Câu hỏi trên được biên soạn tương ứng với MTBG3.5 là "mô tả các phân phối lấy mẫu bao gồm phân phối của các thống kê mẫu liên quan trung bình mẫu, độ lệch chuẩn mẫu, tần suất mẫu". Câu hỏi phù hợp với mức độ 3, thuộc cụm năng lực liên kết trong thang đánh giá năng lực SLTKYH chúng tôi mô tả ở Bảng 2.8, Bảng 4.2. Câu hỏi đánh giá việc hiểu về khái niệm lấy mẫu ngẫu nhiên và phân phối lấy mẫu
của thống kê trung bình mẫu X trong trường hợp phân phối của tổng thể là phân phối chuẩn. Thống kê trả lời của SV đối với câu hỏi này thể hiện trong Bảng 5.2.
Bảng 5.2. Kết quả trả lời tương ứng câu hỏi 7 của Test 2
Các phương án lựa chọn | ||||||
A | B | C* | D | Bỏ trống | Tổng | |
Nhóm trên | 0 | 1 | 35 | 0 | 0 | 36 |
Nhóm dưới | 4 | 5 | 24 | 3 | 0 | 36 |
Tổng | 4 | 6 | 59 | 3 | 0 | |
Tỉ lệ (%) | 5,6 | 8,3 | 81,9 | 4,2 | 0 | |
Độ khó | P = 0,819 | |||||
Độ phân biệt | D = 0,31 (khá tốt, có thể làm cho tốt hơn) | |||||
Có thể bạn quan tâm!
-

 Liệt Kê 14 Vấn Đề Có Bối Cảnh Lâm Sàng Y Học
Liệt Kê 14 Vấn Đề Có Bối Cảnh Lâm Sàng Y Học -
 Ma Trận Đề Kiểm Tra Đánh Giá Năng Lực Sltkyh (Ma Trận 2)
Ma Trận Đề Kiểm Tra Đánh Giá Năng Lực Sltkyh (Ma Trận 2) -
 Phân Tích Kết Quả Thực Nghiệm Đối Với Bài Kiểm Tra Test 2:
Phân Tích Kết Quả Thực Nghiệm Đối Với Bài Kiểm Tra Test 2: -
 Kết Quả Trả Lời Tương Ứng Câu Hỏi 1 Của Test 1
Kết Quả Trả Lời Tương Ứng Câu Hỏi 1 Của Test 1 -
 Trả Lời Của Sv4 Đối Với Nhiệm Vụ 1 Của Test_Thuchanh
Trả Lời Của Sv4 Đối Với Nhiệm Vụ 1 Của Test_Thuchanh -
 Kết Quả Trả Lời Tương Ứng Câu Hỏi 4 Của Test 3
Kết Quả Trả Lời Tương Ứng Câu Hỏi 4 Của Test 3
Xem toàn bộ 200 trang tài liệu này.
(Ghi chú: * là đáp án đúng)
Câu hỏi có độ khó P = 0,819, đối với SV ngành y khoa được khảo sát thì đây được xem là một câu hỏi khá dễ đối với SV, D = 0,31 được xem là chấp nhận được (câu hỏi khá tốt, có thể chỉnh sửa cho tốt hơn). Nếu chỉ xét về loại câu hỏi TNKQ với P = 0,819 thì cần chỉnh sửa để tăng độ khó của câu hỏi. Tuy nhiên, kết quả này cho thấy câu hỏi biên soạn thực tế là phù hợp với mức độ 3 theo thang đánh giá, cho chúng tôi một bằng chứng tốt để đưa ra đánh giá tổng quan về mức độ SLTKYH của SV y khoa được khảo sát. Hơn nữa, với mục đích tìm hiểu về quá trình suy luận của SV khi lựa chọn câu trả lời, trong câu hỏi chúng tôi có yêu cầu SV đưa ra lời giải thích. Qua giải thích của SV, có thể có được những đánh giá xác thực hơn về năng lực SLTKYH của các em.
Đối với câu hỏi này, 81,9% SV chọn đáp án đúng là C, nghĩa là các em đã truy hồi lại được các kí hiệu trong phân phối chuẩn N (; 2 ) và công thức thống kê liên
quan đến trung bình mẫu, khi X thỏa mãn phân phối chuẩn thì
K ( X ).
