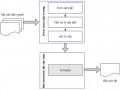
Sau đây, luận án sẽ trình bày và phân tích mô hình của Nallapati và cộng sự [128], được sử dụng làm mô hình cơ sở để phát triển mô hình tóm tắt đề xuất. Sau đó, sẽ trình bày hai cơ chế sử dụng trong [43] để khắc phục các điểm yếu của mô hình cơ sở [128]. Cuối cùng, luận án đề xuất giải pháp giải quyết điểm yếu của mô hình trong [43] để nâng cao hiệu quả cho mô hình tóm tắt.
4.2. Mô hình tóm tắt cơ sở
Các thành phần chính của mô hình tóm tắt đơn văn bản hướng tóm lược cơ sở
[128] được biểu diễn như Hình 4.1 dưới đây.
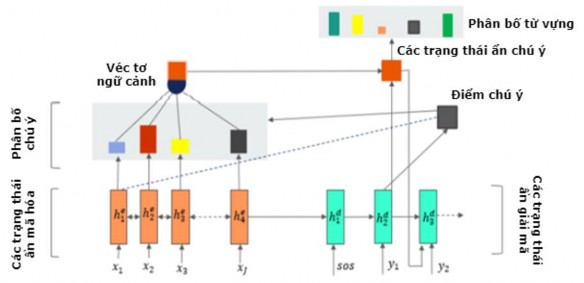
Hình 4.1. Mô hình tóm tắt đơn văn bản hướng tóm lược cơ sở [128]
4.2.1. Mô hình seq2seq của mô hình
Trong mô hình seq2seq, giai đoạn mã hóa sẽ đọc văn bản đầu vào
x x1, x2 , x3,..., xi ,..., xJ và mã hóa thành các trạng thái ẩn mã hóa
1 2 3
j J
hehe, he, he,..., he,..., he, các trạng thái ẩn mã hóa này sẽ là đầu vào cho giai
đoạn giải mã để sinh bản tóm tắt đầu ra
y y1, y2, y3,..., y j,..., yT, trong đó:
- 𝑥𝑖, 𝑦𝑗 tương ứng là véc tơ của các từ của văn bản đầu vào và văn bản tóm tắt.
- 𝐽, 𝑇 tương ứng là số lượng các từ của văn bản đầu vào và văn bản tóm tắt.
Mô hình seq2seq của mô hình cơ sở [128] với bộ mã hóa sử dụng mạng biLSTM và bộ giải mã sử dụng mạng LSTM. Mạng biLSTM của bộ mã hóa sẽ mã hóa chuỗi các từ đầu vào x thành các trạng thái ẩn mã hóa
![]()
![]()
![]()
1 2 3
j J
j j j
j
j
hehe, he, he,..., he,..., hevà
he he he ; với:
he , he
biểu diễn phụ thuộc
![]()
![]()
![]()
1
J
theo chiều tiến, chiều lùi tương ứng, là phép ghép nối, ký hiệu chỉ số trên e biểu thị rằng đó là giai đoạn mã hóa). Mạng LSTM của bộ giải mã hóa sẽ lấy các biểu
J
diễn đã được mã hóa của văn bản (các trạng thái ẩn và trạng thái nhớ
he ,
he ,
ce ,
![]()
1
ce ) làm đầu vào để sinh bản tóm tắt y. Các véc tơ đã mã hóa được sử dụng để khởi tạo các trạng thái ẩn và các trạng thái nhớ cho bộ giải mã như sau:
![]()
hd tanh(W (he he ) b (4.3)
![]()
0
cd ce ce
e2d J 1
e2d
(4.4)
0 J 1
t
với: ký hiệu chỉ số trên d biểu thị rằng đó là giai đoạn giải mã, We2d, 𝑏e2d là các tham
số học. Ở mỗi bước giải mã t, trạng thái ẩn
hd được cập nhật dựa trên trạng thái ẩn
trước đó
d
h
t 1
và các từ đầu vào
E (trong giai đoạn huấn luyện đó là các từ trong
y
t 1
văn bản tóm tắt tham chiếu) được biểu diễn là:
t t1
yt 1
hdLSTM hd, E
(4.5)
Sau đó, phân bố từ vựng sẽ được tính theo công thức:
Pvocab,t
softmax(Wd 2vhd +bd 2v )
(4.6)
t
với: Wd2v, 𝑏𝑑2𝑣 là các tham số học,
Pvocab,t
là véc tơ có kích thước bằng kích thước
của bộ từ vựng 𝑉. Ta sẽ ký hiệu xác suất sinh ra từ mục tiêu w trong bộ từ vựng 𝑉 là
Pvocab,t (w) .
