Bảng 4.3 biểu diễn một mẫu thử nghiệm bao gồm bản tóm tắt tham chiếu, bản tóm tắt của mô hình [43] và bản tóm tắt của mô hình đề xuất PG_Feature_ASDS. Văn bản nguồn của mẫu thử nghiệm này xem Phụ lục C.4trong phần Phụ lục.
Mary Todd Lowrance, teacher at Moises e Molina high school, turned herself into Dallas independent school district police on Thursday morning. Dallas isd police said she had been in a relationship with student, who is older than 17 years old, for a couple of months. She confided in coworker who alerted authorities and police eventually got arrest warrant. Lowrance was booked into county jail on $ 5,000 bond and has been released from the Dallas county jail, according to county records. She has been on leave for several weeks while investigators worked on the case, police said. |
Bản tóm tắt của mô hình Pointer-Generator, Coverage [43] |
Lowrance Lowrance was accused of a male school on a $ 5,000 bond. Lowrance has been on leave for several weeks while investigators worked on the case. The student has been offered counseling warrant. |
Bản tóm tắt của mô hình PG_Feature_ASDS |
Mary Todd Lowrance, 49, arrested after being accused of having an improper relationship with a male student older than 17 years old. Miller said the teacher had been in a relationship with the student for a couple of months. Officers learned of the alleged relationship after Lowrance disclosed details to a coworker who then alerted a Dallas isd officer. |
Có thể bạn quan tâm!
-
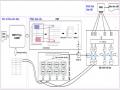
 Các Kết Quả Thử Nghiệm Của Các Mô Hình Xây Dựng
Các Kết Quả Thử Nghiệm Của Các Mô Hình Xây Dựng -
 Giá Trị Các Siêu Tham Số Và Thời Gian Huấn Luyện Các Mô Hình Xây Dựng
Giá Trị Các Siêu Tham Số Và Thời Gian Huấn Luyện Các Mô Hình Xây Dựng -
![Mô Hình Tóm Tắt Đơn Văn Bản Hướng Tóm Lược Cơ Sở [128]](https://tailieuthamkhao.com/uploads/2022/06/10/nghien-cuu-phat-trien-mot-so-phuong-phap-tom-tat-van-ban-su-dung-ky-13-1-120x90.jpg) Mô Hình Tóm Tắt Đơn Văn Bản Hướng Tóm Lược Cơ Sở [128]
Mô Hình Tóm Tắt Đơn Văn Bản Hướng Tóm Lược Cơ Sở [128] -
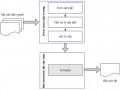 Mô Hình Sử Dụng Thuật Toán Phân Cụm K-Means Kết Hợp Vị Trí Tương Đối Của Câu
Mô Hình Sử Dụng Thuật Toán Phân Cụm K-Means Kết Hợp Vị Trí Tương Đối Của Câu -
 Các Mẫu Tóm Tắt Của Cụm D0716D Trong Bộ Dữ Liệu Duc 2007 Của Mô Hình Đề Xuất Và Con Người
Các Mẫu Tóm Tắt Của Cụm D0716D Trong Bộ Dữ Liệu Duc 2007 Của Mô Hình Đề Xuất Và Con Người -
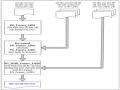 Các Giai Đoạn Huấn Luyện Mô Hình Tóm Tắt Đa Văn Bản Hướng Tóm Lược Đề Xuất Pg_Feature_Amds
Các Giai Đoạn Huấn Luyện Mô Hình Tóm Tắt Đa Văn Bản Hướng Tóm Lược Đề Xuất Pg_Feature_Amds
Xem toàn bộ 185 trang tài liệu này.

Bảng 4.3. Mẫu tóm tắt gồm bản tóm tắt tham chiếu, bản tóm tắt của mô hình trong
[43] và bản tóm tắt của mô hình đề xuất trên bộ dữ liệu CNN/Daily Mail
Như có thể thấy trong Bảng 4.3, bản tóm tắt của hệ thống đề xuất đưa ra nhiều thông tin hơn so với bản tóm tắt của mô hình trong [43] và các từ không bị lặp lại.