![]()
n có
phân phối chuẩn tắc N(0;1), tiếp theo đó là xác định đúng n = 10 (kích thước của mẫu ngẫu nhiên) mà không phải n = 100 (số lần lặp lại khi lấy mẫu ngẫu nhiên), nghĩa là các em đã bắt đầu suy luận với ý tưởng mẫu ngẫu nhiên, quá trình lấy mẫu. Tuy nhiên, điều này chưa cho chúng tôi biết được SV thực sự đã có một sự hiểu biết
về khái niệm phân phối lấy mẫu của thống kê trung bình mẫu X hay không. Trong những giải thích của SV về sự lựa chọn đáp án C, chúng tôi thấy rằng không có SV
nào đề cập đến mẫu ngẫu nhiên và phân phối của X . Đây là một giải thích tốt nhất trong số trả lời của những SV lựa chọn đáp án C (xem Hình 5.2).

Hình 5.2. Trả lời của SV đối với câu hỏi 7 của Test 2
Điều này cho thấy, hầu hết SV chưa có một sự hiểu biết đầy đủ về phân phối
của thống kê K, công thức
K ( X ). n
![]()
N (0;1) phải được giải thích theo nghĩa
quá trình, bắt đầu với một mẫu ngẫu nhiên kích thước n = 10 rút ra từ tổng thể có phân phối chuẩn, lặp lại 100 lần quá trình lấy mẫu ngẫu nhiên như vậy, phân phối của các trung bình mẫu sẽ có phân phối chuẩn với kỳ vọng là và độ lệch chuẩn là
![]()
/ n . Chuẩn hóa phân phối trung bình mẫu, ta sẽ có phân phối của thống kê K. Như vậy, hiểu một cách sâu sắc thì K là một quy luật của sự biến thiên trong quá trình lấy mẫu, nó thể hiện mối liên hệ giữa tham số của tổng thể và thống kê
trung bình mẫu X. Phân phối của K là một công cụ quan trọng trong thống kê suy diễn, cho phép chúng ta dựa vào mẫu để suy diễn cho tổng thể, cụ thể là làm các suy diễn thống kê liên quan đến tham số của tổng thể.
Ví dụ 5.2. Xem xét trả lời của SV đối với câu hỏi 16 trong bài kiểm tra Test 2.
Câu 16. (M5): Nghiên cứu sự phụ thuộc của hàm lượng Glucose (đường huyết) và Hormone (nội tiết tố). Hàm lượng Glucose (đơn vị mmol/L) và Hormone trong máu (đơn vị IU/mL) của một mẫu 35 bệnh nhân được xác định và lưu trong file Data.sav. Xử lý dữ liệu, kết quả của mô hình hồi qui tuyến tính thu được:
Hormone = –0,44.Glucose + 5,77; R2 = 0,56; test t của hệ số góc (độ dốc) có
Sig. = 10-4.
Từ kết quả thu được của mẫu số liệu, hãy viết một báo cáo trong đó đưa ra những nhận định có cơ sở cho nghiên cứu trên.
Từ đó, đưa ra một ví dụ về dự đoán nồng độ Hormone của một bệnh nhân khi biết chỉ số đường huyết của bệnh nhân đó.
Phân tích.
Loại câu hỏi: TL mở. Nội dung TKYH: Phân tích hồi qui tuyến tính đơn biến.
Năng lực SLTKYH: Dự đoán.
Bối cảnh lâm sàng: Câu hỏi xây dựng trên bối cảnh nghiên cứu mối liên quan giữa hàm lượng Glucose và Hormone. Glucose máu là một chỉ số quan trọng giúp bác sĩ đánh giá khả năng kiểm soát đường huyết của cơ thể bệnh nhân, nhờ đó có thể xác định bệnh nhân có mắc các bệnh lý liên quan tới đường huyết (bệnh tiểu đường) hay không, cùng với đó còn có thể đánh giá xem bệnh nhân mắc bệnh tiểu đường có đáp ứng được với các phương pháp điều trị đang áp dụng hay không. Hormone là những chất được sản xuất bởi các tuyến nội tiết có tác dụng to lớn đối với các quá trình của cơ thể. Chúng ảnh hưởng đến sự tăng trưởng và phát triển, tâm trạng, chức năng tình dục, sinh sản và trao đổi chất.
Cụm năng lực: Phản ánh – Mức 5. Câu hỏi trên được đưa ra nhằm đánh giá năng lực SLTKYH Dự đoán của SV liên quan đến phân tích hồi qui tuyến tính đơn biến. Câu hỏi này phù hợp với mức 5 trong thang đánh giá năng lực SLTKYH chúng tôi mô tả ở Bảng 2.8 và Bảng 4.4. Dựa vào những thông tin đã cho, viết báo cáo cho nghiên cứu này nghĩa là mô tả có lý giải một cách đầy đủ về mối liên hệ giữa hàm lượng glucose và hormone, SV cần phải có một sự hiểu biết sâu sắc về các khái niệm thống kê trong phân tích hồi qui tuyến tính đơn biến, phải biết tích hợp các khái niệm và áp dụng sự thấu hiểu suy luận để kiểm chứng, lý giải các thông tin và đưa ra những nhận định có cơ sở.
