Kết quả đánh giá cho thấy các thang đo đạt yêu cầu khá tốt, các hệ số Cronbach’s
alpha đạt từ 0,746 đến 0,859, tương quan biếntổng(itemtotal correlation) đạt thấp nhất
từ 0,427 trở
lên. Trong thang đo EPL, việc loại biến EPL7 sẽ làm tăng độ
tin cậy từ
0,859 lên 0,871. Tuy nhiên, tác giả giữ lại để xem xét thêm trong việc đánh giá thang đo bằng CFA. Bước tiếp theo sẽ thực hiện phướng pháp EFA.
4.2.2. Đánh giá thang đo bằng phân tích EFA
Trong phân tích EFA, phương pháp trích PAF (principal axis factoring PAF) với phép quay không vuông góc (Promax) được sử dụng. Đây là phương pháp mô hình nhân tố chung (Common Factor Model CFM) thường được sử dụng trong việc đánh giá các thang đo lường vì phương pháp này phản ảnh cấu trúc dữ liệu chính xác hơn (Nguyễn Đình Thọ, 2013, trang 409; Gerbing và Anderson, 1988). Số lượng các nhân tố rút trích được xác định ở nhân tố có hệ số Eigenvalue tối thiểu bằng 1, tổng phương sai trích đạt từ 50% trở lên (Nguyễn Đình Thọ và Nguyễn Thị Mai Trang, 2011).
Điều kiện tiến hành phân tích EFA khi hệ số KMO phải nhỏ hơn 1 và lớn hơn 0,5; trường hợp KMO 0,9 là rất tốt; nếu KMO 0,8 là tốt; KMO 0,7 chấp nhận được; KMO 0,6 là tạm được; KMO 0,5 là xấu; KMO 0,5 không thể chấp nhận khi phân tích EFA. Kiểm định Barrtlett được dùng để kiểm định mối quan hệ các biến với điều kiện giá trị p nhỏ hơn mức ý nghĩa 5% thì các biến mới có mối quan hệ tương quan. Hệ số tải nhân tố (factor loading) đạt từ 0,5 trở lên sẽ được giữ lại để thực hiện việc phân tích các bước tiếp theo (Nguyễn Đình Thọ, 2013, trang 400 424).
4.2.2.1. Thang đo các thành phần yêu cầu công việc
Kết quả phân tích EFA cho thấy KMO = 0,86, kiểm định Barrtlett với giá trị Sig = 0,000 < 0,05 nên hai yếu tố CD và HD có mối quan hệ tương quan nhau, đây là cơ sở để xem xét phân tích các bước tiếp theo của EFA. Trong phân tích EFA có hai yếu tố được rút trích tại điểm dừng có hệ số Eigenvalues = 2,697. Tuy nhiên, tổng phương sai trích được 49,319% (các biến tham gia trong mô hình có khả năng giải thích được 49,319%) < 50%, các tải nhân tố đạt trên 0,6, riêng tải nhân tố HD5 đạt 0,536. Khi tách ra chạy riêng EFA từng yếu tố riêng thì CD đạt 50,36%, HD đạt 47,724%. Nguyên nhân tổng phương sai trích được giảm dưới 50% là do hệ số tải nhân tố biến HD5 ở mức 0,545.
Khi loại biến HD5, chạy dữ liệu EFA lại cho hai yếu tố của JD có tổng phương sai
106
trích đạt 50,36%, KMO = 0,891, Sig = 0,000. Mặc dù tổng phương sai trích nhỏ hơn 50%
nhưng các điều kiện khác thỏa yêu cầu, do đó tác giả sẽ giữ lại biến HD5 để xem xét trong việc phân tích nhân tố khẳng định CFA, nếu HD5 không đạt sẽ loại. Như vậy số biến được giữ lại tiếp tục trong quá trình đánh giá thang đo thành phần JD vẫn còn đủ 11 biến.
