liệu từ ngành công nghiệp này sẽ tiếp tục tăng lên nhanh chóng và dễ dàng thu thập bởi tính sẵn có trên môi trường Web. Ứng dụng khai phá dữ liệu trong ngành công nghiệp bán lẻ nhằm xây dựng mô hình giúp xác định xu hướng mua hàng của khách hàng, giúp doanh nghiệp cải thiện chất lượng sản phẩm dịch vụ nhằm nâng cao sự hài lòng của khách hàng và giữ chân khách hàng tốt. Dưới đây là một số ứng dụng của khai phá dữ liệu trong ngành công nghiệp bán lẻ:
Khai phá dữ liệu trên kho dữ liệu khách hàng.
Phân tích đa chiều trên kho dữ liệu khách hàng về doanh số bán hàng, khách hàng, sản phẩm, thời gian và khu vực.
Phân tích hiệu quả của các chiến dịch bán hàng, Marketing.
Quản trị mối quan hệ khách hàng.
Giới thiệu và tư vấn sản phẩm phù hợp cho khách hàng.
Công nghiệp viễn thông
Công nghiệp viễn thông là một trong những ngành công nghiệp mới nổi, cung cấp nhiều dịch vụ như trên điện thoại di động, internet, truyền hình ảnh... Do sự phát triển mạnh của công nghệ máy tính và mạng máy tính, viễn thông đang phát triển với tốc độ rất nhanh. Đây là lý do tại sao khai phá dữ liệu trở nên rất quan trọng trong lĩnh vực này.
Khai phá dữ liệu trong ngành công nghiệp viễn thông giúp xác định các mô hình viễn thông, phát hiện các hoạt động gian lận trong viễn thông, sử dụng tốt hơn nguồn tài nguyên và cải thiện chất lượng dịch vụ viễn thông. Dưới đây là một số ứng dụng của khai phá dữ liệu trong ngành công nghiệp này:
Phân tích dữ liệu đa chiều viễn thông.
Xây dựng các mô hình phát hiện gian lận.
Phát hiện bất thường trong giao dịch viễn thông.
Phân tích hành vi sử dụng dịch vụ viễn thông của khách hàng.
Sử dụng các công cụ trực quan trong phân tích dữ liệu viễn thông.
Phân tích dữ liệu sinh học
Khai phá dữ liệu sinh học là một phần rất quan trọng của lĩnh vực Tin - Sinh Học. Sau đây là một số ứng dụng của khai phá dữ liệu ứng dụng trong sinh học:
Lập chỉ mục, tìm kiếm tương tự, bất thường trong cơ sở dữ liệu Gen.
Xây dựng mô hình khai phá các mạng di truyền và cấu trúc của Gen, protein.
Xây dựng các công cụ trực quan trong phân tích dữ liệu di truyền.
Phát hiện xâm nhập bất hợp pháp
Xâm nhập bất hợp pháp là những hành động đe dọa tính toàn vẹn, bảo mật và tính sẵn sàng của tài nguyên mạng. Trong thế giới của kết nối, bảo mật đã trở thành vấn đề lớn đối với tồn tại của hệ thống. Với sự phát triển của internet và sự sẵn có của các công cụ, thủ thuật trợ giúp cho xâm nhập và tấn công mạng, yêu cầu kiểm soát truy cập bất hợp pháp là yếu tố rất quan trọng đảm bảo cho sự ổn định của hệ thống.
Dưới đây là một số ứng dụng của khai phá dữ liệu có thể được áp dụng để phát hiện xâm nhập:
- Phát triển các thuật toán khai phá dữ liệu để phát hiện xâm nhập.
- Phân tích kết hợp, tương quan và khác biệt để phát hiện xâm nhập.
- Phân tích dòng dữ liệu để phát hiện bất thường.
3. Khai thác dàn các tập phổ biến đóng
Tìm luật kết hợp từ hàng triệu giao dịch trong nhiều CSDL lớn, hiện tại trở nên khó khăn trong lĩnh vực khai thác dữ liệu. Tập phổ biến và tập phổ biến đóng là chìa khóa quan trọng của việc khai thác các luật kết hợp. Các luật kết hợp có thể được khai thác hiệu quả từ Dàn các tập phổ biến đóng.
Không thừa, chính xác, thời gian và chiếm dụng bộ nhớ là các nhân tố cần được xem xét trong khi phát triển thuật toán để tìm các luật kết hợp hữu ích. Xây dựng dàn tập phổ biến đóng là xây dựng quan hệ cha con (trực tiếp) giữa các tập phổ biến đóng với nhau. Do vậy sẽ tiết kiệm được thời gian khi duyệt dàn để sinh luật.
