Do số lượng câu của bản tóm tắt tham chiếu của các bộ dữ liệu CNN/Daily Mail và Baomoi nhỏ nên mô hình pre-trained PG_Feature_ASDS thường sinh ra bản tóm tắt có số lượng câu nhỏ nên độ dài của bản tóm tắt ngắn, trong khi các bộ dữ liệu sử dụng để đánh giá cho mô hình tóm tắt đa văn bản (bộ dữ liệu DUC 2004 đối với tiếng Anh, Corpus_TMV đối với tiếng Việt) có bản tóm tắt tham chiếu dài hơn. Nhận thấy bộ dữ liệu DUC 2007 và DUC 2004 có các đặc điểm giống nhau nên mô hình pre-trained PG_Feature_ASDS được đề xuất huấn luyện tiếp trên bộ dữ liệu DUC 2007 (tiếng Anh); bộ dữ liệu ViMs và Corpus_TMV có đặc điểm giống nhau nên mô hình pre-trained PG_Feature_ASDS được đề xuất huấn luyện tiếp trên bộ dữ liệu ViMs (tiếng Việt) để sinh ra bản tóm tắt dài hơn và cải thiện chất lượng bản tóm tắt sinh ra.
(3) Giai đoạn 3: Đánh giá mô hình tóm tắt đa văn bản hướng tóm lược.
Các văn bản của bộ dữ liệu DUC 2004 (tiếng Anh), Corpus_TMV (tiếng Việt) được sử dụng làm đầu vào cho mô hình tóm tắt đa văn bản hướng tóm lược đề xuất PG_Feature_AMDS để sinh ra bản tóm tắt tóm lược cuối cùng.
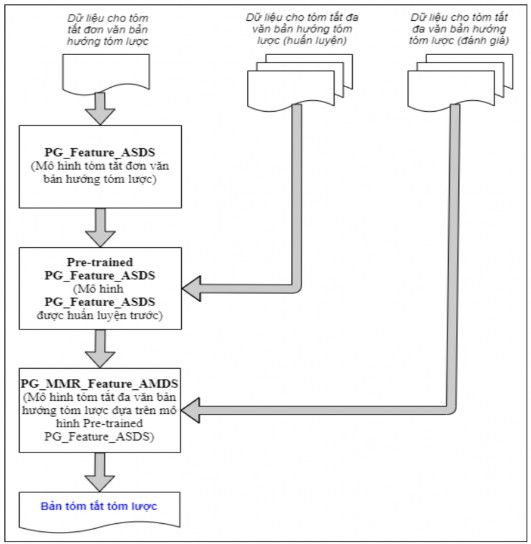
Hình 5.8. Các giai đoạn huấn luyện mô hình tóm tắt đa văn bản hướng tóm lược đề xuất PG_Feature_AMDS
5.3.2.5. Thiết kế thử nghiệm
a) Các bộ dữ liệu thử nghiệm sử dụng trong mô hình
Mô hình đề xuất được thử nghiệm trên các bộ dữ liệu với các mục đích như sau:
Đối với văn bản tiếng Anh
- Bộ dữ liệu CNN/Daily Mail: Sử dụng để huấn luyện mô hình tóm tắt đơn văn bản hướng tóm lược PG_Feature_ASDS được sử dụng làm mô hình tóm tắt được huấn luyện trước cho mô hình đề xuất.
- Bộ dữ liệu DUC 2007: Sử dụng để huấn luyện tiếp mô hình tóm tắt đơn văn bản hướng tóm lược PG_Feature_ASDS được huấn luyện trước.
- Bộ dữ liệu DUC 2004: Đây là bộ dữ liệu được sử dụng để đánh giá mô hình tóm tắt đa văn bản hướng tóm lược đề xuất PG_Feature_AMDS cho tóm tắt văn bản tiếng Anh.
Đối với văn bản tiếng Việt
- Bộ dữ liệu Baomoi: Sử dụng để huấn luyện mô hình tóm tắt đơn văn bản hướng tóm lược PG_Feature_ASDS được sử dụng làm mô hình tóm tắt được huấn luyện trước cho mô hình đề xuất.