Một mẫu tóm tắt với một bài báo của bộ dữ liệu Baomoi được biểu diễn trong Bảng 4.4 bên dưới. Văn bản nguồn của mẫu thử nghiệm này xem Phụ lục C.4trong phần Phụ lục.
Một xưởng sản xuất phi pháp tại Tức Mặc, Thanh đảo, Trung quốc vừa bị phát hiện sử dụng 1.000 kg dầu bẩn để chế biến bánh trung thu. |
Bản tóm tắt của mô hình Pointer-Generator, Coverage [43] |
Sự việc bị phanh phui vào ngày 30/8 vừa qua. Cơ quan an toàn thực phẩm, phòng công thương, công an và chính quyền thị xã đã phối hợp điều tra sự việc bị phanh phui vào ngày 30/8 vừa qua. |
1.000 kg dầu bẩn vừa được chuyển tới bởi một xe tải chở hàng. Theo nguồn tin thân cậy, số dầu này có xuất xứ từ một xưởng chế biến tại mã điếm, Giao Châu. Ngày 31/8, một tổ công tác gồm phòng an toàn thực phẩm, công an và chính quyền thị xã đã phối hợp điều tra sự việc này. |
Bản tóm tắt của mô hình PG_Feature_ASDS
Bảng 4.4. Mẫu tóm tắt gồm bản tóm tắt tham chiếu, bản tóm tắt của mô hình trong
[43] và bản tóm tắt của mô hình đề xuất trên bộ dữ liệu Baomoi
Trong Bảng 4.4, có thể thấy thông tin chính của văn bản là: “1.000 kg dầu bẩn vừa được chuyển tới bởi một xe tải chở hàng. Theo nguồn tin thân cậy, số dầu này có xuất xứ từ một xưởng chế biến tại mã điếm, Giao Châu. Ngày 31/8, một tổ công tác gồm phòng an toàn thực phẩm, công an và chính quyền thị xã đã phối hợp điều tra sự việc này”. Bản tóm tắt tham chiếu chứa hầu hết các thông tin trên. Bản tóm tắt do mô hình trong [43] sinh ra không chứa thông tin quan trọng là “1.000 kg dầu bẩn” và chỉ cung cấp một phần thông tin cần thiết. Ngoài ra, mặc dù văn bản tóm tắt đầu ra của mô hình trong [43] ngắn và thiếu thông tin chính, cụm từ “sự việc bị phanh phui vào ngày 30/8 vừa qua” bị lặp lại hai lần. Trong khi đó, bản tóm tắt được sinh ra bởi mô hình đề xuất PG_Feature_ASDS đã cung cấp nhiều thông tin hơn so với mô hình trong [43] và không chứa các cụm từ lặp lại.
Như vậy, có thể thấy bản tóm tắt đầu ra của mô hình đề xuất dễ hiểu và không có lỗi ngữ pháp đối với cả hai bộ dữ liệu tiếng Anh và tiếng Việt.
4.6. Kết luận chương 4
Trong chương này, luận án đã đề xuất phát triển một mô hình tóm tắt đơn văn bản hướng tóm lược hiệu quả cho tóm tắt văn bản tiếng Anh và tiếng Việt sử dụng các kỹ thuật học sâu, các kỹ thuật hiệu quả khác và kết hợp các đặc trưng của văn bản cho mô hình tóm tắt. Các kết quả đạt được cụ thể như sau:
- Véc tơ hóa văn bản đầu vào sử dụng phương pháp word2vec.
- Sử dụng mạng seq2seq với bộ mã hóa sử dụng mạng biLSTM và bộ giải mã sử dụng mạng LSTM kết hợp cơ chế chú ý, cơ chế sinh từ - sao chép từ và cơ chế bao phủ cho mô hình tóm tắt.
- Kết hợp các đặc trưng vị trí câu và tần suất xuất hiện của từ vào mô hình tóm
tắt.
- Thử nghiệm và đánh giá kết quả mô hình tóm tắt đề xuất PG_Feature_ASDS
cho tóm tắt văn bản tiếng Anh, tiếng Việt sử dụng các bộ dữ liệu CNN/Daily Mail, Baomoi tương ứng.