4.2.2. Cơ chế chú ý áp dụng trong mô hình
![]()
1 2 3
J
j j j
Khi trong mô hình seq2seq sử dụng cơ chế chú ý, bộ giải mã không chỉ lấy các biểu diễn đã được mã hóa (các trạng thái ẩn và các trạng thái nhớ) mà còn chọn các phần chính của đầu vào ở mỗi lần giải mã.
Với các trạng thái ẩn mã hóa là
hehe, he, he,...., he
(với
he he he ). Ở
mỗi bước giải mã t, điểm chú ý của mỗi từ được tính dựa trên các trạng thái ẩn mã
h
h
j
t
hóa e và trạng thái ẩn giải mã d như sau:
ses he, hd (valign )Ttanh Walign hehdbalign
(4.7)
tj j t
với: Walign , valign , balign
j t
là các tham số học.
Sau đó, phân bố chú ý ở bước t này được tính toán dựa trên điểm chú ý của tất
cả các từ trong văn bản đầu vào
se , se , se ,...., se
theo công thức:
e
exp se
exp s
, j 1,J
t1 t 2 t3 tJ
(4.8)
tj
tj J
e tk
k 1
Véc tơ ngữ cảnh của từng từ được tính toán sử dụng phân bố chú ý như sau:
J
t tj j
ce e he
j1
(4.9)
t
Với trạng thái ẩn hiện thời thức:
hd , các trạng thái ẩn chú ý được tính toán theo công
hˆdW cehdb
(4.10)
t c t t c
Cuối cùng, phân bố từ vựng được tính theo công thức:
t
Pvocab,t softmax Wd 2vhˆdbd 2v
trong đó: Wd2v, Wc, bc và 𝑏𝑑2𝑣 là các tham số học.
(4.11)
t yt
t
Với t > 1, trạng thái ẩn
d
h
t 1
được cập nhật theo công thức:
h
d
t 1
LSTM hd, E hˆd
(4.12)
trong đó:
E hˆd
y
t
t
là đầu vào.
4.2.3. Mạng sao chép từ - sinh từ
Mạng sao chép từ - sinh từ (Pointer - Generator) cho phép vừa sao chép các từ trong văn bản nguồn vừa có thể sinh ra từ trong bộ từ vựng. Cơ chế này khắc phục được vấn đề các từ không có trong bộ từ vựng. Cơ chế này không ảnh hưởng đến cách tính phân bố chú ý và véc tơ ngữ cảnh nên phân bố chú ý và véc tơ ngữ cảnh vẫn được tính theo công thức (4.8) và công thức (4.9) tương ứng. Véc tơ ngữ cảnh
t
h
t
ce , trạng thái giải mã ẩn d
và đầu vào giải mã Et sẽ là đầu vào để tính xác suất
𝑝𝑔𝑒𝑛 (generation probability) theo công thức sau:
pgen,t
(W ce W hd W E
b )
(4.13)
trong đó:
s,c t s,h t s,E t s
Ws,c ,Ws,h ,Ws,E ,bs
là các tham số học.
(a) là hàm sigmoid.
pgen,t
là số thực và
pgen,t [0;1] .
pgen,t
được xem như 1 cổng chuyển đổi (switch) có thể sinh 1 từ nằm trong bộ
từ vựng hoặc sao chép từ trong văn bản nguồn nhờ phân bố chú ý (tùy thuộc vào từ đó có trong từ điển hay không).