- Bộ dữ liệu ViMs: Sử dụng để huấn luyện tiếp mô hình tóm tắt đơn văn bản PG_Feature_ASDS được huấn luyện trước.
- Bộ dữ liệu Corpus_TMV: Đây là bộ dữ liệu được sử dụng để đánh giá mô hình tóm tắt đa văn bản hướng tóm lược đề xuất PG_Feature_AMDS cho tóm tắt văn bản tiếng Việt.
b) Tiền xử lý dữ liệu
Các bộ dữ liệu văn bản đầu vào được tiền xử lý sử dụng thư viện Stanford CoreNLP đối với tiếng Anh, thư viện VNCoreNLP đối với tiếng Việt. Trước hết, các bộ dữ liệu thử nghiệm được xử lý tách lấy phần nội dung, loại bỏ các văn bản có độ dài ngắn, xóa các ký tự, từ đặc biệt mà không có nhiều ý nghĩa trong các văn bản, lấy từ gốc đối với dữ liệu tiếng Anh để giảm kích thước của bộ từ vựng và cải thiện chất lượng bản tóm tắt đầu ra. Mỗi văn bản của các bộ dữ liệu CNN/Daily Mail và Baomoi được xử lý tách riêng các phần: Tiêu đề, tóm tắt, nội dung. Đối với các bộ dữ liệu cho tóm tắt đa văn bản hướng tóm lược: Các bản tóm tắt tham chiếu của mỗi cụm dữ liệu (bộ dữ liệu DUC 2004, DUC 2007 có 04 bản tóm tắt tham chiếu; bộ dữ liệu ViMs, Corpus_TMV có 02 bản tóm tắt tham chiếu) được xử lý trích xuất từ các tệp tương ứng để sử dụng cho giai đoạn đánh giá. Sau đó, xử lý tách câu và đánh số thứ tự cho các câu trong phần nội dung của mỗi văn bản.
c) Huấn luyện mô hình
Đối với các thử nghiệm, bộ mã hóa và bộ giải mã được xây dựng từ các khối LSTM có trạng thái ẩn là 256 (bộ mã hóa sử dụng biLSTM có 128 lớp ẩn cho chiều tiến (forward) và 128 lớp ẩn cho chiều lùi (backward); còn bộ giải mã sử dụng LSTM có 256 lớp ẩn) và véc tơ từ có 128 chiều, tỷ lệ dropout là 0,2 (p = 0,2). Bộ từ vựng (vocab) có kích thước 50.000 từ. Văn bản đầu vào được tách thành các từ và đưa vào bộ mã hóa. Đầu vào của bộ giải mã trong quá trình huấn luyện là kết hợp của trạng thái ẩn của bộ mã hóa và các từ của bản tóm tắt tham chiếu. Mô hình được huấn luyện bởi thuật toán tối ưu AdamW [122]. Mô hình được huấn luyện sử dụng Google Colab với cấu hình máy chủ GPU V100, 25GB RAM được cung cấp bởi Google. Các siêu tham số được cài đặt và thời gian huấn luyện (giờ) mô hình được trình bày chi tiết trong Bảng 5.6 dưới đây.
Epochs | Batch size | Hệ số học | Bước tích lũy đạo hàm | Bộ dữ liệu huấn luyện | Thời gian huấn luyện | |
10.000 | 10 | 16 | 2.10-3 | 2 | CNN/Daily Mail | 30 |
10.000 | 10 | 16 | 2.10-3 | 2 | Baomoi | 45 |
20 | 10 | 8 | 2.10-3 | 2 | DUC 2007 | ~1 |
75 | 10 | 8 | 2.10-3 | 2 | ViMs | 2,5 |
Có thể bạn quan tâm!