Kết quả đạt được của chương đã được công bố trong công trình [CT2]. Trong chương tiếp theo, luận án sẽ nghiên cứu đề xuất một mô hình tóm tắt đa văn bản hướng trích rút và các mô hình tóm tắt đa văn bản hướng tóm lược cho tóm tắt văn bản tiếng Anh và tiếng Việt.
Chương 5. PHÁT TRIỂN CÁC PHƯƠNG PHÁP TÓM TẮT ĐA VĂN BẢN
Trong chương này, trước hết luận án đề xuất phát triển một mô hình tóm tắt đa văn bản hướng trích rút Kmeans_Centroid_EMDS cho tóm tắt tiếng Anh và tiếng Việt sử dụng kỹ thuật phân cụm K-means, phương pháp dựa trên trung tâm (Centroid-based), MMR và đặc trưng vị trí câu để tạo bản tóm tắt. Mô hình Kmeans_Centroid_EMDS được thử nghiệm trên bộ dữ liệu DUC 2007 (tiếng Anh) và Corpus_TMV (tiếng Việt). Sau đó, luận án đề xuất phát triển mô hình tóm tắt đa văn bản hướng tóm lược PG_Feature_AMDS dựa trên mô hình tóm tắt đơn văn bản hướng tóm lược được huấn luyện trước đã phát triển ở chương 4 và tinh chỉnh mô hình tóm tắt đơn văn bản này bằng việc huấn luyện tiếp trên các bộ dữ liệu tóm tắt đa văn bản tương ứng để mô hình đề xuất PG_Feature_AMDS đạt được hiệu quả tốt hơn. Mô hình PG_Feature_AMDS được thử nghiệm sử dụng các bộ dữ liệu DUC 2007 và DUC 2004 (tiếng Anh); các bộ dữ liệu ViMs và bộ dữ liệu Corpus_TMV (tiếng Việt). Cuối cùng, luận án đề xuất phát triển mô hình tóm tắt đa văn bản hướng tóm lược Ext_Abs_AMDS-mds-mmr dựa trên mô hình tóm tắt hỗn hợp được xây dựng từ các mô hình tóm tắt đơn văn bản được huấn luyện trước đã phát triển ở chương 3, chương 4 và tinh chỉnh mô hình tóm tắt hỗn hợp này bằng việc huấn luyện tiếp trên các bộ dữ liệu tóm tắt đa văn bản tương ứng để mô hình đề xuất Ext_Abs_AMDS-mds-mmr cho kết quả tốt hơn. Mô hình Ext_Abs_AMDS-mds-mmr cũng được thử nghiệm sử dụng các bộ dữ liệu DUC 2007 và DUC 2004 (tiếng Anh); các bộ dữ liệu ViMs và bộ dữ liệu Corpus_TMV (tiếng Việt).
5.1. Giới thiệu bài toán tóm tắt đa văn bản và hướng tiếp cận
Ngày nay, khối lượng tin tức được cung cấp trên mạng Internet rất lớn. Có nhiều tin tức đề cập đến cùng một chủ đề với một số chi tiết sửa đổi. Nhu cầu tóm tắt tất cả các tin tức này để có thông tin ngắn gọn về chủ đề được đặt ra và tóm tắt đa văn bản là một giải pháp cho vấn đề này. Tóm tắt đa văn bản với mục đích tạo ra một bản tóm tắt duy nhất mang đầy đủ thông tin của tất cả các văn bản nguồn, bản tóm tắt phải tránh sự trùng lặp thông tin giữa các văn bản có cùng nội dung. Ngoài ra, vấn đề thiếu dữ liệu thử nghiệm cho bài toán tóm tắt đa văn bản cũng gây ra nhiều khó khăn. Có thể nói, thách thức của tóm tắt đa văn bản đặt ra lớn hơn rất nhiều so với bài toán tóm tắt đơn văn bản. Bài toán tóm tắt đa văn bản có thể được chia thành 2 loại được phát biểu như sau:
Bài toán tóm tắt đa văn bản hướng trích rút: Cho tập đa văn bản gồm G văn
bản liên quan đến cùng chủ đề được biểu diễn là
Dmul (D1, D2 ,..., Di ,...., DG ) ; trong
đó:
Di là văn bản thứ i trong tập đa văn bản. Mỗi văn bản
Di gồm H câu
Di (si1, si 2 ,..., sij ,...., siH ) , trong đó:
sij
là câu thứ j của văn bản Di trong tập đa văn
bản Dmul, H có giá trị thay đổi tùy thuộc vào từng văn bản. Nhiệm vụ của tóm tắt đa văn bản hướng trích rút là tạo ra một bản tóm tắt ngắn gọn S từ tập văn bản Dmul
gồm M câu được biểu diễn là
S (s' , s' ,..., s' ,...., s'
) (với M < Tổng số câu của tập
1 2 i M
đa văn bản Dmul), trong đó: s' D , j 1,G . Để giải quyết bài toán tóm tắt đa văn
i j
bản hướng trích rút này, luận án tiếp cận theo hướng đưa bài toán tóm tắt đa văn bản hướng trích rút về bài toán phân cụm văn bản và giải quyết các thách thức đặt ra của bài toán tóm tắt đa văn bản. Phương pháp tóm tắt đa văn bản hướng trích rút đề xuất được trình bày chi tiết trong phần 5.2 dưới đây.