4.2.2.2. Thang đo các thành phần động lực làm việc
Phân tích EFA thang đo động lực làm việc gồm IM, EM (INTE và IDENT). Kết quả hệ số KMO = 0,851, kiểm định Barrtlett với giá trị Sig = 0,000 nhỏ hơn 0,05. Điểm dừng ở yếu tố thứ hai có hệ số Eigenvalues = 1,823. Tổng phương sai trích được 53,312% > 50%. Như vậy sau khi phân tích EFA vẫn còn đủ 9 biến tạo thành, hai yếu tố gồm điều chỉnh định danh và điều chỉnh hợp nhất gom lại thành một yếu tố, yếu tố này gọi là EM
(vì hai thành phần yếu tố này thuộc EM mang tính tự chủ), các hệ số tải nhân tố đạt trên 0,6.
Hai thành phần điều chỉnh định danh và điều chỉnh hợp nhất được đặt tên EM
(autonomous Extrinsic Motivatiton). Việc đặt tên biến mới trong nghiên cứu này dựa vào việc đặt biến mới của Ryan và Deci (2020) trong thời gian gần đây. Hai ông cho rằng cả IM và các dạng EM được chuyển hóa tốt vào bên trong (wellinternalization) hay gọi là tự chủ (autonomous) dự báo theo hướng kết quả tích cực theo trình độ và bối cảnh văn hóa khác nhau. EM chia sẻ với IM về chất lượng công việc có ý chí nỗ lực cao, nhưng có sự khác biệt ở đây là IM lại dựa vào sự yêu thích và thích thú. Mọi người thực hiện các hành vi công việc bởi vì họ thấy yêu thích và hoặc thậm chí đó là niềm vui, ngược lại các động lực điều chỉnh định danh và tích hợp dựa trên nhận thức giá trị con người xem các hoạt động công việc là đáng giá, ngay cả khi công việc không thú vị.
Một số nghiên cứu trước đây cũng đặt tên EM gồm hai thành phần IDENT và INTE như nghiên cứu của Mitchell và cộng sự (2020) cho rằng khác với EM dưới dạng kiểm soát làm giảm sự tự chủ và năng lực nhân viên, EM dưới dạng chuyển hóa vào nhân viên (cảm nhận giá trị cá nhân) sẽ hỗ trợ nhân viên thỏa mãn về tâm lý, IM và ý định hành vi. Cho và Yang (2018) nghiên cứu yếu tố chính trị tổ chức ảnh hưởng đến tâm lý và động lực nhân viên cũng dựa vào động lực làm việc của nhân viên phân thành 4 loại động lực gồm thiếu động lực (amotivation), động lực ngoại sinh bị kiểm soát (controlled extrinsic
motivation), EM và IM. Trong đó, điều chỉnh định danh và điều chỉnh hợp nhất được đặt
tên động lực ngoại sinh (EM). Ngoài ra, Gagné và Deci (2005) cho rằng các thang đo
thành phần của động lực thể hiện tính liên tục có thể sử dụng riêng lẻ dùng để ước
lượng các kết quả hoặc có thể được kết hợp đại số để tạo thành chỉ số tự chủ mang tính tương đối. Theo kinh nghiệm nghiên cứu gần đây Howard, Gagné và Bureau (2017) đã chứng minh điều chỉnh hợp nhất không phân biệt từ điều chỉnh định danh và / hoặc IM do mối tương quan giữa các yếu tố này quá cao. Do đó, kết quả gộp biến này cũng phù hợp với nhận định trên.
4.2.2.3. Thang đo các thành phần hành vi khai thác và khám phá
Thực hiện nhóm 12 biến thang đo hành vi cá nhân vào quá trình phân tích EFA có kết quả hệ số KMO = 0,853, kiểm định Barrtlett với giá trị Sig = 0,000 < 0,05. Phân tích rút trích được hai yếu tố trong đó yếu tố thứ hai dừng lại với hệ số Eigenvalues = 2,662. Tổng phương sai trích được 50,558% > 50%. Các tải nhân tố đều đạt trên 0,5. Tuy nhiên, hệ số tải nhân tố EPL7 có hệ số tải dưới 0,5 nên loại khỏi thang đo EPL. Phân tích EFA lại cho thấy các điều kiện đều thỏa với KMO = 0,843, sig = 0,000 < 0,05, tổng phương sai trích đạt 53,184%, các hệ số tải nhân tố đạt trên 0,6. Như vậy, kết quả phân tích EFA thang đo hành vi cá nhân trích ra được hai yếu tố với 11 biến trong đó 5 biến thuộc thang đo EPR, 6 biến thuộc thang đo EPL.
