Số nút lá của cây là 10, kích thước cây (bao gồm gốc, nút quyết định, nút lá) là
19. Biến d3 đóng vai trò quan trọng trong phân nhánh, tiếp đó là biến a2, m2, e2. Quy tắc phân nhánh cụ thể tác giả trình bày trong hình 4.4.
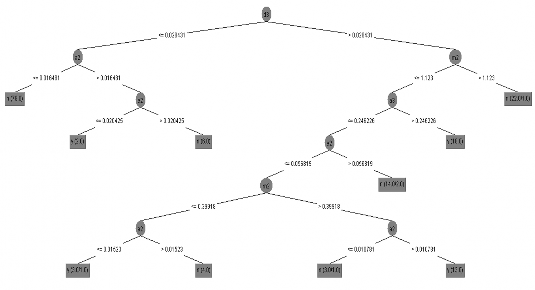
Hình 4.4: Cây quyết định
Nguồn: Tính toán của tác giả
Mô hình DT khá trực quan giúp người sử dụng hình dung được quá trình đi đến kết quả và quá trình phân nhóm tối đa chỉ qua 6 bước.
Xét các quan sát với các thông tin:
Năm | e2 | d3 | m2 | a2 | a3 | |
Mã 25 | 2015 | 0.0161 | 0.0196 | 0.2170 | 0.0089 | 0.2517 |
Mã 5 | 2011 | 0.0696 | 0.0607 | 0.8199 | 0.0118 | 0.1926 |
Có thể bạn quan tâm!
-

 Thống Kê Mô Tả Của Các Biến Đầu Vào/đầu Ra Mô Hình Dea
Thống Kê Mô Tả Của Các Biến Đầu Vào/đầu Ra Mô Hình Dea -
 Các Biến Nghiên Cứu Và Hệ Số Tương Quan Với Biến Phụ Thuộc
Các Biến Nghiên Cứu Và Hệ Số Tương Quan Với Biến Phụ Thuộc -
 Hệ Số Chặn Của Các Ngân Hàng
Hệ Số Chặn Của Các Ngân Hàng -
 Bảng So Sánh Kết Quả Xếp Loại
Bảng So Sánh Kết Quả Xếp Loại -
 Xây dựng mô hình cảnh báo nguy cơ vỡ nợ đối với các ngân hàng thương mại cổ phần Việt Nam - 18
Xây dựng mô hình cảnh báo nguy cơ vỡ nợ đối với các ngân hàng thương mại cổ phần Việt Nam - 18 -
 Tỷ Lệ Lãi Cận Biên Của Các Nhtmcp Việt Nam 2010- 2015
Tỷ Lệ Lãi Cận Biên Của Các Nhtmcp Việt Nam 2010- 2015
Xem toàn bộ 168 trang tài liệu này.
Với quan sát mã 25 năm 2015, ta tuần tự theo các bước sau:
Bước 1: Kiểm tra giá trị của biến d3 và so sánh với giá trị cắt là 0.0284; do d3 = 0.0196 < 0.0284 ta chuyển sang bước 2
Bước 2: Kiểm tra giá trị của biến a2 và so sánh với giá trị 0.01648
do a2 = 0.0089 < 0.01648 nên quan sát sẽ được dán nhãn N, tức nguy cơ thấp. Với quan sát mã 5, năm 2011
Bước 1: Kiểm tra giá trị của biến d3 và so sánh với giá trị cắt là 0.0284; do d3 = 0.0607 > 0.0284 ta chuyển sang bước 2
Bước 2: Kiểm tra giá trị của biến m2 và so sánh với giá trị 1.123 do m2 = 0.8199 < 1.123 ta chuyển sang bước 3
Bước 3: Kiểm tra giá trị của biến a3 và so sánh với giá trị 0.246 do a3 = 0.196 < 0.246 ta chuyển sang bước 4
Bước 4: Kiểm tra giá trị của biến e2 và so sánh với giá trị 0.0568
do e2 = 0.0696 > 0.0568 nên quan sát sẽ được dán nhãn N, tức nguy cơ thấp.
