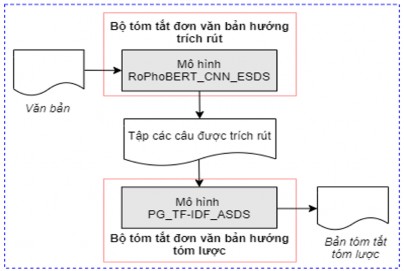
Hình 5.11. Mô hình tóm tắt đơn văn bản hỗn hợp Ext_Abs_ASDS
5.3.3.3. Xây dựng mô hình tóm tắt đa văn bản hướng tóm lược đề xuất
Dựa trên mô hình tóm tắt đơn văn bản pre-trained Ext_Abs_ASDS đề xuất, luận án triển khai phát triển các mô hình để lựa chọn mô hình tóm tắt đa văn bản hướng tóm lược đề xuất. Các mô hình được trình bày chi tiết dưới đây.
(i) Mô hình 1 (Ext_Abs_AMDS): Mô hình tóm tắt đa văn bản được phát triển dựa trên mô hình pre-trained Ext_Abs_ASDS đề xuất (với phương pháp MMR áp dụng trên tập xác suất được chọn của các câu của từng văn bản).
Trong mô hình này, phương pháp MMR được áp dụng trên tập xác suất được chọn của các câu của từng văn bản trên đầu ra của mô hình RoPhoBERT_CNN_ESDS để lựa chọn các câu đưa vào bản tóm tắt của văn bản tương ứng. Các bản tóm tắt này sau đó được kết hợp thành một “siêu văn bản” làm đầu vào cho mô hình PG_TF-IDF_ASDS để sinh bản tóm tắt tóm lược đa văn bản. Mô hình 1 được biểu diễn chi tiết như trong Hình 5.12 dưới đây.
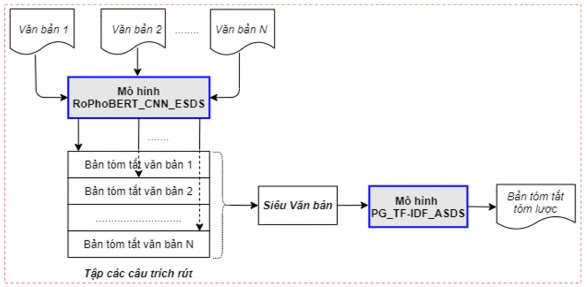
Hình 5.12. Mô hình tóm tắt đa văn bản hướng tóm lược dựa trên mô hình pre- trained Ext_Abs_ASDS đề xuất (MMR áp dụng trên từng văn bản)
(ii) Mô hình 2 (Ext_Abs_AMDS-mmr): Mô hình tóm tắt đa văn bản được phát triển dựa trên mô hình pre-trained Ext_Abs_ASDS với phương pháp MMR áp dụng trên tập xác suất được chọn của các câu của tập đa văn bản.
Trong mô hình 1, nhận thấy rằng siêu văn bản nhận được (ghép các bản tóm tắt của các văn bản từ đầu ra của mô hình RoPhoBERT_CNN_ESDS) có thể chứa các thông tin dư thừa mặc dù đã áp dụng MMR để loại bỏ thông tin trùng lặp trong mỗi bản tóm tắt. Do đó, mô hình 2 sẽ đề xuất áp dụng phương pháp MMR trên tập xác suất được chọn của các câu của tập đa văn bản từ đầu ra của mô hình pre-trained Ext_Abs_ASDS (thay vì áp dụng phương pháp MMR trên tập xác suất của từng văn bản) để chọn câu đưa vào bản tóm tắt (siêu văn bản) được sử dụng làm đầu vào cho mô hình pre-trained PG_TF-IDF_ASDS để sinh bản tóm tắt tóm lược đa văn bản. Mô hình 2 được biểu diễn chi tiết như trong Hình 5.13 dưới đây.