4.2.2.4. Thang đo hiệu quả công việc nhân viên
Kết quả phân tích EFA thang đo PERF của nhân viên được trích thành 1 nhân tố có hệ số KMO = 0,77, kiểm định Barrtlett với giá trị Sig = 0,000 < 0,05. Điểm dừng ở yếu tố thứ nhất có hệ số Eigenvalue = 2,644. Tổng phương sai trích được 55,450% > 50%. Như vậy sau khi phân tích nhân tố EFA vẫn còn đủ 4 biến có các hệ số tải nhân tố đều đạt
trên 0,6.
4.2.2.5. Thang đo tính tích cực của nhân viên
Phân tích EFA thang đo POS cho kết quả hệ số KMO = 0,846, kiểm định Barrtlett với giá trị Sig = 0,000 > 0,05. Kết quả cho thấy chỉ có một yếu tố được rút trích tại điểm
dừng có hệ số Eigenvalue = 3,018. Tổng phương sai trích được 50,913% > 50%. Như
vậy, sau khi phân tích EFA còn đủ 5 biến có các tải nhân tố đều đạt trên 0,6.
108
4.3. Phân tích nhân tố khẳng định CFA
4.3.1. Phương pháp phân tích nhân tố khẳng định CFA
Phương pháp phân tích CFA trong mô hình SEM có nhiều
ưu điểm hơn so với
phương pháp truyền thống như phân tích EFA, đa khái niệmđa phương pháp (MultiTrait
– MultiMethod – MTMM) (Nguyễn Đình Thọ và Nguyễn Thị Mai Trang, 2011). Việc sử dụng CFA giúp xác định được các thang đo lường các khái niệm và đo lường mối quan hệ giữa khái niệm từ các cấu trúc lý thuyết khác để giảm các sai lệch trong quá trình đo lường. Ngoài ra, việc kiểm định mức độ hội tụ và phân biệt của thang đo trong CFA tiến hành đơn giản hơn so với phương pháp MTMM (Nguyễn Đình Thọ và Nguyễn Thị Mai
Trang, 2011).
Luận án này không sử dụng các biến tiềm ẩn mới với kích thước mẫu đủ lớn nên không chọn công cụ PLS – SEM, do đó việc lựa chọn SEM là phù hợp. Hơn nữa, các thang đo được kế thừa từ các nghiên cứu trước và được kiểm chứng trong thực tế, có độ tin cậy cao, mô hình nghiên cứu có nhiều mối quan hệ ảnh hưởng nên cần phải đánh giá mức độ phù hợp tổng thể của mô hình nên việc lựa chọn phần mềm AMOS phân tích kết quả là phù hợp với luận án. Ngoài ra, mô hình SEM còn thể hiện tính ưu việt hơn so với mô hình truyền thống trước đó bởi vì SEM tính được sai số đo lường.
Nghiên cứu SEM còn giúp đo lường các khái niệm tiềm ẩn, các khái niệm này có thể được đo lường riêng lẻ hoặc cùng phối hợp đo lường với các khái niệm khác trong mô hình lý thuyết. Với những ưu điểm của CFA trong phân tích SEM dùng kiểm định giả thuyết trong mô hình so với phương pháp phân tích thông tin thế hệ thứ nhất (hồi quy đa biến, EFA, phương sai, hồi quy logistic...) (Fornell và Larcker, 1981). Vì thế, hiện nay các nghiên cứu trong tiếp thị hay hành vi tổ chức được sử dụng rất rộng rãi. Do đó, phép phân tích SEM được các học giả gọi là thế hệ phân tích thứ hai (Nguyễn Đình Thọ và Nguyễn Thị Mai Trang, 2011).
Phân tích CFA giúp làm rõ các nội dung đo lường tính đơn hướng
(Unidimentionality), độ
tin cậy tổng hợp
thang đo (CR) và giá trị
hội tụ (Convergent
validity), giá trị
phân biệt
(Disciminant validity), giá trị
liên hệ
lý thuyết
(Nomological
validity). Các giá trị này được xem xét trong quá trình kiểm định mô hình đo lường tới
hạn. Giá trị liên hệ lý thuyết được sẽ được phân tích trong mô hình lý thuyết (Anderson
và Gerbing, 1988).
