Danh mục các bảng
Bảng 2.1: Cơ sở dữ liệu giao dịch book store. 13
Bảng 2.2: Cơ sở dữ liệu giao dịch của bảng 2.1 được mã hóa 13
Bảng 2.3: Cơ sở dữ liệu giao dịch theo chiều dọc dùng bit vector 14
Bảng 2.4: Tìm cids của FCS của itemset có DSBV: {1, {12, 129}} 20
Bảng 2.5: Khai thác minimal FCS từ cấu trúc DSBV 21
Bảng 3.1: Bộ dữ liệu chess 47
Bảng 3.2: Kết quả thực nghiệm thu được với bộ dữ liệu Chess 47
Bảng 3.3: Bộ dữ liệu Mushroom 49
Bảng 3.4: Kết quả thực nghiệm thu được với bộ dữ liệu Mushroom 49
Bảng 3.5: Bộ dữ liệu Pumsb 51
Bảng 3.6: Kết quả thực nghiệm thu được với bộ dữ liệu Pumsb 51
Bảng 3.7: Bộ dữ liệu Retail 52
Bảng 3.8: Kết quả thực nghiệm thu được với bộ dữ liệu Retail 53
Bảng 3.9: Bộ dữ liệu T10I4D100K 54
Bảng 3.10: Kết quả thực nghiệm thu được với bộ dữ liệu T10I4D100K 54
Danh mục các hình vẽ, đồ thị
Hình 2.1: Dynamic superset bit vector 18
Hình 2.2: Giao 2 DSBVs 22
Hình 2.3: Hội 2 DSBVs 23
Hình 3.1: Lưu đồ thuật toán 31
Hình 3.2: Cây khai thác FCIs 33
Hình 3.3: Khai thác Dàn FCIs 36
Hình 3.4: biểu đồ so sánh thời gian thực thi của bộ dữ liệu Chess 48
Hình 3.5: biểu đồ so sánh bộ nhớ chiếm dụng của bộ dữ liệu Chess 48
Hình 3.6: Biểu đồ so sánh thời gian thực thi của bộ dữ liệu Mushroom 50
Hình 3.7: Biểu đồ so sánh bộ nhớ chiếm dụng của bộ dữ liệu Mushroom 50
Hình 3.8: Biểu đồ so sánh thời gian thực thi của bộ dữ liệu Pumsb 51
Hình 3.9: Biểu đồ so sánh bộ nhớ chiếm dụng của bộ dữ liệu Pumsb 52
Hình 3.10: Biểu đồ so sánh thời gian thực thi của bộ dữ liệu Retail 53
Hình 3.11: Biểu đồ so sánh bộ nhớ chiếm dụng của bộ dữ liệu Retail 54
Hình 3.11: Biểu đồ so sánh thời gian thực thi của bộ dữ liệu T10I4D100K 55
Hình 3.12: Biểu đồ so sánh bộ nhớ chiếm dụng của bộ dữ liệu T10I4D100K 55
Danh mục từ viết tắt
Từ viết tắt | Từ viết đầy đủ | Ý nghĩa, diễn giải | |
1 | BVCL | Bit-Vector oriented frequent Closed itemset Lattice | Tên thuật toán |
2 | CID | Closed itemset identifier | ID của tập đóng |
3 | CSDL | Cơ sở dữ liệu | Tập các giao dịch chứa tập hạng mục |
4 | DBV | Dynamic bit vector | Vector bit động. |
5 | DSBV | Dynamic superset bit vector | Vector bit động lưu ID của tập bao nó |
6 | FCS | Frequent close supeset | Tập bao phổ biến đóng |
7 | FCI | Frequent close itemeset | Tập phổ biến đóng |
8 | MG | Minimal generator | Tập sinh |
9 | NARs | Non- redundant association rules | các luật kết hợp không dư thừa |
10 | nsLSB | Non-zero least significant bit | vị trí bit 1 gần nhất trong byte tính từ phải qua |
11 | nSL | Non Subsuming list | Danh sách tập không subsume |
12 | OLAP | Online Analysis Processing | Phân tích dữ liệu trực tuyến. |
13 | OLTP | Online Transaction Processing | Phân tích dữ liệu giao tác trực tuyến. |
14 | SL | Subsuming list | Danh sách tập subsume |
15 | TID | Transaction identifiers | Mã (định danh) giao dịch, giao tác. |
Có thể bạn quan tâm!