Gọi
P( yt ) là phân bố cuối cùng để dự đoán một từ, ta có:
P( yt )
pgen,t Pg (yt )1pgen,t Pc (yt )
(4.14)
Phân bố từ vựng
Pg ( yt ) và phân bố chú ý
Pc ( yt ) được định nghĩa như sau:
P ( y ) Pvocab,t ( yt ), yt V
(4.15)
g t 0 , y V
P ( y )
j:x j yt
t
, y
e
tj t
V1
(4.16)
c t
0 , ytV1
với: V là từ điển, V1 là các từ có trong văn bản nguồn.
4.2.4. Cơ chế bao phủ
Cơ chế bao phủ được đề xuất bởi Tu và cộng sự [133] ban đầu được sử dụng cho bài toán dịch máy sử dụng mạng nơ ron (NMT - Neural Machine Translation) để khắc phục nhược điểm của cơ chế chú ý là loại bỏ các thông tin đã có từ trước, tránh lặp lại. Với ưu điểm này, cơ chế bao phủ được áp dụng cho bài toán tóm tắt
u
t
văn bản để giải quyết vấn đề trùng lặp từ. Trong mô hình này, véc tơ bao phủ e
được định nghĩa là tổng phân bố chú ý của các bước giải mã trước đó, được tính theo công thức:
t1
t tj
ue e
j1
(4.17)
Do đó, véc tơ bao phủ chứa thông tin chú ý trên mỗi từ trong văn bản đầu vào trong các bước giải mã trước. Véc tơ bao phủ này được sử dụng để tính toán lại
điểm chú ý theo công thức sau:
se (valign )Ttanh Walign hehduebalign
(4.18)
tj j t t
Lý do của việc thay đổi cách tính này là vấn đề lặp từ có thể xảy ra do bước giải
mã hiện tại phụ thuộc quá nhiều vào bước giải mã ngay trước đó, chính vì thế ta đưa véc tơ bao phủ (được tính bằng tổng phân bố chú ý của các bước giải mã trước) làm đầu vào để giải quyết vấn đề này.
Sau đó, ta sẽ tính toán giá trị mất mát bao phủ theo công thức:
tj tj
j
covlosst
min(e ,ue )
(4.19)
Giá trị mất mát bao phủ sẽ được sử dụng cùng với siêu tham số 𝜆 và hàm mất mát được tính là:
t
losst log P w*
min(e ,ue )
(4.20)
tj tj
j
Tuy nhiên, trong giai đoạn huấn luyện hàm mất mát chỉ được tính theo công thức sau:
t
losst log P w*
(4.21)
Đến giai đoạn kiểm tra, hàm mất mát bao phủ sẽ được tính toán như công thức (4.19). Việc sử dụng hàm mất mát bao phủ trong giai đoạn kiểm tra sẽ giúp giảm thời gian huấn luyện mô hình [43].
4.3. Mô hình tóm tắt đơn văn bản hướng tóm lược PG_Feature_ASDS
Pascanu và cộng sự [134] đã chỉ ra điểm yếu của các mô hình tóm tắt được phát triển dựa trên mạng RNN là vấn đề biến mất gradient, nghĩa là: Khi văn bản đầu vào quá dài, phần đầu của văn bản sẽ bị quên. Mô hình mạng LSTM không hoàn toàn giải quyết được vấn đề này. Do nội dung chính của các bài báo thường nằm ở phần đầu, See và cộng sự [43] khắc phục vấn đề này bằng cách chỉ lấy phần đầu của bài báo để đưa vào mô hình. Tuy nhiên, giải pháp này làm giảm tính linh hoạt của
mô hình tóm tắt vì không phải tất cả các loại văn bản đều có nội dung quan trọng nằm ở phần đầu của văn bản. Để giải quyết vấn đề này, mô hình đề xuất thêm thông tin về vị trí câu (POSI) như đặc trưng cho mô hình để nâng cao trọng số của các câu ở phần đầu văn bản mà không cắt bỏ độ dài văn bản đầu vào.
