Văn bản tóm tắt
A total of 47 bodies have been exhumed from two mass graves. Iraqis find mass graves inside presidential palace compound in Tikrit . ISIS claimed to have executed 1,700 Iraqi soldiers captured outside Camp Speicher .
Bảng 1.1. Ví dụ minh họa một văn bản tóm tắt của văn bản tiếng Anh
Văn bản tóm tắt
Sau khi khảo sát, bà Nguyễn Thị Láng – Trưởng ban Tuyên giáo Liên đoàn lao động tỉnh – đã cùng các Cán bộ công đoàn làm việc với chính quyền địa phương và tổ chức hội nghị đối thoại với sự có mặt của cả đại diện doanh nghiệp và công nhân lao động. Công ty TNHH may Tinh Lợi, có gần 1.000 nữ công nhân lao động đang ở trọ tại đây đã đồng ý mỗi tháng tài trợ thêm cho Trường Mầm non Hương Sen 3 triệu đồng để nâng cấp, mở thêm phòng học, tiếp nhận hơn 200 cháu là con công nhân lao động vào học.
Bảng 1.2. Ví dụ minh họa một văn bản tóm tắt của văn bản tiếng Việt
1.1.2. Phân loại bài toán tóm tắt văn bản
Có thể bạn quan tâm!
-

 Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 1
Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 1 -
 Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 2
Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 2 -
 Ý Nghĩa Khoa Học Và Ý Nghĩa Thực Tiễn
Ý Nghĩa Khoa Học Và Ý Nghĩa Thực Tiễn -
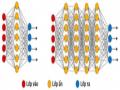 Các Phương Pháp Tóm Tắt Văn Bản Hướng Trích Rút Cơ Sở
Các Phương Pháp Tóm Tắt Văn Bản Hướng Trích Rút Cơ Sở -
![Một Kiến Trúc Cnn Cho Bài Toán Phân Loại Ảnh [84]](https://tailieuthamkhao.com/uploads/2022/06/10/nghien-cuu-phat-trien-mot-so-phuong-phap-tom-tat-van-ban-su-dung-ky-6-1-120x90.jpg) Một Kiến Trúc Cnn Cho Bài Toán Phân Loại Ảnh [84]
Một Kiến Trúc Cnn Cho Bài Toán Phân Loại Ảnh [84] -
 Các Mô Hình Ngôn Ngữ Dựa Trên Học Sâu Được Huấn Luyện Trước
Các Mô Hình Ngôn Ngữ Dựa Trên Học Sâu Được Huấn Luyện Trước
Xem toàn bộ 185 trang tài liệu này.
Bài toán tóm tắt văn bản được phân loại dựa theo các tiêu chí khác nhau bao gồm một số loại bài toán phổ biến sau:

- Tóm tắt đơn văn bản: Văn bản nguồn chỉ có một văn bản duy nhất.
- Tóm tắt đa văn bản: Tập văn bản nguồn gồm nhiều văn bản (các văn bản này thường có nội dung liên quan đến nhau). Văn bản kết quả thu được là một văn bản duy nhất từ tập văn bản nguồn đầu vào. Tóm tắt đa văn bản gặp một số khó khăn như vấn đề trùng lặp thông tin giữa các văn bản nguồn, tiền xử lý văn bản phức tạp, yêu cầu tỉ lệ nén cao.
- Tóm tắt văn bản hướng trích rút: Là quá trình rút gọn văn bản sao cho văn bản kết quả có chứa các đơn vị ngữ liệu nằm trong văn bản nguồn.
- Tóm tắt văn bản hướng tóm lược: Là quá trình rút gọn văn bản sao cho văn bản kết quả có chứa một số đơn vị ngữ liệu mới được sinh ra từ các đơn vị ngữ liệu nằm trong văn bản nguồn hoặc không nằm trong văn bản nguồn. Từ các thông tin này, thực hiện các phép biến đổi để tạo ra một văn bản mới sao cho vẫn đảm bảo giữ được nội dung, ý nghĩa của văn bản nguồn đầu vào. Tóm tắt văn bản hướng tóm lược là bài toán tóm tắt văn bản phức tạp, có nhiều khó khăn trong việc biểu diễn ngữ nghĩa, sinh ngôn ngữ tự nhiên từ văn bản nguồn.
- Tóm tắt đơn ngôn ngữ: Văn bản nguồn và văn bản tóm tắt chỉ có duy nhất một loại ngôn ngữ.
