Bảng 4.19: Tổng hợp c c ô hình (tiếp theo)
MÔ HÌNH | ||||
BMAL5 | BMAL5 _Split | BMAL6 | BMAL6 _Split | |
Biến | TUOI *** | TUOI * | TUOI *** | TUOI * |
TDHV *** | TDHV *** | TDHV *** | TDHV *** | |
VAYVON *** | VAYVON *** | VAYVON *** | VAYVON *** | |
RRB *** | RRB *** | RRB *** | RRB *** | |
NANGSUAT * | NANGSUAT * | NANGSUAT * | NANGSUAT * | |
THUONGHIEU * | THUONGHIEU ** | |||
Brier | 0.167 | 0.171 | 0.166 | 0.175 |
AUC | 0.832 | 0.823 | 0.833 | 0.815 |
Bootstrap AUC | 0.82 | 0.808 | 0.817 | 0.803 |
Dữ liệu ước lượng tham số mô hình | 480 hộ | 385 hộ | 480 hộ | 385 hộ |
Độ chính xác mô hình | 76.46% | 75.58% | 74.58% | 74.55% |
Dữ liệu kiểm tra mô hình | không | 95 hộ | không | 95 hộ |
Độ chính xác mô hình | không | 76.84% | không | 77.89% |
Mức ý nghĩa thống kê: 0 „***‟ 0.001 „**‟ 0.01 „*‟ 0.05 „.‟ 0.1 „ ‟ 1 | ||||
Có thể bạn quan tâm!
-

 Chọn L A Mô Hình Hộ Nông Dân Sẵn Lòng Tham Gia Bảo Hiểm Cây Cà Phê Theo Chỉ Số Năng Suất Bằng Hư Ng H Bma
Chọn L A Mô Hình Hộ Nông Dân Sẵn Lòng Tham Gia Bảo Hiểm Cây Cà Phê Theo Chỉ Số Năng Suất Bằng Hư Ng H Bma -
 Ết Quả Ước Ượng Tha Số V D Đ N Với Ô Hình Bmal2
Ết Quả Ước Ượng Tha Số V D Đ N Với Ô Hình Bmal2 -
 Ết Quả Ước Ượng Tha Số V D Đ N Với Ô Hình Bmal3_Split
Ết Quả Ước Ượng Tha Số V D Đ N Với Ô Hình Bmal3_Split -
 Các Chức Năng C Bản Của C Quan Quản Lý Rủi Ro Nông Nghiệp Và Liên Kết Tới Đ N Vị Phát Triển Thị Trường Bảo Hiểm Nông Nghiệp
Các Chức Năng C Bản Của C Quan Quản Lý Rủi Ro Nông Nghiệp Và Liên Kết Tới Đ N Vị Phát Triển Thị Trường Bảo Hiểm Nông Nghiệp -
 Chính Phủ, 2011. Quyế 3 5/qđ- M B O Hi M Nông Nghi P . Hà Nội, Năm 2011.
Chính Phủ, 2011. Quyế 3 5/qđ- M B O Hi M Nông Nghi P . Hà Nội, Năm 2011. -
 Nghiên cứu ứng dụng thống kê Bayes phân tích việc sẵn lòng tham gia bảo hiểm cây cà phê theo chỉ số năng suất của hộ nông dân tỉnh Đắk Lắk - 21
Nghiên cứu ứng dụng thống kê Bayes phân tích việc sẵn lòng tham gia bảo hiểm cây cà phê theo chỉ số năng suất của hộ nông dân tỉnh Đắk Lắk - 21
Xem toàn bộ 251 trang tài liệu này.