Ngoài ra, từ đầu ra được sinh ra dựa trên phân bố chú ý của tất cả các từ đầu vào ở phía bộ mã hóa và các từ đầu ra trước đó. Bên cạnh đó, do ta lấy toàn bộ văn bản mà không cắt bỏ phần cuối của văn bản nên khi kích thước văn bản tăng lên thì mức độ chú ý của mỗi từ sẽ giảm, do đó hiệu quả của chú ý sẽ giảm đi. Để khắc phục vấn đề này, mô hình đề xuất sử dụng thêm đặc trưng tần suất xuất hiện của từ (TF) để giúp mô hình tập trung vào các từ quan trọng.
Các đặc trưng đề xuất thêm mới cho mô hình được trình bày chi tiết dưới đây.
4.3.1. Các đặc trưng đề xuất thêm mới cho mô hình
4.3.1.1. Đặc trưng vị trí câu
Với văn bản đầu vào
x x1, x2 , x3,...., xJ
có k câu, ta có thể viết lại véc tơ là
x x11, x21, x31,...., xJk; trong đó:
x jk biểu diễn từ thứ 𝑗 ở câu thứ 𝑘. Từ véc tơ 𝑥
này, ta có thể xác định được 1 véc tơ có độ dài bằng véc tơ x biểu diễn vị trí của câu
chứa từ đó là:
xPOSI
1,1,1,..., k, k .
Do thông tin bị tập trung ở cuối văn bản nên ta sẽ nâng trọng số của các từ trong
phần đầu của văn bản lên. Do đó,
xPOSI được sử dụng để tính lại điểm chú ý theo
công thức (4.22) dưới đây và phân bố chú ý theo công thức (4.8) ở trên.
(valign )Ttanh Walign hehdbalign
s
e
tjx
j t
POSI
(4.22)
4.3.1.2. Đặc trưng tần suất xuất hiện của từ
Tần suất xuất hiện của từ trong văn bản là tham số xác định các từ quan trọng trong văn bản. Trong một văn bản, các từ có tần suất xuất hiện càng cao thì khả năng từ đó là từ quan trọng càng cao. Việc sử dụng thêm đặc trưng TF để nâng cao trọng số của các từ quan trọng. Đặc trưng TF của một từ được tính theo công thức:
TF (xi , x)
trong đó:
f (xi , x)
max{f (xi , x) | j 1 J }
(4.23)
- 𝑓(𝑥𝑖,𝑥) là số lần xuất hiện của 𝑥𝑖 trong văn bản.
- max{𝑓(𝑥𝑗,𝑥)|𝑗=1→𝐽} là số lần xuất hiện nhiều nhất của một từ trong văn bản.
Từ véc tơ 𝑥, có thể xác định được 1 véc tơ có độ dài bằng véc tơ x biểu diễn đặc trưng TF như sau:
xTF (TF(x1, x),TF(x2, x),TF(x3, x),....,TF(xJ , x))
(4.24)
Ta sử dụng véc tơ
xTF
này để tính lại để tính lại điểm chú ý theo công thức
(4.25) dưới đây và phân bố chú ý theo công thức (4.8) ở trên.
s
j t
e
(valign )Ttanh Walign hehdbalign .xTF
tjx
(4.25)
POSI
4.3.2. Mô hình tóm tắt đơn văn bản hướng tóm lược đề xuất
Kiến trúc mô hình đề xuất bao gồm mô hình seq2seq với bộ mã hóa sử dụng mạng biLSTM và bộ giải mã sử dụng mạng LSTM, cơ chế chú ý được sử dụng nhằm giúp mô hình tập trung vào các thông tin chính của văn bản. Mặc dù, mô hình seq2seq có sử dụng cơ chế chú ý nhưng vẫn tồn tại các nhược điểm là lỗi lặp từ, lặp câu và mất mát thông tin. Do đó, mô hình đề xuất sử dụng 2 cơ chế trong [43] đã giải quyết được các vấn đề trên là:
- Cơ chế bao phủ: Khắc phục lỗi lặp từ, lặp câu.
