(i) Mô hình 1 (BERT-Tiny/mBERT + CNN + seq2seq): Sử dụng mô hình BERT-Tiny (với bộ dữ liệu CNN), mBERT (với bộ dữ liệu Baomoi) kết hợp với mạng CNN và mạng seq2seq để huấn luyện mô hình tính xác suất được chọn của các câu đưa vào bản tóm tắt.
(ii) Mô hình 2 (BERT-Tiny/mBERT + CNN + seq2seq + MMR): Mô hình 1 kết hợp với phương pháp MMR để lựa chọn câu đưa vào bản tóm tắt. Mô hình này nhằm đánh giá hiệu quả của phương pháp MMR trong việc loại bỏ thông tin trùng lặp cho bản tóm tắt.
(iii) Mô hình 3 (BERT-Tiny/mBERT + CNN + seq2seq + DeepQL): Mô hình 1 kết hợp với kỹ thuật học tăng cường Deep Q-Learning để huấn luyện bộ trích rút câu để lựa chọn câu đưa vào bản tóm tắt. Mô hình này nhằm đánh giá hiệu quả của việc kết hợp kỹ thuật học tăng cường Deep Q-Learning cho mô hình tóm tắt.
(iv) Mô hình 4 (BERT-Tiny/mBERT + CNN + seq2seq + DeepQL + MMR): Mô hình 3 kết hợp với phương pháp MMR để lựa chọn câu đưa vào bản tóm tắt.
Thư viện Transformers được sử dụng để kế thừa các mô hình BERT-Tiny, mBERT và mô hình phân loại câu được xây dựng sử dụng thư viện PyTorch. Các mô hình được huấn luyện sử dụng Google Colab với cấu hình máy chủ GPU V100, 25GB RAM được cung cấp bởi Google. Trước hết, các mô hình được huấn luyện với các siêu tham số được cài đặt và thời gian huấn luyện (giờ) được trình bày trong Bảng 3.13 dưới đây. Tiếp theo, bộ trích rút câu trong các mô hình 3 và mô hình 4 được huấn luyện tiếp với kỹ thuật học tăng cường Deep Q-Learning qua 100.000 bước, batch size là 32, thời gian huấn luyện xấp xỉ 13 giờ trên bộ dữ liệu CNN; và huấn luyện qua 70.000 bước, batch size là 4, thời gian huấn luyện xấp xỉ 80 giờ trên bộ dữ liệu Baomoi.
Epochs | Batch size | Bộ dữ liệu | Thời gian huấn luyện | |
Mô hình 1 (BERT-Tiny/mBERT + CNN + seq2seq) | 5 | 80 | CNN | 5 |
Mô hình 2 (BERT-Tiny/mBERT + CNN + seq2seq + MMR) | 5 | 80 | CNN | 5 |
Mô hình 3 (BERT-Tiny/mBERT + CNN + seq2seq + DeepQL) | 5 | 80 | CNN | 5 |
Mô hình 4 (BERT-Tiny/mBERT + CNN + seq2seq + DeepQL + MMR) | 5 | 80 | CNN | 5 |
Mô hình 1 (BERT-Tiny/mBERT + CNN + seq2seq) | 3 | 8 | Baomoi | 30 |
Mô hình 2 (BERT-Tiny/mBERT + CNN + seq2seq + MMR) | 3 | 8 | Baomoi | 30 |
Mô hình 3 (BERT-Tiny/mBERT + CNN + seq2seq + DeepQL) | 3 | 8 | Baomoi | 30 |
Mô hình 4 (BERT-Tiny/mBERT + CNN + seq2seq + DeepQL + MMR) | 3 | 8 | Baomoi | 30 |
Có thể bạn quan tâm!
