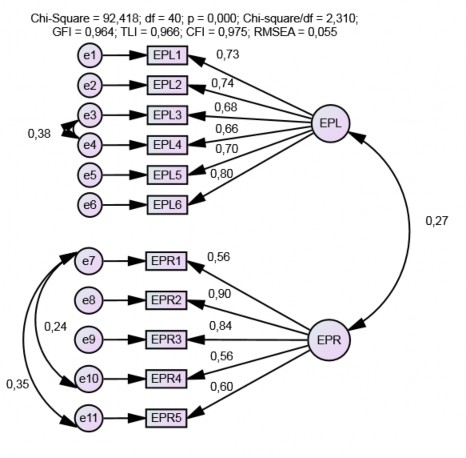
Hình 4.2. Kết quả CFA (chuẩn hoá) thang đo hành vi cá nhân
Nguồn: Trích xuất từ phần mềm xử lý
Mô hình CFA có 40 bậc tự do, CMIN = 92,418, p = 0,000. Tuy nhiên, các tiêu chí khác cho thấy mô hình CFA các khái niệm thành phần hành vi cá nhân phù hợp với dữ liệu của thị trường: CMIN/df = 2,310, TLI = 0,964, TLI = 0,966, CFI =0,975 và RMSEA =
0,055. Hai khái niệm EPL và EPR không đạt được tính đơn hướng do các sai số có tương quan.
Các trọng số hồi quy chuẩn hóa của các biến đều đạt yêu cầu ( ), thấp nhất là biến
EPR1 và EPR4, cả hai EPR1 và EPR4 đều có trọng số hồi quy chuẩn hóa bằng 0,56. Các giá trị p đều có ý nghĩa (p < 0,001). Độ tin cậy tổng hợp của EPL và EPR đều lớn hơn 0,7, các phương sai trung bình được trích của EPL = 51,7%, EPR = 50%. AVE của EPR nhỏ hơn 50% (xem Bảng 4.5).
114
Bảng 4.5. Các giá trị thang đo hành vi khai thác và khám phá
Độ tin cậy tổng hợp (CR) | Phương sai trung bình được trích (AVE) | Phương sai chia sẻ tối đa (MSV) | MaxR(H) (Square rooot of AVE) | Tương quan trong thang đo | |||
EPL | EPR | ||||||
EPL | 0,865 | 0,517 | 0,072 | 0,870 | 0,719 | ||
EPR | 0,827 | 0,500 | 0,072 | 0,889 | 0,269*** | 0,707 | |
Có thể bạn quan tâm!
-

 Thang Đo Hành Vi Khám Phá Và Hành Vi Khai Thác
Thang Đo Hành Vi Khám Phá Và Hành Vi Khai Thác -
 Đặc Điểm Mẫu Khảo Sát Nghiên Cứu Định Lượng Sơ Bộ
Đặc Điểm Mẫu Khảo Sát Nghiên Cứu Định Lượng Sơ Bộ -
 Thang Đo Các Thành Phần Hành Vi Khai Thác Và Khám Phá
Thang Đo Các Thành Phần Hành Vi Khai Thác Và Khám Phá -
 Kiểm Định Vai Trò Điều Tiết Của Tính Tích Cực Lên Mối Quan Hệ Yêu Cầu Công Việc
Kiểm Định Vai Trò Điều Tiết Của Tính Tích Cực Lên Mối Quan Hệ Yêu Cầu Công Việc -
 Mối Quan Hệ Trực Tiếp Giữa Các Khái Niệm Trong Mô Hình Khả Biến Đối Với Nhóm Nam Và Nữ
Mối Quan Hệ Trực Tiếp Giữa Các Khái Niệm Trong Mô Hình Khả Biến Đối Với Nhóm Nam Và Nữ -
 Các Hoạt Động Quản Lý Liên Quan Yêu Cầu Công Việc
Các Hoạt Động Quản Lý Liên Quan Yêu Cầu Công Việc
Xem toàn bộ 205 trang tài liệu này.
Nguồn: Kết quả xử lý từ dữ liệu thu thập
Các hệ số tương quan giữa EPL và EPR, và các sai số đều khác 1 và có giá trị thống kê. Ngoài ra, hệ số MSV < AVE và các hệ số MaxR(H) đều lớn hơn hệ số tương quan của chính thang đo EPL (0,719) và EPR (0,707). Do đó, khái niệm EPL và EPR đạt giá trị phân biệt.