Kết quả từ
dữ liệu phân tích cho thấy đa số độ
nhọn (Kurtoses) và độ
nghiêng
(Skewness) thuôc [ 1, + 1] (xem phụ lục 7.1) nên ước lượng ML trong luận án này là thích hợp. Ngoài ra các giá trị phân phối chuẩn của các biến đo lường lệch rất ít so với mức phân phối chuẩn của các biến.
4.3.1.1. Đo lường tính đơn hướng
Để đánh giá dữ liệu phù hợp mô hình thì cần xem xét tính đơn hướng của các biến đô lường cùng một khái niệm. Thang đo đạt tính đơn hướng khi không có hiện tượng tương quan giữa các sai số trong cùng một khái niệm (Nguyễn Đình Thọ, 2013).
Luận án thực hiện đánh giá sự phù hợp giữa dữ liệu thu thập nhân viên thị trường bất động sản với mô hình đề xuất nghiên cứu thông qua các chỉ tiêu Chibình phương (Chisquare), chỉ số CFI, chỉ số TLI và chỉ số RMSEA, chỉ số PCLOSE.
Mô hình tương thích khi giá trị p của Chibình phương thường yêu cầu phải lớn hơn 0,05. Tuy nhiên, điều kiện này có nhược điểm là nó phụ thuộc vào cỡ mẫu. Khi cỡ mẫu n càng lớn thì giá trị thống kê Chibình phương càng lớn. Điều này sẽ làm giảm đi sự phù hợp mô hình hay chưa đánh giá được mức tương thích của mô hình khi kích thước mẫu thu thập lớn.
Các chỉ số giá trị CFI, GFI, TLI, PCLOSE thay đổi ở mức giá trị 0 đến giá trị 1. Các chỉ số này được cho là tốt khi tiến gần đến 1. Theo Hu và Bentler (1999), các chỉ số này trong phân tích cần đạt một số yêu câu được thể hiện trong Bảng 3.9. Tuy nhiên, nhiều tác giả cho rằng một số trường hợp GFI < 0,9 vẫn có thể dùng được (Hair và cộng sự,
2010), RMSEA nhỏ hơn hoặc bằng
0,08 cũng có thể kết luận
mô hình và dữ liệu thị
trường phù hợp (Nguyễn Đình Thọ và Nguyễn Thị Mai Trang, 2011).
4.3.1.2. Đánh giá độ tin cậy và giá trị hội tụ
Theo Hair và cộng sự (2010), CR được tính dựa trên độ tin cậy của thang đo với điều kiện CR đạt trên 0,7. Thang đo thoả điều kiện đạt giá trị hội tụ khi tổng phương sai trích hay phương sai trung bình được trích (AVE) của mỗi khái niệm đạt điều kiện CR >
0,5.
110
Theo Gerbing và Anderson (1988), thang đo đạt giá trị hội tụ khi các trọng số chuẩn
hóa lớn hơn 0,5 và có ý nghĩa (p < 0,05).
Trong phân tích CFA cần quan tâm đến độ tin cậy của tập hợp các biến đo lường
một khái niệm (nhân tố). Thông thường
các nghiên cứu
ứng dụng hay
dùng Cronbach
alpha, vì hệ số này đo lường tính nhất quán nội tại xuyên suốt trong tập biến trong một thang đo. Trong luận án này tác giả sử dụng các chỉ số đánh giá độ tin cậy hỗn hợp CR, trọng số chuẩn hóa để đánh giá độ tin cậy và giá trị hội tụ AVE (cân nhắc trong quá trình loại biến) (Hair và cộng sự, 2010; Gerbing và Anderson, 1988).
4.3.1.3. Đánh giá giá trị phân biệt của thang đo
Việc đo lường độ phân biệt là rất cần thiết trong quá trình phân biệt các khái niệm trong mô hình (Hair và cộng sự, 2010). Thông thường, giá trị phân biệt được đánh giá qua hai mức độ: Mức độ thứ nhất, kiểm định mức độ phân biệt các thành phần của một khái niệm (within construct); mức độ thứ hai, kiểm tra giá trị phân biệt các khái niệm bằng mô hình đo lường tới hạn, trong đó các khái niệm trong mô hình được biểu diễn các mối
quan hệ với nhau mà không bị ràng buộc. Các tiêu chuẩn cho là phù hợp của dữ liệu
nghiên cứu được thể hiện tại bảng 3.9.