- Tóm tắt đa ngôn ngữ: Văn bản nguồn chỉ chứa duy nhất một loại ngôn ngữ, nhưng văn bản kết quả có thể được tóm tắt theo nhiều ngôn ngữ khác nhau.
- Tóm tắt đan xen ngôn ngữ: Văn bản nguồn có thể gồm nhiều loại ngôn ngữ khác nhau.
Trong các loại tóm tắt văn bản này, tóm tắt hướng trích rút tạo ra văn bản tóm tắt dựa trên trích rút gọn câu mang lại hiệu quả cao về mặt ngôn ngữ, trong khi đó tóm tắt hướng tóm lược sinh ra một văn bản tóm tắt đảm bảo về mặt cú pháp, ngữ
nghĩa bằng việc rút gọn câu [58,59,60]. Các phương pháp tóm tắt văn bản được đề xuất hiện nay thường là tóm tắt theo hướng trích rút vì nó dễ dàng thực hiện hơn so với việc rút gọn câu của tóm tắt hướng tóm lược. Tuy nhiên, sử dụng cách tiếp cận tóm tắt văn bản hướng tóm lược thường cho các văn bản tóm tắt với thông tin ít mạch lạc hơn. Bên cạnh đó, tóm tắt đơn văn bản cũng được thực hiện dễ dàng hơn, văn bản tạo ra có thông tin ít bị trùng lặp so với tóm tắt đa văn bản. Chính vì thế, các loại bài toán tóm tắt đơn văn bản, tóm tắt đa văn bản, tóm tắt văn bản hướng trích rút và tóm tắt văn bản hướng tóm lược giành được sự quan tâm phát triển của các nhà nghiên cứu trong lĩnh vực xử lý ngôn ngữ tự nhiên nói chung và tóm tắt văn bản nói riêng [61].
1.1.3. Các bước thực hiện trong tóm tắt văn bản
Với văn bản nguồn đầu vào, để sinh ra bản tóm tắt thì một hệ thống TTVB cần thực hiện các bước chính được biểu diễn như trong Hình 1.1 dưới đây.

Hình 1.1. Các bước thực hiện trong tóm tắt văn bản
Phân tích: Một văn bản hoặc tập các văn bản nguồn được phân tích để trả ra các thông tin sử dụng cho việc tìm kiếm, đánh giá các đơn vị ngữ liệu quan trọng và các tham số đầu vào cho bước tiếp theo.
Biến đổi: Bước này sử dụng một phép biến đổi tác động trên các thông tin đầu ra của bước phân tích nhằm đơn giản hóa và tạo nên một thể thống nhất. Kết quả trả ra là các đơn vị ngữ liệu được tóm tắt.
Sinh văn bản tóm tắt: Bước này sẽ liên kết các đơn vị ngữ liệu nhận được từ bước biến đổi theo một tiêu chí nào đó để sinh văn bản tóm tắt.
Với mỗi loại hệ thống TTVB sẽ có sự khác nhau nhất định. Đối với các hệ thống TTVB hướng tóm lược thì có đầy đủ các bước trên, nhưng đối với hệ thống TTVB hướng trích rút thì không có bước biến đổi mà chỉ có hai bước phân tích và sinh văn bản tóm tắt.
1.1.4. Một số đặc trưng của văn bản
Vị trí câu: Độ quan trọng của câu trong văn bản dựa theo đặc trưng vị trí được xác định là giá trị vị trí của câu trong văn bản. Nhiều phương pháp thường coi câu đầu tiên trong văn bản là câu quan trọng hơn các câu khác trong văn bản [62,63].
TF-IDF: TF-IDF (Term Frequency - Inverse Document Frequency) là trọng số của một từ thể hiện mức độ quan trọng của từ đó trong một văn bản mà văn bản đó nằm trong một tập hợp các văn bản [64]. Trọng số TF-IDF được tính theo các đặc trưng tần suất xuất hiện của từ (TF) và nghịch đảo tần suất xuất hiện của từ trong một văn bản của một tập các văn bản (IDF) như sau:
- TF = Số lần xuất hiện của từ trong văn bản/Tổng số từ trong văn bản.
- IDF = log(Tổng số văn bản trong tập văn bản/Số văn bản có chứa từ đó).
- TF-IDF = TF*IDF.