4.3.2.3. Thang đo các thành phần động lực làm việc
Thang đo động lực nhân viên bao gồm hai thành phần gồm IM và EM. Trong đó, IM gồm 3 biến và EM gồm có 3 biến thuộc IDENT, 3 biến thuộc INTE. Trong quá trình phân tích EFA, hai thành phần khái niệm thuộc EM (IDENT và INTE) được gom lại thành một yếu tố.
Dựa trên kết quả phân tích EFA, tác giả sử dụng thang đo EM gồm có 6 biến trong đó bao gồm 3 biến của IDENT và ba biến của INTE.
Mô hình CFA (xem Hình 4.3) có 26 bậc tự do, CMIN = 44,675, p = 0,013. Các tiêu
chí phân tích phù hợp với dữ liệu của thị trường: CMIN/df = 1,718, GFI = 0,977, TLI =
0,982, CFI =0,987 và RMSEA = 0,041. Hai yếu tố IM và EM đạt được tính đơn hướng.
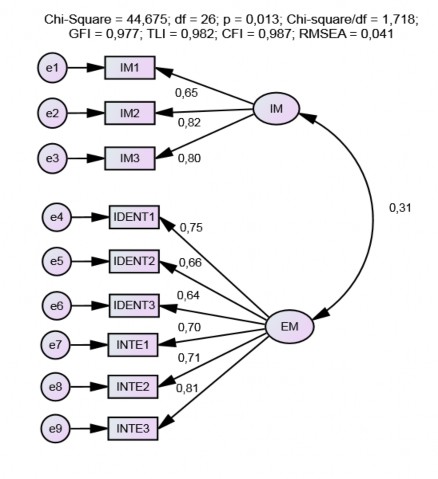
Hình 4.3. Kết quả CFA (chuẩn hoá) các thang đo động lực làm việc
Nguồn: Được trích xuất từ việc xử lý dữ liệu Các trọng số của các biến đều đạt tiêu chuẩn cho phép ( ), thấp nhất là biến IM1 có trọng số bằng 0,649. Tất cả giá trị p đều có ý nghĩa (p < 0,001). Độ tin cậy tổng hợp của IM và EM đều lớn hơn 0,7, các phương sai trung bình được trích đều lớn hơn 0,5, cụ thể AVE của IM = 57,6%, AVE của EM = 50,9% (xem Bảng 4.6). Tất cả các chỉ tiêu đánh giá
đều đạt yêu cầu nên hai thang đo đạt giá trị hội tụ.
Các hệ số tương quan giữa IM và EM là 0,313, và sai số của EM và IM là 0,023 khác 1 và có ý nghĩa. Ngoài ra, các hệ số MSV của IM và EM đều nhỏ hơn các AVE tương ứng. Các hệ số MaxR(H) đều lớn hơn hệ số tương quan của chính thang đo IM (0,759) và EM (0,713). Do đó, IM và EM đạt giá trị phân biệt.
Bảng 4.6. Các giá trị thang đo IM, EM trong mô hình
116
CR | AVE | MSV | MaxR(H) | Tương quan trong thang đo | |||
I | M | EM | |||||
IM | 0,801 | 0,576 | 0,098 | 0,818 | 0,759 | ||
EM | 0,861 | 0,509 | 0,098 | 0,869 | 0,313*** | 0,713 | |
Nguồn: Từ kết quả xử lý dữ liệu CFA
4.3.2.4. Thang đo hiệu quả công việc
Kết quả mô hình CFA cho thấy dữ liệu phù hợp với thị trường (xem Hình 4.4), cụ thể mô hình có bậc tự do là 1, CMIN = 1,320, p = 0,251, CMIN/df = 1,320, GFI = 0,998, TLI = 0,997, CFI = 1,000 và RMSEA = 0,027. Tuy nhiên, thang đo PERF không đạt được tính đơn hướng (do có hệ số tương quan giữa các sai số).