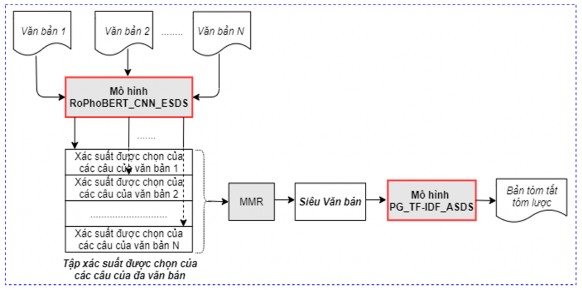
Hình 5.13. Mô hình tóm tắt đa văn bản hướng tóm lược dựa trên mô hình pre- trained Ext_Abs_ASDS với phương pháp MMR áp dụng trên tập đa văn bản
(iii) Mô hình 3 (Ext_Abs_AMDS-mds): Mô hình tóm tắt đa văn bản Ext_Abs_AMDS (mô hình 1) được tinh chỉnh bằng việc huấn luyện tiếp mô hình pre-trained Ext_Abs_ASDS trên các bộ dữ liệu tóm tắt đa văn bản tương ứng.
Nhận thấy rằng bản tóm tắt của các bộ dữ liệu tóm tắt đơn văn bản thường ngắn hơn so với bản tóm tắt của các bộ dữ liệu tóm tắt đa văn bản nên khi áp dụng các mô hình tóm tắt đơn văn bản cho tóm tắt đa văn bản thì kết quả mang lại chưa cao. Do đó, mô hình pre-trained Ext_Abs_ASDS được huấn luyện tiếp trên các bộ dữ liệu tóm tắt đa văn bản tương ứng để được các bản tóm tắt đa văn bản dài hơn nhằm cải thiện hiệu quả tóm tắt cho mô hình tóm tắt đa văn bản đề xuất.
(iv) Mô hình 4 (Ext_Abs_AMDS-mds-mmr): Mô hình tóm tắt đa văn bản Ext_Abs_AMDS-mmr (mô hình 2) được tinh chỉnh bằng việc huấn luyện tiếp mô hình pre-trained Ext_Abs_ASDS trên các bộ dữ liệu tóm tắt đa văn bản tương ứng.
Các mô hình này đều được triển khai thử nghiệm (các kết quả thử nghiệm được trình bày chi tiết trong phần 5.4.5). Các kết quả thử nghiệm cho thấy mô hình 4 (mô hình Ext_Abs_AMDS-mds-mmr) cho kết quả tốt nhất trong các mô hình đã xây dựng và mô hình này được chọn làm mô hình tóm tắt đa văn bản hướng tóm lược đề xuất.
5.3.3.4. Mô hình huấn luyện đề xuất
Các giai đoạn huấn luyện và đánh giá cho mô hình tóm tắt đa văn bản hướng tóm lược đề xuất được trình bày chi tiết trong Hình 5.14 dưới đây.
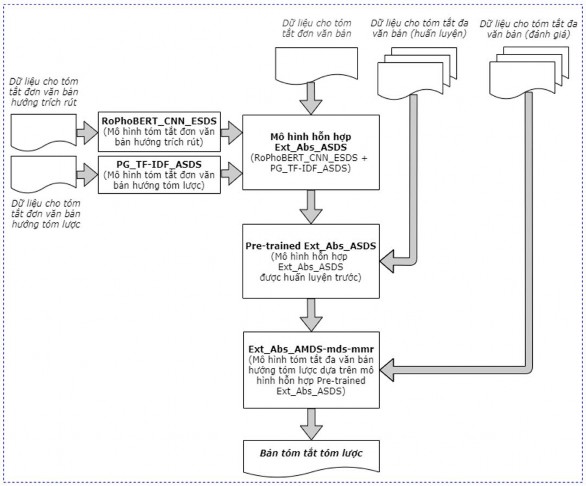
Hình 5.14. Các giai đoạn huấn luyện mô hình tóm tắt đa văn bản hướng tóm lược đề xuất Ext_Abs_AMDS-mds-mmr
(i) Giai đoạn 1:Huấn luyện các mô hình tóm tắt đơn văn bản hướng trích rút RoPhoBERT_CNN_ESDS và hướng tóm lược PG_TF-IDF_ASDS ban đầu.
Hai mô hình tóm tắt đơn văn bản này được huấn luyện trên bộ dữ liệu CNN/Daily Mail (tiếng Anh) và bộ dữ liệu Baomoi (tiếng Việt) để thu được các mô hình tóm tắt đơn văn bản được huấn luyện trước tương ứng (hai mô hình này có thể được huấn luyện song song để giảm thời gian huấn luyện). Đây là 2 thành phần chính của mô hình hỗn hợp đề xuất Ext_Abs_ASDS.
