để đánh giá hiệu quả của kỹ thuật phân cụm K-means so với các kỹ thuật phân cụm khác trong các mô hình tóm tắt văn bản, phương pháp phân tích ngữ nghĩa tiềm ẩn (LSA) [17], chủ đề ẩn (LDA) [141] được triển khai thử nghiệm trên bộ dữ liệu DUC 2007. Luận án cũng so sánh kết quả mô hình tóm tắt đề xuất với các phương pháp tóm tắt dựa trên trung tâm (Centroid-based) và LexRank. Hai phương pháp này hiệu quả trong việc xếp hạng các câu nên chúng thích hợp cho bài toán tóm tắt văn bản. Bảng 5.3 trình bày các kết quả thử nghiệm của các phương pháp.
R-1 | R-2 | R-L | |
LexRank | 37,52 | 8,14 | 34,18 |
LSA | 37,92 | 7,74 | 35,02 |
LDA | 35,69 | 6,26 | 32,71 |
LSA + Centroid-based + MMR + Vị trí câu | 36,37 | 6,90 | 33,50 |
LDA + Centroid-based + MMR + Vị trí câu | 36,73 | 7,22 | 33,58 |
K-means | 37,81 | 7,30 | 34,86 |
K-means + Vị trí câu | 38,11 | 7,87 | 34,86 |
Centroid-based | 38,95 | 9,08 | 35,50 |
K-means + Centroid-based + MMR + Vị trí câu | 40,39 | 9,53 | 37,05 |
Bảng 5.3. Kết quả thử nghiệm các phương pháp tóm tắt trên bộ dữ liệu DUC 2007
Bảng 5.3 chỉ ra rằng các phương pháp LSA và LDA không tốt bằng kỹ thuật phân cụm K-means trong nhiệm vụ tóm tắt đa văn bản. Kết quả của phương pháp LexRank cũng kém hơn so với kỹ thuật K-means. Tuy nhiên, phương pháp dựa trên trung tâm (Centroid-based) giải quyết vấn đề này khá tốt với kết quả độ đo R-1 là 38,95%, R-2 là 9,08% và R-L là 35,50%. Sự kết hợp của kỹ thuật phân cụm K- means, phương pháp dựa trên trung tâm, MMR và vị trí câu cho kết quả các độ đo R-1, R-2 và R-L tốt hơn so với các phương pháp còn lại.
5.2.5. So sánh và đánh giá kết quả
Mô hình đề xuất cũng được so sánh với các nghiên cứu hiện đại khác đã công bố trên cùng bộ dữ liệu thử nghiệm DUC 2007. Phương pháp DSDR [142] đại diện cho tóm tắt đa văn bản dựa trên cấu trúc lại câu. Trong phương pháp này, các câu quan trọng được lựa chọn và cấu trúc lại bằng cách học một chức năng cấu trúc lại câu. Sau đó, DSDR cung cấp một tập các câu đại diện tối ưu để ước lượng gần đúng toàn bộ tập văn bản bằng cách giảm thiểu lỗi khi cấu trúc lại. Phương pháp PV-DM
[143] sử dụng bộ nhớ phân tán để biểu diễn văn bản và chọn các câu bằng cách cấu trúc lại ở mức văn bản. Phương pháp PV-DM không đánh giá cho độ đo R-L.
Hai mô hình cơ sở Random và Lead cũng được sử dụng để so sánh với mô hình đề xuất Kmeans_Centroid_EMDS. Kỹ thuật Random lựa chọn các câu ngẫu nhiên từ các văn bản đầu vào để đưa vào bản tóm tắt. Thay vào đó, Lead sắp xếp các văn bản đầu vào theo trình tự thời gian và chọn các câu dẫn đầu từ mỗi văn bản để đưa vào bản tóm tắt. Kết quả so sánh và đánh giá của các phương pháp được trình bày trong Bảng 5.4 dưới đây.