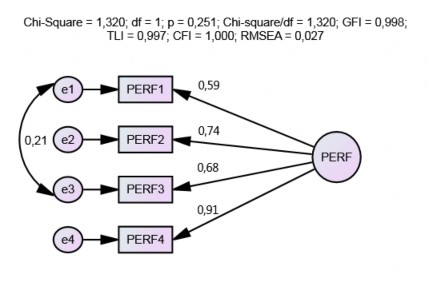
Hình 4.4. Kết quả CFA (chuẩn hoá) thang đo hiệu quả công việc
Nguồn: Kết quả xử lý dữ liệu của tác giả
Các trọng số hồi quy chuẩn hóa của các biến đều đạt tiêu chuẩn cho phép ( ), thấp nhất là biến PERF1 có trọng số hồi quy chuẩn hóa bằng 0,589. Tất cả trọng số hồi quy có giá trị p đều có ý nghĩa (p < 0,001). Độ tin cậy tổng hợp của PERF = 0,822 lớn hơn 0,7, phương sai trung bình được trích lớn hơn 0,5, cụ thể AVE của PERF = 54,2%, các chỉ tiêu đánh giá mức độ hội tụ của thang đo đều đạt yêu cầu nên thang đo đạt giá trị hội tụ.
4.3.2.5. Thang đo tính tích cực
Kết quả mô hình CFA của POS cho kết quả dữ liệu phù hợp với thị trường (xem
Hình 4.5), cụ thể mô hình có bậc tự do df = 5, CMIN = 7,499, p = 0,186, CMIN/df = 1,500, GFI = 0,993, TLI = 0,993, CFI = 0,997 và RMSEA = 0,034. Thang đo POS đạt được tính
đơn hướng.
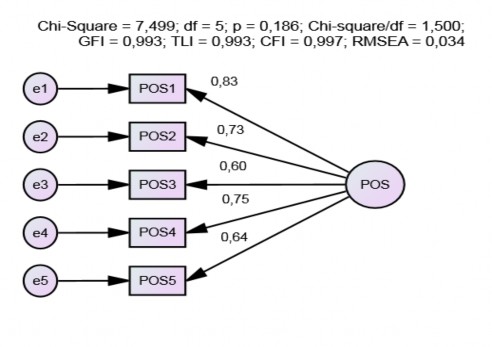
Hình 4.5. Kết quả CFA (chuẩn hoá) thang đo tính tích cực
Nguồn: Kết quả xử lý dữ liệu của tác giả Các trọng số chuẩn hóa của các biến đều đạt chuẩn cho phép ( ), thấp nhất là biến POS3 có trọng số bằng 0,599. Tất cả trọng số có giá trị p đều có ý nghĩa (p < 0,001). Độ tin cậy tổng hợp của POS = 0,836 > 0,7, AVE = 50,9% > 50%. Các chỉ số thang đo POS
đều đạt yêu cầu nên thang đo đạt giá trị hội tụ.
4.3.2.6. Kết quả kiểm định giá trị phân biệt giữa các khái niệm trong mô hình CFA
Mô hình CFA phân tích có 672 bậc tự do, CMIN = 1062,053, P = 0,000. Tuy nhiên,
kết quả phân tích CFA cho thấy dữ liệu phù hợp với thị trường với GFI = 0,892, TLI = 0,940, CFI = 0,946, RMSEA = 0,37, PCLOSE = 1,000. Mô hình có hai thang đo EPR và
EPL không đạt được tính đơn hướng vì có tương quan sai số, các thang đo còn lại đều
đạt tính đơn hướng.
118
Trọng số các biến của thang đo có giá trị lớn hơn 0,5 trong đó thấp nhất là biến
EPR1 = 0,568. Các trọng số có giá trị p đều có ý nghĩa (p < 0,001). Ngoài ra, độ tin cậy tổng hợp (CR) các thang đo đều lớn hơn 0,7 và phương sai trung bình được trích đều lớn hơn phương sai chia sẻ tối đa (MSV) (xem phụ lục 7.2). Do đó, chúng ta có thể kết luận các thang đo đạt giá trị hội tụ.
Hệ số tương quan (R) giữa các khai niệm và sai số chuẩn (S.E) đều khác 1 và có ý nghĩa (trừ một số giá trị có p lớn hơn 0,05). Ngoài ra, các hệ số MSV của các khái niệm đều nhỏ hơn các AVE tương ứng (xem phụ lục 7.2). Do đó, các khái niệm đạt giá trị phân biệt.