- Cơ chế sao chép từ - sinh từ: Khắc phục lỗi mất mát thông tin.
Tuy nhiên, trong quá trình thử nghiệm tóm tắt cho tiếng Anh (bộ dữ liệu CNN/Daily Mail) và tiếng Việt (bộ dữ liệu Baomoi), mô hình cho kết quả chưa cao như mong muốn, nhiều mẫu thử nghiệm đưa ra kết quả chưa chính xác nên luận án đề xuất thêm mới 2 đặc trưng của văn bản vào mô hình là: Đặc trưng vị trí câu trong văn bản (POSI) và tần suất xuất hiện của từ trong văn bản (TF).
Mô hình đề xuất với các đặc trưng POSI và TF thêm mới được biểu diễn như trong Hình 4.2 dưới đây.
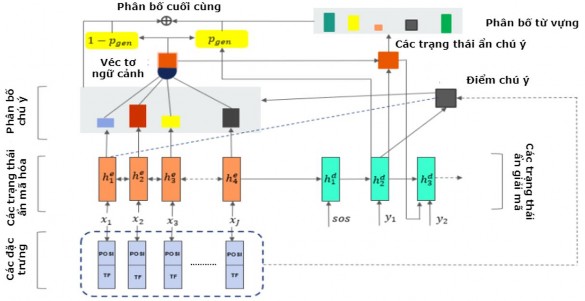
Hình 4.2. Mô hình tóm tắt đơn văn bản hướng tóm lược đề xuất PG_Feature_ASDS
4.4. Thử nghiệm mô hình
4.4.1. Các bộ dữ liệu thử nghiệm
Mô hình đề xuất được thử nghiệm trên hai bộ dữ liệu CNN/Daily Mail cho tiếng Anh và Baomoi cho tiếng Việt. Mục đích của việc thử nghiệm trên bộ dữ liệu
CNN/Daily Mail là để so sánh kết quả của mô hình đề xuất với kết quả của các hệ thống tóm tắt văn bản hướng tóm lược cho tiếng Anh trên cùng bộ dữ liệu gần đây. Việc thử nghiệm trên bộ dữ liệu Baomoi để đánh giá hiệu quả của mô hình đề xuất đối với một ngôn ngữ khác là tiếng Việt và để đảm bảo tính tổng quát của phương pháp tiếp cận tóm tắt hướng tóm lược đã đề xuất.
4.4.2. Tiền xử lý dữ liệu
Trước hết, bộ dữ liệu văn bản đầu vào được xử lý tách từ sử dụng thư viện Stanford CoreNLP đối với văn bản tiếng Anh, thư viện UETSegment14 đối với văn bản tiếng Việt. Với các văn bản của bộ dữ liệu Baomoi, xóa các từ không có ý nghĩa ở nhiều văn bản (ví dụ như: vov.vn, dantri,vn, baodautu.vn,…) vì các từ này không đóng góp vào nội dung của văn bản, loại bỏ những văn bản không có phần tóm tắt hoặc không có phần nội dung, các bài viết quá ngắn (nhỏ hơn 50 ký tự) cũng bị loại
bỏ. Sau đó, mỗi đơn vị dữ liệu (bao gồm 1 phần tóm tắt và 1 phần nội dung) được định dạng theo kiểu dữ liệu quy định trong Tensorflow (đối với cả hai bộ dữ liệu). Kiểu dữ liệu này được định dạng cho cả 3 tập dữ liệu: Tập dữ liệu huấn luyện (train), tập dữ liệu kiểm tra (validate) và tập dữ liệu đánh giá (test). Đồng thời, dựa vào dữ liệu huấn luyện tạo một bộ từ vựng (vocab) với kích thước là 50.000 từ.
4.4.3. Thiết kế thử nghiệm
Luận án triển khai thử nghiệm bốn mô hình khác nhau trên các bộ dữ liệu CNN/Daily Mail và Baomoi như sau:
(i) Mô hình 1: Mô hình seq2seq cơ bản với cơ chế attention [128].
(ii) Mô hình 2: Mạng Pointer - Generator với cơ chế Coverage [43].