Câu trung tâm: Độ quan trọng của câu trong văn bản dựa theo đặc trưng câu trung tâm được tính bằng giá trị trung bình của độ tương tự giữa một câu và các câu khác trong văn bản. Đặc trưng này xem xét sự cùng xuất hiện của các từ giữa một câu và các câu khác trong văn bản [65].
1.2. Một số phương pháp đánh giá văn bản tóm tắt tự động
Với bài toán tóm tắt văn bản, hiệu quả của văn bản tóm tắt có vai trò quan trọng. Để đánh giá hiệu quả của các văn bản tóm tắt, cần phải dựa vào các tham số như tỷ lệ nén, độ chính xác, độ liên kết,…Có một số phương pháp đánh giá hiệu quả văn bản tóm tắt được trình bày dưới đây.
1.2.1. Phương pháp dựa trên độ tương tự về nội dung
Đánh giá độ tương tự về nội dung của văn bản kết quả được sinh ra bởi hệ thống TTVB đang xét so với các văn bản kết quả tương ứng được sinh ra bởi các phương pháp khác. Giả sử, văn bản kết quả của ứng dụng đang xét là S, văn bản kết quả tóm tắt tương ứng của n phương pháp đánh giá khác là: J1, J2,…,Jn (với cùng văn bản nguồn ban đầu) thì công thức tính toán độ tương tự là:
sim(M , S,{J , J
, J }) M (S, J1 ) M (S, J2 ) M (S, J3 )
(1.1)
trong đó:
1 2 3 3
- M là tiêu chí tính toán độ tương tự về nội dung giữa 2 văn bản X và Y, M
( ) ( )
x
2
y
2
i
i
i
thường được tính toán theo công thức sau [66]:
cos( X ,Y )
xiy
(1.2)
với: X, Y là hai văn bản được biểu diễn dưới dạng véc tơ tương ứng.
- Hoặc M có thể được tính toán theo cách khác bởi công thức [67]:
LCS( X ,Y ) length( X ) length(Y ) d ( X ,Y )
2
(1.3)
với:
+ X, Y là hai văn bản được biểu diễn dưới dạng chuỗi các từ tương ứng.
+ d(X,Y) là số lượng phép toán thêm mới và xóa ít nhất cần thực hiện để biến
đổi văn bản X thành văn bản Y.
+ LCS(X,Y) là độ dài của chuỗi con chung lớn nhất giữa X và Y.
+ length(X), length(Y) tương ứng là độ dài của 2 văn bản X, Y.
1.2.2. Phương pháp dựa trên độ tương quan phù hợp
Phương pháp dựa trên độ tương quan phù hợp đánh giá hệ thống TTVB dựa trên các câu truy vấn: Với một truy vấn Q và một tập văn bản {Di} và một công cụ để sắp xếp các văn bản Di theo thứ tự mức độ phù hợp giữa Di với Q theo chiều giảm dần thì từ tập {Di}, ta có tập {Si} là tập văn bản tóm tắt của {Di} được tạo ra bởi hệ thống đang xét, ta sử dụng công cụ sắp xếp ở trên để sắp xếp {Si} giống như
trên. Để đánh giá, cần xác định độ tương quan giữa hai danh sách đã được sắp xếp này.
Công thức xác định độ tương quan phổ biến là độ tương quan tuyến tính giữa hai tập điểm phù hợp x và y:
i
( x )
x
2
i
i
( y )
y
2
i
i
r
i( xix ) ( yy )
(1.4)
trong đó: x và y là giá trị trung bình của từng tập điểm phù hợp tương ứng đối với tập văn bản Di.
1.2.3. Phương pháp ROUGE
Đánh giá kết quả tóm tắt văn bản là một nhiệm vụ khó khăn ở thời điểm hiện nay vì việc sử dụng ý kiến đánh giá của các chuyên gia ngôn ngữ được xem là cách đánh giá tốt nhất nhưng tốn kém nhiều chi phí. Do đó, giải pháp đánh giá tự động được xem như giải pháp tối ưu để đánh giá chất lượng của các bản tóm tắt do các hệ thống tóm tắt văn bản sinh ra. Giải pháp đánh giá tự động phải tìm ra một độ đo gần với đánh giá của con người nhất để đánh giá văn bản tóm tắt và ROUGE (Recall- Oriented Understudy for Gisting Evaluation) [68] là một độ đo đánh giá tự động hiệu quả được sử dụng phổ biến hiện nay.
