Một bản tóm tắt tham chiếu
Kakadu National Park is exposed to a number of serious threats which are placing it under both ascertained and potential danger," the bureau said in a report after it sent a mission to Australia to examine claims by conservation groups that Kakadu (National Park in Northern Territory) was under threat from Jabiluka.
Bảng 5.5. Các mẫu tóm tắt của cụm D0716D trong bộ dữ liệu DUC 2007 của mô hình đề xuất và con người
Bảng 5.6 trình bày mẫu tóm tắt của cụm văn bản Cluster_2 trong bộ dữ liệu Corpus_TMV gồm một bản tóm tắt tham chiếu và bản tóm tắt của mô hình đề xuất. Các văn bản nguồn của mẫu tóm tắt này xem Phụ lục C.5trong phần Phụ lục.
Tổ chức quan sát Nhân quyền có trụ sở tại Mỹ cho rằng 82 người, trong đó ít nhất 57 thường dân đã thiệt mạng do các cuộc tấn công của máy bay không người lái và máy bay tấn công khác ở Yemen giữa tháng 9/2012 và tháng 6/2013. Những cuộc tấn công như vậy là bừa bãi và trái với luật pháp quốc tế. Tuy nhiên, Mỹ đã ngay lập tức phủ nhận những cáo buộc trên. Phát ngôn viên Nhà Trắng Jay Carney cho biết: "Chúng tôi sẽ xem xét cẩn trọng những báo cáo này”. Carney cũng cho biết, khi quyết định sử dụng máy bay không người lái chống lại các nghi phạm khủng bố, thay vì sử dụng quân đội hoặc sử dụng các loại vũ khí khác, Washington đã "lựa chọn hành động ít có khả năng gây ra thiệt hại nhất đối với những người vô tội". Theo ông Carney, chính quyền Mỹ đang xem xét cẩn trọng báo mới nhất của tổ chức Ân Xá Quốc tế về số lượng thường dân thiệt mạng và bị thương trong các cuộc không kích bằng máy bay không người lái của Mỹ. Ông Carney khẳng định, các chiến dịch chống khủng bố của Mỹ được tiến hành hoàn toàn tuân thủ theo luật pháp của Mỹ và quốc tế. |
Bản tóm tắt của mô hình đề xuất Kmeans_Centroid_EMDS |
Hôm 22/10 , Tổ chức Ân xá Quốc tế và Tổ chức Nhân quyền có trụ sở tại Mỹ ( Human Rights Watch – HRW ) đã cùng đưa ra báo cáo chi tiết về những thương vong trong các hoạt động của Mỹ ở Pakistan và Yemen . Tổ chức quan sát Nhân quyền có trụ sở tại Mỹ cho rằng 82 người , trong đó ít nhất 57 thường dân đã thiệt mạng do các cuộc tấn công của máy bay không người lái và máy bay tấn công khác ở Yemen giữa tháng 9/2012 và tháng 6/2013 . Tổ chức Ân xá quốc tế có trụ sở tại London thì cho biết họ đang lo ngại các cuộc tấn công được nêu trong báo cáo và các cuộc tấn công khác là những hành động giết người trái pháp luật mà theo luật tố tụng có thể cấu thành tội ác chiến tranh . Tổ chức Ân xá dẫn nguồn của chính phủ Pakistan và các tổ chức phi chính phủ cho biết có đến từ 400 đến 900 thường dân đã bị giết hại trong hơn 300 cuộc tấn công từ năm 2004 đến tháng 9/2013 . Tuy nhiên , Mỹ đã ngay lập tức phủ nhận những cáo buộc trên. |
Có thể bạn quan tâm!
