RRHHD | 256 | 0.24 | 0.43 | 0.00 | 1.00 | |
27 | RRLDB | 256 | 0.09 | 0.29 | 0.00 | 1.00 |
28 | RRLDTN | 256 | 0.05 | 0.22 | 0.00 | 1.00 |
29 | RRLDC | 256 | 0.04 | 0.18 | 0.00 | 1.00 |
Nhóm h nông dân Không sẵn lòng tham gia b o hi m cây cà phê theo chỉ số ă suất | ||||||
1 | TUOI | 224 | 43.72 | 8.09 | 25.00 | 62.00 |
2 | GIOITINH | 224 | 0.96 | 0.19 | 0.00 | 1.00 |
3 | DANTOC | 224 | 0.47 | 0.50 | 0.00 | 1.00 |
4 | TDHV | 224 | 6.93 | 2.62 | 1.0 | 12.00 |
5 | KINHNGHIEM | 224 | 17.05 | 6.35 | 3.00 | 40.00 |
6 | HOIND | 224 | 0.97 | 0.17 | 0.00 | 1.00 |
7 | LAODONG | 224 | 2.67 | 0.98 | 1.00 | 6.00 |
8 | DIENTICH | 224 | 1.27 | 1.18 | 0.1 | 14.00 |
9 | TUOICAY | 224 | 13.67 | 1.89 | 11.00 | 18.00 |
10 | NANGSUAT | 224 | 26.77 | 5.96 | 16.0 | 45.00 |
11 | THUNHAP | 224 | 42.62 | 8.92 | 16.8 | 58.71 |
12 | SOHUUDAT | 224 | 0.81 | 0.39 | 0.00 | 1.00 |
13 | VAYVON | 224 | 0.04 | 0.19 | 0.00 | 1.00 |
14 | TIEUCHUAN | 224 | 0.01 | 0.12 | 0.00 | 1.00 |
15 | THITRUONG | 224 | 0.01 | 0.12 | 0.00 | 1.00 |
16 | THUONGHIEU | 224 | 0.55 | 0.50 | 0.00 | 1.00 |
17 | RRHH | 224 | 0.92 | 0.27 | 0.00 | 1.00 |
18 | RRMTT | 224 | 0.84 | 0.36 | 0.00 | 1.00 |
19 | RRB | 224 | 0.54 | 0.50 | 0.00 | 1.00 |
20 | RRLL | 224 | 0.18 | 0.39 | 0.00 | 1.00 |
21 | RRCT | 224 | 0.79 | 0.41 | 0.00 | 1.00 |
22 | RRSB | 224 | 0.79 | 0.40 | 0.00 | 1.00 |
23 | RRON | 224 | 0.25 | 0.43 | 0.00 | 1.00 |
Có thể bạn quan tâm!
-

 Tổng Hợp Các Yếu Tố Sẽ Mã Hóa Được Đề Xuất
Tổng Hợp Các Yếu Tố Sẽ Mã Hóa Được Đề Xuất -
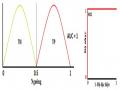 Diện Tích Dưới Đường C Ng Đ C Trưng H Ạt Động Của Bộ Thu Nhận
Diện Tích Dưới Đường C Ng Đ C Trưng H Ạt Động Của Bộ Thu Nhận -
 Th C Trạng Sản Uất C Hê Trên Địa Bàn Tỉnh Đắk Lắk
Th C Trạng Sản Uất C Hê Trên Địa Bàn Tỉnh Đắk Lắk -
 Ết Quả Ước Ượng Tha Số V D Đ N Với Ô Hình Bmal2
Ết Quả Ước Ượng Tha Số V D Đ N Với Ô Hình Bmal2 -
 Ết Quả Ước Ượng Tha Số V D Đ N Với Ô Hình Bmal3_Split
Ết Quả Ước Ượng Tha Số V D Đ N Với Ô Hình Bmal3_Split -
 So Sánh Mô Hình Hồi Quy Logistic Tần Số Và Hồi Quy Logistic Bayesian
So Sánh Mô Hình Hồi Quy Logistic Tần Số Và Hồi Quy Logistic Bayesian
Xem toàn bộ 251 trang tài liệu này.