1.2.3.1. Độ đo ROUGE
Độ đo ROUGE được sử dụng như một độ đo tiêu chuẩn để đánh giá hiệu quả của các hệ thống tóm tắt văn bản. ROUGE thực hiện so sánh một bản tóm tắt được sinh tự động từ mô hình tóm tắt và một tập các bản tóm tắt tham chiếu (bản tóm tắt tự nhiên của con người). Vì vậy, để có được một đánh giá tốt, việc tính toán độ hồi tưởng (Recall) và độ chính xác (Precision) [69,70] thông qua các từ trùng lặp được sử dụng trong độ đo ROUGE.
Độ hồi tưởng: Thể hiện bản tóm tắt hệ thống nắm bắt lại được bao nhiêu phần của bản tóm tắt tham chiếu, được tính toán theo công thức:
R c
a
(1.5)
trong đó: c là số lượng từ bản tóm tắt hệ thống nắm bắt lại, a là tổng số từ trong bản tóm tắt tham chiếu.
Nếu tất cả các từ trong bản tóm tắt tham chiếu đã được tóm tắt lại bởi hệ thống thì cũng chưa thể khẳng định được bản tóm tắt hệ thống là chất lượng thực sự vì một bản tóm tắt được sinh ra từ hệ thống có thể rất dài và chứa tất cả số từ có trong bản tóm tắt tham chiếu nhưng phần lớn các từ còn lại trong bản tóm tắt hệ thống lại dư thừa, điều này làm cho bản tóm tắt dài dòng. Chính vì thế, độ chính xác được sử dụng để khắc phục vấn đề này.
Độ chính xác: Thể hiện bản tóm tắt hệ thống trong thực tế có bao nhiêu phần liên quan đến bản tóm tắt tham chiếu, được tính theo công thức:
P c
b
(1.6)
trong đó: c là số lượng từ bản tóm tắt hệ thống nắm bắt lại liên quan đến bản tóm tắt tham chiếu, b là tổng số từ trong bản tóm tắt hệ thống.
Một độ đo thường được sử dụng là độ đo F1 ( F1 score ) [70]. Độ đo F1 được tính toán dựa trên độ hồi tưởng R và độ chính xác P theo công thức:
F1 2 R * P
R P
(1.7)
Độ đo F1 thể hiện chất lượng bản tóm tắt của hệ thống tóm tắt văn bản khách quan hơn vì nó có xu hướng gần với giá trị nhỏ hơn giữa hai giá trị độ hồi tưởng và độ chính xác, giá trị F1 lớn nếu cả hai giá trị độ hồi tưởng và độ chính xác lớn.
1.2.3.2. Các độ đo ROUGE phổ biến
Các độ đo ROUGE [68] phổ biến thường được sử dụng để đánh giá chất lượng của bản tóm tắt hệ thống so với bản tóm tắt tham chiếu trong bài toán tóm tắt văn bản gồm:
Độ hồi tưởng của Rouge – N (ký hiệu RN): Thể hiện việc sử dụng một từ (uni- gram), hai từ (bi-gram), ba từ (tri-gram) hoặc N từ (N-gram) xuất hiện đồng thời trong bản tóm tắt hệ thống và bản tóm tắt tham chiếu. Độ hồi tưởng RN (thường N = 1 ÷ 4) được tính theo công thức:
SRS gram S Countmatch (gramN)
RN
SRS
N
gramN S
Count(gramN )
(1.8)
trong đó:
+ N: là N-gram (với N =1, 2, 3,...).
+ RS: là tập văn bản tóm tắt tham chiếu.
+ Countmatch(gramN): là số lượng N-gram xuất hiện đồng thời trong bản tóm tắt hệ thống và bản tóm tắt tham chiếu.
+ Count(gramN): là số lượng N-gram có trong bản tóm tắt tham chiếu.
Độ chính xác của Rouge – N (ký hiệu PN): Thể hiện việc sử dụng một từ (uni- gram), hai từ (bi-gram), ba từ (tri-gram) hoặc N từ (N-gram) xuất hiện trong bản tóm tắt hệ thống có liên quan đến bản tóm tắt tham chiếu. Độ hồi tưởng PN (thường N = 1 ÷ 4) được tính theo công thức:
SRS gram S Countmatch (gramN)
PN
N
gramNSS
Count(gramN )
(1.9)
với: SS: là văn bản tóm tắt hệ thống.