-

 Phát Triển Các Phương Pháp Tóm Tắt Đơn Văn Bản Hướng Trích Rút
Phát Triển Các Phương Pháp Tóm Tắt Đơn Văn Bản Hướng Trích Rút -
 Kết Quả Thử Nghiệm Một Số Phương Pháp Tóm Tắt Văn Bản Cơ Sở. Ký Hiệu ‘*’ Thể Hiện Phương Pháp Được Triển Khai Thử Nghiệm Trên Các Bộ
Kết Quả Thử Nghiệm Một Số Phương Pháp Tóm Tắt Văn Bản Cơ Sở. Ký Hiệu ‘*’ Thể Hiện Phương Pháp Được Triển Khai Thử Nghiệm Trên Các Bộ -
 Các Kết Quả Thử Nghiệm Của Các Mô Hình Xây Dựng
Các Kết Quả Thử Nghiệm Của Các Mô Hình Xây Dựng -
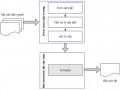
![Mô Hình Tóm Tắt Đơn Văn Bản Hướng Tóm Lược Cơ Sở [128]](https://tailieuthamkhao.com/uploads/2022/06/10/nghien-cuu-phat-trien-mot-so-phuong-phap-tom-tat-van-ban-su-dung-ky-13-1-120x90.jpg) Mô Hình Tóm Tắt Đơn Văn Bản Hướng Tóm Lược Cơ Sở [128]
Mô Hình Tóm Tắt Đơn Văn Bản Hướng Tóm Lược Cơ Sở [128] -
 Mẫu Tóm Tắt Gồm Bản Tóm Tắt Tham Chiếu, Bản Tóm Tắt Của Mô Hình Trong
Mẫu Tóm Tắt Gồm Bản Tóm Tắt Tham Chiếu, Bản Tóm Tắt Của Mô Hình Trong -
 Mô Hình Sử Dụng Thuật Toán Phân Cụm K-Means Kết Hợp Vị Trí Tương Đối Của Câu
Mô Hình Sử Dụng Thuật Toán Phân Cụm K-Means Kết Hợp Vị Trí Tương Đối Của Câu
Xem toàn bộ 185 trang tài liệu này.

Bảng 3.13. Giá trị các siêu tham số và thời gian huấn luyện các mô hình xây dựng
Các kết quả thử nghiệm của các mô hình thu được như trong Bảng 3.14 dưới đây.
CNN | Baomoi | |||||
R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
BERT-Tiny/mBERT + CNN + seq2seq | 29,55 | 11,67 | 27,12 | 51,17 | 23,83 | 36,54 |
BERT-Tiny/mBERT + CNN + seq2seq + MMR | 30,09 | 11,95 | 27,80 | 51,41 | 24,01 | 36,92 |
BERT-Tiny/mBERT + CNN + seq2seq + DeepQL | 30,49 | 12,22 | 27,89 | 51,73 | 24,10 | 37,18 |
BERT-Tiny/mBERT + CNN + seq2seq + DeepQL + MMR | 31,36 | 12,84 | 28,33 | 51,95 | 24,38 | 37,56 |
Mô hình
Bảng 3.14. Kết quả thử nghiệm của các mô hình xây dựng
Với các kết quả thử nghiệm trình bày trong Bảng 3.14, mặc dù mô hình 1 chưa xử lý loại bỏ các câu trùng lặp nhưng đã cho kết quả khả quan và tốt hơn các phương pháp như LexRank, TextRank, LEAD (Bảng 3.1) trên cả hai bộ dữ liệu CNN, Baomoi tương ứng. Trong mô hình 2, phương pháp MMR được kết hợp vào mô hình tóm tắt để loại bỏ các thông tin trùng lặp đã cho kết quả tốt hơn mô hình 1. Mô hình 3 mặc dù chưa xử lý loại bỏ các thông tin trùng lặp nhưng việc kết hợp kỹ thuật học tăng cường Deep Q-Learning đã cho kết quả tốt hơn so với mô hình 1 và thậm chí tốt hơn cả mô hình 2, điều này chứng tỏ mô hình tóm tắt kết hợp với kỹ thuật học tăng cường đã cho kết quả tốt. Với việc sử dụng phương pháp MMR, mô hình 4 đã cho các kết quả tốt hơn rò rệt so với mô hình 3 trên cả hai bộ dữ liệu CNN và Baomoi.