RRMG | 224 | 0.99 | 0.12 | 0.00 | 1.00 | |
25 | RRNVL | 224 | 0.86 | 0.35 | 0.00 | 1.00 |
26 | RRHHD | 224 | 0.20 | 0.40 | 0.00 | 1.00 |
27 | RRLDB | 224 | 0.14 | 0.35 | 0.00 | 1.00 |
28 | RRLDTN | 224 | 0.05 | 0.22 | 0.00 | 1.00 |
29 | RRLDC | 224 | 0.05 | 0.22 | 0.00 | 1.00 |
Ngu n: Kết qu tính toán của tác gi
4.3.2. Chọn l a mô hình hộ nông dân sẵn lòng tham gia bảo hiểm cây cà phê theo chỉ số năng suất bằng hư ng h BMA
Với 29 biến độc lập, chúng ta có một tập hợp gồm 229 = 536,870,912 (Năm trăm ba mươi sáu triệu tám trăm bảy mươi ngàn chín trăm mười hai) mô hình nghiên cứu (Raftery, 1995). Theo cách làm thủ công, để xem xét mô hình một cách đầy đủ nhất thì ước lượng 536,870.912 mô hình rồi so sánh kết quả của chúng với nhau là việc tốn rất nhiều thời gian, công sức và có thể nói là không khả thi. Tuy nhiên, phương pháp BMA sẽ giúp chúng ta thực hiện tốt điều này.
Tiêu chí lựa chọn mô hình phù hợp nhất của phương pháp BMA là so sánh xác suất hậu định và chỉ số BIC của m i mô hình, mô hình nào có xác suất hậu định cao nhất và chỉ số BIC thấp nhất là tốt nhất (phù hợp nhất với dữ liệu). Thuật toán Occam‟s Window sẽ rút gọn số mô hình lại như sau. Trước tiên, những mô hình có xác suất hậu định rất bé so với mô hình các xác suất hậu định lớn nhất sẽ bị loại bỏ; tiếp theo, những mô hình có nhiều biến độc lập hơn những mô hình khác nhưng xác suất hậu định lại nhỏ hơn thì những mô hình đó bị thuật toán loại bỏ. Tác giả sử dụng gói ứng dụng BMA trong phần mềm R để tìm kiếm nhanh chóng tập hợp các mô hình nói trên. Vì biến phụ thuộc BAOHIEM là biến nhị phân nên tác giả sử dụng phương pháp BMA cho mô hình nghiên cứu theo hồi quy logistic và hồi quy probit. Kết quả tác giả thu được là mô hình được lựa chọn bằng phương pháp BMA theo hồi quy logistic là tập hợp gồm 82 mô hình (xem Phụ lục 7.47) và theo hồi quy probit là tập hợp hợp gồm 84 mô hình (xem Phụ lục 7.48). Các mô hình được sắp
xếp theo giá trị xác suất hậu định từ cao nhất đến thấp dần, đồng thời chỉ số BIC của các mô hình được sắp xếp theo thứ tự từ thấp nhất đến cao dần.
S s nh hư ng h BMA dụng cho mô hình hồi quy logistic và mô hình hồi quy probit
Từ kết quả trên, tác giả nhận thấy 2 tập hợp các mô hình nghiên cứu bằng phương pháp BMA theo hồi quy logistic và hồi quy probit có số lượng mô hình gần như tương đương nhau. Vì số lượng mô hình do phương pháp BMA chọn lựa theo 2 cách khá lớn và các mô hình đó gần như giống nhau (xem Phụ lục 7.47 và Phụ lục 7.48); do đó, tác giả không so sánh tất cả các mô hình do phương pháp BMA chọn theo 2 cách mà tác giả xin phép lấy 6 mô hình phù hợp với dữ liệu nhất theo m i cách để so sánh. Đó là 6 mô hình có xác suất hậu định cao nhất và chỉ số BIC thấp nhất được phương pháp BMA chọn theo hồi quy logistic; chúng được ký hiệu là BMAL1, BMAL2, BMAL3, BMAL4, BMAL5, BMAL6 (xem Bảng 4.4); và 6 mô
hình có xác suất hậu định cao nhất và chỉ số BIC thấp nhất được phương pháp BMA chọn theo hồi quy probit; chúng được ký hiệu là BMAP1, BMAP2, BMAP3, BMAP4, BMAP5, BMAP6 (xem Bảng 4.5).
Căn cứ vào 6 mô hình phù hợp với dữ liệu nhất do BMA đề xuất theo hồi quy logistic và 6 mô hình phù hợp với dữ liệu nhất do BMA đề xuất theo hồi quy probit đều có các biến độc lập giống nhau gồm TUOI, DANTOC, TDHV, NANGSUAT, VAYVON, THUONGHIEU, RRB; hơn nữa, các biến độc lập này có cùng mức ý nghĩa thống kê và xác suất tác động đến biến phụ thuộc BAOHIEM gần như nhau (xem Bảng 4.4 và Bảng 4.5). Bên cạnh đó, theo nghiên cứu của Gujarati (2011) các giá trị bằng số của các hệ số hồi quy logistic và probit tuy khác nhau nhưng về mặt định tính thì các ý nghĩa kết quả là giống nhau. Từ kết quả trên, tác giả nhận thấy phương pháp BMA chọn lựa mô hình nghiên cứu theo hồi quy logistic và probit là tương tự nhau. Vì vậy, tác giả xin chọn 6 mô hình phù hợp nhất với dữ liệu do phương pháp BMA chọn theo hồi quy logistic để phân tích việc sẵn lòng tham gia bảo hiểm cây cà phê theo chỉ số năng suất của hộ nông dân tỉnh Đắk Lắk.
