tóm lược hiện đại khác đã công bố trên cùng các bộ dữ liệu thử nghiệm. Điều đó chứng tỏ mô hình đề xuất đã đạt được kết quả tốt cho tóm tắt đa văn bản hướng tóm lược tiếng Anh và tiếng Việt.
5.4. Kết luận chương 5
Trong chương này, luận án đã đề xuất phát triển một mô hình tóm tắt đa văn bản hướng trích rút và hai mô hình tóm tắt đa văn bản hướng tóm lược sử dụng các kỹ thuật học máy, học sâu kết hợp với các kỹ thuật hiệu quả khác và các đặc trưng của văn bản. Các mô hình tóm tắt này đều áp dụng được cho tóm tắt đa văn bản tiếng Anh và tiếng Việt. Các kết quả đạt được cụ thể như sau:
Mô hình tóm tắt đa văn bản hướng trích rút Kmeans_Centroid_EMDS:
- Đề xuất phát triển mô hình tóm tắt đa văn bản hướng trích rút dựa trên kỹ thuật phân cụm K-means, phương pháp dựa trên trung tâm (Centroid-based) trong học máy.
- Kết hợp các đặc trưng vị trí câu, MMR vào mô hình tóm tắt.
- Thử nghiệm và đánh giá kết quả mô hình đề xuất Kmeans_Centroid_EMDS cho tóm tắt đa văn bản tiếng Anh, tiếng Việt trên các bộ dữ liệu DUC 2007, Corpus_TMV tương ứng.
Mô hình tóm tắt đa văn bản hướng tóm lược PG_Feature_AMDS:
Có thể bạn quan tâm!
-

 Các Mẫu Tóm Tắt Của Cụm D0716D Trong Bộ Dữ Liệu Duc 2007 Của Mô Hình Đề Xuất Và Con Người
Các Mẫu Tóm Tắt Của Cụm D0716D Trong Bộ Dữ Liệu Duc 2007 Của Mô Hình Đề Xuất Và Con Người -
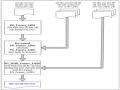 Các Giai Đoạn Huấn Luyện Mô Hình Tóm Tắt Đa Văn Bản Hướng Tóm Lược Đề Xuất Pg_Feature_Amds
Các Giai Đoạn Huấn Luyện Mô Hình Tóm Tắt Đa Văn Bản Hướng Tóm Lược Đề Xuất Pg_Feature_Amds -
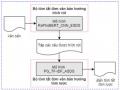 Mô Hình Tóm Tắt Đơn Văn Bản Hỗn Hợp Ext_Abs_Asds
Mô Hình Tóm Tắt Đơn Văn Bản Hỗn Hợp Ext_Abs_Asds -
 Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 20
Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 20 -
 Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 21
Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 21 -
 Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 22
Nghiên cứu, phát triển một số phương pháp tóm tắt văn bản sử dụng kỹ thuật học sâu - 22
Xem toàn bộ 185 trang tài liệu này.
- Đề xuất phát triển mô hình tóm tắt đa văn bản hướng tóm lược PG_Feature_AMDS dựa trên mô hình tóm tắt đơn văn bản hướng tóm lược pre- trained PG_Feature_ASDS đã đề xuất.
- Kết hợp các đặc trưng tần suất xuất hiện của từ và vị trí câu vào mô hình tóm tắt đa văn bản để tương thích với mô hình pre-trained PG_Feature_ASDS đã đề xuất.

- Tinh chỉnh mô hình PG_Feature_ASDS bằng việc huấn luyện tiếp mô hình trên các bộ dữ liệu thử nghiệm tóm tắt đa văn bản tương ứng (bộ dữ liệu DUC 2007 đối với tiếng Anh, bộ dữ liệu ViMs đối với tiếng Việt).
- Thử nghiệm và đánh giá kết quả mô hình đề xuất PG_Feature_AMDS cho tóm tắt đa văn bản tiếng Anh, tiếng Việt trên các bộ dữ liệu DUC 2004, Corpus_TMV tương ứng.
Mô hình tóm tắt đa văn bản hướng tóm lược Ext_Abs_AMDS-mds-mmr:
- Đề xuất phát triển mô hình tóm tắt đa văn bản hướng tóm lược Ext_Abs_AMDS-mds-mmr dựa trên mô hình hỗn hợp Ext_Abs_ASDS được huấn luyện trước.