4.4. Kiểm định phân phối chuẩn và phương sai phương pháp chung
Để đánh giá dữ liệu có phù hợp hay không trước khi phân tích SEM bằng phương pháp ML Nghiên cứu thực hiện phép kiểm tra Kurtosis và skewness. Ngoài ra, để kiểm tra dữ liệu có xảy ra hiện tượng sai lệch phương pháp chung hay không bằng việc kiểm định phương sai một nhân tố (Harman’s Test), hệ số tương quan giữa các thang đo lường khái niệm (Lindell và Whitney, 2001) và phân tích phương sai qua việc dùng công cụ nhân tố tiềm ẩn chung (CLF).
4.4.1. Kiểm định phân phối chuẩn
Kết quả phân tích các biến đo lường từ dữ liệu cho thấy các Kurtosis và Skewness thuộc [1, +1], do đó việc áp dụng ML làm nguyên tắc ước lượng là phù hợp (xem phụ lục 7.1). Ngoài ra, việc thực hiện bootstrap với mẫu 1.000 cho kết quả phù hợp trong quá trình kiểm định bootstrap với p = 0,000.
Kết quả kiểm định tính ổn định các chỉ số phù hợp với dữ liệu thị trường liên quan đến mô hình tổng thể theo phương pháp chọn Bollen – Stine Bootstrap cũng cho thấy kết quả mô hình đạt ổn định với p = 0,001 và N = 1.000.
4.4.2. Kiểm tra hiện tượng phương sai phương pháp chung
Luận án này sử dụng cùng đối tượng khảo sát nhân viên kinh doanh hay môi giới bất động sản trong bối cảnh ngành bất động sản tại Việt Nam. Các đối tượng khảo sát trả lời tại một thời điểm và cùng thang đo 7 mức (điểm). Mặc dù các thang đo đã thực hiện các bước điều chỉnh, bổ sung và làm rõ nghĩa thang đo phù hợp bối cảnh và đối tượng khảo sát trong nghiên cứu định tính để hạn chế phương sai phương pháp chung
(CMV) do các thang đo nhân viên tự đánh giá PERF của mình dựa trên cảm nhận, vì hành
vi trả
lời phỏng vấn có thể
dẫn đến sai lệch khi dùng chung một phương pháp
(Podsakoff và cộng sự, 2003).
Để kiểm soát thống kê các sai lệch phương pháp chung theo thống kê, tác giả thực hiện theo ba cách. Cách thứ nhất, kiểm soát thống kê ảnh hưởng của sai lệch phương pháp bằng cách phân tích một nhân tố Harman với điều kiện tổng phương sai trích phải nhỏ hơn 50%. Cách thứ hai, hệ số tương quan giữa các khái niệm nhỏ hơn 0,9 sẽ không có sự hiện diện của sai lệch phương pháp chung (Lindell và Whitney, 2001). Cách thứ ba, dùng kỹ thuật phân tích nhân tố tiềm ẩn chung (common latent factor) hay gọi nhân tố phương pháp chung (common method factor) thực hiện nhằm mục đích so sánh phương sai phương pháp chung sau khi thực hiện CFA (Bagozzi, 1984; Podsakoff và cộng sự, 2003). Điều kiện giá trị p > 5% thì mô hình không có sự sai lệch khi xem xét phương sai giữa mô hình giới hạn và không giới hạn.
Kết quả kiểm định Harman dựa trên phần mềm SPSS 24.0 cho thấy tất cả 39 biến khi đưa vào phép trích nhân tố chính (Principal components) theo hình thức trích một nhân tố cố định (Fixed number of factors) với số nhân tố trích là 1 (Factors to extract = 1) và
không lựa chọn phương pháp xoay nhân tố (chọn none). Kết quả kiểm định cho thấy
tổng phương sai trích được 22,195%. Ngoài ra, các hệ số tương quan đều nhỏ hơn 0,9 (xem phụ lục 7.2). Như vậy phương sai phương pháp chung không phải là yếu tố gây ảnh hưởng đến sai lệch kết quả.