Có thể thấy rằng, kết quả thử nghiệm của mô hình 4 là tốt nhất trong các mô hình xây dựng và mô hình 4 được chọn cho phương pháp tóm tắt đề xuất mBERT- Tiny_seq2seq_DeepQL_ESDS.
Bảng 3.15 biểu diễn một mẫu tóm tắt gồm bản tóm tắt tham chiếu của con người và bản tóm tắt đầu ra của phương pháp tóm tắt đề xuất mBERT- Tiny_seq2seq_DeepQL_ESDS trên bộ dữ liệu CNN. Văn bản nguồn của mẫu tóm tắt này xem Phụ lục C.3trong phần Phụ lục.
Bản tóm tắt của phương pháp mBERT-Tiny_seq2seq_DeepQL_ESDS The Shariya refugee camp opened around six months ago , made up of some 4,000 tents and counting . The vast majority of the camp 's occupants are from the town of Sinjar , which is near the border with Syrian Kurdistan , and fled the ISIS assault there back in August . The fighters separated the young women and girls , some as young as 8 years old , to be sold as slaves , for their " masters " to use as concubines. |
Bảng 3.15. Một mẫu tóm tắt trên bộ dữ liệu CNN
Bảng 3.16 biểu diễn một mẫu tóm tắt gồm bản tóm tắt tham chiếu của con người và bản tóm tắt đầu ra của mô hình tóm tắt đề xuất mBERT- Tiny_seq2seq_DeepQL_ESDS trên bộ dữ liệu Baomoi. Văn bản nguồn của mẫu tóm tắt này xem Phụ lục C.3trong phần Phụ lục.
Bản tóm tắt của phương pháp mBERT-Tiny_seq2seq_DeepQL_ESDS Chắc chắn rằng SVĐ San Siro sẽ lại rực sáng khi mà các tifosi của họ sẽ chứng kiến màn ra mắt đầu tiên của cựu cầu thủ Clarence Seedorf trong cương vị HLV trưởng của AC Milan . Vì vậy , thày trò ông Antonio Conte hoàn toan tự tin sẽ có trận thắng thứ 18 trong mùa giải này trong trận đấu vào đêm thứ Bảy tới. |
Bảng 3.16. Một mẫu tóm tắt trên bộ dữ liệu Baomoi
Như vậy, các kết quả thực nghiệm trên hai bộ dữ liệu CNN và Baomoi cho thấy phương pháp tóm tắt đề xuất mBERT-Tiny_seq2seq_DeepQL_ESDS đã cho kết quả tốt cho tóm tắt văn bản tiếng Anh và tiếng Việt.
3.4.5. Đánh giá và so sánh kết quả
Kết quả thử nghiệm của phương pháp tóm tắt đề xuất được so sánh với kết quả thử nghiệm của các phương pháp mà nghiên cứu sinh đã thử nghiệm và các phương pháp hiện đại khác đã công bố trên cùng các bộ dữ liệu thử nghiệm. Kết quả so sánh và đánh giá được trình bày như trong Bảng 3.17 dưới đây.
CNN | Baomoi | |||||
R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
LexRank* | 22,9 | 6,6 | 17,2 | 38,5 | 17,0 | 28,9 |
TextRank* | 26,0 | 7,3 | 19,2 | 44,7 | 19,2 | 32,9 |
LEAD* | 29,0 | 10,7 | 19,3 | 46,5 | 20,3 | 30,8 |
Cheng và Lapata (2016) [125] | 28,4 | 10,0 | 25,0 | - | - | - |
REFRESH [125] | 30,4 | 11,7 | 26,9 | - | - | - |
BERT-Tiny/mBERT + CNN + seq2seq§ | 29,55 | 11,67 | 27,12 | 51,17 | 23,83 | 36,54 |
BERT-Tiny/mBERT + CNN + seq2seq + MMR§ | 30,09 | 11,95 | 27,80 | 51,41 | 24,01 | 36,92 |
BERT-Tiny/mBERT + CNN + seq2seq + DeepQL§ | 30,49 | 12,22 | 27,89 | 51,73 | 24,10 | 37,18 |
BERT-Tiny/mBERT + CNN + seq2seq + DeepQL + MMR§ | 31,36 | 12,84 | 28,33 | 51,95 | 24,38 | 37,56 |
Bảng 3.17. So sánh và đánh giá kết quả các phương pháp
(các ký hiệu ‘*’, ‘-’ và ‘§' trong Bảng 3.17 ở trên biểu diễn các phương pháp đã thử nghiệm, không thử nghiệm và các mô hình xây dựng thử nghiệm trên các bộ dữ liệu tương ứng)
Kết quả trong Bảng 3.17 cho thấy phương pháp tóm tắt đề xuất có kết quả tốt hơn đáng kể so với các hệ thống hiện đại khác trên hai bộ dữ liệu CNN và Baomoi tương ứng. Điều này chứng tỏ phương pháp tóm tắt đề xuất mBERT- Tiny_seq2seq_DeepQL_ESDS đã đạt hiệu quả tốt cho tóm tắt văn bản tiếng Anh và tiếng Việt.