Với bộ dữ liệu 114 quan sát (bộ dữ liệu sử dụng trong ước lượng mô hình Logit) cây quyết định có kết quả phân loại trong bảng 4.24.
Bảng 4.24: Hiệu suất mô hình cây quyết định
Dự báo | ||||
Y | % đúng | |||
0 | 1 | |||
Y | 0 | 74 | 1 | 98.67% |
1 | 4 | 35 | 89.74% | |
95.61% | ||||
Nguồn: Tính toán của tác giả
Trong 75 quan sát thuộc nhóm Y = 0, mô hình DT phân nhóm đúng 74 quan sát đạt tỷ lệ 98.67%, trong 39 quan sát có Y = 1, mô hình phân nhóm đúng 35 quan sát chiếm tỷ lệ 89.74 %, tổng kết lại mô hình phân nhóm đúng 109 quan sát trong tổng số 114 quan sát như vậy hiệu suất đạt 95.61%. Như vậy, mô hình cây quyết định có hiệu suất phân loại cao nhất trong ba mô hình. Việc phân nhóm NH là trực quan, dễ áp dụng.
Kết luận chương 4
Chương 4, tác giả thực nghiệm xây dựng mô hình cảnh báo nguy cơ vỡ nợ cho các NHTMCP Việt Nam, cụ thể:
+ Tính toán chỉ tiêu nợ xấu, ước lượng hiệu quả hoạt động, phân loại hiệu quả hoạt động các NHTMCP từ đó xác định nguy cơ cho các NHTMCP trong mẫu.
+ Xây dựng 39 chỉ tiêu tài chính, phân thành 7 nhóm tương tự các nhóm nhân tố của mô hình CAMELS sử dụng trong cảnh báo nguy cơ vỡ nợ ngân hàng.
+ Thực nghiệm mô hình Logit với dữ liệu mảng để cảnh báo nguy cơ vỡ nợ cho các NHTMCP. Mô hình Logit, tác động cố định đã chỉ ra các chỉ tiêu tác động trực tiếp tới nguy cơ vỡ nợ các ngân hàng, các chỉ tiêu đó là: Tốc độ tăng trưởng GDP, lãi cận biên; nợ quá hạn/ tổng nợ phải trả, các khoản cho vay thuần/ tiền gửi khách hàng.
+ Thực nghiệm mô hình mạng nơron và cây quyết định cảnh báo vỡ nợ các NHTMCP, kết quả cho thấy hai mô hình này có hiệu suất phân loại cao hơn mô hình Logit. Mô hình cây quyết định chỉ ra 5 chỉ tiêu sử dụng trong cảnh báo nguy cơ vỡ nợ các ngân hàng.
CHƯƠNG 5
KẾT LUẬN VÀ KIẾN NGHỊ CHÍNH SÁCH
5.1. Các kết quả đạt được
a) Kết quả mô hình Logit dữ liệu mảng tác động cố định
ln( p ) + $*RGDP $*d3 $
* e11 $* l3
1 p
Cụ thể,
i 1 2 3 4
ln( p ) 1.2955*RGDP 1.0346 * d3 2.014 * e11 3.0769 * l3
1 pi
+ Từ tập 42 biến ban đầu và sau đó là 18 biến, cuối cùng mô hình Logit còn lại 4 biến số (RGDP, d3, e11, l3). Luận án đã tiến hành kiểm định việc lựa chọn mô hình tác động cố định và mô hình tác động ngẫu nhiên và kết quả là mô hình tác động cố định được lựa chọn. Như vậy tác động của các biến số RGDP, d3, e11, l3 đến nguy cơ vỡ nợ các ngân hàng là tác động cố định. Điều này có nghĩa là các biến số RGDP, d3, e11, l3 tác động đến nguy cơ vỡ nợ các ngân hàng là giống nhau về xu thế, cố định trong thời gian nghiên cứu và tương tự nhau giữa các ngân hàng.