Tương tự, kết quả phân tích nhân tố tiềm ẩn chung (Common latent factor) bằng việc sử dụng mô hình giới hạn với các trọng số biến quan sát theo dạng chuẩn hoá của nhân tố tiềm ẩn chung bằng không (mô hình giới hạn) và mô hình với trọng số là a (mô hình không giới hạn). Kết quả xử lý cho thấy sự khác biệt phương sai hai mô hình là 3,84 với mức ý nghĩa 5%, chênh lệch bậc tự do là 1. Tuy nhiên, mức sai lệch này là không lớn.
Kiểm tra hiện tượng sai lệch phương sai có ảnh hưởng đến việc thổi phồng dữ liệu nghiên cứu hay không chúng ta cần kiểm tra sự chênh lệch giữa các trọng số hồi quy giữa mô hình tới hạn (hoặc mô hình giới hạn) và mô hình không giới hạn, nếu sự chênh lệch này không lớn hơn 0,2 thì chúng ta có thể kết luận dữ liệu ít bị ảnh hưởng bởi sai lệch do phản hồi của người trả lời. Kết quả so sánh cho thấy các trọng số chuẩn hoá
120
của các biến đều nhỏ nhơn 0,2 (từ kết quả so sánh trọng số chuẩn hoá hai mô hình). Do
đó, các chỉ số trong mô hình tới hạn cho thấy dữ liệu nghiên cứu phù hợp với thị trường
và hiện tượng sai lệch phương sai phương pháp chung không phải là trở ngại đáng lo trong mô hình.
4.5. Kiểm định mô hình nghiên cứu
4.5.1. Kiểm định mô hình nghiên cứu lý thuyết
Trước tiên, luận án thực hiện phân tích SEM bằng ước lượng ML để kiểm định giả thuyết. Thứ hai, thực hiện ước lượng Bootstrap để đánh giá mức độ ổn định mô hình và các độ tin cậy thang đo.
Mô hình phân tích SEM cho kết quả có bậc tự do 510, CMIN = 718,047, P = 0,000. Tuy nhiên, các chỉ số thu thập dữ liệu thu thập như CMIN/df = 1,048, GFI = 0,913, TLI
=0,964, CFI = 0,967, RMSEA = 0,031, PCLOSE = 1,000 thể hiện được mức độ tương thích với mô hình.
Các tham số ước lượng được trình bày tại Bảng 4.7 thể hiện các mối quan hệ tác động, tất cả cá giá trị p thỏa điều kiện bé hơn 0,05 (độ tin cậy 95%). Kết quả chứng tỏ các thang đo đều đạt giá trị về mặt lý thuyết do mỗi thang đo lường có mối quan hệ với các thang đo lường khác theo như đã đề xuất trong các giả thuyết nghiên cứu. Biến EM và EPL có mối quan hệ tương quan mạnh nhất với ML = 0,57, mối quan hệ CD và IM với ML = 0,381, mối quan hệ CD và EM với ML = 0,330…(Bảng 4.7)
Bảng 4.7. Kết quả kiểm định mối quan hệ trực tiếp giữa các khái niệm
ML | UE | S.E. | C.R. | P | Kết luận | |
CD EM | 0,330 | 0,400 | 0,069 | 5,765 | 0,001 | Ủng hộ |
CD IM | 0,381 | 0,244 | 0,038 | 6,355 | 0,001 | Ủng hộ |
HD EM | 0,134 | 0,190 | 0,080 | 2,388 | 0,017 | Ủng hộ |
HD IM | 0,160 | 0,120 | 0,043 | 2,789 | 0,005 | Ủng hộ |
CD EPR | 0,129 | 0,113 | 0,055 | 2,047 | 0,041 | Ủng hộ |
EM EPL | 0,570 | 0,540 | 0,055 | 9,882 | 0,001 | Ủng hộ |
EM EPR | 0,208 | 0,150 | 0,042 | 3,553 | 0,001 | Ủng hộ |
HD EPL | 0,235 | 0,317 | 0,068 | 4,627 | 0,001 | Ủng hộ |
IM EPL | 0,233 | 0,418 | 0,091 | 4,601 | 0,001 | Ủng hộ |
IM EPR | 0,219 | 0,300 | 0,085 | 3,515 | 0,001 | Ủng hộ |