Câu hỏi yêu cầu SV: Hiểu câu hỏi một cách chi tiết. Viết báo cáo cho nghiên cứu bao gồm: Đọc và giải thích trong một bối cảnh để xác định có tồn tại hay không mối liên hệ giữa glucose và yếu tố hormone, mức độ liên kết là như thế nào; Mô hình hồi qui tuyến tính đơn biến có phù hợp để mô tả mối liên hệ giữa glucose và hormone, sự thay đổi của glucose có ý nghĩa giải thích cho nồng độ hormone hay không; Hàm hồi qui mẫu là một ước lượng của hàm hồi qui tổng thể từ mẫu dữ liệu, có ý nghĩa giải thích và tiên đoán như thế nào về mối liên hệ giữa hai biến. Sau khi đánh giá mức độ phù hợp của mô hình hồi qui mẫu thông qua kết quả của thủ tục
kiểm định hệ số góc (độ dốc) và hệ số xác định R2, đưa ra được một ví dụ cụ thể
minh họa về ý nghĩa của mô hình hồi qui cho phép dự đoán giá trị của kết quả phát sinh từ một chỉ số lâm sàng cụ thể về biến glucose. Sử dụng suy luận một cách linh hoạt, thiết lập giải thích và giao tiếp có hiệu quả các kết quả của quá trình này.
Đây là câu hỏi có trả lời mở, có nhiều cách trả lời khác nhau. SV thành công là SV khai thác đầy đủ 3 thông tin đã cho: Với thông tin “R2 = 0,56”, đây là hệ số xác định của mô hình hồi qui, hệ số xác định đánh giá độ phù hợp của hàm hồi qui mẫu với tập dữ liệu, chỉ ra rằng trong 100% của toàn bộ các sai lệch của tập dữ liệu so với trung bình thì có 56% là do glucose giải thích, còn 44% là do sai số ngẫu nhiên và do các yếu tố khác (nếu có) mà ta không đưa vào trong mô hình này để xem xét. Với thông tin “test t của hệ số góc (độ dốc) có Sig. = 10-4”, cho thấy độ dốc b khác 0 là có ý nghĩa thống kê (p = 10-4 < 0,01), nghĩa là có mối liên hệ giữa glucose và hormone, mô hình hồi qui tuyến tính là phù hợp để mô tả về mối liên hệ này; Với thông tin “Hormone = –0,44.Glucose + 5,77” là hàm hồi qui mẫu, là một ước lượng của hàm hồi qui tổng thể, trong đó một ước lượng là b = – 0,44 và a = 5,77, cho thấy mối tương quan nghịch chiều giữa glucose và hormone, trong một giới hạn phù hợp của hàm lượng glucose, khi glucose tăng thêm 1 (mmol/L) thì hormone giảm 0,44 (IU/mL). Hàm hồi qui mẫu cho phép dự đoán nồng độ hormone trong máu đối với bệnh nhân có hàm lượng glucose cụ thể, chẳng hạn đối với bệnh nhân có chỉ số đường huyết là 6,5 (mmol/L) thì dự đoán nồng độ hormone trong máu là 2,91 (IU/mL). Thống kê kết quả trả lời của SV đối với câu hỏi này được thể hiện trong Bảng 5.3.
Bảng 5.3. Kết quả trả lời tương ứng câu hỏi 16 của Test 2
Số điểm | |||
0 | 0,5 | 1,0 | |
Tỉ lệ (%) (N2 = 72) | 81,9 | 16,7 | 1,4 |
Kết quả bài làm của SV cho thấy, chỉ có 1 SV thành công chiếm tỉ lệ 1,4%, hầu hết SV thất bại ở câu hỏi này, có 81,9% SV bỏ trống, hoặc có trả lời nhưng không đúng phần nào của câu hỏi, hoặc đưa ra được ví dụ về dự đoán về nồng độ hormone với bệnh nhân có chỉ số đường huyết cụ thể nhưng trước đó không giải thích được mô hình hồi qui tuyến tính là phù hợp để mô tả mối liên hệ giữa glucose và hormone. Ngoài SV đạt điểm tối đa cho câu hỏi này, còn lại hầu hết SV mới chỉ dừng lại ở mức tính toán, cho một giá trị glucose cụ thể và thay vào hàm hồi qui
mẫu để xác định nồng độ hormone; tuy nhiên không có SV nào đưa ra được kết luận và giải thích đúng dựa vào thông tin “test t của hệ số góc có Sig. = 10-4”.