-

 Mẫu Tóm Tắt Gồm Bản Tóm Tắt Tham Chiếu, Bản Tóm Tắt Của Mô Hình Trong
Mẫu Tóm Tắt Gồm Bản Tóm Tắt Tham Chiếu, Bản Tóm Tắt Của Mô Hình Trong -
 Mô Hình Sử Dụng Thuật Toán Phân Cụm K-Means Kết Hợp Vị Trí Tương Đối Của Câu
Mô Hình Sử Dụng Thuật Toán Phân Cụm K-Means Kết Hợp Vị Trí Tương Đối Của Câu -
 Các Mẫu Tóm Tắt Của Cụm D0716D Trong Bộ Dữ Liệu Duc 2007 Của Mô Hình Đề Xuất Và Con Người
Các Mẫu Tóm Tắt Của Cụm D0716D Trong Bộ Dữ Liệu Duc 2007 Của Mô Hình Đề Xuất Và Con Người -
 Mô Hình Tóm Tắt Đơn Văn Bản Hỗn Hợp Ext_Abs_Asds
Mô Hình Tóm Tắt Đơn Văn Bản Hỗn Hợp Ext_Abs_Asds -
 Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 19
Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 19 -
 Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 20
Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 20
Xem toàn bộ 185 trang tài liệu này.
Warmup
Bảng 5.6. Giá trị các siêu tham số và thời gian huấn luyện mô hình. Warmup là quá trình huấn luyện ban đầu với tỷ lệ học nhỏ để hiệu chỉnh cơ chế chú ý
Các bộ dữ liệu được xử lý chi tiết như sau:
- Bộ dữ liệu CNN/Daily Mail: Độ dài văn bản được xử lý lấy 400 từ, độ dài bản tóm tắt tham chiếu là 120 từ.
- Bộ dữ liệu Baomoi: Độ dài văn bản được xử lý lấy 400 từ, độ dài bản tóm tắt tham chiếu là 50 từ.
- Bộ dữ liệu DUC 2007: Độ dài văn bản được xử lý lấy 1.500 từ, độ dài bản tóm tắt tham chiếu là 200 từ.
- Bộ dữ liệu ViMs: Độ dài văn bản được xử lý lấy 1.500 từ, độ dài bản tóm tắt tham chiếu là 200 từ.
Trong giai đoạn đánh giá, độ dài bản tóm tắt sinh ra của mô hình được lấy số từ nằm trong khoảng từ 100 đến 200 từ đối với cả 2 bộ dữ liệu DUC 2004 và Corpus_TMV (do độ dài bản tóm tắt tham chiếu được lấy 200 từ). Mô hình sử dụng thuật toán tìm kiếm Beam với kích thước tìm kiếm bằng 5 (beam_size = 5).
d) Các kết quả thử nghiệm
Kết quả thử nghiệm của mô hình tóm tắt đơn văn bản hướng tóm lược
Bảng 5.7 dưới đây là kết quả của mô hình tóm tắt đơn văn bản hướng tóm lược PG_Feature_ASDS trên các bộ dữ liệu CNN và Baomoi đã đề xuất ở chương 4.
CNN | Baomoi | |||||
R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
PG_Feature_ASDS | 31,89 | 13,01 | 29,97 | 30,59 | 11,53 | 19,45 |
Bảng 5.7. Kết quả thử nghiệm của các mô hình tóm tắt đơn văn bản hướng tóm lược PG_Feature_ASDS trên các bộ dữ liệu CNN và Baomoi
Kết quả của mô hình tóm tắt đa văn bản hướng tóm lược cơ sở
Kết quả các độ đo R-1, R-2 và R-SU4 công bố của mô hình cơ sở [147] trên bộ dữ liệu DUC 2004 tương ứng là 36,88%; 8,73% và 12,64%.
Kết quả thử nghiệm mô hình PG_Feature_AMDS sử dụng mô hình PG_Feature_ASDS chưa được huấn luyện tiếp trên bộ dữ liệu DUC 2007 và bộ dữ liệu ViMs tương ứng
Bảng 5.8 dưới đây là các kết quả thử nghiệm trên bộ dữ liệu DUC 2004 cho tiếng Anh và bộ dữ liệu Corpus_TMV cho tiếng Việt.