Độ đo F1 của Rouge – N (ký hiệu R–N): Độ đo R–N (thường N = 1 ÷ 4) được tính toán dựa trên độ hồi tưởng RN và độ chính xác PN theo công thức:
R N 2 RN * PN
RN PN
(1.10)
Trong công thức (1.10), khi N = 1 ta có độ đo R-1, N = 2 ta có độ đo R-2 là các độ đo thường được sử dụng để đánh giá hiệu quả của các mô hình tóm tắt văn bản.
Độ đo F1 của Rouge – L (ký hiệu R–L): Thể hiện việc sử dụng chuỗi các từ dài nhất xuất hiện đồng thời trong bản tóm tắt của hệ thống và bản tóm tắt tham chiếu dựa trên chuỗi con chung dài nhất (LCS - Longest Common Subsequence). LCS chính là bài toán tìm kiếm chuỗi con chung dài nhất cho tất cả các chuỗi trong
một tập các chuỗi (thường là hai chuỗi). Độ đo R-L được tính dựa trên độ hồi tưởng
u
Rlcs và độ chính xác Plcs như sau:
LCS(ri ,C)
Rlcs
Plcs
i1
m
u
LCS(ri ,C)
i1
n
(1.11)
(1.12)
(12 )R * P
P
R L lcs lcs
(1.13)
2
Rlcs lcs
trong đó: C là tập tóm tắt ứng viên; ri là câu xét trong bản tóm tắt tham chiếu; u là số lượng câu của bản tóm tắt tham chiếu; m là số lượng từ của tập tóm tắt tham
chiếu; n là số lượng từ của tập tóm tắt ứng viên C;
LCS(ri ,C)
là điểm của tập
được xác định bằng hợp của tập chuỗi con chung dài nhất giữa câu ri và mọi câu trong tập C, điểm này được tính bằng tổng độ dài của hợp các chuỗi con chung lớn nhất chia cho độ dài của ri; là hệ số điều khiển độ quan trọng tương đối của Rlcs và Plcs ( là tham số thường được chọn bằng 1).
Trong công thức (1.13), khi
1
ta có một độ đo thường được sử dụng để
đánh giá chất lượng của bản tóm tắt và được tính theo công thức:
R L 2 Rlcs * Plcs
Rlcs Plcs
(1.14)
Độ đo F1 của Rouge-S (ký hiệu R-S): Độ đo R-S xác định độ tương đồng giữa cặp từ bất kỳ trong một câu được ghép theo đúng thứ tự. Độ đo R-S được tính dựa trên độ hồi tưởng RS và độ chính xác PS như sau:
R SKIP2 ( X ,Y )
S C(m, 2)
P SKIP2 ( X ,Y )
S C(n, 2)
(12 )R * P
(1.15)
(1.16)
R S S S
(1.17)
R 2 P
S S
trong đó: m là số lượng từ của bản tóm tắt tham chiếu; n là số lượng từ của tập tóm
tắt ứng viên C; X là tập tóm tắt tham chiếu; Y là tập tóm tắt ứng viên;
SKIP2 ( X ,Y )
là số lượng từ ghép cặp skip bi-gram trùng khớp giữa X và Y; C(m,2), C(n,2) tương ứng là các hàm tổ hợp chập 2 của m phần tử, hàm tổ hợp chập 2 của n phần tử; là hệ số điều khiển độ quan trọng tương đối của RS và PS ( là tham số tự chọn và thường được chọn bằng 1).
Trong công thức (1.17), khi
R S 2 RS * PS
RS PS
1 ta có công thức tính độ đo như sau:
(1.18)
Độ đo F1 của Rouge-St (ký hiệu R-St): Khi sử dụng độ đo R-S có thể xuất hiện một số các cặp từ vô nghĩa như “the the”, “is is”,..v...v.... Để giảm thiểu các cặp từ
vô nghĩa này, ta có thể giới hạn khoảng cách có thể tạo thành cặp từ là t (trong t- skip bi-gram), nghĩa là chỉ có các từ cách nhau không quá t từ mới có thể tạo thành cặp từ hợp lệ (do các cặp từ vô nghĩa thường không nằm gần nhau nên khi chọn t nhỏ sẽ hạn chế được tình trạng tạo các cặp từ vô nghĩa). Khi đó, độ đo R-St được tính dựa trên độ hồi tưởng RSt và độ chính xác PSt như sau:
R SKIP2,t ( X ,Y )
(1.19)
St t
(m i 1)
i0
P SKIP2,t ( X ,Y )
(1.20)
St t
(n i 1)
i0
(12 )R * P
R St St St
(1.21)
R 2 P
St St
trong đó: m là số lượng từ của bản tóm tắt tham chiếu; n là số lượng từ của tập tóm
tắt ứng viên C; X là tập tóm tắt tham chiếu; Y là tập tóm tắt ứng viên;
SKIP2,t ( X ,Y )
là số lượng từ ghép cặp skip bi-gram trùng khớp giữa X và Y; là hệ số điều khiển
độ quan trọng tương đối của bằng 1).