-
![Mô Hình Tóm Tắt Đơn Văn Bản Hướng Tóm Lược Cơ Sở [128]](https://tailieuthamkhao.com/uploads/2022/06/10/nghien-cuu-phat-trien-mot-so-phuong-phap-tom-tat-van-ban-su-dung-ky-13-1-120x90.jpg)
![Mô Hình Tóm Tắt Đơn Văn Bản Hướng Tóm Lược Cơ Sở [128]](data:image/svg+xml,%3Csvg%20xmlns=%22http://www.w3.org/2000/svg%22%20viewBox=%220%200%2075%2075%22%3E%3C/svg%3E) Mô Hình Tóm Tắt Đơn Văn Bản Hướng Tóm Lược Cơ Sở [128]
Mô Hình Tóm Tắt Đơn Văn Bản Hướng Tóm Lược Cơ Sở [128] -
 Mẫu Tóm Tắt Gồm Bản Tóm Tắt Tham Chiếu, Bản Tóm Tắt Của Mô Hình Trong
Mẫu Tóm Tắt Gồm Bản Tóm Tắt Tham Chiếu, Bản Tóm Tắt Của Mô Hình Trong -
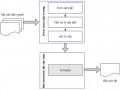 Mô Hình Sử Dụng Thuật Toán Phân Cụm K-Means Kết Hợp Vị Trí Tương Đối Của Câu
Mô Hình Sử Dụng Thuật Toán Phân Cụm K-Means Kết Hợp Vị Trí Tương Đối Của Câu -
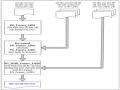 Các Giai Đoạn Huấn Luyện Mô Hình Tóm Tắt Đa Văn Bản Hướng Tóm Lược Đề Xuất Pg_Feature_Amds
Các Giai Đoạn Huấn Luyện Mô Hình Tóm Tắt Đa Văn Bản Hướng Tóm Lược Đề Xuất Pg_Feature_Amds -
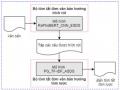 Mô Hình Tóm Tắt Đơn Văn Bản Hỗn Hợp Ext_Abs_Asds
Mô Hình Tóm Tắt Đơn Văn Bản Hỗn Hợp Ext_Abs_Asds -
 Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 19
Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 19
Xem toàn bộ 185 trang tài liệu này.
Bảng 5.6. Các mẫu tóm tắt của cụm Cluster_2 trong bộ dữ liệu Corpus_TMV của mô hình đề xuất và con người
Với các bản tóm tắt kết quả trong Bảng 5.5 và Bảng 5.6, có thể thấy bản tóm tắt đầu ra của mô hình đề xuất đưa ra các thông tin chính giống với bản tóm tắt tham chiếu của con người tương ứng. Nói cách khác, nó chứa thông tin chính của tập các văn bản đầu vào. Tuy nhiên, trình tự của các câu cần được xem xét kỹ lưỡng để cải thiện tính mạch lạc cho bản tóm tắt đầu ra của mô hình đề xuất.
5.3. Các mô hình tóm tắt đa văn bản hướng tóm lược dựa trên mô hình tóm tắt đơn văn bản được huấn luyện trước
5.3.1. Đặt vấn đề
Tóm tắt hướng tóm lược dựa trên mạng nơ ron sử dụng mô hình seq2seq đã cho các kết quả khả quan nhưng các nghiên cứu này tập trung chủ yếu vào tóm tắt đơn văn bản do dữ liệu huấn luyện sẵn có đã đáp ứng được phần nào cho bài toán tóm tắt đơn văn bản [43,144]. Trong bài toán tóm tắt đa văn bản hướng tóm lược, đã có một số nghiên cứu được công bố như [145,146]. Baumel và cộng sự [142] đề xuất mở rộng hệ thống tóm tắt đa văn bản hướng tóm lược để sinh ra các bản tóm tắt tập trung vào truy vấn. Zhang và cộng sự [146] thêm bộ mã hóa tập văn bản vào khung tóm tắt phân cấp. Hệ thống của Lebanoff và cộng sự [147] điều chỉnh mô hình seq2seq được huấn luyện trên dữ liệu tóm tắt đơn văn bản để hoạt động được với một tập văn bản đầu vào. Hệ thống này sử dụng phương pháp MMR để lựa chọn các câu biểu diễn tập văn bản đầu vào và sử dụng mô hình seq2seq để liên kết các câu thành một bản tóm tắt tóm lược.