4. Ý nghĩa khoa học và thực tiễn của đề tài
- Thuật toán BVCL đổi mới hơn so với thuật toán CHARML cũng như các thuật toán duyệt tuần tự tập hạng mục ở những điểm chính sau:
o Cấu trúc DSBV lưu thông tin tập cha ở dạng bit nên việc truyền thông tin cho các tập trong dàn khi gọi đệ qui là nhanh chóng.
o Cách tổ chức 2 danh sách subsume list và non - subsume list làm cho thuật toán bỏ qua khá nhiều bước khi đệ qui với các tập trong subsume list.
- Thuận toán mới cải thiện hiệu suất khai thác dàn các tập phổ biến đóng này góp phần giải quyết vấn đề trong việc khai thác luật kết hợp với nhiều ứng dụng rộng, bao gồm những phân tích về hành vi mua sắm của khách hàng, chuỗi truy xuất web, những thực nghiệm có tính khoa học, điều trị bệnh, ngăn chặn tai họa thiên nhiên và sự hình thành protein…
5. Phương pháp nghiên cứu và đối tượng nghiên cứu
Phương pháp nghiên cứu:
- Phương pháp nghiên cứu tài liệu: dựa vào các tài liệu đã công bố của các nhà nghiên cứu về các thuật toán khai thác tập phổ biến, tập phổ biến đóng, và khai thác Dàn: Apriori-Gen, FP-tree, Charm, CharmL, MG-Charm, DCI- Closed, LCM, DBV-Miner, GENCLOSE, NAFCP. Phân tích cách sử dụng cấu trúc dữ liệu DBV, DSBV cách tổ chức CSDL (ngang hay dọc), cách phát sinh mẫu ứng viên mới, các kỹ thuật khai thác Dàn… và xu hướng phát triển của các thuật toán.
- Phương pháp thực nghiệm: Tiến hành hiện thực và thực nghiệm các phương pháp được đề xuất trong luận văn để xác định tính đúng đắn, khả thi và phát triển so với các phương pháp đã công bố của các tác giả trong và ngoài nước có liên quan đến luận văn.
- Phương pháp thống kê, phân tích dữ liệu: Thống kê, tổng hợp các số liệu trong quá trình thực nghiệm để phân tích, đánh giá từ đó nhận thức, phát hiện, và chọn lọc những ưu điểm để phát huy, tìm cách khắc phục những hạn chế, đồng thời kết hợp những thông tin liên quan đã thu thập được lại thành
một nội dung logic đầy đủ để đề xuất thuật toán mới có thời gian khai thác đồng thời Dàn các tập phổ biến đóng và tập sinh của chúng nhanh hơn và tiết kiệm bộ nhớ hơn (có so sánh kết quả thực nghiệm).
Đối tượng nghiên cứu: Thuật toán BVCL khai thác dàn các tập phổ biến đóng, cấu trúc vectơ bit động - DBV, cấu trúc superset vectơ bit động DSBV dùng để lưu và truyền thông tin của các tập superset, các kỹ thuật ánh xạ, chỉ mục để tăng tốc độ tìm kiếm cho thuật toán.
6. Khó khăn và Thách thức
Cho trước CSDL D và ngưỡng minSup do người dùng đặt ra, phải tìm đầy đủ các tập phổ biến đóng là một thách thức không nhỏ về thời gian do độ phức tạp trong việc khai thác là hàm mũ.
Độ dài của vector bit tăng lên theo số transaction trong CSDL. Làm tốn kém nhiều bộ nhớ. Cấu trúc bit vector động tiết kiệm khá nhiều bộ nhớ đối với CSDL thưa, tuy nhiên, đối với CSDL đặc, việc tiết kiệm không đáng kể. Trên các bộ dữ liệu dùng trong luận văn này, bộ nhớ tiết kiệm hơn 50% so với cấu trúc bit vector tỉnh.
7. Mục tiêu và phạm vi của luận văn
Mục đích cuối cùng của quá trình khai thác tập phổ biến là khai thác tập luật kết hợp và ứng dụng các kết quả vào trong thực tế.
Theo cách khai thác luật kết hợp truyền thống, việc tìm tất cả các luật kết hợp từ CSDL thõa minSup và minConf gặp nhiều bất lợi khi số tập phổ biến lớn. Do đó cần có một phương pháp thích hợp để khai thác với số lượng luật ít hơn nhưng vẫn đảm bảo tích hợp đầy đủ tất cả các luật của phương pháp khai thác truyền thống. Một trong những cách tiếp cận đó là khai thác luật thiết yếu nhất, chỉ lưu lại các luật có vế trái tối tiểu và vế phải tối đại (theo quan hệ cha – con).
Mục tiêu của luận văn là tập trung vào nghiên cứu, phân tích ưu điểm và hạn chế các thuật toán khai thác tập phổ biến đóng, tập phổ biến đóng trên Dàn. Với mong muốn làm giảm thời gian khai thác luật, sử dụng quan hệ cha – con trên Dàn để giảm chi phí xét quan hệ cha – con và vì vậy làm giảm được thời gian khai thác luật.