- Kết hợp đặc trưng trọng số của từ TF-IDF vào các mô hình tóm tắt đơn văn bản được huấn luyện trước.
- Tinh chỉnh mô hình hỗn hợp pre-trained Ext_Abs_ASDS bằng việc huấn luyện tiếp mô hình này trên các bộ dữ liệu tóm tắt đa văn bản tương ứng.
- Thử nghiệm và đánh giá kết quả mô hình đề xuất Ext_Abs_AMDS-mds-mmr cho tóm tắt đa văn bản tiếng Anh, tiếng Việt trên các bộ dữ liệu DUC 2004, Corpus_TMV tương ứng.
Kết quả đạt được của chương đã được công bố trong công trình [CT1].
KẾT LUẬN
Luận án đã nghiên cứu về bài toán tóm tắt văn bản trong xử lý ngôn ngữ tự nhiên, các kỹ thuật hiện đại sử dụng để phát triển các mô hình tóm tắt văn bản hiệu quả như các kỹ thuật học máy, học sâu, các mô hình được huấn luyện trước kết hợp các đặc trưng của văn bản. Trên cơ sở đó, luận án đã đề xuất phát triển một số mô hình tóm tắt văn bản hướng trích rút và hướng tóm lược cho tiếng Anh và tiếng Việt. Mức độ hiệu quả của các mô hình đề xuất được đánh giá khách quan, đầy đủ qua thực nghiệm và phân tích giải thích các kết quả thực nghiệm. Với việc thử nghiệm trên các bộ dữ liệu có độ tin cậy cao, các mô hình tóm tắt văn bản đề xuất của luận án đã cho kết quả tóm tắt với độ chính xác cao, nghiên cứu sinh có thể bảo đảm rằng các mô hình tóm tắt văn bản đã đề xuất có hiệu quả cao hơn và khả năng ứng dụng tốt hơn so với một số phương pháp tóm tắt hiện tại.
A. Kết quả đạt được của luận án
Với bố cục của luận án gồm 5 chương, các kết quả chính đạt được có thể được tóm tắt như sau:
Đề xuất ba mô hình tóm tắt đơn văn bản hướng trích rút áp dụng cho tóm tắt văn bản tiếng Anh và tiếng Việt gồm:
Mô hình RoPhoBERT_MLP_ESDS: Mô hình sử dụng các mô hình tối ưu của mô hình pre-trained BERT để véc tơ hóa văn bản làm đầu vào cho mô hình phân loại sử dụng mạng MLP, kết hợp với các đặc trưng vị trí câu và phương pháp MMR để lựa chọn câu đưa vào bản tóm tắt.
Mô hình mBERT_CNN_ESDS: Mô hình sử dụng mô hình mBERT đa ngôn ngữ được đào tạo trước, mạng CNN, mô hình seq2seq, lớp FC, kết hợp các đặc trưng TF-IDF và MMR để lựa chọn câu đưa vào bản tóm tắt.
Mô hình mBERT-Tiny_seq2seq_DeepQL_ESDS: Mô hình sử dụng mô hình BERT-Tiny, mBERT để véc tơ hóa văn bản tiếng Anh, tiếng Việt tương ứng làm đầu vào cho mô hình phân loại câu sử dụng mạng CNN, seq2seq kết hợp với kỹ thuật học tăng cường Deep Q-Learning và phương pháp MMR để lựa chọn câu đưa vào bản tóm tắt. Mô hình được áp dụng hiệu quả trong điều kiện tài nguyên hạn chế.
Cả 3 mô hình tóm tắt đơn văn bản hướng trích rút đề xuất này đều được thử nghiệm trên các bộ dữ liệu CNN (tiếng Anh) và bộ dữ liệu Baomoi (tiếng Việt) đã cho kết quả cao.
Đề xuất phát triển một mô hình tóm tắt đơn văn bản hướng tóm lược hiệu quả sử dụng các kỹ thuật học sâu kết hợp các đặc TF và vị trí câu (mô hình PG_Feature_ASDS). Mô hình được thử nghiệm trên hai bộ dữ liệu CNN/Daily Mail (tiếng Anh) và bộ dữ liệu Baomoi (tiếng Việt) đã cho kết quả khá tốt. Mô hình có thể áp dụng hiệu quả cho tóm tắt văn bản tiếng Anh và tiếng Việt. Mô hình này cũng được sử dụng làm mô hình được huấn luyện trước trong giải pháp phát triển các mô hình tóm tắt đa văn bản hướng tóm lược mà luận án đề xuất.