Ngu n: Kết qu tính toán của tác gi
4.3.5. So sánh mô hình hồi quy logistic tần số và hồi quy logistic Bayesian
Trong 6 mô hình BMAL1_Split, BMAL2_Split, BMAL3_Split, BMAL4_Split, BMAL5_Split, BMAL6_Split phân tích hộ nông dân sẵn lòng tham gia bảo hiểm cây cà phê theo chỉ số năng suất phù hợp nhất với dữ liệu. Do đó, tác giả xin phép sử dụng mô hình BMAL5 Split làm mô hình đại diện để so sánh mô hình hồi quy logistic tần số và hồi quy logistic Bayesian. Dựa vào kết quả thể hiện ở Bảng 4.17, mô hình BMAL5_Split hồi quy logistic tần số cung cấp cho chúng ta giá trị P-value và tất cả các biến độc lập điều có ý nghĩa thống kê, mô hình BMAL5_Split hồi quy logistic Bayesian cung cấp cho chúng ta giá trị trung bình phân phối hậu định ước lượng tham số của các biến độc lập với mức 95% (Quy trình lấy mẫu cho chu i MCMC 2000 lần, xem Phụ lục 7.45). Đặc biệt, hệ số ước lượng của các biến độc lập theo hồi quy logistic tần số và giá trị trung bình của các biến độc lập theo hồi quy logistic Bayesian gần bằng nhau (xem Bảng 4.20). Sự khác biệt là hồi quy logistic tần số không cho biết xác suất xảy ra tại một điểm mà chỉ cung cấp khoảng tin cậy 95 tại điểm đó (xem Hình 4.3). Trong khi đó, hồi quy logistic Bayesian cho chúng ta biết xác suất xảy ra tại một điểm thông qua phối xác suất (Gelman và Hill, 2007) (xem Hình 4.4).
Bảng 4.20: So sánh hồi quy logistic tần số và hồi quy logistic Bayesian
Hồi quy logistic | Hồi quy logistic Bayesian | |||
Hệ số | P-value | Giá trị trung bình | Phân phối 95 | |
(Intercept) | -7.069 | 2.69e-09 *** | -7.199 | (-9.514, -4.852) |
TUOI | 0.043 | 0.016244 * | 0.043 | (0.008, 0.078) |
TDHV | 0.352 | 5.32e-12 *** | 0.359 | (0.258, 0.461) |
NANGSUAT | 0.038 | 0.049749 * | 0.039 | (0.001, 0.078) |
VAYVON | 2.118 | 1.73e-05 *** | 2.129 | (1.246, 3.066) |
THUONGHIEU | 0.765 | 0.006113 ** | 0.773 | (0.223, 1.305) |