Qua đó nhận thấy thuật toán BVCL với các cấu trúc dữ liệu DBV, DSBV hiệu quả và mạnh mẻ, phù hợp để nghiên cứu và ứng dụng. Đề xuất tích hợp, cải tiến thuật toán gốc để khai thác đồng thời Dàn tập phổ biến đóng và tập sinh, cần thiết cho công việc khai thác tập luật kết hợp sau này. Cuối cùng, so sánh kết quả thực nghiệm của thuật toán BVCL cải tiến với thuật toán gốc và thuật toán CharmL, MGCharm trên các CSDL tổng hợp và thực tế.
8. Đóng góp của luận văn
Đề tài có cải tiến so với thuật toán gốc của tác giả, bằng cách kết hợp, tối ưu việc khai thác đồng thời tập sinh vào bên trong thuật toán gốc. Thuật toán cải tiến không nhanh hơn thuật toán gốc về phương diện khai thác dàn các tập phổ biến đóng. Tuy nhiên, việc khai thác tập sinh là rất quan trọng trong quá trình khai thác tập luật kết hợp. Nếu thuật toán gốc khai thác riêng rẽ dàn tập phổ biến đóng và tập sinh thì thuật toán mà đề tài cải tiến nhanh và hiệu quả hơn rất nhiều, vấn đề so sánh sẽ được đề cập riêng ở phần so sánh đánh giá.
Chương 2: CƠ SỞ LÝ THUYẾT
1. Khái quát bài toán
D: là các giao dịch trong Database.
Với một tập các giao dịch T = {t1, t2... tn}. Mỗi giao dịch ti (1 ≤ i ≤ n) được xác định bởi khóa được gọi là Tid.
Tidset(X): Một tập các giao dịch chứa tập X.
Itemset(Y): Biễu diễn một tập các Items xuất hiện trong các giao dịch của Tidset (Y).
𝑖=0
𝑇𝑖𝑑𝑠𝑒𝑡(𝑋) = ⋂𝑘 𝑡𝑖𝑑𝑠𝑒𝑡(𝑥𝑖 ) , 𝑣ớ𝑖 {𝑥1, 𝑥2, . . . , 𝑥𝑘} ⊆ 𝐼, I là Itemset
𝐼𝑡𝑒𝑚𝑠𝑒𝑡(𝑌) = ⋂𝑝 𝐼𝑡𝑒𝑚𝑠𝑒𝑡(𝑦 ), 𝑣ớ𝑖 𝑌 = {𝑦1, 𝑦2, . . . , 𝑦𝑝} ⊆ 𝑇 , T là Tidset
𝑗=0 𝑖
Và: I = {i1, i2… im}
Số giao dịch trong tidset (X) tương ứng với độ hỗ trợ của X được biểu diễn bởi sup (X).
Một Itemset X được gọi là phổ biến nếu Sup(X) ≥ Minsup.
Độ hỗ trợ (Support) của luật kết hợp X =>Y là tần suất của giao dịch chứa tất cả các items trong cả hai tập X và Y. Ví dụ, support của luật X =>Y là 5% có nghĩa là 5% các giao dịch X và Y được mua cùng nhau.
Minsup: là độ hỗ trợ nhỏ nhất phải xác định trước khi sinh luật kết hợp.
Một tập phổ biến X được gọi là tập phổ biến đóng nếu không có tập nào bao nó có cùng độ phổ biến. Hay nói cách khác. Không tồn tại tập phổ biến X’, X con X’, mà sup (X) = sup (X’).
Xét X và Y là 2 tập phổ biến đóng.
- Y được gọi là bao (frequent closed superset (FCS)) X nếu X ⊂ Y.
- Y là bao tối tiểu (minimal closed superset) của X nếu không tồn tại tập phổ biến đóng Z mà X ⊂ Z ⊂ Y.
- Tập G được gọi là tập sinh (Generator) của tập đóng X, nếu và chỉ nếu G ⊆ X
và Sup(G) = Sup(X).
Nếu Y là bao tối tiểu của tập đóng X thì node Y được xem là con node X, và có 1 cạnh từ X Y.
Một luật kết hợp (AR) được biểu diễn X ⇒ (Y − X): X, Y là 2 tập phổ biến và X ⊂ Y.
Khai thác Dàn các tập phổ biến đóng Frequent closed itemset lattice (FCIL) là sắp xếp các Nodes của các tập phổ biến đóng, kết nối các Nodes theo cặp trong Dàn và tạo nên quan hệ Cha – Con. Ta cũng đồng thời khai thác các tập sinh tương ứng với các tập phổ biến đóng trong Dàn.