Đề xuất phát triển một mô hình tóm tắt đa văn bản hướng trích rút sử dụng các kỹ thuật học máy, kết hợp đặc trưng vị trí câu và MMR để sinh văn bản tóm tắt (mô hình Kmeans_Centroid_EMDS). Mô hình được thử nghiệm trên bộ dữ liệu DUC 2007 (tiếng Anh), Corpus_TMV (tiếng Việt) cho kết quả tốt khi tóm tắt đa văn bản tiếng Anh, tiếng Việt.
Đề xuất phát triển hai mô hình tóm tắt đa văn bản hướng tóm lược cho tóm tắt đa văn bản tiếng Anh và tiếng Việt gồm:
Mô hình PG_Feature_AMDS: Mô hình dựa trên mô hình tóm tắt đơn văn bản hướng tóm lược PG_Feature_ASDS được huấn luyện trước. Mô hình PG_Feature_ASDS được tinh chỉnh bằng việc huấn luyện tiếp mô hình trên các bộ dữ liệu thử nghiệm cho tóm tắt đa văn bản tương ứng để mô hình đề xuất đạt được các kết quả tốt hơn. Mô hình đề xuất PG_Feature_AMDS được thử nghiệm sử dụng các bộ dữ liệu DUC 2007, DUC 2004 (tiếng Anh) và bộ dữ liệu ViMs, Corpus_TMV (tiếng Việt) đã cho kết đáng khá tốt. Với kết quả của mô hình đề xuất, mô hình có thể mở ra một hướng tiếp cận mới khi phát triển các mô hình tóm tắt đa văn bản hướng tóm lược hiệu quả trong điều kiện khan hiếm dữ liệu thử nghiệm.
Mô hình Ext_Abs_AMDS-mds-mmr: Mô hình dựa trên mô hình hỗn hợp Ext_Abs_ASDS được huấn luyện trước được xây dựng trên các mô hình tóm tắt đơn văn bản RoPhoBERT_CNN_ESDS, PG_TF-IDF_ASDS. Các mô hình tóm tắt đơn văn bản này được huấn luyện tiếp trên các bộ dữ liệu tóm tắt đa văn bản tương ứng để mô hình tóm tắt đạt được các kết quả tốt hơn. Mô hình tóm tắt đa văn bản hướng tóm lược đề xuất Ext_Abs_AMDS-mds-mmr được thử nghiệm sử dụng các bộ dữ liệu DUC 2007, DUC 2004 (tiếng Anh) và các bộ dữ liệu ViMs, Corpus_TMV (tiếng Việt) đã cho độ chính xác cao. Kết quả cho thấy đây là một hướng tiếp cận hiệu quả khi phát triển các mô hình tóm tắt đa văn bản hướng tóm lược.
Với các mô hình tóm tắt văn bản đã đề xuất của luận án, nghiên cứu sinh nhận thấy rằng các mô hình tóm tắt đề xuất đã đáp ứng tốt các yêu cầu của bài toán tóm tắt văn bản. Các mô hình tóm tắt văn bản đề xuất này là cơ sở để tiếp tục nghiên cứu phát triển các mô hình tóm tắt văn bản tiếp theo và có thể triển khai áp dụng hiệu quả cho các bài toán khác trong xử lý ngôn ngữ tự nhiên, các ứng dụng trong thực tiễn.
B. Những khó khăn và tồn tại của luận án
Mặc dù đã đề xuất phát triển được một số mô hình tóm tắt văn bản hiệu quả nhưng luận án đã gặp một số khó khăn và còn một số tồn tại sau:
Điều kiện cơ sở vật chất phục vụ cho thử nghiệm các mô hình đề xuất khó khăn.
Dữ liệu thử nghiệm cho các mô hình tóm tắt văn bản, đặc biệt là dữ liệu thử nghiệm cho tóm tắt đa văn bản còn thiếu.