3.5. So sánh đánh giá ba mô hình tóm tắt đơn văn bản hướng trích rút đề xuất
Sau đây là kết quả so sánh đánh giá 3 mô hình tóm tắt đơn văn bản hướng trích rút đã đề xuất theo hai tiêu chí độ chính xác và thời gian thực hiện trên các bộ dữ liệu thử nghiệm cho tóm tắt văn bản tiếng Anh và tiếng Việt.
Bảng 3.18 dưới đây trình bày kết quả độ chính xác của 3 mô hình đề xuất.
CNN | Baomoi | |||||
R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
RoPhoBERT_MLP_ESDS | 32,18 | 12,31 | 28,87 | 52,511 | 24,696 | 37,796 |
mBERT_CNN_ESDS | 32,67 | 13,04 | 29,53 | 54,67 | 25,26 | 37,48 |
mBERT- Tiny_seq2seq_DeepQL_ESDS | 31,36 | 12,84 | 28,33 | 51,95 | 24,38 | 37,56 |
Bảng 3.18. So sánh đánh giá độ chính xác của 3 mô hình đề xuất
Bảng 3.18 cho thấy cả ba mô hình tóm tắt đề xuất đã đạt được hiệu quả cao cho bài toán tóm tắt đơn văn bản hướng trích rút (kết quả của mỗi mô hình đã được đánh giá và so sánh với các hệ thống khác trên cùng các bộ dữ liệu tương ứng khi thử nghiệm). Có thể nói, mô hình mBERT_CNN_ESDS với việc sử dụng mô hình BERT đa ngôn ngữ để mã hóa văn bản đầu vào và mô hình phân loại câu được xây dựng bằng việc kết hợp nhiều mô hình học sâu để tận dụng ưu điểm của các mô hình học sâu này đã cho kết quả cao nhất trong hầu hết các độ đo. Mô hình RoPhoBERT_MLP_ESDS mặc dù đã sử dụng các mô hình BERT tối ưu để mã hóa văn bản đầu vào nhưng cho kết quả độ chính xác không cao bằng mô hình mBERT_CNN_ESDS (trừ độ đo R-L cho tiếng Việt), lý do là do mô hình phân loại câu chỉ sử dụng mạng MLP (mô hình phân loại của mô hình này là đơn giản nhất trong 3 mô hình đề xuất). Mô hình mBERT-Tiny_seq2seq_DeepQL_ESDS mặc dù mô hình phân loại câu đã sử dụng nhiều kỹ thuật học sâu và kết hợp với kỹ thuật học tăng cường để cải thiện độ chính xác của mô hình tính xác suất của câu được chọn nhưng vẫn cho kết quả thấp nhất trong 3 mô hình đề xuất là do mô hình này sử dụng mô hình BERT thu nhỏ để mã hóa văn bản đầu vào (hiệu quả của các mô hình BERT thu nhỏ thấp hơn, nhưng thời gian thực thi lại nhanh hơn nhiều so với các mô hình BERT, BERT tối ưu). Do đó, mô hình mBERT-Tiny_seq2seq_DeepQL_ESDS có thể đáp ứng được các yêu cầu ràng buộc về tài nguyên bị hạn chế và thời gian thực thi nhanh.