Tuy nhiên, một trong những khó khăn đối với bài toán tóm tắt đa văn bản hướng tóm lược là dữ liệu huấn luyện sẵn có không đủ lớn để huấn luyện các mô hình học sâu hiệu quả. Thực tế hiện nay, chỉ có một vài bộ dữ liệu sẵn có với số lượng văn bản hạn chế được sử dụng cho bài toán tóm tắt đa văn bản hướng tóm lược, trong khi đó đã có các bộ dữ liệu sẵn có với số lượng văn bản đủ lớn đáp ứng được phần nào cho các mô hình tóm tắt đơn văn bản hướng tóm lược sử dụng các kỹ thuật học sâu (đối với cả tiếng Anh và tiếng Việt). Với thực tế đó, việc phát triển một mô hình tóm tắt duy nhất cho bài toán tóm tắt đa văn bản hướng tóm lược rất khó đạt được hiệu quả như mong muốn, trong khi đó các mô hình tóm tắt đơn văn bản đã mang lại những kết quả khả quan. Trong phần này, luận án nghiên cứu phát triển hai phương pháp tóm tắt đa văn bản hướng tóm lược dựa trên các mô hình tóm tắt đơn văn bản hướng tóm lược (lúc này mô hình tóm tắt đơn văn bản hướng tóm lược được xem như mô hình tóm tắt được huấn luyện trước) theo các phương pháp tiếp cận khác nhau. Hai phương pháp này được trình bày chi tiết dưới đây.
5.3.2. Mô hình tóm tắt đa văn bản hướng tóm lược dựa trên mô hình tóm tắt đơn văn bản hướng tóm lược được huấn luyện trước PG_Feature_AMDS
5.3.2.1. Giới thiệu mô hình
Để phát triển mô hình tóm tắt đa văn bản hướng tóm lược, trước hết G văn bản
của tập văn bản nguồn đầu vào
Dmul (D1, D2 ,..., Di ,...., DG )
(mỗi văn bản
Di có H
câu, H có giá trị thay đổi tùy thuộc vào từng văn bản) được ghép thành 1 văn bản lớn gọi là “siêu văn bản” và siêu văn bản này được coi như một đơn văn bản
D' (s , s ,..., s , s , s ,..., s ...., s
) gồm N’ câu (với N’ là tổng số câu của tập
11 12 1H 21 22 2 H GH
văn bản đầu vào Dmul). Giả sử văn bản D' được viết lại thành
D' (s , s ,..., s ,...., s ) , với s là câu thứ i trong văn bản D', H' là số lượng câu của
1 2 i H 'i
văn bản D'). Bên cạnh đó, văn bản D' này cũng được biểu diễn dưới dạng
D' (x , x ,..., x , x , x ,..., x ,...., x ) (mỗi văn bản D có L từ, L có giá trị thay
11 12 1L 21 22 2 L GL i
đổi tùy thuộc vào từng văn bản) và được viết lại thành
D' (x , x ,..., x ,...., x
) , với
1 2 i J
xi là từ thứ i trong văn bản D', J là số lượng từ của văn bản D'. Như vậy, để tóm tắt
đa văn bản Dmul ta đi tóm tắt đơn văn bản D' và đây chính là bài toán tóm tắt đơn văn bản hướng tóm lược cần giải quyết đối với văn bản D'. Sau đó, sử dụng mô hình tóm tắt đơn văn bản hướng tóm lược đã đề xuất PG_Feature_ASDS ở chương 4 để tóm tắt văn bảnD' (lúc này mô hình PG_Feature_ASDS được coi như mô hình tóm tắt đơn văn bản hướng tóm lược được huấn luyện trước). Bản tóm tắt tóm lược
của D' sinh ra gồm T từ được biểu diễn là Y ( y1, y2 ,..., yi ,...., yT )
chính là bản tóm
tắt tóm lược biểu diễn nội dung của tập đa văn bản đầu vào Dmul, với:
yi Di
hoặc
yi Di
(lúc này từ được lấy từ bộ từ vựng).
Để tăng hiệu quả cho mô hình tóm tắt đa văn bản, mô hình tóm tắt đơn văn bản được huấn luyện trước PG_Feature_ASDS được tinh chỉnh bằng việc huấn luyện tiếp trên các bộ dữ liệu thử nghiệm của bài toán tóm tắt đa văn bản hướng tóm lược tương ứng. Mô hình tóm tắt đa văn bản hướng tóm lược này được đặt tên là mô hình PG_Feature_AMDS. Mô hình đề xuất PG_Feature_AMDS được thử nghiệm trên các bộ dữ liệu tóm tắt đa văn bản tiếng Anh, tiếng Việt cho kết quả tốt và có thể áp dụng hiệu quả cho tóm tắt đa văn bản tiếng Anh và tiếng Việt.