Các mô hình tóm tắt văn bản đề xuất hiện tại mới chỉ áp dụng được cho tóm tắt văn bản tiếng Anh và tiếng Việt.
Độ phức tạp của các mô hình tóm tắt văn bản đã đề xuất là vấn đề cần xem xét do đặc điểm phức tạp của các mô hình học sâu đã sử dụng.
C. Định hướng phát triển
Luận án đã đề xuất phát triển một số mô hình tóm tắt văn bản áp dụng hiệu quả cho tóm tắt văn bản tiếng Anh và tiếng Việt. Từ các kết quả tốt của các mô hình đề xuất và kinh nghiệm phát triển các mô hình tóm tắt văn bản sử dụng các kỹ thuật học sâu, nghiên cứu sinh nhận thấy rằng các hướng nghiên cứu này thích hợp để phát triển các mô hình tóm tắt hiệu quả cho bài toán tóm tắt văn bản. Tuy nhiên, các mô hình tóm tắt văn bản đề xuất được thử nghiệm trên các bộ dữ liệu chưa đủ lớn. Trong thời gian tới, nghiên cứu sinh sẽ tiếp tục hướng nghiên cứu với một số định hướng sau:
Đánh giá tổng quan các mô hình đề xuất trên các bộ dữ liệu khác nhau.
Phát triển mở rộng các mô hình tóm tắt văn bản đề xuất để có thể áp dụng tóm tắt cho nhiều ngôn ngữ khác nhau như: Tiếng Trung, Nhật, Hàn Quốc,...
Phát triển các giải pháp xây dựng các bộ dữ liệu cho bài toán tóm tắt văn bản.
Nghiên cứu đề xuất các giải pháp tóm tắt văn bản trong điều kiện thiếu dữ liệu thử nghiệm.
Nghiên cứu tích hợp các mô hình tóm tắt văn bản đề xuất cho các công cụ tìm kiếm, các hệ thống khai phá dữ liệu văn bản và khai phá dữ liệu trang Website.
Nghiên cứu tích hợp các mô hình tóm tắt văn bản đề xuất để xây dựng hệ thống phần mềm “Thư ký ảo”, “Trợ lý ảo” áp dụng cho các buổi họp, xê mi na khoa học trong thực tế.
DANH MỤC CÁC CÔNG TRÌNH ĐÃ CÔNG BỐ
[CT1] Hai Cao Manh, Huong Le Thanh, Tuan Luu Minh (2019), Extractive Multi- document Summarization using K-means, Centroid-based Method, MMR, and Sentence Position. In Proceedings of the Tenth International Symposium on Information and Communication Technology (SoICT 2019), pp. 29-35, ACM (DOI: 10.1145/3368926.3369688).
[CT2] Viet Nguyen Quoc, Huong Le Thanh, Tuan Luu Minh (2020), Abstractive Text Summarization using LSTMs with Rich Features. In International Conference of the Pacific Association for Computational Linguistics (PACLING 2019: Computational Linguistics), pp. 28-40, Springer, Singapore.
[CT3] Minh-Tuan Luu, Thanh-Huong Le, Minh-Tan Hoang (2021), An Effective Deep Learning Approach for Extractive Text Summarization. Indian Journal of Computer Science and Engineering (IJCSE), Vol. 12, No. 2, pp. 434-444, 2021 (DOI: https://doi.org/10.21817/indjcse/2021/v12i2/211202146) (SCOPUS).
[CT4] Tuan Luu Minh, Huong Le Thanh, Tan Hoang Minh (2021), A hybrid model using the pre-trained BERT and deep neural networks with rich feature for extractive text summarzation. Journal of Computer Science and Cybernetics, Vol. 37, No. 2, pp. 123-143, 2021 (DOI: https://doi.org/10.15625/1813-
9663/37/2/15980).
[CT5] Lưu Minh Tuấn, Lê Thanh Hương, Hoàng Minh Tân (2021), Một phương pháp kết hợp các mô hình học sâu và kỹ thuật học tăng cường hiệu quả cho tóm tắt văn bản hướng trích rút. Tạp chí Khoa học và Công nghệ Đại học Thái Nguyên, Tập 226, Số 11, trang 208-215, 2021 (DOI: https://doi.org/10.34238/tnu-jst.4747).