1
+ Theo kết quả ước lượng của mô hình biến RGDP có hệ số $ 1 .2 9 nhỏ hơn không, biến RGDP tác động ngược chiều tới nguy cơ vỡ nợ và như vậy kết quả mô hình Logit đã minh chứng tác động của điều kiện kinh tế vĩ mô, cụ thể là tốc độ tăng trưởng tổng sản phẩm quốc dân tới nguy cơ vỡ nợ của các NHTMCP Việt Nam.
2
+ Biến d3 = Nợ quá hạn /tổng nợ phải trả, có hệ số trong mô hình $ 1 . 0 3 lớn
hơn không. Các ngân hàng phân loại nợ thành 5 nhóm trong đó các khoản nợ thuộc nhóm 2 đến nhóm 5 là nợ quá hạn, khi một khoản cho vay bị quá hạn theo một nghĩa nào đó ngân hàng cũng sẽ bị quá hạn số tiền đó đối với người cho ngân hàng vay, do vậy chỉ số nợ quá hạn/ tổng nợ phải trả là một chỉ số phản ánh mức độ thâm hụt của ngân hàng, chỉ số này càng lớn càng khiến ngân hàng mất an toàn. Khả năng vỡ nợ chịu ảnh hưởng dương của chỉ tiêu này.
+ Theo kết quả của mô hình biến e11- Lãi cận biên, có hệ số $32.014 , biến e11 có ảnh hưởng ngược chiều đến mức nguy cơ vỡ nợ. Trong chương 2, tác giả cho rằng một ngân hàng hoạt động tốt sẽ phải huy động được các nguồn vốn vay giá rẻ đồng thời cũng sử dụng vốn vay đó để cho vay, khoản chênh lệch giữa lãi vay và lãi suất cho vay thể hiện qua chỉ tiêu e11, biến e11 có ảnh hưởng ngược chiều đến mức nguy cơ vỡ nợ. Kết quả ước lượng hệ số của biến e11 có dấu âm đúng như kỳ vọng.
+ Biến l3 = Các khoản cho vay thuần/ tiền gửi của khách hàng, có hệ số
$4 3 . 0 7 . Tỷ lệ l3 đánh giá tương quan giữa phần vốn cho vay với phần tiền gửi của khách, tỷ lệ này cao cho thấy mức độ rủi ro cao cho tiền gửi của khách hàng. Một sự gia tăng của tỷ lệ này nghĩa là ‘tấm đệm’ của ngân hàng để chống lại nguy cơ rút tiền gửi đột ngột đang bị giảm đi. Tỷ lệ l3 cũng phản ánh mức độ thanh khoản của ngân hàng, giá trị của chỉ tiêu này lớn khả năng thanh khoản của ngân hàng kém. Mặt khác, tỷ lệ này tăng lên chứng tỏ ngân hàng tăng cường hoạt động sử dụng vốn để tăng thêm thu nhập từ lãi và như vậy ngân hàng cần gia tăng hệ số CAR hơn để phòng rủi ro. Kết quả nghiên cứu cũng cho thấy khả năng vỡ nợ của ngân hàng chịu ảnh hưởng dương của biến l3.
10 21 6
22 14 19 7
+ Các hệ số chặn i của các ngân hàng trong mô hình Logit đã được tính và nêu trong bảng 4.17. Các hệ số này đo lường sự khác biệt, tính đặc thù của các NH có ảnh hưởng đến vỡ nợ, theo kết quả đó bốn ngân hàng có mã là 22, 14, 19, 7 có hệ số chặn lớn: 10.265 , 9.879 , 8.206 , 8.135 , hàm chứa rủi ro vỡ nợ cao hơn, các ngân hàng với mã 10, 21, 6 có hệ số chặn 3.189 , 2.73 , 0.982 nhỏ nhất hàm chứa nguy cơ vỡ nợ thấp hơn trong cùng điều kiện của các biến số.
b)Tác động biên của các biến đến xác suất vỡ nợ p
+ Căn cứ vào độ lớn của các hệ số ước lượng trong mô hình Logit tác giả tính toán tác động biên của các biến tới xác suất vỡ nợ và trình bày kết quả trong bảng 5.1.