Bài toán tóm tắt đa văn bản hướng tóm lược: Cho tập đa văn bản Dmul gồm G
văn bản liên quan đến cùng chủ đề được biểu diễn là Dmul (D1, D2 ,..., Di ,...., DG ) ;
trong đó:
Di là văn bản thứ i trong tập đa văn bản. Mỗi văn bản
Di được biểu diễn
dưới dạng là
Di (xi1, xi 2 ,..., xij ,...., xiL ) , với:
xij
là từ thứ j của văn bản
Di , L là số
lượng từ của văn bản
Di có giá trị thay đổi tùy thuộc vào từng văn bản. Bản tóm tắt
tóm lược S của tập đa văn bản Dmul được sinh ra gồm T từ được biểu diễn là
Y ( y1, y2 ,..., yi ,...., yT ) ; với:
i 1,T , yi Di
hoặc yi Di
(lúc này từ được lấy từ bộ
từ vựng). Để giải quyết bài toán tóm tắt đa văn bản hướng tóm lược, luận án triển khai tiếp cận theo hai phương pháp là:
- Phương pháp 1: Đưa bài toán tóm tắt đa văn bản hướng tóm lược về bài toán tóm tắt đơn văn bản hướng tóm lược bằng cách ghép các văn bản trong tập đa văn bản thành một “siêu văn bản”, siêu văn bản này được coi như đơn văn bản và áp dụng các kỹ thuật tóm tắt đơn văn bản hướng tóm lược đã đề xuất để sinh bản tóm tắt tóm lược cuối cùng.
- Phương pháp 2: Đưa bài toán tóm tắt đa văn bản hướng tóm lược về bài toán tóm tắt đơn văn bản hướng tóm lược bằng cách tóm tắt từng đơn văn bản của tập đa văn bản để được bản tóm tắt, sau đó ghép các bản tóm tắt này thành một “siêu văn bản”. Siêu văn bản này được coi như một đơn văn bản và áp dụng các kỹ thuật tóm tắt đơn văn bản hướng tóm lược đã đề xuất để sinh bản tóm tắt tóm lược cuối cùng.
Hai phương pháp tóm tắt đa văn bản hướng tóm lược này sẽ được trình bày trong phần 5.3.
5.2. Mô hình tóm tắt đa văn bản hướng trích rút Kmeans_Centroid_EMDS
5.2.1. Giới thiệu mô hình
Các nghiên cứu về tóm tắt đa văn bản hướng trích rút thường nhóm các câu tương tự nhau từ tập đa văn bản đầu vào thành các cụm và chọn các câu trung tâm của mỗi cụm để đưa vào phần tóm tắt [136,137]. Độ tương tự cosine thường được sử dụng để tính toán độ tương tự giữa một cặp câu (các câu được biểu diễn dưới dạng véc tơ có trọng số TF-IDF). Câu có tần suất xuất hiện nhiều nhất được coi là trung tâm của cụm. Tuy nhiên, phương pháp này không xem xét ngữ nghĩa của mỗi từ trong văn bản nên bản tóm tắt sinh ra có thể không tốt về mặt ngữ nghĩa. Một vấn đề khác với cách tiếp cận này là một số cụm có thể chứa thông tin không quan trọng từ các văn bản đầu vào.