5.3.2.2. Các thành phần của mô hình
a) Mô hình tóm tắt đơn văn bản hướng tóm lược được huấn luyện trước
Mô hình tóm tắt đơn văn bản hướng tóm lược đã đề xuất PG_Feature_ASDS ở chương 4 (Hình 4.2) được sử dụng để phát triển mô hình tóm tắt đa văn bản hướng tóm lược. Mô hình này được xem như mô hình tóm tắt đơn văn bản hướng tóm lược được huấn luyện trước (pre-trained PG_Feature_ASDS).
b) Các đặc trưng đề xuất thêm mới cho mô hình
Đặc trưng vị trí câu (POSI)
Với văn bản đầu vào x x1, x2 , x3,...., xJ có H câu, véc tơ x được viết lại là
x x11, x21, x31,...., xJH ; trong đó: xjh là từ thứ j ở câu thứ h. Từ véc tơ x, ta xác định được 1 véc tơ có độ dài bằng véc tơ x biểu diễn vị trí của câu chứa từ đó:
xPOSI
1,1,1,..., h, h.
Do bộ giải mã sử dụng mạng LSTM để dự đoán một từ dựa vào từ trước đó nên đối với các văn bản dài thì thông tin ở phần đầu văn bản sẽ bị “quên” dẫn đến nội
dung sẽ tập trung ở cuối văn bản. Chính vì thế, mô hình sử dụng thêm đặc trưng vị trí câu xPOSI và xử lý cập nhật nâng trọng số chú ý của các từ của các câu ở đầu văn bản lên bằng cách chia trọng số chú ý của từ cho vị trí câu xPOSI tương ứng của nó.
Đặc trưng tần suất xuất hiện của từ
Với các văn bản có độ dài khác nhau, có những từ xuất hiện nhiều trong các văn bản dài thay vì xuất hiện trong các văn bản ngắn nên tần suất xuất hiện của từ t trong văn bản d được tính theo công thức sau:
TF( t ) f t ,d ; trong đó: t là một từ trong văn bản d, f(t,d) là số lần xuất hiện của
T
t trong văn bản d, T là tổng số từ trong văn bản.
Với véc tơ biểu diễn văn bản đầu vào x x11, x21, x31,...., xJH ; trong đó: xjh là
từ thứ j ở câu thứ h, ta xác định được véc tơ biểu diễn TF là:
xTF
TF (x11),TF (x21),TF (x31),....,TF (xJ H ). Giá trị TF biểu diễn mức độ quan
trọng của từ trong văn bản nên mô hình sử dụng thêm đặc trưng TF và xử lý cập
nhật nâng trọng số của từ lên bằng cách nhân trọng số chú ý của từ với ứng để giúp mô hình chú ý vào các từ quan trọng.
Độ đo MMR
xTF
tương
Điểm MMR thể hiện được độ tương đồng của từ với chủ đề văn bản và tính dư thừa thông tin đối với bản tóm tắt hiện có.
Với véc tơ biểu diễn văn bản đầu vào x x11, x21, x31,...., xJH ; trong đó: xjh là
từ thứ j ở câu thứ h, véc tơ biểu diễn MMR được xác định là:
xMMR MMR(x11), MMR(x21), MMR(x31),...., MMR(xJ H )
Tại thời điểm đánh giá mô hình, điểm MMR được đưa vào để tính giá trị phân bố chú ý.
Như vậy, giá trị phân bố chú ý được tính lại sau khi thêm 3 đặc trưng mới như
sau:
- Trong giai đoạn huấn luyện mô hình: Tính toán theo công thức (4.25) và công thức (4.8) ở trên.
- Trong giai đoạn đánh giá mô hình: Tính toán theo công thức (5.9) dưới đây và công thức (4.8) ở trên.
(valign )Ttanh Walign hehdbalign
se
j t
.x .x
(5.9)
tjx
POSI
TF MMR
c) Phương pháp PG - MMR
Phương pháp PG – MMR [147] mô tả khung lặp thực hiện tóm tắt đa văn bản dưới dạng một siêu văn bản được kết hợp từ tập các văn bản đầu vào để sinh ra bản tóm tắt. Trong mỗi bước lặp, phương pháp PG - MMR chọn ra k câu có điểm cao nhất dựa theo nguyên tắc của phương pháp MMR, k câu này được sử dụng làm đầu vào cho mạng sinh từ - sao chép từ để sinh ra một câu tóm tắt. Tiếp theo, điểm của các câu đầu vào được cập nhật lại dựa trên độ tương đồng với các câu của văn bản đầu vào (độ quan trọng) và các câu đã tóm tắt trong các bước lặp trước (độ dư thừa). Câu giống với câu đã được sinh tóm tắt trước đó hơn sẽ nhận điểm thấp hơn. Việc chọn k câu thông qua phương pháp PG - MMR giúp cho mô hình sinh từ - sao
chép từ xác định được nội dung của câu nguồn chưa đưa vào bản tóm tắt, từ đó giải quyết được vấn đề trùng lặp thông tin khi tóm tắt văn bản dài.