RRB | 1.066 | 0.000114 *** | 1.082 | (0.529, 1.649) |
Mức ý nghĩa thống kê: 0 „***‟ 0.001 „**‟ 0.01 „*‟ 0.05 „.‟ 0.1 „ ‟ 1 | ||||
Ngu n: Kết qu tính toán của tác gi
Hình 4.3: Kết quả mô hình hồi quy logistic tần số
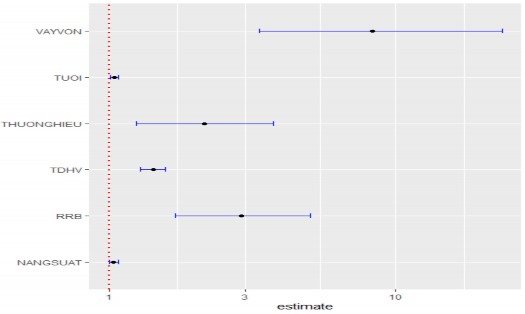
Ngu n: Kết qu tính toán của tác gi
Hình 4.4: Kết quả mô hình hồi quy logistic Bayesian
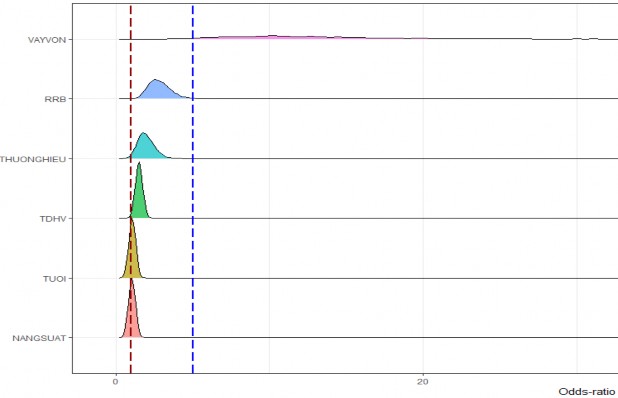
Ngu n: Kết qu tính toán của tác gi
4.4. Xây d ng t n đồ
Trong luận án này, dựa trên mô hình ước lượng tác giả sẽ xây dựng toán đồ dự đoán nhanh để xem xét việc hộ nông dân có sẵn l ng tham gia bảo hiểm cây cà phê theo chỉ số năng suất. Toán đồ này sẽ giúp nhà nghiên cứu cây cà phê, công ty bảo hiểm, ngân hàng thương mại…dễ dàng dự đoán sơ bộ được khả năng sẵn l ng tham gia bảo hiểm cây cà phê theo chỉ số năng suất của hộ nông dân. Toán đồ được tác giả xây dựng trực tuyến cho một mô hình đại diện (BMAL5_Slipt) theo đường dẫn liên kết như sau: https://ledinhthang.shinyapps.io/WTJIC/ (Hình 4.5)
Hình 4.5: T n đồ d đ n hộ nông d n sẵn ng tha gia bả hiể c c hê the chỉ số năng suất bằng hình ảnh
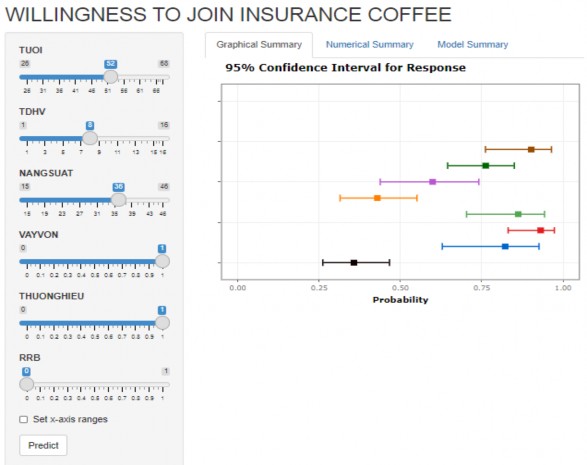
Ngu n: Kết qu tính toán của tác gi
Nhìn vào toán đồ, ta thấy bên trái toán đồ thể hiện những biến độc lập của nh nghiên cứu và ô “Predict” (dự đoán); bên phải toán đồ thể hiện kết quả dự đoán bằng hình ảnh (xem Hình 4.5) và bằng số liệu (xem Hình 4.6). Khi ta muốn dự báo khả năng một hộ nông dân nào đó sẵn lòng tham gia bảo hiểm cây cà phê hiểm cây cà phê theo chỉ số năng suất thì chúng ta chỉ cần chọn giá trị của biến TUOI, biến TDHV, biến NANGSUAT, biến VAYVON, biến THUONGHIEU, biến RRB của hộ nông dân đó sao cho khớp với giá trị của các biến đó trên toán đồ và nhấn nút “Predict”. Kết quả dự báo sẽ được toán đồ của mô hình nghiên cứu thể hiện bằng hình ảnh hoặc bằng số liệu.