TÀI LIỆU THAM KHẢO
[1] Vilca G. C. V. and Cabezudo M. A. S. (2017). A study of abstractive summarization using semantic representations and discourse level information. In Proceedings of the 20th International Conference on Text, Speech, and Dialogue, pp. 482-490.
[2] Mehdi Allahyari, Seyedamin Pouriyeh, Mehdi Assef, Saeid Safaei, Elizabeth
D. Trippe, Juan B. Gutierrez, and Krys Kochut (2017). Text Summarization Techniques: A Brief Survey. International Journal of Advanced Computer Science and Applications (IJACSA), Vol. 8, No. 10, pp. 397-405.
[3] Radev D. R., Hovy E., and McKeown K. (2002). Introduction to the special issue on summarization. Computational Linguistics, Vol. 28, No. 4, pp. 399- 408. MIT Press. DOI: 10.1162/089120102762671927.
[4] Ko Y. and Seo J. (2008). An effective sentence-extraction technique using contextual information and statistical approaches for text summarization. Pattern Recognition Letters, Vol. 29, No. 9, pp. 1366–1371. DOI: 10.1016/ j.patrec.2008.02.008.
[5] Afsharizadeh M., Ebrahimpour-Komleh H., and Bagheri A. (2018). Query- oriented text summarization using sentence extraction technique. 2018 4th International Conference on Web Research (ICWR), Tehran, Iran. DOI: 10.1109/ICWR.2018.8387248.
[6] Mark Wasson (1998). Using leading text for news summaries: Evaluation results and implications for commercial summarization applications. In Proceedings of the 17th international conference on Computational linguistics- Vol. 2, pp. 1364-1368.
[7] Miller G. A. (1995). WordNet: A lexical database for English. Communications of the ACM, Vol. 38, No. 11, pp. 39–41.
[8] Sankarasubramaniam Y., Ramanathan K., and Ghosh S. (2014). Text summarization using Wikipedia. Information Processing & Management, Vol. 50, No. 3, pp. 443–461. DOI: 10.1016/j.ipm.2014.02.001.
[9] Wang Y. and Ma J. (2013). A Comprehensive method for text summarization based on latent semantic analysis. In Proceedings of the Natural language processing and Chinese computing, pp. 394–401.
[10] Sahni A. and Palwe S. (2018). Topic Modeling On Online News Extraction. In Proceedings of the Intelligent Computing and Information and Communication, pp. 611-622.
[11] Gunes Erkan and Dragomir R. Radev (2004). LexRank: Graph-based Lexical Centrality as Salience in Text Summarization. Journal of Artificial Intelligence Research, Vol. 22, No. 1, pp 457-479.
[12] Mehta P. And Majumder P. (2018). Effective aggregation of various summarization techniques. Information Processing & Management, Vol. 54, No. 2, pp. 145–158. DOI: 10.1016/j.ipm.2017.11.002.
[13] Dragomir R. Radev, Hongyan Jing, Malgorzata Stys, and Daniel Tam (2004). Centroid-based summarization of multiple documents. Information Processing and Management, Vol. 40, No. 6, pp. 919–938.
[14] Rada Mihalcea and Paul Tarau (2004). TextRank: Bringing Order into Texts. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, pp. 404-411. Association for Computational Linguistics.
[15] Brin S., and Page L. (1998). The anatomy of a large-scale hypertextual Web search engine. In Proceedings of the seventh international conference on World Wide Web 7, pp. 107–117.
[16] Al-Sabahi K., Zhang Z., Long J., and Alwesabi K. (2018). An enhanced latent semantic analysis approach for Arabic document summarization. Arabian Journal for Science and Engineering, Vol. 43, No. 5. DOI: 10.1007/s13369- 018-3286-z.
[17] Mashechkin I. V., Petrovskiy M. I., Popov D. S., and Tsarev D. V. (2011). Automatic text summarization using latent semantic analysis. Programming and Computer Software, Vol. 37, No. 6, pp. 299–305. DOI: 10.1134/s0361768811060041.
[18] Alguliyev R. M., Aliguliyev R. M., Isazade N. R., Abdi A., and Idris N. (2019). COSUM: Text summarization based on clustering and optimization. Expert Systems, Vol. 36, No. 1. DOI: 10.1111/exsy.12340 e12340.