(ii) Giai đoạn 2:Huấn luyện mô hình hỗn hợp Ext_Abs_ASDS.
Mô hình PG_TF-IDF_ASDS của mô hình Ext_Abs_ASDS được huấn luyện tiếp trên tập các câu trích rút (bản tóm tắt trích rút) đầu ra của mô hình RoPhoBERT_CNN_ESDS trên các bộ dữ liệu tóm tắt đơn văn bản để được mô hình hỗn hợp pre-trained Ext_Abs_ASDS sử dụng cho mô hình tóm tắt đa văn bản hướng tóm lược đề xuất.
(iii) Giai đoạn 3:Huấn luyện tiếp mô hình hỗn hợp pre-trained Ext_Abs_ASDS trên các bộ dữ liệu tóm tắt đa văn bản tương ứng.
Bản tóm tắt được sinh ra bởi mô hình hỗn hợp pre-trained Ext_Abs_ASDS thường có độ dài ngắn vì số lượng câu của bản tóm tắt của các bộ dữ liệu CNN/Daily Mail và Baomoi nhỏ, trong khi các bộ dữ liệu sử dụng để đánh giá cho mô hình tóm tắt đa văn bản có bản tóm tắt dài hơn. Do đó, mô hình hỗn hợp pre- trained Ext_Abs_ASDS được đề xuất huấn luyện tiếp trên bộ dữ liệu DUC 2007 (tiếng Anh), bộ dữ liệu ViMs (tiếng Việt) để sinh ra bản tóm tắt dài hơn nhằm nâng cao độ chính xác của bản tóm tắt sinh ra.
(iv) Giai đoạn 4:Đánh giá mô hình tóm tắt đa văn bản hướng tóm lược.
Tập các văn bản của bộ dữ liệu DUC 2004 (tiếng Anh) và Corpus_TMV (tiếng Việt) được sử dụng làm đầu vào cho mô hình tóm tắt đa văn bản hướng tóm lược đề xuất Ext_Abs_AMDS-mds-mmr để sinh bản tóm tắt cho mô hình tóm tắt đa văn bản hướng tóm lược.
5.3.3.5. Thử nghiệm mô hình
a) Dữ liệu thử nghiệm
Mô hình đề xuất được thử nghiệm trên các bộ dữ liệu như sau:
Đối với tóm tắt văn bản tiếng Anh
- Bộ dữ liệu CNN/Daily Mail: Để huấn luyện các mô hình tóm tắt đơn văn bản RoPhoBERT_CNN_ESDS, PG_TF-IDF_ASDS và Ext_Abs_ASDS.
- Bộ dữ liệu DUC 2007: Để huấn luyện tiếp mô hình hỗn hợp pre-trained Ext_Abs_ASDS.
- Bộ dữ liệu DUC 2004: Để đánh giá các mô hình tóm tắt đa văn bản tóm lược.
Đối với tóm tắt văn bản tiếng Việt
- Bộ dữ liệu Baomoi: Để huấn luyện các mô hình tóm tắt đơn văn bản RoPhoBERT_CNN_ESDS, PG_TF-IDF_ASDS và Ext_Abs_ASDS.
- Bộ dữ liệu ViMs: Để huấn luyện tiếp mô hình hỗn hợp pre-trained Ext_Abs_ASDS.
- Bộ dữ liệu Corpus_TMV: Để đánh giá các mô hình tóm tắt đa văn bản tóm lược.
b) Tiền xử lý dữ liệu
Các bộ dữ liệu văn bản đầu vào tiếng Anh, tiếng Việt được tiền xử lý sử dụng các thư viện Stanford CoreNLP, VNCoreNLP tương ứng. Mỗi văn bản của các bộ dữ liệu CNN/Daily Mail và Baomoi được xử lý tách riêng các phần tiêu đề, tóm tắt, nội dung. Đối với các bộ dữ liệu cho tóm tắt đa văn bản: các bản tóm tắt tham chiếu của mỗi cụm dữ liệu (DUC 2004, DUC 2007 có 04 bản tóm tắt tham chiếu; ViMs, Corpus_TMV có 02 bản tóm tắt tham chiếu) được trích xuất từ các tệp tương ứng để sử dụng cho giai đoạn đánh giá. Phần nội dung của mỗi văn bản được xử lý tách câu và đánh số thứ tự sử dụng làm đầu vào cho mô hình tóm tắt.