R-1 | R-2 | R-L | R-S4 | R-SU4 | |
DUC 2004 | 36,56 | 9,13 | 18,39 | 8,17 | 8,55 |
Copus_TMV | 44,63 | 27,69 | 30,87 | 30,96 | 32,89 |
Bảng 5.8. Kết quả thử nghiệm mô hình PG_Feature_AMDS trên bộ DUC 2004 và Corpus_TMV sử dụng mô hình PG_Feature_ASDS chưa được huấn luyện tiếp trên bộ DUC 2007 và bộ ViMs tương ứng
Kết quả thử nghiệm mô hình PG_Feature_AMDS sử dụng mô hình tóm tắt đơn văn bản PG_Feature_ASDS đã được huấn luyện tiếp trên bộ dữ liệu DUC 2007 và bộ dữ liệu ViMs tương ứng
Bảng 5.9 dưới đây là kết quả thử nghiệm trên bộ dữ liệu DUC 2004 cho tiếng Anh và bộ dữ liệu Corpus_TMV cho tiếng Việt.
R-1 | R-2 | R-L | R-S4 | R-SU4 | |
DUC 2004 | 37,71 | 9,50 | 19,14 | 8,39 | 9,28 |
Copus_TMV | 66,04 | 39,00 | 38,81 | 44,33 | 45,80 |
Bảng 5.9. Kết quả thử nghiệm mô hình PG_Feature_AMDS trên bộ DUC 2004 và Corpus_TMV sử dụng mô hình PG_Feature_ASDS đã được huấn luyện tiếp trên bộ DUC 2007 và bộ ViMs tương ứng
Bảng 5.10 trình bày một mẫu tóm tắt bao gồm một bản tóm tắt tham chiếu của con người và bản tóm tắt của mô hình đề xuất trên bộ dữ liệu DUC 2004 (tiếng Anh). Văn bản nguồn của mẫu tóm tắt này xem Phụ lục C.6trong phần Phụ lục.
Bản tóm tắt của mô hình PG_Feature_AMDS Augusto Pinochet , 82 , was placed under arrest in London Friday by British police acting on a warrant issued by a Spanish judge . Castro , Latin America 's only remaining authoritarian leader , said the case was a senator he was traveling on a diplomatic passport and had immunity from arrest . The Chilean government has protested Pinochet 's role in the death of Chilean dictator Augusto Pinochet . In 1998 he had been arrested by British police . He said he was a member of the Pinochet Parliament . In 1998 , he was arrested for the murder of the Chilean government in 1997 . He was arrested in 1998 for being a member of a U.N. |
Bảng 5.10. Một mẫu thử nghiệm trên bộ dữ liệu DUC 2004
Bảng 5.11 trình bày một mẫu tóm tắt bao gồm một bản tóm tắt tham chiếu của con người và bản tóm tắt của mô hình đề xuất trên bộ dữ liệu Corpus_TMV (tiếng Việt). Văn bản nguồn của các mẫu tóm tắt xem Phụ lục C.6trong phần Phụ lục.
Bản tóm tắt của hệ thống PG_Feature_AMDS Theo thông tin từ một số người dân trong khu vực cho biết , mưa đá diễn ra trong khoảng 20 phút từ 15g30 đến 15g50 , trong đó có đoạn hơn nửa bánh xe ô tô . Nhiều xe mô tô chết máy phải dắt bộ qua đoạn đường ngập . Khoảng 6h30 ngày 31- 5 , tại 3 phường Tân Biên , Tân Hoà , Tân Hoà , trời mây , trời nắng , lặng gió , độ ẩm , nhiệt độ từ 22 - 29 độ C. Phương Tiện đi qua khu vực P.Tân Biên , Tân Hoà , Hố Nai ngập bằng quả cà chua bi . Trước mưa đá , do lượng mưa lớn kéo dài hơn 30 phút. |
Một bản tóm tắt tham chiếu
Bảng 5.11. Một mẫu thử nghiệm trên bộ dữ liệu Corpus_TMV
Từ các kết quả thử nghiệm, có thể thấy mô hình tóm tắt đa văn bản hướng tóm lược đề xuất đã đạt được kết quả cao cho tóm tắt văn bản tiếng Anh và tiếng Việt.