Để đánh giá hiệu quả về thời gian thực thi, ba mô hình đề xuất được thực hiện đánh giá trên tập gồm 100 văn bản được lấy ngẫu nhiên từ 2 bộ dữ liệu CNN/Daily Mail và bộ dữ liệu Baomoi (mỗi bộ dữ liệu được lấy ngẫu nhiên 100 văn bản để đánh giá) để ghi nhận tổng thời gian thực hiện của từng mô hình, sau đó tính trung bình số lượng văn bản thực thi trong 1 giây của mỗi mô hình. Bảng 3.19 dưới đây trình bày chi tiết hiệu quả về thời gian thực hiện của ba mô hình. Có thể thấy rằng, mô hình mBERT-Tiny_seq2seq_DeepQL_ESDS với việc sử dụng mô hình BERT thu nhỏ (BERT-Tiny) để mã hóa văn bản tiếng Anh đầu vào (mô hình này vẫn dùng mBERT cho mã hóa văn bản tiếng Việt do mô hình BERT-Tiny không hỗ trợ cho tiếng Việt) có thời gian thực hiện tóm tắt nhanh nhất. Cụ thể như sau: Trong 1 giây, mô hình này có thể tóm tắt được trung bình 22,1 văn bản, trong khi đó 2 mô hình còn lại RoPhoBERT_MLP_ESDS, mBERT_CNN_ESDS tương ứng chỉ tóm tắt được trung bình 1,30 văn bản và 0,62 văn bản. Như vậy, có thể nói mô hình mBERT-Tiny_seq2seq_DeepQL_ESDS thực hiện nhanh hơn 2 mô hình RoPhoBERT_MLP_ESDS và mBERT_CNN_ESDS tương ứng là 17 lần và 35,65 lần. Khi đánh giá đối với tiếng Việt thì 3 mô hình cho hiệu quả thời gian xấp xỉ nhau, chỉ có mô hình RoPhoBERT_MLP_ESDS là nhanh hơn là do bộ phân loại câu được xây dựng có kiến trúc đơn giản nhất trong 3 mô hình (chỉ gồm MLP).
Ngoài ra, để đánh giá một cách khách quan hiệu quả thời gian thực hiện của mô hình mBERT-Tiny_seq2seq_DeepQL_ESDS, luận án cũng thử nghiệm mô hình này bằng cách sử dụng mô hình mBERT thay cho BERT-Tiny khi mã hóa cho văn bản tiếng Anh và kết quả thu được là 0,63 văn bản/1 giây.
Ngôn ngữ | Mô hình mã hóa văn bản | Số lượng văn bản trung bình/1 giây | |
RoPhoBERT_MLP_ESDS | Tiếng Anh | RoBERTa | 1,30 |
mBERT_CNN_ESDS | Tiếng Anh | mBERT | 0,62 |
mBERT- Tiny_seq2seq_DeepQL_ESDS | Tiếng Anh | BERT-Tiny | 22,1 |
RoPhoBERT_MLP_ESDS | Tiếng Việt | PhoBERT | 3,64 |
mBERT_CNN_ESDS | Tiếng Việt | mBERT | 2,61 |
mBERT- Tiny_seq2seq_DeepQL_ESDS | Tiếng Việt | mBERT | 2,61 |
mBERT- Tiny_seq2seq_DeepQL_ESDS | Tiếng Anh | mBERT | 0,63 |
Bảng 3.19. So sánh đánh giá thời gian thực hiện của 3 mô hình đề xuất
Như vậy, có thể nói mô hình mBERT-Tiny_seq2seq_DeepQL_ESDS mặc dù cho kết quả độ chính xác không cao bằng 2 mô hình còn lại, nhưng mô hình lại có hiệu quả về thời gian và có thể đáp ứng được các yêu cầu về tài nguyên hạn chế.