Giá trị phân biệt đạt được khi mối tương quan giữa hai thành phần của một khái niệm hoặc giữa các khái niệm khác 1. Khi đó, mô hình đạt được độ phù hợp với dữ liệu thu thập từ thị trường. Theo Hair và cộng sự (2010) thì các chỉ số thang đo có giá trị phân biệt khi MSV nhỏ hơn AVE và chỉ số MaxR(H) (Square root of AVE) lớn hơn giá trị tương quan chính trong thang đo đó (innerconstruct correlations). Luận án này sử dụng các hệ số đánh giá mức độ phân biệt theo Hair và cộng sự (2010) và theo hệ số tương quan giữa các khái niệm.
4.3.2. Kết quả kiểm định thang đo bằng phân tích CFA
Phân tích CFA được thực hiện dựa trên các khái niệm JD gồm CD và HD, động lực làm việc bao gồm IM và EM (INTE và IDENT), hành vi cá nhân gồm EPL và EPR, PERF và cuối cùng là POS. Các chỉ tiêu được tiến hành đánh giá lần lượt bao gồm tính đơn hướng, độ phân biệt, giá trị hội tụ và giá trị liên hệ lý thuyết sẽ đánh giá trong mô hình tới hạn (Anderson và Gerbing, 1988). Công cụ dùng phân tích CFA và SEM dùng phần mềm SPSS 24.0, AMOS 24.0.
4.3.2.1. Thang đo các thành phần yêu cầu công việc
Thang đo JD gồm hai thành phần HD với 5 biến và CD với 6 biến.
Mô hình ban đầu có 43 bậc tự do, Chibình phương = 67,033, p = 0,011. Tuy vậy, các tiêu chí khác cho thấy mô hình JD phù hợp với dữ liệu của thị trường: CMIN/df = 1,559 < 3, GFI = 0, 973, TLI = 0,981, CFI = 0,985 và RMSEA = 0,036. Các khái niệm đạt được tính đơn hướng do không có tương quan giữa các sai số.
Các trọng số chuẩn hóa của các biến đều đạt yêu cầu ( ), thấp nhất là biến HD5 có trọng số chuẩn hóa bằng 0,546. Tất cả các giá trị p đều có ý nghĩa (p < 0,001). Ngoài ra,
các giá trị của thang đo thỏa điều kiện. Tuy nhiên, phương sai trung bình được trích
không thỏa điều kiện (AVE < 0,5). Hệ số AVE của HD chưa đạt do biến HD5 có chỉ số
chuẩn hóa biến nhỏ nhất bằng 0,546. Kết quả mô hình CFA loại HD5 khỏi mô hình
(Hình 4.1), tất cả các hệ số hồi quy chuẩn hóa lớn hơn 0,5 và có ý nghĩa.
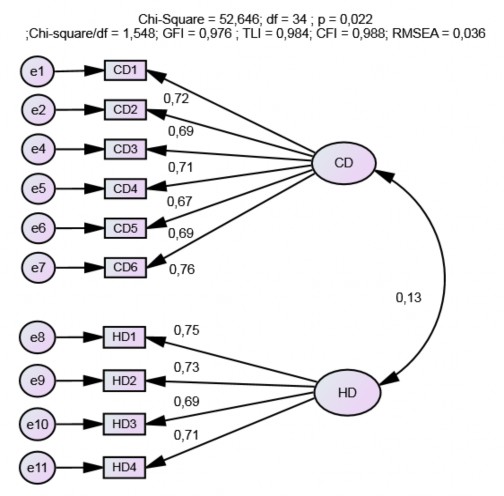
Hình 4.1. Kết quả CFA (chuẩn hoá) thang đo yêu cầu công việc
112
Nguồn: Trích xuất từ việc xử lý dữ liệu
Mô hình loại biến HD5 có 34 bậc tự do, Chibình phương (CMIN) = 52,646, p =
0,022. Tuy vậy, các tiêu chí khác cho thấy mô hình JD phù hợp với dữ liệu của thị
trường: CMIN/df = 1,548 < 3, GFI = 0, 976, TLI = 0,984, CFI = 0,988 và RMSEA = 0,036.