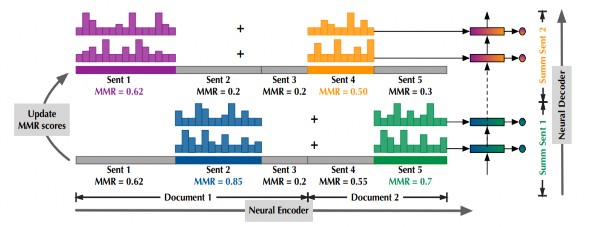
Hình 5.6. Minh họa phương pháp PG-MMR (k=2) [147]
Để mô hình sinh từ - sao chép từ hoạt động hiệu quả khi sử dụng k câu nguồn chọn được để thực hiện tóm tắt mà không cần huấn luyện lại mô hình, các tham số được điều chỉnh trong quá trình đánh giá như sau:
Giá trị phân bố chú ý phụ thuộc vào k câu được chọn: Nếu từ thuộc k câu được chọn thì sẽ được tính theo công thức (4.8) ở chương 4, trong các trường hợp còn lại thì sẽ bằng 0 như sau:
e, nÒu tò jk c©u ®îc chän
e
tjnew tj
(5.10)
0, trong c¸c trêng hîp cßn l¹i
Trong phương pháp PG-MMR, các câu không được chọn gọi là các câu bị “tắt”
(“mute”).
Độ tương đồng và độ dư thừa của câu nguồn trong phương pháp PG - MMR được tính toán theo công thức (2.44) của phương pháp MMR đề xuất đã trình bày ở chương 2.
5.3.2.3. Mô hình tóm tắt đa văn bản hướng tóm lược đề xuất
Mô hình tóm tắt đa văn bản hướng tóm lược đề xuất được trình bày chi tiết trong Hình 5.7.
Mô hình sử dụng phương pháp MMR để trích rút các câu đại diện từ siêu văn bản được kết hợp từ tập văn bản nguồn đầu vào và tận dụng mô hình mã hóa - giải mã (ở đây là mạng Pointer-Generator) để tóm tắt các câu này thành bản tóm tắt tóm lược và lặp lại cho đến khi đạt ngưỡng xác định. Mô hình đề xuất sử dụng mô hình tóm tắt đơn văn bản hướng tóm lược được huấn luyện trước trên các bộ dữ liệu tóm tắt đơn văn bản hướng tóm lược tương ứng.
Mô hình tóm tắt đa văn bản hướng tóm lược đề xuất gồm 2 thành phần chính:
- Mô hình tóm tắt đơn văn bản hướng tóm lược PG_Feature_ASDS được huấn luyện trước trên các bộ dữ liệu tóm tắt đơn văn bản hướng tóm lược tương ứng đã đề xuất ở chương 4 (gọi là mô hình pre-trained PG_Feature_ASDS).
- Mô hình PG-MMR [147] áp dụng trong tóm tắt đa văn bản: Để tương thích với mô hình tóm tắt đơn văn bản pre-trained PG_Feature_ASDS, mô hình PG-
MMR [147] được xử lý thêm các đặc trưng tần suất xuất hiện của từ TF và vị trí câu trong văn bản POSI.

Hình 5.7. Mô hình tóm tắt đa văn bản hướng tóm lược đề xuất PG_Feature_AMDS
Đối với bộ giải mã, cần chia thành hai giai đoạn là: Huấn luyện mô hình và sinh bản tóm tắt vì khi huấn luyện mô hình ta sử dụng giá trị đầu ra thực tế làm đầu vào cho bộ giải mã, còn sinh bản tóm tắt là giai đoạn sau khi đã huấn luyện xong mô hình pre-trained PG_Feature_ASDS và sử dụng mô hình này để dự đoán kết quả đầu ra. Do không biết được kết quả đầu ra thực tế như trong giai đoạn huấn luyện nên mô hình sử dụng thuật toán tìm kiếm Beam để tìm ra kết quả phù hợp nhất.