5.3.2.6. Đánh giá và so sánh kết quả
Để đảm bảo tính khách quan, kết qủa thử nghiệm của mô hình đề xuất được đánh giá và so sánh với kết quả của các phương pháp cơ sở, các phương pháp đã thử nghiệm và kết quả của các phướng pháp hiện đại khác đã công bố trên cùng bộ dữ liệu tương ứng. Bảng 5.12 là kết quả so sánh và đánh giá hiệu quả các phương pháp.
DUC 2004 | Corpus_TMV | |||||
R-1 | R-2 | R-SU4 | R-1 | R-2 | R-SU4 | |
SumBasic [147] | 29,48 | 4,25 | 8,64 | - | - | - |
KLSumm [147] | 31,04 | 6,03 | 10,23 | - | - | - |
LexRank [147] | 34,44 | 7,11 | 11,19 | - | - | - |
Centroid [147] | 35,49 | 7,80 | 12,02 | - | - | - |
ICSISumm [147] | 37,31 | 9,36 | 13,12 | - | - | - |
PG-Original [147] | 31,43 | 6,03 | 10,01 | - | - | - |
G-MMR w/ Cosine [147] | 36,88 | 8,73 | 12,64 | - | - | - |
PG_Feature_AMDS | 37,71 | 9,50 | 9,28 | 66,04 | 39,00 | 45,80 |
Bảng 5.12. So sáng và đánh giá kết quả của các phương pháp. Ký hiệu ‘-’ biểu diễn các phương pháp không được thử nghiệm trên các bộ dữ liệu tương ứng
Kết quả trong Bảng 5.12 chỉ ra rằng mô hình đề xuất PG_Feature_AMDS có kết quả tốt hơn đáng kể so với phương pháp đã thử nghiệm và các phương pháp hiện đại khác đã công bố trên hai bộ dữ liệu tương ứng. Điều đó chứng tỏ mô hình
đề xuất đã đạt được kết quả tốt cho tóm tắt đa văn bản hướng tóm lược cho tiếng Anh và tiếng Việt.
5.3.3. Mô hình tóm tắt đa văn bản hướng tóm lược dựa trên mô hình tóm tắt đơn văn bản hỗn hợp được huấn luyện trước Ext_Abs_AMDS- mds-mmr
5.3.3.1. Giới thiệu mô hình
Việc phát triển một hệ thống tóm tắt đa văn bản hướng tóm lược duy nhất sử dụng các kỹ thuật học sâu gặp nhiều khó khăn do vấn đề khan hiếm dữ liệu huấn luyện các mô hình (nếu có thì các bộ dữ liệu này cũng không đủ lớn), trong khi đó các bộ dữ liệu tóm tắt đơn văn bản hướng tóm lược sẵn có hiện nay đã đáp ứng được cho các mô hình tóm tắt đơn văn bản. Mặc dù mô hình tóm tắt đa văn bản hướng tóm lược đề xuất phát triển ở trên đã đạt được các kết quả tốt. Tuy nhiên, việc ghép tất cả các văn bản của tập đa văn bản đầu vào thành 1 siêu văn bản (siêu văn bản này sẽ có độ dài lớn) làm giảm hiệu quả của mô hình tóm tắt nếu tập đa văn bản đầu vào lớn. Để khắc phục vấn đề trên, trong phần này luận án nghiên cứu đề xuất phát triển một mô hình tóm tắt đa văn bản hướng tóm lược dựa trên mô hình tóm tắt hỗn hợp được xây dựng sử dụng các mô hình tóm tắt đơn văn bản đã đề xuất được huấn luyện trước để sinh bản tóm tắt tóm lược cho tập đa văn bản. Mô hình tóm tắt hỗn hợp được xây dựng gồm 2 mô hình tóm tắt là: mô hình tóm tắt đơn văn bản hướng trích rút và mô hình tóm tắt đơn văn bản hướng tóm lược (mô hình tóm tắt hỗn hợp này được đặt tên là Ext_Abs_ASDS).