Bảng 5.1: Tác động biên của các biến đến xác suất vỡ nợ p
Tác động biên của các biến đến xác suất p | ||||
Mức xác suất p ban đầu | RGDP thay đổi 1% | d3 thay đổi 1% | e11 thay đổi 1% | l3 thay đổi 1% |
10% | - 0.07 | 0.093 | - 0.085 | 0.0027 |
15% | - 0.104 | 0.132 | - 0.127 | 0.0038 |
20% | - 0.136 | 0.165 | - 0.168 | 0.0047 |
30% | - 0.195 | 0.217 | - 0.246 | 0.0061 |
40% | - 0.246 | 0.248 | - 0.318 | 0.0069 |
50% | - 0.285 | 0.257 | - 0.382 | 0.0071 |
16.2% | - 0.112 | 0.14 | - 0.137 | 0.004 |
Nguồn: Tính toán của tác giả
Chẳng hạn, khi cho các biến trong mô hình Logit nhận giá trị ứng với giá trị trung bình của các biến tác giả tính được xác suất vỡ nợ là p = 0.162 (16.2%). Nếu biến RGDP tăng 1% trong khi các biến khác giữ nguyên thì theo tính toán ở bảng 5.1 xác suất p khi đó giảm 0.112, nếu biến d3 tăng 1% thì xác suất p sẽ lại tăng 0.14, tương tự như vậy khi cho biến e11, l3 thay đổi thì xác suất p lần lượt thay đổi là -0.137 và 0.004. Các quan sát khác với các thông tin cụ thể có thể căn cứ vào mô hình để ước lượng ra xác suất vỡ nợ thay đổi.
c)Tổng kết, so sánh kết quả phân loại của các mô hình
Với bộ dữ liệu 114 quan sát (Bộ dữ liệu sử dụng trong ước lượng mô hình Logit)
Ba mô hình (LA với dữ liệu mảng tác động cố định, mô hình ANN, mô hình DT) cùng phân loại đúng 93 quan sát, số quan sát bị phân nhóm sai bởi cả ba mô hình chỉ là 1 quan sát, số quan sát có sự sai khác giữa các mô hình là 20.
Bảng 5.2: Tổng hợp các quan sát có kết quả dự báo khác nhau trong các mô hình
Mã NH | Năm | Mô hình LA | Mô hình ANN | Mô hình DT | |
1 | 1 | 2012 | S | Đ | Đ |
2 | 1 | 2014 | S | Đ | Đ |
3 | 3 | 2012 | S | Đ | Đ |
4 | 6 | 2010 | S | S | Đ |
5 | 18 | 2012 | S | Đ | Đ |
6 | 18 | 2014 | S | Đ | Đ |
7 | 32 | 2013 | S | Đ | Đ |
8 | 21 | 2013 | S | Đ | Đ |
9 | 26 | 2013 | S | Đ | Đ |
10 | 31 | 2012 | S | Đ | Đ |
11 | 31 | 2013 | S | Đ | Đ |
12 | 30 | 2012 | S | Đ | Đ |
13 | 22 | 2012 | Đ | S | Đ |
14 | 26 | 2011 | S | Đ | S |
15 | 5 | 2011 | Đ | S | S |
Mã NH | Năm | Mô hình LA | Mô hình ANN | Mô hình DT | |
16 | 25 | 2012 | Đ | Đ | S |
17 | 22 | 2011 | Đ | S | S |
18 | 4 | 2013 | Đ | S | Đ |
19 | 5 | 2013 | Đ | S | Đ |
20 | 21 | 2011 | Đ | S | Đ |
Nguồn: Tính toán của tác giả
Hiệu suất của ba mô hình được tổng kết trong bảng 5.3.