-

 Khai thác dàn tập phổ biến đóng sử dụng cấu trúc DSBV - 1
Khai thác dàn tập phổ biến đóng sử dụng cấu trúc DSBV - 1 -
 Phương Pháp Nghiên Cứu Và Đối Tượng Nghiên Cứu
Phương Pháp Nghiên Cứu Và Đối Tượng Nghiên Cứu -
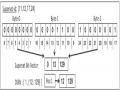 Cơ Sở Dữ Liệu Giao Dịch Theo Chiều Dọc Dùng Bit Vector.
Cơ Sở Dữ Liệu Giao Dịch Theo Chiều Dọc Dùng Bit Vector. -
 Đề Xuất Thuật Toán Khai Thác Dàn Các Tập Phổ Biến Đóng Và Cải Tiến
Đề Xuất Thuật Toán Khai Thác Dàn Các Tập Phổ Biến Đóng Và Cải Tiến
Xem toàn bộ 72 trang tài liệu này.

LỜI NÓI ĐẦU
1. Mở đầu
Ngày nay, khi khả năng lưu trữ của máy tính tăng cao, cùng với sự gia tăng
khủng khiếp lượng dữ liệu trên mạng intenet. Ngày càng xuất hiện nhiều cơ sở dữ liệu với lượng dữ liệu lớn và phức tạp, lượng dữ liệu trong các cơ sở dữ liệu này quá lớn để có thể phân tích, trích xuất theo phương pháp thống kê truyền thống. Điều này đòi hỏi phải có phương pháp, kỹ thuật để khai thác, trích xuất thông tin trong các tập dữ liệu đồ sộ này.
Data mining hay khai thác dữ liệu là quá trình khám phá các thông tin, các mối quan hệ có giá trị ẩn chứa bên trong lượng dữ liệu lớn. Quá trình khai thác dữ liệu kết hợp các công cụ từ thống kê và trí tuệ nhân tạo (như mạng nơ ron và học máy) với quản lý cơ sở dữ liệu để phân tích các tập dữ liệu lớn. Khai thác dữ liệu được sử dụng rộng rãi trong kinh doanh (bảo hiểm, ngân hàng, bán lẻ), nghiên cứu khoa học (thiên văn học, y học) và an ninh chính phủ (phát hiện bọn tội phạm và khủng bố). Khai thác dữ liệu được xem là phương pháp mà đơn vị Able Danger của Quân đội Mỹ đã dùng để xác định kẻ đứng đầu cuộc tấn công ngày 11 tháng 9, Mohamed Atta, và ba kẻ tấn công ngày 11 tháng 9 khác là các thành viên bị nghi ngờ thuộc lực lượng al Qaeda hoạt động ở Mỹ hơn một năm trước cuộc tấn công.
Tìm những mẫu quan trọng và hữu ích trong 1 tập dữ liệu lớn và phân tích những quan hệ trong các mẫu này là 1 phần trọng yếu của data mining. Tất cả những mẫu này có thể được sử dụng để phát sinh tập luật kết hợp cần thiết. Tập luật kết hợp mô tả sự đồng xuất hiện và mối quan hệ giữa các mẫu. Những luật này có thể rất hữu ích cho nhiều tổ chức thương mại. Các luật kết hợp có thể đóng vai trò quan trọng trong mối liên quan đến việc mua hàng ở siêu thị. Phân tích các đặc điểm của hàng hóa giao dịch, chúng ta có thể dự đoán thói quen về ăn uống của khách hàng, về tình trạng tài chính và nhu cầu tiêu dùng của các sản phẩm. Nó cũng giúp y khoa nghiên cứu tương tác của một số thuốc với nhau. Vì thế, việc
phát triển các thuật toán để khai thác các mối quan hệ giữa các mẫu luôn là lĩnh vực nghiên cứu được quan tâm.
Những mẫu mà thường xuyên xãy ra giao dịch trong database được gọi là các mẫu phổ biến. Tuy nhiên, những mẫu phổ biến thường rất lớn và chứa nhiều mẫu dư thừa trong tập dữ liệu, chẳng hạng như về sinh học, viễn thông, điều tra dân số. Những tập các mẫu phổ biến đóng là giải pháp để loại bỏ các mẫu dư thừa từ những tập mẫu phổ biến. Một tập phổ biến được gọi là phổ biến đóng nếu như không có tập cha (bao nó) có cùng độ phổ biến.