5.4.1.2. Phân tích kết quả thực nghiệm đối với bài kiểm tra Test 1:
Dữ liệu thu thập được là bài làm của N1 = 103 SV ngành y khoa năm thứ nhất, học kỳ 1, năm học 2018-2019, trường ĐH Y Dược Huế đối với bài kiểm tra Test 1. Những SV này vừa học xong những kiến thức liên quan chủ đề Lý thuyết mẫu trong học phần XS-TKYH. Các em đã nắm bắt tốt các khái niệm, công thức TKYH liên quan biến ngẫu nhiên, định lý giới hạn trung tâm, tổng thể, mẫu ngẫu nhiên, lấy mẫu, các loại bảng, biểu đồ, các thống kê mẫu, một số phân phối thông dụng và phân phối lấy mẫu.
Kết quả xử lý điểm bài kiểm tra Test 1 (Phụ lục 13) cho chúng tôi xác định tỉ lệ phần trăm (%) SV đạt các mức SLTKYH, thể hiện trong Bảng 5.4 và Hình 5.3.
Bảng 5.4. Tỉ lệ (%) SV đạt các mức Suy luận thống kê y học đối với Test 1
Mức SLTKYH | Mức điểm | Tỉ lệ (%) (N1 = 103) | |
Phản ánh | 5, 6 | (7,5; 10] | 12,62 |
Liên kết | 4 | (5; 7,5] | 22,33 |
3 | (2,4; 5] | 55,34 | |
Tái tạo | 1, 2 | (0; 2,4] | 9,71 |
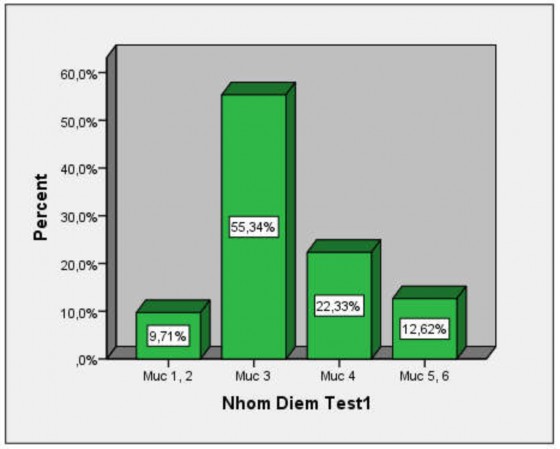
Hình 5.3. Phân bố tỉ lệ SV đạt các mức SLTKYH đối với Test 1
Bài kiểm tra Test 1 được xây dựng để đánh giá năng lực SLTKYH Mô tả của SV. Từ Bảng 5.4 và biểu đồ trong Hình 5.3 cho thấy đối với SV được khảo sát, chỉ có 9,71% SV chỉ đạt được mức năng lực thấp là mức tái tạo và 65,05% SV đạt được các mức 1, 2, 3. SV chủ yếu đạt năng lực ở các mức 3, 4 (liên kết) là 77,67%, các mức cao 5, 6 (phản ánh) vẫn còn thấp, chỉ có 12,62%.
Phân tích những trả lời của SV đối với từng câu hỏi, chúng tôi nhận thấy đa phần SV có câu trả lời tốt đối với những câu hỏi ở mức tái tạo, đối với 6 câu hỏi NLC ở mức tái tạo (Câu 1, 3, 6, 7, 9,10) trong Test 1, thống kê được tỉ lệ (%) SV trả lời đúng với mỗi câu hỏi ở mức này đều đạt từ 85% trở lên. Tuy nhiên, đối với 2 câu hỏi ở mức phản ánh (Câu 13, 15), tỉ lệ SV đạt điểm tối đa không vượt quá 11%. Tỉ lệ (%) SV trả lời đúng đối với mỗi câu hỏi ở mức tái tạo và phản ánh của Test 1 thể hiện trong Bảng 5.5.