RSt và
PSt
( là tham số tự chọn và thường được chọn
Trong công thức (1.21), khi
R St 2 RSt * PSt
RSt PSt
1 ta có độ đo được tính theo công thức:
(1.22)
Trong công thức (1.22), khi t = 4 ta có độ đo R-S4 là độ đo thường được sử dụng để đánh giá hiệu quả của các mô hình tóm tắt văn bản.
Độ đo F1 của Rouge-SUt (ký hiệu R-SUt): Là độ đo mở rộng của độ đo R-St bằng việc thêm một từ (uni-gram) làm đơn vị đếm để khắc phục trường hợp một câu ứng cử viên không có cặp từ đồng xuất hiện nào với bản tóm tắt tham chiếu. Độ đo R-SUt thu được từ R-St bằng cách thêm điểm đánh dấu đầu câu vào đầu các câu ứng viên và các câu tóm tắt tham chiếu. Khi t = 4 ta có độ đo R-SU4 thu được từ độ đo R-S4 là độ đo thường được sử dụng để đánh giá hiệu quả của các mô hình tóm tắt văn bản.
Hiện nay, các độ đo ROUGE được sử dụng như một độ đo tiêu chuẩn phổ biến để đánh giá hiệu quả của các mô hình tóm tắt văn bản. Do đó, luận án sẽ sử dụng các độ đo R-1, R-2, R-L, R-S4 và R-SU4 để đánh giá hiệu quả của các mô hình tóm tắt văn bản đề xuất.
1.3. Các phương pháp kết hợp văn bản trong tóm tắt đa văn bản
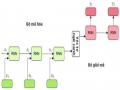
Đối với bài toán tóm tắt đa văn bản, vấn đề đặt ra đầu tiên là việc kết hợp các văn bản trong tập văn bản nguồn này như thế nào?
Hình 1.2. Phương pháp xử lý tóm tắt từng đơn văn bản trong tóm tắt đa văn bản
Hiện nay có hai phương pháp thường được sử dụng để giải quyết vấn đề này là:
- Phương pháp thứ nhất: Kết hợp tất cả các văn bản đầu vào thành một văn bản duy nhất gọi là siêu văn bản, rồi thực hiện tóm tắt đối với siêu văn bản này để sinh ra bản tóm tắt cuối cùng. Phương pháp này đưa bài toán tóm tắt đa văn bản trở thành bài toán tóm tắt đơn văn bản và có thể sử dụng các kỹ thuật tóm tắt đơn văn bản để sinh ra bản tóm tắt cuối cùng.
- Phương pháp thứ hai: Trước hết, từng văn bản của tập đa văn bản được tóm tắt để sinh ra văn bản tóm tắt tương ứng. Sau đó, các văn bản tóm tắt này sẽ được kết hợp lại thành một văn bản tóm tắt tổng hợp. Sau đó, văn bản tóm tắt tổng hợp này sẽ được xử lý tóm tắt bằng các kỹ thuật tóm tắt đơn văn bản để sinh ra văn bản tóm tắt cuối cùng, đây cũng chính là bản tóm tắt kết quả của tập đa văn bản nguồn cần tóm tắt. Hình 1.2 biểu diễn ý tưởng của phương pháp xử lý tóm tắt từng đơn văn bản trong tóm tắt đa văn bản.
Phương pháp tiếp cận thứ nhất dễ nắm bắt được các thông tin mới lạ hơn so với phương pháp tiếp cận thứ hai. Phương pháp tiếp cận thứ hai thực hiện tóm tắt từng văn bản trước làm cho độ dài văn bản đầu vào của mô hình tóm tắt đa văn bản giảm nên bản tóm tắt cuối cùng sẽ có độ chính xác cao.