Một số nghiên cứu đã áp dụng phương pháp dựa trên trung tâm để sinh ra văn bản tóm tắt như [138,139]. Cách tiếp cận này sinh ra các trung tâm cụm chứa các từ là trung tâm của tất cả các văn bản đầu vào. Bản tóm tắt được sinh ra bằng cách thu thập các câu có chứa các từ trung tâm. Nhược điểm của cách tiếp cận này là không ngăn chặn được sự dư thừa thông tin trong bản tóm tắt. Để giải quyết vấn đề này, Carbonell và Goldstein [116] đã đề xuất phương pháp MMR để sinh ra các bản tóm tắt. Tuy nhiên, cách tiếp cận này không loại bỏ được các câu không quan trọng trong bản tóm tắt. Có thể nói, việc tạo ra một bản tóm tắt mô tả tốt nhất các văn bản đầu vào và chứa thông tin dư thừa ít nhất là một thách thức lớn trong bài toán tóm tắt đa văn bản. Để giải quyết các vấn đề này, luận án nghiên cứu đề xuất phương pháp tiếp cận tóm tắt đa văn bản hướng trích rút sử dụng thuật toán phân cụm K- means để phân cụm các câu của các văn bản đầu vào. Để giải quyết vấn đề chọn các câu đại diện cho các cụm không quan trọng, phương pháp dựa trên trung tâm được sử dụng để tìm các câu trung tâm nhất và loại bỏ các cụm chứa ít thông tin. Ngoài ra, phương pháp MMR được áp dụng để loại bỏ thông tin trùng lặp giữa các câu trong bản tóm tắt. Bản tóm tắt được sinh ra với một trình tự thời gian hợp lý dựa trên đặc trưng vị trí câu trong văn bản được thêm vào mô hình. Phương pháp được mô tả cụ thể như sau: Trước tiên, tập đa văn bản đầu vào Dmul (D1, D2 ,..., Di ,...., DG ) được xử lý ghép thành 1 đơn văn bản lớn duy nhất gồm
N câu được biểu diễn là:
D (s1, s2 ,..., si ,...., sN ) ; với N bằng tổng số câu của tất cả
các văn bản thuộc tập Dmul. Tiếp theo, áp dụng kỹ thuật phân cụm đối với văn bản D
để được K cụm biểu diễn là
C (C1,C2 ,...,Ci ,....,CK )
với:
i 1, K ; trong đó: cụm
i
Ci (si1, si 2 ,..., si n )
gồm ni
câu có tâm cụm tương ứng là ci
được xác định theo
thuật toán. Phương pháp dựa trên trung tâm được sử dụng để tìm các câu trung tâm
i
nhất và loại bỏ các cụm chứa ít thông tin. Câu s* có độ tương đồng lớn nhất với tâm
cụm
ci được chọn để đại diện cho cụm và được tập
S * gồm K câu tương ứng với K
cụm là
S* (s*, s* ,..., s* ) . Cuối cùng, áp dụng phương pháp MMR dựa trên độ
1 2 K
tương đồng và đặc trưng vị trí câu để chọn câu từ tập S * đưa vào bản tóm tắt S.
5.2.2. Các thành phần chính của mô hình
5.2.2.1. Véc tơ hóa câu
Tập các từ tách được từ văn bản đầu vào cần đưa về dạng véc tơ, độ dài của mỗi véc tơ phụ thuộc vào kích thước của bộ từ vựng hoặc kích thước lựa chọn. Mô hình đề xuất sử dụng phương pháp word2vec để véc tơ hóa văn bản đầu vào cho mô hình phân cụm sử dụng thuật toán K-means.
5.2.2.2. K-means cho bài toán phân cụm
, x
N
dN ,
a) Bài toán phân cụm Đầu vào:
+ Có N điểm dữ liệu được biểu diễn liệu chỉ thuộc đúng một cụm duy nhất;
Xx1,x2,
mỗi điểm dữ
+ K là số cụm (cluster) cần tìm ( K N );
Đầu ra:
+ Các trọng tâm của các cụm:
m , m ,…, m
d1.