Bảng 5.5. Tỉ lệ (%) SV trả lời đúng câu hỏi mức tái tạo, phản ánh của Test 1
Loại câu hỏi | Mức SLTKYH | Tỉ lệ (%) (N1 = 103) | |
1 | NLC | Tái tạo | 86,4 |
3 | NLC | Tái tạo | 86,4 |
6 | NLC | Tái tạo | 89,3 |
7 | NLC | Tái tạo | 88,3 |
9 | NLC | Tái tạo | 87,4 |
13 | TL đóng | Phản ánh | 9,7 |
15 | TL mở | Phản ánh | 10,7 |
Sau đây, chúng tôi trình bày một số ví dụ về việc phân tích đánh giá thể hiện năng lực SLTKYH qua trả lời của SV đối với từng câu hỏi, bao gồm 3 câu hỏi thuộc ba cụm năng lực tái tạo, liên kết, phản ánh trong Test 1 là câu hỏi 1, 14, 15.
Ví dụ 5.3. Xem xét trả lời của SV đối với câu hỏi 1 của bài kiểm tra Test 1. Mô tả theo vấn đề thì đây là câu hỏi 1 của vấn đề hàm lượng Glucose.
VẤN ĐỀ: Hàm lượng Glucose
Nghiên cứu về hàm lượng glucose máu của người bình thường khỏe mạnh. Kết quả xét nghiệm glucose (mg%) của 100 người bình thường khỏe mạnh thu thập được lưu trong file Glucose.sav. Xử lý số liệu bằng phần mềm SPSS, thu được một số kết quả như sau:
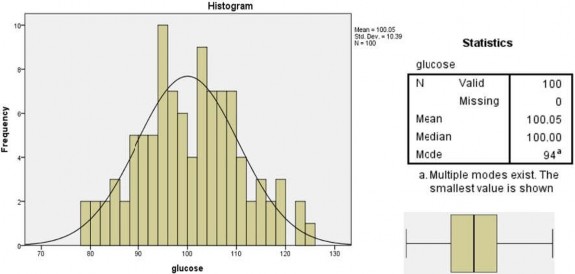
Câu hỏi 1. (M2) Hàm lượng Glucose
Phát biểu nào sau đây là phù hợp nhất khi mô tả về dữ liệu trên:
A. Phân phối hàm lượng Glucose mẫu lệch phải, trung bình mẫu là 100,05 và độ lệch chuẩn mẫu là 10,39.
B. Phân phối hàm lượng Glucose mẫu lệch trái, trung bình mẫu là 100,05 và độ lệch chuẩn mẫu là 10,39.
C. Phân phối hàm lượng Glucose mẫu xấp xỉ chuẩn, trung bình mẫu là 100,05 và độ lệch chuẩn mẫu là 10,39.
D. Phân phối hàm lượng Glucose mẫu xấp xỉ chuẩn, trung bình mẫu là 100,05 và phương sai mẫu là 10,39.
Hãy đưa ra lời giải thích hỗ trợ cho câu trả lời của bạn?
Phân tích.
Loại câu hỏi: NLC (có yêu cầu giải thích). Nội dung TKYH: Mô tả phân phối mẫu. Năng lực SLTKYH: Mô tả.
Bối cảnh lâm sàng: Câu hỏi xây dựng trên bối cảnh nghiên cứu mô tả chỉ số glucose (mg%) qua xét nghiệm glucose máu. Glucose máu là một chỉ số quan trọng giúp bác sĩ đánh giá khả năng kiểm soát đường huyết của cơ thể bệnh nhân, nhờ đó có thể xác định bệnh nhân có mắc các bệnh lý liên quan tới đường huyết hay không, cùng với đó còn có thể đánh giá xem bệnh nhân mắc bệnh tiểu đường có đáp ứng được với các phương pháp điều trị đang áp dụng hay không.
Cụm năng lực: Tái tạo – Mức 2. Câu hỏi trên được đưa ra nhằm đánh giá năng lực SLTKYH Mô tả của SV liên quan đến mô tả phân phối mẫu dựa vào đặc điểm đồ thị, biểu đồ và các số đo lường thống kê. Câu hỏi này phù hợp với mức độ 2 trong thang đánh giá SLTKYH chúng tôi đưa ra ở Bảng 2.8 và Bảng 4.2. Câu hỏi chủ yếu liên quan đến sự tái tạo của kiến thức đã học, ở đó việc lý giải và nhận ra các tình huống trong bối cảnh không đòi hỏi nhiều hơn suy luận trực tiếp. SV cần giải quyết vấn đề bằng cách giải mã các kí hiệu thống kê quen thuộc "mean", "median", "Std.Dev." và giải thích đặc điểm phân phối mẫu thông qua biểu đồ tổ chức Histogram với đường cong chuẩn, biểu đồ hộp, đây đều là những biểu diễn tiêu chuẩn, quen thuộc cho một biến của dữ liệu định lượng.