Bảng 4.4: Mô hình nghiên cứu được a chọn bởi hư ng h BMA theo hồi quy logistic
Xác suất | BMA L1 | BMA L2 | BMA L3 | BMA L4 | BMA L5 | BMA L6 | |
TUOI | 92.7% | 0.0588 *** | 0.0572 *** | 0.0469 ** | 0.0492 ** | 0.0560 *** | 0.0544 *** |
DANTOC | 28% | 0.5890 * | 0.5503 * | ||||
TDHV | 100% | 0.4062 *** | 0.4354 *** | 0.4004 *** | 0.3748 *** | 0.3967 *** | 0.4245 *** |
NANGSUAT | 24.6% | 0.0366 * | 0.0375 * | ||||
VAYVON | 100% | 2.5961 *** | 2.4439 *** | 2.5705 *** | 2.7015 *** | 2.4805 *** | 2.3239 *** |
THUONGHIEU | 50.3% | 0.6623 ** | 0.6254 * | 0.6474 * | |||
RRB | 100% | 1.1411 *** | 1.1403 *** | 1.1544 *** | 1.1541 *** | 1.0064 *** | 0.9997 *** |
Số biến độc lập | 5 | 4 | 5 | 6 | 6 | 5 | |
BIC | -2.438 | -2.437 | -2.437 | -2.437 | -2.436 | -2.436 | |
Xác suất hậu định | 9.2% | 6.8% | 5.5% | 5.0% | 4.1% | 3.6% | |
Mức ý nghĩa thống kê: 0 „***‟ 0.001 „**‟ 0.01 „*‟ 0.05 „.‟ 0.1 „ ‟ 1 | |||||||
Ngu n: Kết qu tính toán của tác gi
Bảng 4.5: Mô hình nghiên cứu được a chọn bởi hư ng h BMA theo hồi quy probit
Xác suất | BMA P1 | BMA P2 | BMA P3 | BMA P4 | BMA P5 | BMA P6 | |
TUOI | 97% | 0.0354 *** | 0.0347 *** | 0.0330 *** | 0.0290 ** | 0.0338 *** | 0.0300 ** |
DANTOC | 19% | 0.3292 * | 0.3118 * | ||||
TDHV | 100% | 0.2394 *** | 0.2580 *** | 0.2514 *** | 0.2371 *** | 0.2337 *** | 0.2206 *** |
NANGSUAT | 30% | 0.0229 * | 0.0227 * | ||||
VAYVON | 100% | 1.4630 *** | 1.3780 *** | 1.3157 *** | 1.4239 *** | 1.4043 *** | 1.5029 *** |
THUONGHIEU | 45% | 0.3754 ** | 0.3707 * | 0.3594 * | |||
RRB | 100% | 0.6509 *** | 0.6577 *** | 0.5683 *** | 0.6639 *** | 0.5643 *** | 0.6578 *** |
Số biến độc lập | 5 | 4 | 5 | 5 | 6 | 6 | |
BIC | -2.437 | -2.437 | -2.436 | -2.436 | -2.436 | -2.435 | |
Xác suất hậu định | 8.4% | 8% | 4.9% | 4.8% | 4.7% | 3.7% | |
Mức ý nghĩa thống kê: 0 „***‟ 0.001 „**‟ 0.01 „*‟ 0.05 „.‟ 0.1 „ ‟ 1 | |||||||
Ngu n: Kết qu tính toán của tác gi
Theo Bảng 4.4, tác giả nhận thấy 6 mô hình phù hợp nhất với dữ liệu gồm 7 biến độc lập TUOI, DANTOC, TDHV, NANGSUAT, VAYVON, THUONGHIEU,
RRB và những biến này có xác suất tác động đến biến BAOHIEM cao nhất trong số 29 biến độc lập (xem Bảng 4.6). Đây có thể xem là những biến quang trọng đối với mô hình nghiên cứu. Đặc biệt, trong các biến này thì có 3 biến DANTOC, THUONGHIEU, RRB là biến mới. Hơn nữa, trong nghiên cứu định tính thì yếu tố tuổi, yếu tố trình độ học vấn, yếu tố dân tộc, yếu tố năng suất, yếu tố vay vốn ngân
hàng và yếu tố rủi ro bão đều là những yếu tố có khả năng tác động đến yếu tố sẵn lòng tham gia bảo hiểm cây cà phê theo chỉ số năng suất của hộ nông dân tỉnh Đắk Lắk. Do đó, tùy vào mục đích nghiên cứu hoặc ứng dụng mà các nhà nghiên cứu cây cà phê, công ty bảo hiểm, ngân hàng thương mại có sự lựa chọn mô hình phù hợp với mục tiêu nghiên cứu.