Các khái niệm thành phần không có mối quan hệ tương quan giữa các sai số (error), do đó các khái niệm đạt được tính đơn hướng.
Tất cả các chỉ số CR của HD và CD đều lớn hơn 0,7. Chỉ số AVE của CD (50,4%) và HD (52,3%) đều > 50%. Vì thế, các biến dùng để đo lường hai thành phần CD và HD đạt giá trị hội tụ (Bảng 4.4).
Bảng 4.4. Các giá trị thang đo yêu cầu công việc thách thức và yêu cầu công việc cản trở
CR | AVE | MSV | MaxR(H) | Tương quan trong thang đo | ||||
CD | HD | |||||||
CD | 0,859 | 0,504 | 0,017 | 0,861 | 0,710 | |||
HD | 0,814 | 0,523 | 0,017 | 0,816 | 0,132* | 0,723 | ||
Có thể bạn quan tâm!
-
 Quy Trình Thực Hiện Nghiên Cứu Sơ Bộ Định Tính
Quy Trình Thực Hiện Nghiên Cứu Sơ Bộ Định Tính -
 Thang Đo Hành Vi Khám Phá Và Hành Vi Khai Thác
Thang Đo Hành Vi Khám Phá Và Hành Vi Khai Thác -
 Đặc Điểm Mẫu Khảo Sát Nghiên Cứu Định Lượng Sơ Bộ
Đặc Điểm Mẫu Khảo Sát Nghiên Cứu Định Lượng Sơ Bộ -
 Kết Quả Cfa (Chuẩn Hoá) Các Thang Đo Động Lực Làm Việc
Kết Quả Cfa (Chuẩn Hoá) Các Thang Đo Động Lực Làm Việc -
 Kiểm Định Vai Trò Điều Tiết Của Tính Tích Cực Lên Mối Quan Hệ Yêu Cầu Công Việc
Kiểm Định Vai Trò Điều Tiết Của Tính Tích Cực Lên Mối Quan Hệ Yêu Cầu Công Việc -
 Mối Quan Hệ Trực Tiếp Giữa Các Khái Niệm Trong Mô Hình Khả Biến Đối Với Nhóm Nam Và Nữ
Mối Quan Hệ Trực Tiếp Giữa Các Khái Niệm Trong Mô Hình Khả Biến Đối Với Nhóm Nam Và Nữ
Xem toàn bộ 205 trang tài liệu này.
Nguồn: Từ dữ liệu phân tích CFA
Ghi chú: ***: Sig. < 0,001; **: Sig. < 0,01; *: Sig.< 0,05; MaxR(H): Square rooot of AVE Mô hình sau khi loại HD5 cho thấy HD và CD có hệ số tương quan và các sai số
chuẩn của các biến nhỏ hơn 1. Ngoài ra, hệ số MSV < AVE và các hệ số MaxR(H) (HD
= 0,816; CD = 0,861) đều lớn hơn hệ số tương quan của chính thang đo HD (0,723) và CD (0,710). Do đó, khái niệm HD và CD đạt giá trị phân biệt.
4.3.2.2. Thang đo các thành phần hành vi cá nhân
Thang đo hành vi cá nhân bao gồm hai thành phần EPR và EPL. Trong đó, EPL gồm 6 biến và EPR gồm 5 biến.
Mô hình CFA xử
lý lần thứ
nhất có 53 bậc tự
do, Chibình phương (CMIN) =
234,816 với giá trị p = 0,000, CMIN/df = 4,430, TLI = 0,896, RMSEA = 0,089. Các tiêu chí phù hợp gồm GFI = 0, 907, CFI = 0,917. Kiểm tra các chỉ số biến thì EPL7 có trọng số chuẩn hoá nhỏ hơn 0,5 nên EPL7 loại và mô hình CFA được chạy lại với kết quả điều chỉnh được cải thiện như hình 4.2.