DUC 2007 | Corpus_TMV | |||||
R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
Random [142] | 32,03 | 5,43 | 29,13 | - | - | - |
Lead [142] | 31,45 | 6,15 | 26,58 | - | - | - |
DSDR [142] | 39,57 | 7,44 | 35,34 | - | - | - |
PV-DM [143] | 39,83 | 8,51 | - | - | - | - |
K-means + Centroid-based + MMR + Vị trí câu | 40,39 | 9,53 | 37,05 | 73,86 | 48,42 | 68,09 |
Bảng 5.4. So sánh và đánh giá kết quả của các phương pháp. Ký hiệu ‘-’ biểu diễn các phương pháp không được thử nghiệm trên bộ dữ liệu tương ứng
Bảng 5.4 cho thấy mô hình tóm tắt đề xuất Kmeans_Centroid_EMDS cho kết quả tốt hơn so với một số phương pháp hiện đại đã được công bố. Điều đó cũng chứng minh rằng mô hình đề xuất đã đạt được hiệu quả tốt cho tóm tắt đa văn bản hướng trích rút cho tiếng Anh và tiếng Việt.
Bảng 5.5 trình bày mẫu tóm tắt của cụm văn bản D0716D trong bộ dữ liệu DUC 2007 bao gồm một bản tóm tắt tham chiếu của con người và bản tóm tắt đầu ra của mô hình đề xuất Kmeans_Centroid_EMDS. Các văn bản nguồn của mẫu tóm tắt này xem Phụ lục C.5trong phần Phụ lục.
In October 1997, the Australian government gave permission to Energy Resources of Australia (ERA) to open the Jabiluka uranium mine on the edge of the Kakadu National Park which is on the World Heritage List, in Australia's Northern Territory. The mine is expected to produce 19.5 million tons of ore and generate 4.46 billion U.S. dollars to Australia's GNP over 28 years. Jabiluka is considered a litmus test for up to 12 other uranium mines in Australia. Conservationists and the Aboriginal "Mirrar" owners of the land oppose the mine while ERA insists that its environmental record has been proven by the 16-year operation of the Ranger mine, also located in the Kakadu Park. Opposition leader Kim Beazley said the Labor Party would stop Jabiluka if it won the government in the October national election. Shortly after construction began in mid June 1998, there were a series of public protests. An ERA office in Darwin was firebombed. A team from the United Nations World Heritage Bureau visited the site, then called for closing the Jabiluka mine because it poses a danger to the cultural and natural values of the Kakadu Park. In November 1998, the U.N. World Heritage Bureau, after intense lobbying by the Australian government, decided not to put the Kakadu National Park on its endangered list, but asked for a detailed report by April 15th 1999 on what has been done to prevent further damage and mitigate all threats to the Kakadu park by the Jabiluka mine. |
Bản tóm tắt của mô hình đề xuất Kmeans_Centroid_EMDS |
The Australian federal government Thursday rejected a UNESCO report which called for Kakadu National Park in northwest Australia to be placed on the endangered list because of the threat posed by the Jabiluka uranium mine. CANBERRA, Australia (AP)A United Nations World Heritage committee called Wednesday for the scrapping of the proposed Jabiluka uranium mine in Australia's Northern Territory. The Australian: -- The Australian government's environmental report on the Jabiluka uranium mine (located in Kakadu Natural Park), to be released Thursday, found the area is not under threat and attacked a UNESCO report that said Kakadu Natural Park was in danger. In a major embarrassment to the Howard government, the Bureau of the U.N. World Heritage Committee found Kakadu was under threat, raising the prospect that the committee will this week make Kakadu only the 26th of the world's 552 World Heritage Sites to be placed on its endangered list. The Age -- Australian conservationists and traditional aboriginal owners threatened to blockade development of the huge Jabiluka uranium mine in the country's vast Kakadu National Park, which is on the World Heritage List, after the federal government approved the mining plan for the Jabilika mine yesterday. "The mission has concluded that |