1 2 K
+ Nhãn của mỗi điểm dữ liệu: Với mỗi điểm dữ liệu
xi , ta gọi
, yiK
yi yi1, yi 2 ,
là véc tơ nhãn của nó, trong đó nếu
xi được phân chia vào
cụm k thì
yij 0,j k (nghĩa là có một phần tử của véc tơ
yi tương ứng với cụm
của
xi bằng 1, còn tất cả các phần tử còn lại bằng 0).
Với điều kiện của véc tơ nhãn, ta viết lại là:
K
yij 0,1,i, j;
yij 1, i.
j1
(5.1)
Nếu ta coi trọng tâm mk là đại diện cho cụm thứ k và một điểm dữ liệu xi
được phân vào cụm k. Véc tơ sai số nếu thay xibằng mklà ximk. Ta muốn véc
tơ sai số này gần với véc tơ không, tức là
xi gần với
mk . Việc này có thể được thực
hiện thông qua việc tối thiểu bình phương khoảng cách Ơclít || x m ||2 .
i k 2
Do x được phân vào cụm k nên biểu thức || x m ||2
được viết lại thành:
i i k 2
K
|| x m ||2 = y || x m ||2 y || x m ||2 (vì y
1, y
0,j k )
i k 2
ik i k 2
j1
ij i j 2
N K
ik ij
Sai số cho toàn bộ dữ liệu là:
L Y , M y || x m ||2
ij i j 2
, yN, M m1, m2, , mK
i1 j1
trong đó: Y y1,y2,
là các ma trận được tạo bởi véc tơ
nhãn của mỗi điểm dữ liệu và trọng tâm của mỗi cụm tương ứng. Hàm mất mát của
bài toán phân cụm K-means là L Y , M với các điều kiện trong công thức (5.1).
Như vậy, ta cần giải bài toán tối ưu:
N K
Y , M arg min y || x m ||2
(5.2)
Y ,M
i1
j1
ij i j 2
K
thỏa mãn điều kiện ràng buộc:
yij 0,1,i, j;
yij 1, i.
j1
Để giải bài toán (5.2) ta giải hai bài toán con sau:
- Bài toán 1: Cố định
M , tìm Y (biết các trọng tâm, cần tìm các véc tơ nhãn)
để hàm mất mát đạt giá trị nhỏ nhất.
+ Với các trọng tâm đã biết, bài toán tìm véc tơ nhãn cho toàn bộ dữ liệu được
đưa về bài toán tìm véc tơ nhãn cho từng điểm dữ liệu
K
xi như sau:
y arg min y || x m ||2
(5.3)
i yi
j 1
ij i j 2
K
thỏa mãn điều kiện:
yij 0,1,i, j;
yij 1, i.
j1
+ Do chỉ có một phần tử của véc tơ nhãn
yi bằng 1 nên bài toán ở (5.3) chính là
bài toán đi tìm cụm j có trọng tâm cụm gần điểm
xi nhất:
j arg min || x m ||2
(5.4)
j i j 2
+ Do
|| x m ||2 là bình phương khoảng cách Ơclít tính từ điểm x đến trọng
i j 2 i
tâm
mj nên ta có thể kết luận là mỗi điểm
xi thuộc vào cụm có trọng tâm gần nó
nhất. Từ đó, có thể suy ra véc tơ nhãn của từng điểm dữ liệu.
- Bài toán 2: Cố định Y , tìm M (biết cụm cho từng điểm, cần tìm trọng tâm
mới cho mỗi cụm) để hàm mất mát đạt giá trị nhỏ nhất.
+ Với véc tơ nhãn cho từng điểm dữ liệu đã biết, bài toán tìm trọng tâm cho mỗi cụm trở thành:
N
m arg min y
|| x m
||2
(5.5)
j m j
i1
ij i j 2
+ Do hàm cần tối ưu là một hàm liên tục và có đạo hàm xác định tại mọi điểm nên ta có thể tìm nghiệm bằng phương pháp giải đạo hàm bằng 0.