Các đặc trưng đề xuất thêm mới vào từng giai đoạn như sau:
- Giai đoạn huấn luyện mô hình pre-trained PG_Feature_ASDS (mô hình này là đầu vào cho phương pháp PG-MMR): Đề xuất thêm các đặc trưng tần suất xuất hiện của từ TF và vị trí câu POSI vào khi tính điểm chú ý của từ trong văn bản.
- Giai đoạn đánh giá mô hình (xử lý bởi phương pháp PG-MMR): Thêm các đặc trưng TF, POSI và MMR để tính điểm chú ý áp dụng cho từng đơn văn bản trong siêu văn bản trước khi đưa vào thuật toán tóm tắt đa văn bản.
Dựa trên thuật toán tóm tắt của mô hình trong [147], thuật toán tóm tắt của mô hình đề xuất được mô tả dưới đây.
Đầu vào: - Dữ liệu đơn văn bản (SD); - Dữ liệu đa văn bản (MD); Đầu ra: Bản tóm tắt của tập đa văn bản (Summary); Thuật toán: 1: Huấn luyện mô hình Pointer – Generator với SD; 2: Tính toán I(Si) và R(Si) tương ứng là các điểm độ quan trọng và độ dư thừa của các câu nguồn đầu vào Si MD; 3: MMR(Si) λI(Si) với tất cả các câu nguồn; 4: Summary {}; 5: t chỉ số (index) của các từ trong bản tóm tắt; 6: While t < Lmax do //Lmax là độ dài tối đa bản tóm tắt; 7: Chọn k câu với điểm MMR cao nhất; 8: Tính ae theo công thức (4.5), (4.6) và (5.10); tjnew 9: Chạy giải mã PG cho từng bước để nhận được {wt}; //w là bản tóm tắt Summary từ k câu 10: Summary Summary + {wt}; //Summary là bản tóm tắt 11: If wt là ký hiệu kết thúc câu then 12: R(Si) Sim(Si,Summary), i; 13: MMR(Si) λI(Si) − (1 − λ)R(Si), i; 14: End if; 15: End While; 16: Return; |
Thuật toán 5.3: PG-MMR cho tóm tắt đa văn bản tóm lược
5.3.2.4. Mô hình huấn luyện đề xuất
Trong quá trình thử nghiệm mô hình tóm tắt đa văn bản sử dụng mô hình pre- trained PG_Feature_ASDS, nhận thấy các kết quả thu được của mô hình chưa cao như mong muốn. Do đó, mô hình đề xuất tinh chỉnh mô hình pre-trained PG_Feature_ASDS bằng việc huấn luyện tiếp mô hình pre-trained PG_Feature_ASDS trên các bộ dữ liệu tóm tắt đa văn bản tương ứng (các bộ dữ liệu tóm tắt đa văn bản được sử dụng để huấn luyện tiếp mô hình khác biệt với các bộ dữ liệu sẽ sử dụng để đánh giá mô hình). Các giai đoạn huấn luyện và đánh giá cho mô hình tóm tắt đa văn bản hướng tóm lược được biểu diễn chi tiết như trong hình
5.8 dưới đây, bao gồm 3 giai đoạn:
(1) Giai đoạn 1: Huấn luyện mô hình tóm tắt đơn văn bản hướng tóm lược ban đầu PG_Feature_ASDS để được mô hình tóm tắt đơn văn bản hướng tóm lược được huấn luyện trước (mô hình pre-trained PG_Feature_ASDS).
Mô hình tóm tắt đơn văn bản hướng tóm lược được huấn luyện trên bộ dữ liệu CNN/Daily Mail (tiếng Anh) và bộ dữ liệu Baomoi (tiếng Việt) để được mô hình tóm tắt đơn văn bản hướng tóm lược được huấn luyện trước sử dụng cho mô hình tóm tắt đa văn bản hướng tóm lược đề xuất.
(2) Giai đoạn 2: Huấn luyện tiếp mô hình tóm tắt đơn văn bản hướng tóm lược PG_Feature_ASDS trên các bộ dữ liệu tóm tắt đa văn bản tương ứng.