Sự lặp lại giữa các quan hệ Tập Cha – Tập Con trong các tập đóng làm tăng thêm nhiều chi phí trong việc phát sinh các luật kết hợp không dư thừa (NARs). Tuy nhiên cũng thấy rằng, các luật kết hợp không dư thừa có thể được phát sinh hiệu quả hơn từ cấu trúc dàn của các tập đóng so với việc khai thác trực tiếp từ tập đóng [4]. Cấu trúc dàn sắp xếp tất cả các tập đóng theo quan hệ cha – con [18]. Dàn mô tả sự phụ thuộc giữa các tập đóng dẫn đến việc khai thác nhanh các luật kết hợp không dư thừa.
Mục tiêu của luận văn này hướng tới cách giải quyết bài toán: Từ cơ sở dữ liệu có sẵn, làm sao để khai thác toàn bộ các tập phổ biến đóng, quan hệ cha – con giữa các tập này, cải tiến giải thuật khai thác dàn các tập phổ biến đóng để việc khai thác tập luật kết hợp sau này được dễ dàng và hiệu quả hơn.
Dựa trên một số công trình nghiên cứu về lĩnh vực khai thác tập phổ biến đóng trong những năm gần đây, đặc biệt là dựa trên công trình nghiên cứu năm 2017: “An efficient dynamic superset bit-vector approach for mining frequent closed itemsets and their lattice structure”[1] của Tahrima Hashem và cộng sự. Từ đó luận văn sẽ tập trung nghiên cứu:
Khai thác tập phổ biến đóng: tìm hiểu về tập phổ biến, tập phổ biến đóng, và các ứng dụng của khai thác tập phổ biến đóng và dàn, phát biểu
bài toán và các phương pháp khai thác dàn tập phổ biến đóng nỗi bật đã được nghiên cứu trước đó.
Khai thác dàn tập phổ biến đóng: trình bày về dàn các tập phổ biến đóng, cấu trúc DSBV.
Cải tiến thuật toán: đề xuất phương pháp khai thác song song tập sinh và dàn của tập phổ biến đóng.
Kết quả thự nghiệm trên thuật toán BVCL cải tiến, so sánh với thuật toán gốc và các phương pháp trước đây.
2. Bố cục đề tài
Luận văn trình bày trong 03 chương:
- Chương 1: Giới thiệu tổng quan về khai thác dữ liệu, ý nghĩa của khai thác dữ liệu, ứng dụng của khai thác dữ liệu, khai thác tập phổ biến đóng, nêu rõ phạm vi, mục tiêu, phương pháp nghiên cứu, ý nghĩa khoa học và thực tiễn, các kết quả dự kiến với đóng góp của luận văn là đề xuất một cải thiện khai thác dàn các tập phổ biến đóng của thuật toán BVCL.
- Chương 2: Trình bày cơ sở lý thuyết của các khái niệm, kỹ thuật khai thác dàn các tập phổ biến đóng, tập sinh và các giai đoạn tổ chức bài toán. Mô tả và phân tích ưu điểm khuyết điểm của các thuật toán đã có trước đó. Từ đó, hình thành hướng đi mới cho thuật toán cải tiến khai thác dàn tập phổ biến đóng.
- Chương 3: Đề xuất thuật toán cải tiến khai thác dàn các tập phổ biến đóng, chỉ rõ các bước cải tiến mới so với thuật toán BVCL, so sánh kết quả thực nghiệm của thuật toán mới với thuật toán gốc cũng như với các thuật toán đã có.
- Tiếp theo, là phần Kết luận và Hướng phát triển, nêu tóm gọn về kết quả đạt được cũng như các hướng nghiên cứu, ứng dụng có thể mở rộng và phát triển của luận văn trong tương lai.
Cuối cùng, phần Tài liệu tham khảo, liệt kê danh sách các tài liệu tham khảo sử dụng trong luận văn.
1. Khai thác dữ liệu
Chương 1: TỔNG QUAN
Khối lượng dữ liệu khổng lồ được thu thập trên toàn thế giới, tăng lên hàng terabyte (hoặc petabyte) dữ liệu mỗi ngày từ nhiều nguồn dữ liệu: dữ liệu về kinh tế, khoa học kỹ thuật, y tế, mạng internet, mạng xã hội, các hệ thống truyền dữ liệu tự động và từ các khía cạnh khác trong cuộc sống hàng ngày của con người.