Hình 4.6: T n đồ d đ n hộ nông d n sẵn ng tha gia bả hiể c c hê the chỉ số năng suất bằng số liệu
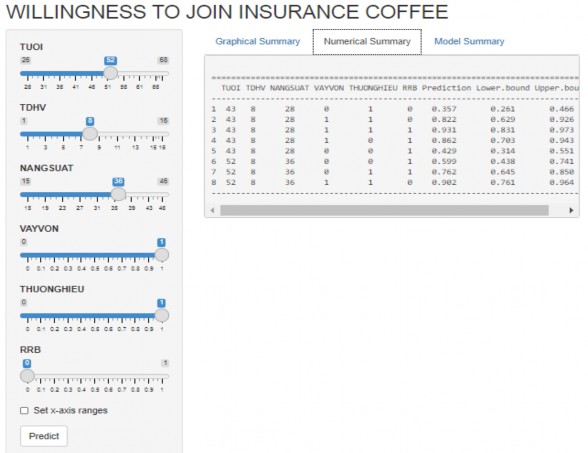
Ngu n: Kết qu tính toán của tác gi
4.5. Kết luận chư ng 4
Phương pháp thống kê BMA đã lựa chọn ra các mô hình phù hợp nhất với dữ liệu. Các mô hình đó có số biến ít hơn nên tiết kiệm về mặt dữ liệu, dự báo chính xác hơn và đặc biệt là cung cấp cho chúng ta xác suất hậu định của mô hình. Phương pháp tách dữ liệu thành hai phần huấn luyện và kiểm tra kết hợp với phương pháp bootstrap giúp chúng ta xác định được mô hình đó có thể áp dụng cho một quần thể độc lập mà vẫn có độ chính xác như trong quần thể phát triển. Phương pháp hồi quy logistic Bayesian cũng có ưu điểm hơn hồi quy logistic là cung cấp cho chúng ta phân phối hậu định của hệ số hồi quy. Mô hình hộ nông dân sẵn lòng tham gia bảo hiểm cây cà phê theo chỉ số năng suất mà tác giả nhận thấy là phù hợp nhất với nghiên cứu này là mô hình BMAL5 Split. Mô hình bao gồm 6 yếu tố: yếu tố tuổi của chủ hộ, yếu tố trình độ học vấn của chủ hộ, yếu tố năng suất cây cà phê, yếu tố vay vốn ngân hàng, yếu tố thương hiệu và yếu tố rủi ro bão. Kết quả chương 4 sẽ là nền tảng cho việc chọn lựa hàm ý và chính sách ở chương 5.
CHƯƠNG 5: ẾT LUẬN VÀ HÀM Ý CHÍNH SÁCH
5.1. Những kết quả nghiên cứu chính
Trong nghiên cứu này, phương pháp thống kê BMA đã cho thấy sự chắc chắn trong việc xây dựng mô hình hộ nông dân sẵn lòng tham gia bảo hiểm cây cà phê theo chỉ số năng suất, tất cả 536.870.912 mô hình được tạo bởi 29 biến độc lập đều được xem xét và so sánh bởi giá trị xác suất hậu định và BIC. Vì mô hình nghiên cứu có biến phụ thuộc là nhị phân, cho nên tác giả đã sử dụng phương pháp BMA cho mô hình hồi quy logistic và phương pháp BMA cho mô hình hồi quy probit trong việc lựa chọn mô hình. Kết quả là 2 phương pháp BMA này đã tìm ra những mô hình nghiên cứu phù hợp nhất với dữ liệu tương đồng nhau.
Một lần nữa, để đảm bảo sự chắc chắn trong việc xây dựng mô hình, phương pháp BMA đã cung cấp chi tiết thông tin về những mô hình phù hợp nhất với dữ liệu. Từ đó, các nghiên cứu cần sẽ có cái nhìn tổng quát hơn về biến phụ thuộc trong mô hình bằng cách xem xét những mô hình đó. Mô hình BMAL1, BMAL2, BMAL3, BMAL4, BMAL5, BMAL6 là 6 mô hình phù hợp nhất với dữ liệu do phương pháp BMA chọn được trong nghiên cứu này. Những mô hình này có xác suất hậu định cao nhất và có chỉ số BIC thấp nhất, tổng xác suất hậu định của 6 mô hình này chiếm 34,2% (xem Bảng 4.4).