Với tập đa văn bản gồm G văn bản đầu vào
Dmul (D1, D2 ,..., Di ,...., DG ) ; trong
đó: mỗi văn bản
Di có H câu, L từ được biểu diễn là
Di (si1, si 2 ,..., sij ,...., siH ) , với:
sij
là câu thứ j của văn bản
Di hoặc
Di (xi1, xi 2 ,..., xij ,...., siL ) , với:
xij
là từ thứ j
của văn bản
Di . Trước hết, với mỗi văn bản
Di qua mô hình tóm tắt hướng trích rút
thu được tập xác suất được chọn của các câu là:
đó:
pi ( pi1, pi 2 ,..., pij ,...., piH ) ; trong
pij (0 | sij , D,)
pij p
(1| s
, D,) , với:
pij
là xác suất được chọn của câu thứ j trong văn
ij ij
bản Di.
Do đó, tập văn bản Dmul qua mô hình tóm tắt hướng trích rút sẽ thu được tập xác
suất được chọn của các câu là: p ( p11, p12 ,..., p1H , p21, p22 ,..., p2 H ...., pNH ) .
Sau đó, áp dụng phương pháp MMR đề xuất trên tập xác suất p nhận được bản tóm tắt gồm các câu được trích rút từ tập văn bản Dmul và được coi như một đơn văn
bản gồm H' câu được biểu diễn là
D' (s' , s' ,..., s' ,...., s' ) , với: s'
là câu thứ i của
1 2 i H 'i
văn bản D' hoặc
D' (x' , x' ,..., x' ,...., x' ) , với: x' là từ thứ i của văn bản D'. Đây
1 2 i H 'i
chính là bài toán tóm tắt đơn văn bản hướng tóm lược cần giải quyết đối với văn bản D'.
Tiếp theo, văn bản D' được qua mô hình tóm tắt đơn văn bản hướng tóm lược
đã đề xuất để sinh ra bản tóm tắt gồm T từ Y ( y1, y2 ,..., yi ,...., yT )
chính là bản tóm
tắt tóm lược biểu diễn nội dung của tập đa văn bản đầu vào Dmul, với:
yi Di
hoặc
yi Di
(lúc này từ được lấy từ bộ từ vựng).
Trong mô hình, các mô hình tóm tắt đơn văn bản, mô hình tóm tắt hỗn hợp được huấn luyện trước trên các bộ dữ liệu tóm tắt đơn văn bản và được tinh chỉnh bằng việc huấn luyện tiếp trên các bộ dữ liệu tóm tắt đa văn bản tương ứng để phát triển mô hình tóm tắt đa văn bản hướng tóm lược đề xuất (mô hình này được đặt tên là Ext_Abs_AMDS-mds-mmr). Mô hình Ext_Abs_AMDS-mds-mmr có thể áp dụng hiệu quả cho tóm tắt đa văn bản tiếng Anh và tiếng Việt.
5.3.3.2. Các thành phần của mô hình
Mô hình tóm tắt đa văn bản hướng tóm lược đề xuất Ext_Abs_AMDS-mds-mmr
bao gồm các mô hình thành phần chính được mô tả như dưới đây.
a) Mô hình tóm tắt đơn văn bản hướng trích rút được huấn luyện trước
Mô hình tóm tắt đơn văn bản hướng trích rút mBERT_CNN_ESDS đã đề xuất ở chương 3 (Hình 3.4) được tinh chỉnh mô đun mã hóa từ sử dụng các mô hình tối ưu RoBERTa để mã hóa văn bản tiếng Anh, PhoBERT để mã hóa văn bản tiếng Việt thay vì mô hình mBERT (các mô hình tối ưu RoBERTa, PhoBERT đạt hiệu quả cao hơn so với các mô hình BERT, mBERT) để cải thiện hiệu quả cho mô hình tóm tắt (mô hình được đặt tên là RoPhoBERT_CNN_ESDS). Mô hình được biểu diễn trong Hình 5.9 dưới đây.