Bảng 5.3: Hiệu suất của ba mô hình ở mẫu 114 quan sát
Logit với dữ liệu mảng | Mạng nơron | Cây quyết định | |
Hiệu suất | 87.71% | 92.98% | 95.61% |
Sai lầm loại I | 20.52% | 17.94% | 10.26% |
Nguồn: Tính toán của tác giả
Ngoài việc so sánh hiệu suất của các mô hình, người ta thường chú ý đến tỷ lệ sai lầm loại I, sai lầm loại II. Trong đó sai lầm loại I là một NH có nguy cơ vỡ nợ cao nhưng được dự báo là nguy cơ vỡ nợ thấp và ngược lại đối với sai lầm loại II: NH có nguy cơ vỡ nợ thấp nhưng lại được dự báo có nguy cơ vỡ nợ cao. Đối với mô hình dự báo, sai lầm loại I sẽ được quan tâm hơn do hậu quả của nó thường nghiêm trọng hơn. Bảng 5.3 cũng cho thấy mô hình mạng nơron, cây quyết định có tỷ lệ sai lầm loại I thấp hơn mô hình Logit.
Với bộ dữ liệu 49 quan sát thuộc 10 ngân hàng có đầu ra không đổi (Y = 0 trong các năm quan sát): mạng nơ ron và mô hình cây quyết định đều phân nhóm đúng 49 quan sát đạt hiệu suất 100%.
Với bộ dữ liệu của năm 2015 gồm 25 quan sát: Kết quả hiệu suất ba mô hình
được nêu trong bảng 5.4.
Bảng 5.4: Hiệu suất các mô hình
Logit | Mạng nơron | Cây quyết định | |
Hiệu suất | 96% | 96% | 100% |
Nguồn: Tính toán của tác giả
Như vậy trong các bộ dữ liệu khác nhau mô hình mạng nơron, cây quyết định đều có hiệu suất phân loại cao hơn mô hình Logit. Đặc biệt số các quan sát bị phân nhóm sai bởi tất cả các mô hình là rất ít, 1 quan sát do đó việc kết hợp cùng lúc cả ba mô hình sẽ cho hiệu suất phân nhóm chính xác cao. Việc kết hợp cùng lúc ba mô hình sẽ càng cần thiết với những quan sát mà kết quả phân nhóm khi sử dụng mô hình Logit ở ngưỡng tiếp giáp. Trong bảng 5.2, trong số 13 quan sát bị phân nhóm sai bởi mô hình Logit tác giả đã kiểm tra kết quả phân nhóm của hai mô hình ANN, DT thì hai mô hình mạng nơ ron và cây quyết định đã phân nhóm đúng 11 quan sát.
5.2. Phân loại các ngân hàng thương mại cổ phần
Sử dụng kết quả tính xác suất vỡ nợ trong mô hình Logit dữ liệu mảng ở mục 4.2 tác giả mới chỉ xếp loại các NHTMCP thành hai nhóm, để giúp cảnh báo vỡ nợ tốt hơn tác giả luận án sẽ xếp các ngân hàng thành nhiều nhóm nguy cơ vỡ nợ hơn. Về vấn đề xếp hạng và phân nhóm các doanh nghiệp, trên thế giới có ba công ty xếp hạng uy tín (Moody’s, S&P, KMV), các tổ chức xếp hạng này đều có lưu trữ dữ liệu thực nghiệm mối liên hệ giữa xác suất vỡ nợ với một mức xếp hạng.
Bảng 5.5: Xác suất vỡ nợ và các mức XHTD của KMV
Moody’s | PD (%) | |
>=AA | >=Aa2 | Từ 0.02 đến 0.04 |
AA/A | A1 | Từ 0.04 đến 0.1 |
A/BBB+ | Baa1 | Từ 0.1 đến 0.19 |
BBB+/BBB- | Baa3 | Từ 0.19 đến 0.4 |
BBB-/BB | Ba1 | Từ 0.4 đến 0.72 |
BB/BB- | Ba3 | Từ 0.72 đến 1.01 |
BB-/B+ | B1 | Từ 1.01 đến 1.43 |
B+/B | B2 | Từ 1.43 đến 2.02 |
B/B- | B3 | Từ 2.02 đến 3.45 |
Nguồn: Công ty KMV
Tuy nhiên tác giả bước đầu xếp loại các NHTMCP thành 4 nhóm do đó để có cơ sở xếp loại các NHTMCP tác giả xem xét quyết định 06/2008/QĐ-NHNN ra ngày