3.6. Kết luận chương 3
Trong chương này, luận án đã đề xuất phát triển ba mô hình tóm tắt đơn văn bản hướng trích rút áp dụng hiệu quả cho tóm tắt văn bản tiếng Anh và tiếng Việt sử
dụng các kỹ thuật học sâu kết hợp với các kỹ thuật hiệu quả khác trong tóm tắt văn bản. Các kết quả đạt được cụ thể như sau:
Mô hình tóm tắt RoPhoBERT_MLP_ESDS:
- Véc tơ hóa văn bản đầu vào sử dụng các mô hình tối ưu RoBERTa (tiếng Anh), PhoBERT (tiếng Việt) làm đầu vào cho mô hình phân loại sử dụng MLP.
- Kết hợp đặc trưng vị trí câu vào mô hình tóm tắt.
- Cải tiến phương pháp MMR và sử dụng để lựa chọn câu đưa vào bản tóm tắt.
- Thử nghiệm và đánh giá kết quả mô hình đề xuất RoPhoBERT_MLP_ESDS cho tóm tắt đơn văn bản tiếng Anh, tiếng Việt trên bộ dữ liệu CNN, Baomoi tương ứng.
Mô hình tóm tắt mBERT_CNN_ESDS:
- Véc tơ hóa văn bản đầu vào sử dụng mô hình BERT đa ngôn ngữ được huấn luyện trước.
- Đề xuất và tinh chỉnh mạng CNN sử dụng một hàm kích hoạt mới để trích chọn các đặc trưng của câu.
- Đề xuất mô hình seq2seq với bộ mã hóa và bộ giải mã sử dụng mạng biLSTM 2 chiều để liên kết ngữ cảnh của các câu trong văn bản.
- Kết hợp đặc trưng TF-IDF vào mô hình.
- Đề xuất sử dụng một lớp kết nối đầy đủ FC với hàm kích hoạt softmax để phân loại các câu được chọn đưa vào bản tóm tắt.
- Sử dụng phương pháp MMR để loại bỏ thông tin dư thừa cho bản tóm tắt.
- Thử nghiệm và đánh giá kết quả mô hình đề xuất mBERT_CNN_ESDS cho tóm tắt đơn văn bản tiếng Anh, tiếng Việt trên bộ dữ liệu CNN, Baomoi tương ứng.
Mô hình tóm tắt mBERT-Tiny_seq2seq_DeepQL_ESDS:
- Véc tơ hóa văn bản đầu vào sử dụng mô hình BERT-Tiny cho tiếng Anh và mô hình mBERT cho tiếng Việt.
- Đề xuất sử dụng mạng CNN để trích rút đặc trưng của văn bản để trích xuất các đặc trưng của câu.
- Đề xuất mô hình seq2seq với bộ mã hóa sử dụng mạng biGRU để mã hóa văn bản và bộ giải mã sử dụng mạng GRU để trích rút câu.
- Đề xuất sử dụng mạng FC với hàm kích hoạt softmax để phân loại các câu được chọn đưa vào bản tóm.
- Huấn luyện bộ trích rút câu sử dụng kỹ thuật học tăng cường Deep Q-Learing để tăng hiệu quả cho mô hình tính xác suất được chọn của câu.
- Sử dụng phương pháp MMR để loại bỏ thông tin dư thừa cho bản tóm tắt.
- Thử nghiệm và đánh giá kết quả mô hình đề xuất mBERT- Tiny_seq2seq_DeepQL_ESDS cho tóm tắt đơn văn bản tiếng Anh, tiếng Việt trên bộ dữ liệu CNN, Baomoi tương ứng.
Các kết quả đạt được của chương đã được công bố trong các công trình [CT3], [CT4], [CT5]. Trong chương tiếp theo, luận án sẽ nghiên cứu đề xuất mô hình tóm tắt đơn văn bản hướng tóm lược cho văn bản tiếng Anh và tiếng Việt.