c) Huấn luyện mô hình
Các mô hình thử nghiệm sử dụng mô hình RoBERTa/PhoBERT (với 12 lớp, 768 chiều, 12 đầu chú ý (head attention), 110 triệu tham số) để mã hóa văn bản đầu vào cho mô hình tóm tắt hướng trích rút. Bộ mã hóa và bộ giải mã của mô hình tóm tắt hướng tóm lược được xây dựng từ các khối LSTM có trạng thái ẩn là 1024 (bộ mã hóa sử dụng biLSTM có 512 trạng thái ẩn cho chiều tiến và 512 trạng thái ẩn cho
chiều lùi; bộ giải mã sử dụng LSTM có 1024 trạng thái ẩn) và véc tơ từ có 300 chiều.
Chi tiết xử lý các bộ dữ liệu cho quá trình huấn luyện như sau:
- Bộ dữ liệu CNN/Daily Mail: Độ dài văn bản được xử lý lấy tối đa 64 câu, độ dài câu tối đa 32 từ (đệm '0' nếu cần) làm đầu vào cho mô hình RoPhoBERT_CNN_ESDS, đầu ra là văn bản có độ dài là max(0,4*Số câu của văn bản, 7 câu). Đối với mô hình PG_TF-IDF_ASDS, độ dài văn bản được xử lý lấy tối đa 400 từ, độ dài bản tóm tắt tham chiếu để đánh giá là 120 từ.
- Bộ dữ liệu Baomoi: Độ dài văn bản được xử lý lấy tối đa 48 câu, độ dài câu tối đa 16 từ (đệm '0' nếu cần) làm đầu vào cho mô hình RoPhoBERT_CNN_ESDS, đầu ra là văn bản có độ dài là max(0,5*Số câu của văn bản, 4 câu). Đối với mô hình PG_TF-IDF_ASDS, độ dài văn bản được xử lý lấy tối đa 400 từ, độ dài bản tóm tắt tham chiếu là 50 từ.
- Bộ dữ liệu DUC 2007: Mỗi văn bản được xử lý lấy tối đa 64 câu, độ dài câu tối đa 32 từ làm đầu vào cho mô hình RoPhoBERT_CNN_ESDS, đầu ra của mỗi văn bản có độ dài là max(0,4*Số câu của văn bản, 7 câu) do mỗi văn bản của bộ DUC 2007 có xấp xỉ 14 câu. Siêu văn bản (ghép của các bản tóm tắt đầu ra của mô hình RoPhoBERT_CNN_ESDS) được xử lý lấy độ dài 1.000 từ, độ dài bản tóm tắt tham chiếu sử dụng để đánh giá là 200 từ làm đầu vào cho mô hình PG_TF- IDF_ASDS.
- Bộ dữ liệu ViMs: Mỗi văn bản được xử lý lấy tối đa 48 câu, độ dài câu tối đa 16 từ làm đầu vào cho mô hình, đầu ra của mỗi văn bản có độ dài bằng max(0,5*Số câu của văn bản, 4 câu) do mỗi văn bản của bộ ViMs có xấp xỉ 8 câu. Siêu văn bản (ghép của các bản tóm tắt đầu ra của mô hình RoPhoBERT_CNN_ESDS) được xử lý lấy độ dài 1.000 từ, độ dài bản tóm tắt tham chiếu sử dụng để đánh giá là 250 từ làm đầu vào cho mô hình PG_TF-IDF_ASDS.
Mô hình được huấn luyện sử dụng Google Colab với cấu hình máy chủ GPU P100, 25GB RAM được cung cấp bởi Google. Mô hình được huấn luyện bởi thuật toán tối ưu AdamW [122]. Các tham số sử dụng trong quá trình huấn luyện các mô hình gồm: Số bước tích lũy gradient (accumulate gradient step) bằng 2, hệ số học bằng 2.10-3, warmup (quá trình huấn luyện ban đầu) là 1.000 bước. Bộ từ vựng có kích thước 50.000 từ. Các siêu tham số được cài đặt và thời gian huấn luyện (giờ) các mô hình được trình bày chi tiết như trong Bảng 5.13 dưới đây.