2. Hướng tiếp cận khai thác tập phổ biến đóng
Một số lượng lớn các công trình nghiên cứu tập trung vào việc phát triển các thuật toán để khai thác các tập phổ biến đóng. Hầu hết các kỹ thuật này có thể được phân thành bốn loại tùy thuộc vào chiến lược riêng.
- Đầu tiên là chiến lược thử nghiệm và phát triển theo APRIORI-GEN [19]. Thủ tục kiểm tra tính đóng của 1 tập hạng mục.
- Thứ 2 là sử dụng cấu trúc dữ liệu theo FP-tree [20].
- Thứ 3 là dùng kỹ thuật tìm kiếm lai. CHARM [9] là một ví dụ điển hình cho cách tiếp cận này, nó khai thác không chỉ item - space mà còn tid - space.
- Thứ 4 là DCI-Closed [21] và LCM [22], khác với ba loại nêu trên. Cả hai cách tiếp cận này đều vượt qua vấn đề chi phí kiểm tra để loại bỏ việc phát sinh các bản sao của các tập đóng. Chúng duyệt không gian tìm kiếm theo chiều sâu và phát sinh tập phổ biến đóng mới bằng cách mở rộng các tập đóng được khai thác trước đó. Hơn nữa, chúng không đòi hỏi bộ nhớ lưu trữ cho các tập đóng đã được phát hiện trước đó. LCM [22] áp dụng sự xuất hiện và phiên bản lai của các kỹ thuật diffset [9] đối với tính toán độ phổ biến và tính đóng dựa trên các đặc tính của bộ dữ liệu.
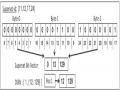
Các thuật toán khai thác FCI có thể được chia thành hai loại cơ bản phụ thuộc vào cách biểu diễn cơ sở dữ liệu, horizontal (tid × itemset) và vertical (item × tidset). Quan sát từ các tài liệu hiện có [23] cho thấy rằng các thuật toán sử dụng biểu diễn CSDL theo chiều dọc tốt hơn các phương pháp sử dụng biểu diễn theo chiều ngang. Bảng 2.2 là một biễu diễn dạng mã hóa của Bảng 2.1 trong đó các Item được biễu diễn bằng các chữ cái, và được biễu diễn theo chiều ngang. ECLAT [10]. Zaki đã giới thiệu cơ sở dữ liệu theo chiều dọc.
Bảng 2.1: Cơ sở dữ liệu giao dịch book store.
Itemset | |
t1 | Algorithms, Logic Design, Data Mining, Programming in C, Networking |
t2 | Logic Design, Compiler, Programming in C, Microprocessor |
t3 | Algorithms, Logic Design, Data Mining, Networking, Programming in C |
t4 | Algorithms, Logic Design, Compiler, Programming in C, Microprocessor, Networking |
t5 | Algorithms, Logic Design, Compiler, Data Mining, Programming in C, Microprocessor, Networking |
t6 | Compiler, Data Mining, Microprocessor, Networking, Human Computer Interaction, Logic Design |
Có thể bạn quan tâm!
-

 Khai thác dàn tập phổ biến đóng sử dụng cấu trúc DSBV - 1
Khai thác dàn tập phổ biến đóng sử dụng cấu trúc DSBV - 1 -
 Khai thác dàn tập phổ biến đóng sử dụng cấu trúc DSBV - 2
Khai thác dàn tập phổ biến đóng sử dụng cấu trúc DSBV - 2 -
 Cơ Sở Dữ Liệu Giao Dịch Theo Chiều Dọc Dùng Bit Vector.
Cơ Sở Dữ Liệu Giao Dịch Theo Chiều Dọc Dùng Bit Vector. -
 Đề Xuất Thuật Toán Khai Thác Dàn Các Tập Phổ Biến Đóng Và Cải Tiến
Đề Xuất Thuật Toán Khai Thác Dàn Các Tập Phổ Biến Đóng Và Cải Tiến -
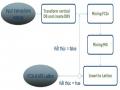 Đặc Tả Và Phân Tích Thuật Toán Input: Csdl Giao Dịch: Db, Minsup.
Đặc Tả Và Phân Tích Thuật Toán Input: Csdl Giao Dịch: Db, Minsup.
Xem toàn bộ 72 trang tài liệu này.

Bảng 2.2: Cơ sở dữ liệu giao dịch của bảng 2.1 được mã hóa.
Itemset | |
t1 | A, L, D, P, N |
t2 | L, C, P, M |
t3 | A, L, D, N, P |
t4 | A, L, C, P, M, N |
t5 | A, L, C, D, P, M, N |
t6 | C, D, M, N, H, L |
BitTableFI [24] thay thế tidset với bit - vector, nơi mỗi bit tương ứng với một
tid.