Chương 4. PHÁT TRIỂN PHƯƠNG PHÁP TÓM TẮT ĐƠN VĂN BẢN HƯỚNG TÓM LƯỢC
Các kỹ thuật học sâu đã đạt được hiệu quả cao trong các nhiệm vụ xử lý ngôn ngữ tự nhiên khi dữ liệu mẫu sẵn có lớn. Tuy nhiên, trong bài toán tóm tắt văn bản hướng tóm lược, một vấn đề khó khăn gặp phải là dữ liệu mẫu sẵn có không đủ lớn để có thể huấn luyện mô hình học sâu hiệu quả. Việc thiếu dữ liệu này chủ yếu do quá trình tạo ra các bộ dữ liệu đòi hỏi phải tiêu tốn nhiều công sức từ những chuyên gia có kinh nghiệm, chuyên môn sâu trong lĩnh vực và thực tế cho thấy hiện nay chưa có một bộ dữ liệu nào đủ lớn để đáp ứng hiệu quả cho bài toán tóm tắt văn bản theo hướng tóm lược. Vấn đề này gây ra khó khăn đối với các nghiên cứu trên thế giới nói chung và các nghiên cứu tại Việt Nam nói riêng. Tuy nhiên, yêu cầu đặt ra đối với các hệ thống tóm tắt văn bản là vẫn phải phải đạt được hiệu quả cao. Để giải quyết vấn đề này, trong chương này luận án đề xuất một phương pháp tóm tắt đơn văn bản hướng tóm lược sử dụng các mô hình học sâu có thể áp dụng hiệu quả cho tóm tắt văn bản, đó là mô hình PG_Feature_ASDS. Mô hình đề xuất được thử nghiệm trên các bộ dữ liệu CNN/Daily Mail cho tóm tắt văn bản tiếng Anh và Baomoi cho tóm tắt văn bản tiếng Việt.
4.1. Giới thiệu bài toán và hướng tiếp cận
Tóm tắt đơn văn bản hướng tóm lược sinh ra một văn bản tóm tắt ngắn gọn, cô đọng, nắm bắt được nội dung chính của văn bản nguồn. Để sinh bản tóm tắt, tóm tắt hướng tóm lược thực hiện viết lại và nén văn bản nguồn (tương tự như cách con người tóm tắt văn bản) thay vì lựa chọn các câu quan trọng từ văn bản đầu vào như trong tóm tắt đơn văn bản hướng trích rút.
Bài toán tóm tắt đơn văn bản hướng tóm lược được phát biểu như sau: Cho một
văn bản D gồm N câu được biểu diễn là
D (s1, s2 ,..., si ,...., sN )
với
i 1, N , si là
câu thứ i trong văn bản hay văn bản được biểu diễn dưới dạng
X (x1, x2 ,..., xi ,...., xJ ) ; trong đó: xi là từ thứ i trong văn bản, J là số lượng từ của
văn bản. Nhiệm vụ của bài toán tóm tắt đơn văn bản hướng tóm lược là sinh ra bản
tóm tắt gồm T từ được biểu diễn là Y ( y1, y2 ,..., y j ,...., yT )
(với
j 1,T ) biểu diễn
nội dung chính của văn bản X (T < J), trong đó:
y j là các từ có thể thuộc văn bản
nguồn ( y j X ) hoặc không thuộc văn bản nguồn ( y j X ) khi đó nó sẽ thuộc bộ từ vựng.
Luận án tiếp cận theo hướng đưa bài toán tóm tắt đơn văn bản hướng tóm lược
về bài toán sinh văn bản. Ở mỗi bước, một mô hình sẽ sinh ra 1 từ dựa vào các từ đã
được sinh ra trước đó. Với văn bản đầu vào
X (x1, x2 ,..., xi ,...., xJ ) , mô hình sẽ
ước lượng xác suất có điều kiện
p( y1, y2 ,...., yT | x1, x2 ,...., xJ )
với:
x1, x2 ,...., xJ là
các từ trong chuỗi đầu vào và y1, y2 ,...., yT là các từ của chuỗi đầu ra tương ứng, được tính theo công thức:
T
p( y1, y2 ,...., yT | x1, x2 ,...., xJ ) p( yt | ,v, y1, y2 ,...., yt 1 )
t 1
(4.1)
trong đó:
+ θ là tập tham số của mô hình cần xây dựng.