Bảng 4.6: X c suất c c biến độc ậ t c động ên biến hụ thuộc (BAOHIEM)
Biến độc ậ | c suất | STT | Biến độc ậ | c suất | |
1 | TUOI | 92.7% | 16 | THUONGHIEU | 50.3% |
2 | GIOITINH | 0.5% | 17 | RRHH | 15.3% |
3 | DANTOC | 28.2% | 18 | RRMTT | 0.6% |
4 | TDHV | 100% | 19 | RRB | 100% |
5 | KINHNGHIEM | 6.5% | 20 | RRLL | 5.8% |
6 | HOIND | 0.0% | 21 | RRCT | 1.4% |
7 | LAODONG | 4.5% | 22 | RRSB | 0.5% |
8 | DIENTICH | 0.0% | 23 | RRON | 1.1% |
9 | TUOICAY | 4.4% | 24 | RRMG | 4.2% |
10 | NANGSUAT | 24.6% | 25 | RRNVL | 8.3% |
11 | THUNHAP | 0.6% | 26 | RRHHD | 5.5% |
12 | SOHUUDAT | 0.5% | 27 | RRLDB | 2.1% |
13 | VAYVON | 100% | 28 | RRLDTN | 0.5% |
14 | TIEUCHUAN | 1.1% | 29 | RRLDC | 3.0% |
15 | THITRUONG | 0.5% | |||
Ngu n: Kết qu tính toán của tác gi
4.3.3. ết quả ước ượng tha số v hả năng d đ n chính c của ô hình
Hiện nay, chiến lược xây dựng mô hình thường được sử dụng khá phổ biến trong thực tế là chia bộ dữ liệu nghiên cứu thành 2 bộ dữ liệu nhỏ hơn một cách ngẫu nhiên (phần mềm chọn tự động, Nguyễn Văn Tuấn, 2020). Cụ thể như sau:
4.3.3.1. Sử dụng t n bộ dữ iệu để ước ượng tham số và d đ n
Trong trường hợp này, tác giả sẽ sử dụng toàn bộ dữ liệu 480 quan sát thu thập được để ước lượng tham số mô hình BMAL1 (xem Bảng 4.7), BMAL2 (xem Bảng 4.8), BMAL3 (xem Bảng 4.9), BMAL4 (xem Bảng 4.10), BMAL5 (xem Bảng 4.11), BMAL6 (xem Bảng 4.12). Độ chính xác của mô hình sẽ được tính bằng cách so sánh kết quả dự đoán của mô hình với kết quả khảo sát thực tế về việc sẵn l ng tham gia bảo hiểm cây cà phê theo chỉ số năng suất của hộ nông dân tỉnh Đắk Lắk. Cụ thể, tác giả d ng dữ liệu ước lượng tham số mô hình để so sánh với kết quả dự đoán của mô hình nhằm tìm ra độ chính xác của mô hình BMAL1 (xem Bảng 4.7), BMAL2 (xem Bảng 4.8), BMAL3 (xem Bảng 4.9), BMAL4 (xem Bảng 4.10), BMAL5 (xem Bảng 4.11), BMAL6 (xem Bảng 4.12).
Bảng 4.7: ết quả ước ượng tha số và d đ n với ô hình BMAL1
Ước ượng | Sai số chuẩn | P-value | |
(Intercept) | -7.19384 | 1.02293 | 2.03e-12 *** |
TUOI | 0.05875 | 0.01598 | 0.000236 *** |
TDHV | 0.40615 | 0.04760 | < 2e-16 *** |
VAYVON | 2.59613 | 0.45681 | 1.32e-08 *** |
THUONGHIEU | 0.66229 | 0.25546 | 0.009527 ** |
RRB | 1.14111 | 0.24479 | 3.14e-06 *** |
Chỉ số | Gi trị | ||
Brier | 0.168 | ||
AUC | 0.828 | ||
AUC (bootstrap 1000 lần) | 0.819 | ||
Kết quả dự đoán của mô hình theo dữ liệu ước lượng (toàn bộ dữ liệu) | |||
Độ chính xác | 75.83% | ||
Độ nhạy | 77.73% | ||
Độ đặc hiệu | 73.66% | ||
Ma trận nhầm lẫn | Tham khảo | ||
Dự đoán | SL | KSL | |
SL | 199 | 59 | |
KSL | 57 | 165 | |
Mức ý nghĩa thống kê: 0 „***‟ 0.001 „**‟ 0.01 „*‟ 0.05 „.‟ 0.1 „ ‟ 1 | |||
Ngu n: Kết qu tính toán của tác gi