(iii) Mô hình 3: Hệ thống đề xuất dựa trên [43] và thêm đặc trưng vị trí câu.
(iv) Mô hình 4: Hệ thống đề xuất dựa trên [43] và bổ sung thêm các đặc trưng vị trí câu và tần suất xuất hiện của từ.
Hai mô hình 1 và 2 được thử nghiệm bởi mã nguồn trong [43] trên hai bộ dữ liệu CNN/Daily Mail và Baomoi. Hai mô hình 3 và 4 do luận án thực hiện cài đặt để lựa chọn mô hình tóm tắt đề xuất.
Đầu vào của mô hình là một chuỗi các từ của bài báo, mỗi từ được biểu diễn dưới dạng một véc tơ. Kích thước bộ từ vựng trong các thử nghiệm là 50.000 từ cho tiếng Anh và tiếng Việt. Đối với các thử nghiệm, mô hình có trạng thái ẩn 256 chiều và véc tơ mã hóa từ 128 chiều, kích thước lô dữ liệu (batch size) được giới hạn là 16 và độ dài văn bản đầu vào là 800 từ đối với tiếng Anh và 550 từ đối với tiếng Việt (do các văn bản tiếng Anh có độ dài nhỏ hơn 800 từ và các văn bản tiếng Việt có độ dài nhỏ hơn 550 từ nên độ dài văn bản được giới hạn như vậy là hợp lý). Mô hình sử dụng bộ tối ưu hóa Adagrad [135] với hệ số học là 0,15 và giá trị tích lũy ban đầu là 0,1. Khi tinh chỉnh mô hình, giá trị hàm mất mát (loss) được sử dụng để dừng mô hình sớm. Trong giai đoạn đánh giá, độ dài bản tóm tắt được giới hạn tối đa là 100 từ cho cả hai bộ dữ liệu.
Ngoài ra, hệ thống cũng triển khai thử nghiệm mô hình của See và cộng sự [43] trên bộ dữ liệu CNN/Daily Mail để đánh giá hiệu quả của việc sử dụng 400 từ đầu tiên của văn bản làm đầu vào cho hệ thống.
14 https://github.com/phongnt570/UETsegmenter
4.5. Đánh giá và so sánh kết quả
Bảng 4.1 dưới đây biểu diễn các kết quả thử nghiệm trên bộ dữ liệu CNN/Daily Mail. Các độ đo R-1, R-2 và R-L được sử dụng để đánh giá và so sánh hiệu quả của các mô hình.
CNN/Daily Mail | |||
R-1 | R-2 | R-L | |
Mô hình 1 (Seq2seq + attention) [128] | 27,21 | 10,09 | 24,48 |
Mô hình 2 (Pointer-Generator + Coverage) [43] (*) | 29,71 | 12,13 | 28,05 |
Mô hình 3 ((*) + POSI) | 31,16 | 12,66 | 28,61 |
Mô hình 4 ((*) + POSI + TF) | 31,89 | 13,01 | 29,97 |
Có thể bạn quan tâm!
-
 Kết Quả Thử Nghiệm Một Số Phương Pháp Tóm Tắt Văn Bản Cơ Sở. Ký Hiệu ‘*’ Thể Hiện Phương Pháp Được Triển Khai Thử Nghiệm Trên Các Bộ
Kết Quả Thử Nghiệm Một Số Phương Pháp Tóm Tắt Văn Bản Cơ Sở. Ký Hiệu ‘*’ Thể Hiện Phương Pháp Được Triển Khai Thử Nghiệm Trên Các Bộ -
 Các Kết Quả Thử Nghiệm Của Các Mô Hình Xây Dựng
Các Kết Quả Thử Nghiệm Của Các Mô Hình Xây Dựng -
 Giá Trị Các Siêu Tham Số Và Thời Gian Huấn Luyện Các Mô Hình Xây Dựng
Giá Trị Các Siêu Tham Số Và Thời Gian Huấn Luyện Các Mô Hình Xây Dựng -
 Mẫu Tóm Tắt Gồm Bản Tóm Tắt Tham Chiếu, Bản Tóm Tắt Của Mô Hình Trong
Mẫu Tóm Tắt Gồm Bản Tóm Tắt Tham Chiếu, Bản Tóm Tắt Của Mô Hình Trong -
 Mô Hình Sử Dụng Thuật Toán Phân Cụm K-Means Kết Hợp Vị Trí Tương Đối Của Câu
Mô Hình Sử Dụng Thuật Toán Phân Cụm K-Means Kết Hợp Vị Trí Tương Đối Của Câu -
 Các Mẫu Tóm Tắt Của Cụm D0716D Trong Bộ Dữ Liệu Duc 2007 Của Mô Hình Đề Xuất Và Con Người
Các Mẫu Tóm Tắt Của Cụm D0716D Trong Bộ Dữ Liệu Duc 2007 Của Mô Hình Đề Xuất Và Con Người
Xem toàn bộ 185 trang tài liệu này.