N
Đặt l(m ) y || x m ||2 ( l m là hàm bên trong arg min ), ta có đạo hàm:
j ij i j 2 j
i1
l mj 2N
y m
x
(5.6)
mj
i1
ij j i
Giải phương trình đạo hàm bằng 0:
N N
mj yij yij xi
(5.7)
i1
i1
N
Ta có:
yij xi
N
mj i1
yij
i1
N
(5.8)
Trong công thức (5.8), ta thấy
yij là số lượng các điểm dữ liệu trong cụm j
i1
hay mj
chính là trung bình cộng của các điểm trong cụm j.
b) Thuật toán phân cụm K-means
Thuật toán K-means cho bài toán phân cụm dữ liệu [120,121,140] là thuật toán học không giám sát, đây là phương pháp phân cụm phổ biến trong các phương pháp phân cụm dữ liệu. Thuật toán được tóm tắt như dưới đây.
Đầu vào: Tập dữ liệu X, K cụm cần tìm; Đầu ra: Các trọng tâm M,véc tơ nhãn Y cho mỗi điểm dữ liệu; Thuật toán: 1: Khởi tạo ngẫu nhiên K điểm dữ liệu làm các điểm trọng tâm ban đầu của K cụm; |
2: Lặp các bước sau cho đến khi gặp điều kiện hội tụ 2.1: Với mỗi điểm dữ liệu, gán vào cụm có trọng tâm gần nhất;
2.2: Với mỗi cụm, tính toán lại trọng tâm của cụm dựa trên các điểm dữ liệu thuộc cụm đó;
3: Return;
5.2.2.3. Tóm tắt văn bản dựa trên trung tâm
Phương pháp dựa trên trung tâm (Centroid-based) [13] thường được sử dụng trong tóm tắt văn bản để xác định các câu trung tâm trong một tập văn bản đó là các câu có lượng thông tin cần thiết và có nhiều liên quan đến chủ đề chính của tập văn bản. Một véc tơ câu được biểu diễn dựa trên TF-IDF của các từ trong câu. Một từ là
từ trung tâm nếu có giá trị TF-IDF lớn hơn một ngưỡng nhất định sent . Các câu
chứa nhiều từ trung tâm sẽ được chọn đưa vào bản tóm tắt. Mô hình sẽ sử dụng mô hình BoW với trọng số TF-IDF cho bài toán tóm tắt văn bản dựa trên trung tâm.
Thuật toán dựa trên trung tâm cho tóm tắt văn bản được mô tả sau đây.
Đầu vào: Tập các câu; Đầu ra: Bản tóm tắt của tập các câu đầu vào; Thuật toán: 1: Tập các câu tách từ văn bản đầu vào được biểu diễn dưới dạng véc tơ (có kích thước bằng kích thước của bộ từ vựng) sử dụng mô hình BoW với trọng số TF-IDF. 2: Tính véc tơ trung tâm (centroid) v: Kích thước của véc tơ centroid bằng kích thước của bộ từ vựng. Mỗi phần tử aw v biểu diễn cho từ w trong bộ từ vựng được tính theo công thức: awsTF _ IDFw,s , với S là tập S các câu, TF _ IDFw,s là TF-IDF của từ w trong câu s. 3: Tính độ trung tâm của các câu bằng cách tính độ tương đồng của véc tơ câu và véc tơ trung tâm, trong đó nếu một câu có độ trung tâm nhỏ hơn một giá trị ngưỡng sentthì độ trung tâm sẽ được đặt lại bằng 0. Công thức tính độ tương đồng giữa véc tơ câu s và véc 1 cosines,v1 tơ trung tâm v là: sim(s,v) 2 , với: cosine s, v 1s vlà khoảng cách cosin (Cosine || s ||2 || v ||2 distance) giữa s và v. 4: Sắp xếp tập các câu theo thứ tự giảm dần của độ trung tâm đã tính. 5: Bản tóm tắt được sinh ra bằng cách chọn lần lượt các câu trong tập câu đã được sắp xếp đưa vào bản tóm tắt (các câu này phải có thông tin trùng lặp với các |