[19] John A., and Wilscy M. (2013). Random forest classifier based multi- document summarization system. In Proceedings of the 2013 IEEE Recent Advances in Intelligent Computational Systems (RAICS). DOI: 10.1109/RAICS.2013.6745442.
[20] Shetty K., and Kallimani J. S. (2017). Automatic extractive text summarization using K-means clustering. In Proceedings of the 2017 International Conference on Electrical, Electronics, Communication, Computer, and Optimization Techniques (ICEECCOT). DOI: 10.1109/ICEECCOT.2017.8284627.
[21] Kobayashi H., Noguchi M., and Yatsuka T. (2015). Summarization based on embedding distributions. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, pp. 1984-1989.
[22] Chen L., and Nguyen M. L. (2019). Sentence selective neural extractive summarization with reinforcement learning. In Proceedings of the 2019 11th International Conference on Knowledge and Systems Engineering (KSE). DOI: 10.1109/KSE.2019.8919490.
[23] Jianpeng Cheng and Mirella Lapata (2016). Neural summarization by extracting sentences and words. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Vol. 1: Long Papers), pp. 484–
494. Association for Computational Linguistics.
[24] Ramesh Nallapati, Feifei Zhai, and Bowen Zhou (2017). Summarunner: A recurrent neural network based sequence model for extractive summarization
of documents. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, pp. 3075–3081.
[25] Warule P.D., Sawarkar S.D., Gulati A. (2019). Text Summarization Using Adaptive Neuro-Fuzzy Inference System. Computing and Network Sustainability (Lecture Notes in Networks and Systems), Vol. 75, pp. 315-324. Springer, Singapore. DOI: 10.1007/978-981-13-7150-9_34.
[26] Yao K., Zhang L., Luo T., and Wu Y. (2018). Deep reinforcement learning for extractive document summarization. Neurocomputing, Vol. 284, pp. 52–62. DOI: 10.1016/j.neucom.2018.01.020.
[27] Yousefi-Azar M., and Hamey L. (2017). Text summarization using unsupervised deep learning. Expert Systems with Applications, Vol. 68, pp. 93–105. DOI: 10.1016/j. eswa.2016.10.017.
[28] Bhat I. K., Mohd M., and Hashmy R. (2018). SumItUp: A hybrid single- document text summarizer. Soft computing: Theories and applications: Proceedings of SoCTA 2016, Vol. 1, pp. 619–634. Springer, Singapore.
[29] Al-Abdallah R. Z., and Al-Taani A. T. (2017). Arabic single-document text summarization using particle swarm optimization algorithm. Procedia Computer Science, Vol. 117, pp. 30–37. DOI: 10.1016/j.procs.2017.10.091.
[30] Krishnakumari K., and Sivasankar E. (2018). Scalable Aspect-Based Summarization in the Hadoop Environment. Advances in Intelligent Systems and Computing, vol. 654, pp. 439-449. Springer, Singapore. DOI: 10.1007/978-981-10-6620-7_42.
[31] Chitrakala S., Moratanch N., Ramya B., Revanth Raaj C. G., and Divya B. (2018). Concept-based extractive text summarization using graph modelling and weighted iterative ranking. In Proceedings of International Conference on Emerging research in computing, information, communication and applications: ERCICA 2016, pp. 149–160. Springer, Singapore.
[32] Ganesan K., Zhai C., and Han J. (2010). Opinosis: A graph-based approach to abstractive summarization of highly redundant opinions. In Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010), pp. 340–348. Coling 2010 Organizing Committee.
[33] Khan A., Salim N. and Farman H. (2016). Clustered genetic semantic graph approach for multi-document abstractive summarization. In Proceedings of the 2016 International Conference on Intelligent Systems Engineering (ICISE). DOI: 10.1109/INTELSE.2016.7475163.
[34] Lloret E., Roma-Ferri M. T., and Palomar M. (2011). COMPENDIUM: A text summarization system for generating abstracts of research papers. In Proceedings of the natural language processing and information systems. Springer, Berlin, Heidelberg. DOI: 10.1016/j.datak.2013.08.005.
[35] Ranjitha N. S., and Kallimani J. S. (2017). Abstractive multi-document summarization. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI). DOI: 10.1109/ICACCI.2017.8125804.