Epochs | Batch size | Bộ dữ liệu huấn luyện | Thời gian huấn luyện | |
RoPhoBERT_CNN_ESDS | 8 | 18 | CNN/Daily Mail | 52 |
PG_TF-IDF_ASDS | 8 | 18 | CNN/Daily Mail | 30 |
Ext_Abs_ASDS | 4 | 4 | CNN/Daily Mail | 17 |
Ext_Abs_ASDS | 4 | 2 | DUC 2007 | ~1 |
RoPhoBERT_CNN_ESDS | 8 | 18 | Baomoi | 48 |
PG_TF-IDF_ASDS | 8 | 16 | Baomoi | 38 |
Ext_Abs_ASDS | 4 | 4 | Baomoi | 22 |
Ext_Abs_ASDS | 4 | 2 | ViMs | ~1 |
Có thể bạn quan tâm!
-
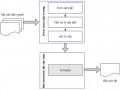
 Mô Hình Sử Dụng Thuật Toán Phân Cụm K-Means Kết Hợp Vị Trí Tương Đối Của Câu
Mô Hình Sử Dụng Thuật Toán Phân Cụm K-Means Kết Hợp Vị Trí Tương Đối Của Câu -
 Các Mẫu Tóm Tắt Của Cụm D0716D Trong Bộ Dữ Liệu Duc 2007 Của Mô Hình Đề Xuất Và Con Người
Các Mẫu Tóm Tắt Của Cụm D0716D Trong Bộ Dữ Liệu Duc 2007 Của Mô Hình Đề Xuất Và Con Người -
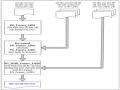 Các Giai Đoạn Huấn Luyện Mô Hình Tóm Tắt Đa Văn Bản Hướng Tóm Lược Đề Xuất Pg_Feature_Amds
Các Giai Đoạn Huấn Luyện Mô Hình Tóm Tắt Đa Văn Bản Hướng Tóm Lược Đề Xuất Pg_Feature_Amds -
 Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 19
Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 19 -
 Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 20
Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 20 -
 Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 21
Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 21
Xem toàn bộ 185 trang tài liệu này.
Bảng 5.13. Giá trị các siêu tham số và thời gian huấn luyện các mô hình
Độ dài bản tóm tắt tóm lược sinh ra của mô hình được lấy số từ trong khoảng từ 100 đến 200 từ với bộ dữ liệu DUC 2004 (do độ dài bản tóm tắt tham chiếu lấy 200 từ), độ dài trong khoảng từ 125 đến 250 từ với bộ dữ liệu Corpus_TMV (do độ dài bản tóm tắt tham chiếu lấy 250 từ). Thuật toán tìm kiếm Beam được sử dụng với kích thước tìm kiếm bằng 5 (beam_size = 5).
d) Thiết kế thử nghiệm
Trước hết, luận án triển khai thử nghiệm các mô hình tóm tắt đơn văn bản RoPhoBERT_CNN_ESDS, PG_TF-IDF_ASDS và Ext_Abs_ASDS sử dụng cho mô hình tóm tắt đa văn bản hướng tóm lược đề xuất. Bảng 5.14 dưới đây là kết quả thử nghiệm thu được trên các bộ dữ liệu CNN/Daily Mail và Baomoi.
CNN/Daily Mail | Baomoi | |||||
R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
RoPhoBERT_CNN_ESDS | 41,27 | 19,68 | 38,01 | 54,82 | 25,81 | 37,62 |
PG_TF-IDF_ASDS | 37,01 | 16,45 | 33,13 | 51,39 | 24,41 | 36,63 |
Ext_Abs_ASDS | 39,64 | 18,53 | 37,11 | 54,65 | 25,59 | 37,18 |
Bảng 5.14. Kết quả thử nghiệm của các mô hình tóm tắt đơn văn bản trên các bộ dữ liệu CNN/Daily Mail và Baomoi
Tiếp theo, luận án triển khai thử nghiệm các mô hình xây dựng ở trên. Bảng 5.15 dưới đây là kết quả thử nghiệm của các mô hình thu được trên hai bộ dữ liệu DUC 2004 và Corpus_TMV tương ứng.