+ v là trạng thái ẩn đại diện cho chuỗi từ đầu vào
x1, x2 ,...., xJ .
+
bước t.
p( yt | ,v, y1, y2 ,...., yt 1)
là phân bố xác suất của các từ trong bộ từ vựng ở
Sau đó, từ tập các phân bố xác suất này kết hợp với chiến lược tìm kiếm để sinh ra bản tóm tắt tóm lược cuối cùng (trong luận án sử dụng kỹ thuật tìm kiếm Beam).
Mục tiêu đặt ra là đi xây dựng và huấn luyện mô hình để tìm tập tham số sao
cho xác suất
p( yt | ,, y1, y2 ,...., yt 1)
lớn nhất với
yt Y tại bước t. Điều này
tương đương với việc tối thiểu hóa hàm mất mát cross - entropy:
T
L() log p( yt | ,, y1, y2 ,...., yt 1 )
t 1
(4.2)
Các nghiên cứu gần đây thường sử dụng mô hình seq2seq để phát triển các mô hình giải quyết vấn đề này nhằm xây dựng các hệ thống tóm tắt văn bản hướng tóm lược hiệu quả. Rush và cộng sự [115] đã áp dụng mô hình seq2seq với bộ mã hóa sử dụng mạng CNN kết hợp với cơ chế chú ý theo ngữ cảnh để sinh ra bản tóm tắt tóm lược. Nallapati và cộng sự [128] đã sử dụng mạng seq2seq với cơ chế chú ý để sinh bản tóm tắt dài hơn. Gu và cộng sự [130] đề xuất một mạng CopyNet dựa trên mạng sinh từ - sao chép từ (Pointer - Generator) [131] để khắc phục vấn đề thiếu từ trong bộ từ vựng để sinh bản tóm tắt. Bằng việc sử dụng mạng Pointer - Generator [131] và cơ chế phân tán [132], See và cộng sự [43] đã cải tiến mạng trong [128] để tạo ra một hệ thống tóm tắt tốt hơn để giải quyết vấn đề thiếu từ trong bộ từ vựng và lỗi lặp từ để sinh bản tóm tắt tóm lược. Tuy nhiên, kiến trúc ban đầu của mô hình seq2seq nhận văn bản đầu vào ngắn vì seq2seq là "bộ nhớ ngắn hạn", nghĩa là mô hình thường xử lý các câu "gần" nhưng lại "quên" các câu ở xa hơn. Do đó, hầu hết các mô hình tóm tắt văn bản sử dụng mô hình seq2seq này có xu hướng bỏ qua phần đầu của văn bản nếu văn bản đầu vào dài. Đây là thách thức đặt ra đối với các mô hình tóm tắt mà mục tiêu xử lý là các bài báo với các thông tin quan trọng thường nằm ở phần đầu của bài báo.
Trong chương này, luận án đề xuất phát triển một mô hình tóm tắt đơn văn bản hướng tóm lược có thể xem xét toàn bộ văn bản đầu vào và sinh ra một bản tóm tắt gồm nhiều câu. Dựa trên mô hình tóm tắt hướng tóm lược cơ sở [128] - mô hình sử dụng mô hình seq2seq có bộ mã hóa sử dụng mạng biLSTM và bộ giải mã sử dụng mạng LSTM với cơ chế chú ý; cơ chế sao chép từ - sinh từ và cơ chế bao phủ (Coverage) [43], luận án nghiên cứu cải tiến mô hình bằng việc đề xuất thêm các đặc trưng vị trí câu (POSI) và tần suất xuất hiện của từ (TF) trong văn bản cho mô hình. Mô hình đề xuất được thử nghiệm và đánh giá trên hai bộ dữ liệu CNN/Daily Mail cho tóm tắt văn bản tiếng Anh và Baomoi cho tóm tắt văn bản tiếng Việt. Các thử nghiệm cho thấy mô hình đề xuất cho kết quả tốt hơn so với mô hình cơ sở và các phương pháp hiện có trên cùng các bộ dữ liệu thử nghiệm.