Từ những năm đầu thập kỷ 60 đến cuối những năm 1980, công nghệ sưu tập, lưu trữ và xử lý, phân tích dữ liệu đã tiến bộ vượt bậc trước sự phát triển mạnh mẽ của xu hướng tin học hóa trên toàn thế giới. Ban đầu sự thu thập và phát sinh cơ sở dữ liệu, chỉ là truy xuất file thô sơ (đầu những năm 1960). Sau những năm 1970 đến đầu 1980s, phát triển sang hệ thống quản lý CSDL, trong đó đã có công cụ phân tích dữ liệu giao dịch trực tuyến - OLTP. Từ giữa đến cuối những năm 1980, phát triển hệ thống cơ sở dữ liệu nâng cao và hệ thống phân tích CSDL nâng cao, triển khai kèm theo đó là các công cụ nổi bật dành cho phân tích dữ liệu nâng cao. Trong đó có sự ra đời của kiến trúc kho dữ liệu mới đi kèm kỹ thuật OLAP, có khả năng khai thác dữ liệu đa chiều, phân tích dữ liệu sâu, xem thông tin với nhiều góc độ khác nhau.
Tuy nhiên khối dữ liệu khổng lồ được thu thập và lưu trữ trong nhiều kho chứa dữ liệu lớn không ngừng tăng nhanh. Việc hiểu hết các thông tin, cũng như rút trích ra các kiến thức ẩn đã nhúng trong khối dữ liệu khổng lồ cực lớn này mà không có công cụ mạnh mẽ hỗ trợ là vượt xa khả năng của con người. Điều này đòi hỏi cần có một công cụ mạnh mẽ, linh hoạt hơn để đáp ứng nhu cầu khám phá các mẫu dữ liệu đặc biệt, quan trọng, nhằm rút trích ra các thông tin, kiến thức có giá trị từ khối dữ liệu khổng lồ.
Cuối những năm 1980, khai thác dữ liệu ra đời, đánh dấu sự tiến triển mới của công nghệ thông tin. Các chức năng của khai thác dữ liệu bao gồm: mô tả đặc tính và phân biệt dữ liệu, khai thác các mẫu (chuỗi) phổ biến, sự kết hợp và tương quan, phân lớp và hồi quy, phân tích gom cụm, và nhận dạng ngoại lệ.
Trong tương lai, nếu phát sinh thêm nhiều kiểu dữ liệu mới, ứng dụng mới và nhu cầu phân tích dữ liệu mới thì việc xuất hiện thêm các thao tác khai thác dữ liệu mới là điều có thể dự đoán được.
2. Ứng dụng của khai thác dữ liệu
Khai phá dữ liệu đã và đang được ứng dụng rộng rãi trong rất nhiều lĩnh vực và hiện nay đã có rất nhiều công cụ thương mại và phi thương mại triển khai các nhiệm vụ của khai phá dữ liệu.
Sau đây là một số lĩnh vực mà khai phá dữ liệu đang được ứng dụng rộng rãi:
Phân tích dữ liệu tài chính.
Công nghiệp bán lẻ.
Công nghiệp viễn thông.
Phân tích dữ liệu sinh học.
Phát hiện xâm nhập.
Một số ứng dụng trong khoa học.
Phân tích dữ liệu tài chính
Dữ liệu tài chính trong ngân hàng và trong ngành tài chính thường đáng tin cậy và có chất lượng cao, tạo điều kiện cho khai phá dữ liệu. Dưới đây là một số ứng dụng điển hình trong khai phá dữ liệu tài chính:
Dự đoán khả năng vay và thanh toán của khách hàng, phân tích chính sách tín dụng đối với khách hàng.
Phân tích hành vi khách hàng (vay, gửi tiền).
Phân loại và phân nhóm khách hàng mục tiêu cho tiếp thị tài chính.
Phát hiện các hoạt động rửa tiền và tội phạm tài chính khác.
Công nghiệp bán lẻ
Khai phá dữ liệu có vai trò rất quan trọng trong ngành công nghiệp bán lẻ, do dữ liệu thu thập từ lĩnh vực này rất lớn từ doanh số bán hàng, lịch sử mua hàng của khách hàng, vận chuyển hàng hóa, tiêu thụ và dịch vụ. Điều tự nhiên là khối lượng dữ