DUC 2004 | Corpus_TMV | |||||
R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
Mô hình 1 (Ext_Abs_AMDS) | 38,22 | 11,19 | 19,63 | 60,10 | 37,61 | 36,24 |
Mô hình 2 (Ext_Abs_AMDS- mmr) | 38,34 | 11,36 | 19,95 | 60,21 | 37,74 | 36,22 |
Mô hình 3 (Ext_Abs_AMDS- mds) | 40,47 | 13,62 | 21,04 | 67,53 | 40,11 | 43,82 |
Mô hình 4 (Ext_Abs_AMDS- mds-mmr) | 40,88 | 13,91 | 21,05 | 67,99 | 40,83 | 44,05 |
Bảng 5.15. Kết quả thử nghiệm các mô hình xây dựng trên bộ dữ liệu DUC 2004 và Corpus_TMV
Các kết quả thử nghiệm trình bày trong Bảng 5.15 cho thấy mô hình 4 với việc huấn luyện tiếp mô hình pre-trained Ext_Abs_ASDS trên các bộ dữ liệu tóm tắt đa văn bản và phương pháp MMR áp dụng trên tập xác suất được chọn của các câu của tập đa văn bản để chọn câu đưa vào bản tóm tắt đã cho các kết quả tốt hơn so với các mô hình còn lại trên cả hai bộ dữ liệu DUC 2004 và Corpus_TMV. Mô hình 4 được lựa chọn là mô hình tóm tắt đa văn bản hướng tóm lược đề xuất Ext_Abs_ASDS-mds-mmr.
Bảng 5.16 trình bày một mẫu tóm tắt gồm một bản tóm tắt tham chiếu của con người và bản tóm tắt đầu ra của mô hình đề xuất Ext_Abs_AMDS-mds-mmr trên bộ dữ liệu DUC 2004 (tiếng Anh). Văn bản nguồn của mẫu tóm tắt này xem Phụ lục
C.7trong phần Phụ lục.
Bản tóm tắt của mô hình Ext_Abs_AMDS-mds-mmr Hun Sen 's on Friday rejected opposition parties demands for talks outside the country . Government and opposition parties have asked King Norodom Sihanouk to host a summit meeting after a series of post-election negotiations between the two opposition groups and Hun Sen 's party to form a new government failed . Hun Sen 's ruling party won 64 of the 122 seats in parliament in July 's national election , but not the two -thirds necessary to form a government on its own . Negotiations to form the next government have become deadlocked , and opposition party leaders are out of the country. |
Các bản tóm tắt tham chiếu
Bảng 5.16. Một mẫu thử nghiệm trên bộ dữ liệu DUC 2004
Bảng 5.17 trình bày một mẫu tóm tắt gồm một bản tóm tắt tham chiếu của con người và bản tóm tắt đầu ra của mô hình đề xuất Ext_Abs_AMDS-mds-mmr trên bộ dữ liệu Corpus_TMV (tiếng Việt). Văn bản nguồn của các mẫu tóm tắt này xem Phụ lục C.7trong phần Phụ lục.