Bảng 4.1. Kết quả thử nghiệm của các mô hình trên bộ dữ liệu CNN/Daily Mail. Ký hiệu ‘(*)’ là mô hình của See và cộng sự [43]
Khi lặp lại thử nghiệm trong [43] sử dụng 400 từ đầu tiên của bài báo làm đầu vào thì nhận được điểm R-1 là 35,87%. Tuy nhiên, khi sử dụng toàn bộ bài báo làm đầu vào thì độ đo R-1 giảm xuống còn 29,71%. Điều này là do khi cung cấp một văn bản dài cho mô hình, phần đầu của văn bản bị hệ thống "quên" mà nội dung chính của bài báo thường nằm ở phần đầu. Tuy nhiên, các bài báo được tóm tắt theo cách này sẽ làm giảm tính tổng quát của hệ thống cũng như trong các trường hợp thông tin quan trọng có thể không nằm ở 400 từ đầu tiên của văn bản.
Bảng 4.1 cho thấy khi sử dụng toàn bộ văn bản của bài báo làm đầu vào, cả hai mô hình đề xuất (mô hình 3 và mô hình 4) đều cho kết quả tốt hơn các hệ thống trong [128] và [43] trong cả ba độ đo R-1, R-2 và R-L. Kết quả thử nghiệm cho thấy rằng đặc trưng vị trí câu là thông tin quan trọng trong việc sinh ra một bản tóm tắt chất lượng và tần suất xuất hiện của từ là một chỉ báo tốt cho các nhiệm vụ tóm tắt văn bản sử dụng các kỹ thuật học sâu. Khi thông tin về vị trí câu và tần suất xuất hiện của từ được thêm vào mô hình, độ đo R-1 được cải thiện đáng kể, cao hơn 2,18% so với độ đo R-1 của hệ thống trong [43].
Bảng 4.2 dưới đây biểu diễn các kết quả thử nghiệm trên bộ dữ liệu Baomoi.
Baomoi | |||
R-1 | R-2 | R-L | |
Mô hình 1 (Seq2seq + attn baseline) [128] | 26,68 | 9.34 | 16,49 |
Mô hình 2 (Pointer-Generator + Coverage) [43] (*) | 28,34 | 11,06 | 18,55 |
Mô hình 3 ((*) + POSI) | 29,47 | 11,31 | 18,85 |
Mô hình 4 ((*) + POSI + TF) | 30,59 | 11,53 | 19,45 |
Bảng 4.2. Kết quả thử nghiệm của các mô hình trên bộ dữ liệu Baomoi. Ký hiệu ‘(*)’ là mô hình của See và cộng sự [43]
Kết quả trong Bảng 4.2 cũng chỉ ra rằng cả hai mô hình đề xuất đều đạt các điểm R-1, R-2, R-L cao hơn so với hai hệ thống còn lại. Mô hình đề xuất tốt nhất thu được độ đo R-1 cao hơn 2,25% so với độ đo R-1 của mô hình trong [43] và cao hơn 3,91% so với độ đo R-1 của mô hình cơ bản trong [128].