Sau khi tìm được 6 mô hình phù hợp nhất với dữ liệu, tác giả sử dụng phương pháp tách dữ liệu và tạo ra 6 mô hình BMAL1_Split, BMAL2_Split, BMAL3_Split, BMAL4_Split, BMAL5_Split, BMAL6_Split dự báo việc sẵn lòng tham gia bảo hiểm cây cà phê theo chỉ số năng suất của hộ nông dân tỉnh Đắk Lắk nhằm mục đích kiểm tra sự phù hợp của các mô hình trong các bộ dữ liệu độc lập khác. Tuy nhiên, việc sử dụng phương pháp này sẽ làm giảm cỡ mẫu tức làm giảm độ nhạy của nghiên cứu do số biến cố ít hơn tham số. Do đó, tác giả đã sử dụng phương pháp này kết hợp với phương pháp bootstrap nhằm tăng tính ổn định và tăng sự tái lập của mô hình. Kết quả là khả năng dự báo của 6 mô hình BMAL1_Split,
BMAL2_Split, BMAL3_Split, BMAL4_Split, BMAL5_Split, BMAL6_Split với bộ dữ liệu khác cho độ chính xác khá tốt, từ 76.84 đến 81.05% (xem Bảng 4.19).
Yếu tố thương hiệu, yếu tố rủi ro bão, yếu tố dân tộc là các điểm mới đã được phát hiện trong nghiên cứu này. Đây là những yếu tố chưa từng được xuất hiện trong các nghiên cứu thực nghiệm hoặc chỉ được đề cập trong các nghiên cứu định tính về việc sẵn lòng tham gia bảo hiểm cây trồng. Những hộ nông dân có tuổi chủ hộ lớn, có trình độ học vấn cao, dân tộc Kinh, được vay vốn ngân hàng, năng suất cây cà phê cao, quan tâm phát triển thương hiệu cây cà phê, bị ảnh hưởng bởi bão thì khả năng sẵn lòng tham gia bảo hiểm cây cà phê theo chỉ số năng suất của hộ nông dân tỉnh Đắk Lắk cao hơn những hộ nông dân còn lại. Những hộ nông dân là người dân tộc Kinh có trình độ học vấn cao hơn những hộ nông dân dân tộc tiểu số tỉnh Đắk Lắk, họ sẽ hiểu được lợi ích của bảo hiểm và chủ hộ lớn tuổi có kinh nghiệm sản xuất cà phê nên biết được sản xuất cà phê có rất nhiều rủi ro. Đồng thời các ngân hàng thương mại đều muốn đảm khả năng thanh toán nguồn vốn đã cho vay luôn khuyến khích hộ nông dân tham gia bảo hiểm. Mặt khác hộ nông dân cũng có nhu cầu tham gia bảo hiểm như một công cụ để đề phòng rủi ro và dùng phần tiền bồi thường từ bảo hiểm để chi trả tiền vay cho ngân hàng nếu bị thiệt hại năng suất do rủi ro gây ra. Cùng với đó, những hộ nông dân có năng suất cao khi gặp rủi ro có thể dẫn đến tình trạng mất thu nhập do bị đền hợp đồng vì không đảm bảo chất lượng cũng như số lượng cà phê trong hợp đồng. Đây là một thiệt hại kép của hộ nông dân sản xuất cây cà phê và làm ảnh hưởng nghiêm trọng đến thương hiệu cà phê của tỉnh Đắk Lắk.
Ngoài kết quả ước lượng hồi quy logistic tần số, chúng ta có thể sử dụng phân phối xác suất hậu định của mô hình khi dùng hồi quy logistic Bayesian. Phân phối xác suất của mô hình cho chúng ta cái nhìn tổng quát hơn về sự tác động của các biến độc lập đến việc sẵn lòng tham gia bảo hiểm cà phê theo chỉ số năng suất của hộ nông dân tỉnh Đắk Lắk (Hình 4.4).
Đặc biệt, tác giả đã xây dựng được toán đồ của mô hình nghiên cứu hộ nông dân sẵn l ng tham gia bảo hiểm cây cà phê theo chỉ số năng suất bằng hình thức