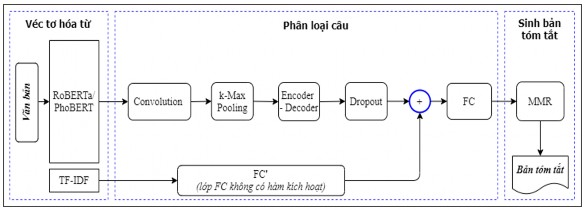
Hình 5.9. Mô hình tóm tắt đơn văn bản hướng trích rút RoPhoBERT_CNN_ESDS
b) Mô hình tóm tắt đơn văn bản hướng tóm lược được huấn luyện trước
Mô hình tóm tắt đơn văn bản hướng tóm lược PG_Feature_ASDS đã đề xuất ở chương 4 (Hình 4.2) được tinh chỉnh sử dụng đặc trưng trọng số của từ TF-IDF thay cho các đặc trưng tần suất xuất hiện của từ TF, vị trí câu POSI để giảm độ phức tạp tính toán cho mô hình (mô hình này được đặt tên là PG_TF-IDF_ASDS). Mô hình được biểu diễn trong Hình 5.10 dưới đây.
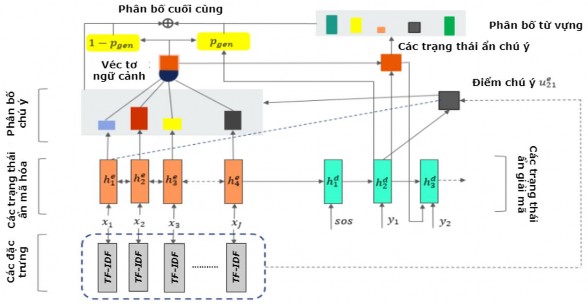
Hình 5.10. Mô hình tóm tắt đơn văn bản hướng tóm lược PG_TF-IDF_ASDS
Với mỗi véc tơ biểu diễn văn bản đầu vào
x x11, x21, x31,...., xJk; trong đó: xjk
biểu diễn từ thứ j ở câu thứ k, ta xác định được véc tơ biểu diễn TF-IDF:
xTF IDF
TF IDF (x11),TF IDF (x21),...,TF IDF (xJ k ). Giá trị TF-IDF thể
hiện mức độ quan trọng của từ trong văn bản mà văn bản nằm trong tập văn bản đang xét nên để nâng trọng số của từ giúp cho mô hình chú ý vào các từ quan trọng, ta nhân trọng số chú ý của từ với giá trị xTF-IDF tương ứng. Với việc sử dụng đặc
trưng trọng số của từ TF-IDF, điểm chú ý được tính theo công thức (5.11) như sau:
se (valign )Ttanh Walign hehdbalign .xTF IDF
(5.11)
tj j t
Sau đó, phân bố chú ý được tính theo công thức (4.8) ở trên.
c) Mô hình tóm tắt đơn văn bản hỗn hợp được huấn luyện trước sử dụng cho mô hình đề xuất
Một mô hình tóm tắt đơn văn bản hướng tóm lược hỗn hợp (mô hình được đặt tên là Ext_Abs_ASDS) được xây dựng dựa trên hai mô hình tóm tắt đơn văn bản pre-trained RoPhoBERT_CNN_ESDS, pre-trained PG_TF-IDF_ASDS. Mô hình này được sử dụng như mô hình tóm tắt đơn văn bản hướng tóm lược được huấn luyện trước cho mô hình tóm tắt đa văn bản hướng tóm lược đề xuất. Trong mô hình Ext_Abs_ASDS, mô hình pre-trained PG_TF-IDF_ASDS được huấn luyện tiếp trên tập các câu được trích rút thu được từ đầu ra của mô hình RoPhoBERT_CNN_ESDS. Mô hình pre-trained Ext_Abs_ASDS được biểu diễn chi tiết trong Hình 5.11 dưới đây.