Một bản tóm tắt tham chiếu
Ngày 21/10 , trong không khí thắm tình hữu nghị , Liên hoan hữu nghị nhân dân Việt Nam-Ấn Độ lần thứ 6 đã khai mạc tại Thủ đô Hà Nội . Liên hoan hữu nghị nhân dân Việt Nam-Ấn Độ lần thứ VI diễn ra trong bối cảnh hai nước Việt Nam và Ấn Độ vừa kết thúc thắng lợi " Năm hữu nghị Việt Nam-Ấn Độ 2012 " , đồng thời đang tích cực chuẩn bị cho chuyến thăm hữu nghị chính thức Ấn Độ trong thời gian tới của Tổng Bí thư Ban chấp hành Trung ương Đảng Cộng sản Việt Nam Nguyễn Phú Trọng . Đến dự có ông Vũ Xuân Hồng , Chủ tịch Liên hiệp ; bà Shrimati Preeti Saran , Đại sứ Ấn Độ tại Việt Nam ; ông Devi Prasad Tripathi , Trưởng đoàn đại biểu nhân dân Ấn Độ cùng đại diện các bộ ngành ở trung ương , Hà Nội . Trong khuôn khổ Liên hoan lần này , đại biểu nhân dân hai nước sẽ cùng nhau ôn lại truyền thống đoàn kết , đồng tình , ủng hộ và giúp đỡ lẫn nhau ; thảo luận , đề xuất các biện pháp tăng cường mối quan hệ giữa nhân dân hai nước nói chung và các tổ chức nhân dân hai nước nói riêng , góp phần hiện thực hoá các thoả thuận đạt được giữa lãnh đạo cấp cao
Bản tóm tắt của mô hình Ext_Abs_AMDS-mds-mmr Từ năm 2007 đến nay , Đoàn tham dự toạ đàm về giao lưu văn hoá Việt Nam-Ấn Độ , thăm quan tìm hiểu về văn hoá Chăm . Tại TPHCM , Đoàn sẽ đi thăm địa đạo Củ Chi , di tích lịch sử đã để lại nhiều ấn tượng đối với chuyến thăm hữu nghị chính thức Ấn Độ trong thời gian tới của Tổng Bí thư Ban chấp hành Trung ương Đảng Cộng sản Việt Nam Nguyễn Phú Trọng . Các đại biểu sẽ tham dự các hoạt động phong phú và ý nghĩa tại Hà Nội , Đà Nẵng và TPHCM . Đây là sự kiện được tổ chức tại TP HCM , tối nay , trong màu áo thăm quan , cùng với nhiều chủng loại , đặc biệt là sự lựa chọn của những dấu mốc quan trọng giúp Việt Nam và Ấn Độ , hai nước Việt Nam và TPHCM . Liên hoan diễn ra trong 7 ngày , từ 20 đến 26/10 . Liên hoan lần thứ VI diễn ra trong bối cảnh hai nước Chăm và dâng hương tại Tượng đài Indira Gandi , thăm tìm hiểu bạn bè quốc tế . Đến dự có ông Hà Minh Huệ , Phó chủ tịch Hội hữu nghị Việt Nam - Ấn Độ. |
hai nước . Được biết , diễn ra trong 7 ngày ( từ 20 đến 26-
Bảng 5.17. Một mẫu thử nghiệm trên bộ dữ liệu Corpus_TMV
Từ các kết quả thử nghiệm, có thể thấy mô hình tóm tắt đa văn bản hướng tóm lược đề xuất Ext_Abs_AMDS-mds-mmr đã đạt được kết quả tốt cho tóm tắt đa văn bản tiếng Anh và tiếng Việt.
5.3.3.6. So sánh và đánh giá kết quả
Kết quả thử nghiệm của mô hình đề xuất được đánh giá và so sánh với kết quả của các phương pháp tóm tắt đa văn bản hướng tóm lược hiện đại khác đã công bố trên cùng bộ dữ liệu tương ứng. Bảng 5.18 là kết quả đánh giá và so sánh hiệu quả của các phương pháp.
DUC 2004 | Corpus_TMV | |||||
R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
Extract+Rewrite [147] | 28,90 | 5,33 | - | |||
Opinosis [147] | 27,07 | 5,03 | - | |||
PG-Original [147] | 31,43 | 6,03 | - | |||
PG-MMR w/ SummRec [147] | 34,57 | 7,46 | - | - | - | - |
PG-MMR w/ SentAttn [147] | 36,52 | 8,52 | - | |||
G-MMR w/ Cosine [147] | 36,88 | 8,73 | - | - | - | - |
PG-MMR w/ BestSum [147] | 36,42 | 9,36 | - | - | - | - |
Ext_Abs_AMDS-mds | 40,47 | 13,62 | 21,04 | 67,53 | 40,11 | 43,82 |
Ext_Abs_AMDS-mds-mmr | 40,88 | 13,91 | 21,05 | 67,99 | 40,83 | 44,05 |
Bảng 5.18. So sáng và đánh giá kết quả của các phương pháp. Ký hiệu ‘-’ biểu diễn các phương pháp không được thử nghiệm trên các bộ dữ liệu tương ứng
Kết quả trong Bảng 5.18 cũng chỉ ra rằng mô hình đề xuất Ext_Abs_AMDS- mds-mmr có kết quả tốt hơn đáng kể so với các hệ thống tóm tắt đa văn bản hướng