4.3.3 Tổng hợp các nhân tố và biến quan sát sau khi EFA
Tóm lại, sau khi tác giả tiến hành phân tích EFA cho 5 biến độc lập và 1 biến phụ thuộc, thì kết quả số nhân tố và các biến còn giữ lại cho nghiên cứu là 5 biến độc lập (gồm 21 biến quan sát, trong đó có 6 biến quan sát do tác giả đề xuất, 15 biến được tác giả kế thừa thang đo HEdPERF hiệu chỉnh 2006) và 1 nhân tố phụ thuộc (gồm 3 biến quan sát do tác giả kế thừa của Đặng Thị Hồ Thủy 2018) được trình bày qua bảng sau (chi tiết xem Phụ lục 11).
Bảng 4.6: Tổng hợp các nhân tố và biến quan sát sau khi EFA
Tên nhân tố | Biến quan sát | Số lượng biến quan sát | |
1 | Học thuật | Aca1, Aca2, Aca4 | 3 |
2 | Phi học thuật | N – Aca1, N- Aca2, N- Aca3, N- Aca4 | 4 |
3 | Danh tiếng | Rep3, Rep4, Rep5 | 3 |
4 | Tiếp cận | Acc1, Acc2, Acc3, Acc4, Acc5, Acc6, Acc7 | 7 |
5 | Chương trình đào tạo | Pro2, Pro3, Pro4, Pro5 | 4 |
6 | Sự hài lòng của sinh viên | Sat1, Sat2, Sat3 | 3 |
Tổng cộng | 24 | ||
Có thể bạn quan tâm!
-

 Kết Quả Kiểm Định Cronbach’S Alpha Các Thang Đo
Kết Quả Kiểm Định Cronbach’S Alpha Các Thang Đo -
 Những Giả Thuyết Cho Mô Hình Nghiên Cứu Chính Thức
Những Giả Thuyết Cho Mô Hình Nghiên Cứu Chính Thức -
 Kết Quả Thống Kê Mô Tả Mẫu Theo Dữ Liệu Trùng Lắp
Kết Quả Thống Kê Mô Tả Mẫu Theo Dữ Liệu Trùng Lắp -
 Kiểm Định Sự Khác Biệt Về Sự Hài Lòng Của Sinh Viên Đối Với Chất Lượng Dịch Vụ Đào Tạo Tại Khoa Du Lịch Trường Đại Học Công Nghiệp Thực
Kiểm Định Sự Khác Biệt Về Sự Hài Lòng Của Sinh Viên Đối Với Chất Lượng Dịch Vụ Đào Tạo Tại Khoa Du Lịch Trường Đại Học Công Nghiệp Thực -
 Một Số Hàm Ý Quản Trị Góp Phần Nâng Cao Sự Hài Lòng Của Sinh Viên Đối Với Chất Lượng Dịch Vụ Đào Tạo Tại Khoa Du Lịch Nói Riêng Và Trường Đại
Một Số Hàm Ý Quản Trị Góp Phần Nâng Cao Sự Hài Lòng Của Sinh Viên Đối Với Chất Lượng Dịch Vụ Đào Tạo Tại Khoa Du Lịch Nói Riêng Và Trường Đại -
 Các nhân tố ảnh hưởng đến sự hài lòng của sinh viên về chất lượng dịch vụ đào tạo tại Khoa Du lịch Trường Đại học Công nghiệp Thực phẩm TP.HCM - 13
Các nhân tố ảnh hưởng đến sự hài lòng của sinh viên về chất lượng dịch vụ đào tạo tại Khoa Du lịch Trường Đại học Công nghiệp Thực phẩm TP.HCM - 13
Xem toàn bộ 179 trang tài liệu này.
(Nguồn: Tác giả tổng hợp)
4.4 Phân tích hồi qui đa biến
4.4.1 Kiểm tra sự tương quan giữa biến độc lập và biến phụ thuộc
Trước khi phân tích hồi qui, ta cần xem xét sự tương quan giữa biến độc lập và biến phụ thuộc (sử dụng tương quan Pearson). Nếu biến độc lập nào có tương quan chặt chẽ với biến phụ thuộc nghĩa là Sig. (2-tailed) < 0,05 thì sẽ được đưa vào chạy hồi qui vì có ý nghĩa thống kê, còn biến nào có Sig. (2-tailed) > 0,05 thì không
đưa vào chạy hồi qui vì không có ý nghĩa thống kê. Kết quả kiểm tra sự tương quan Pearson giữa biến độc lập và biến phụ thuộc được thể hiện ở Phụ lục 12.
Bảng 4.7: Kết quả tương quan giữa biến độc lập và biến phụ thuộc
N | Sự hài lòng của sinh viên về chất lượng dịch vụ đào tạo | ||
Học thuật | Tương quan Pearson | 208 | 0,742** |
Sig. (2-tailed) | 0,000 | ||
Phi học thuật | Tương quan Pearson | 208 | 0,735** |
Sig. (2-tailed) | 0,000 | ||
Danh tiếng | Tương quan Pearson | 208 | 0,496** |
Sig. (2-tailed) | 0,000 | ||
Tiếp cận | Tương quan Pearson | 208 | 0,523** |
Sig. (2-tailed) | 0,000 | ||
Chương trình đào tạo | Tương quan Pearson | 208 | 0,698** |
Sig. (2-tailed) | 0,000 |
(Nguồn: Tác giả xử lý dữ liệu bằng phần mềm SPSS)
Từ kết quả trên cho ta thấy, biến phụ thuộc có mối quan hệ tương quan tuyến tính với 5 biến độc lập ở mức ý nghĩa 0,000 < 0,05 và hệ số tương quan giữa biến phụ thuộc “Sự hài lòng” với biến độc lập “Học thuật” là 0,742; hệ số tương quan giữa biến phụ thuộc với biến độc lập “Phi học thuật” là 0,735; hệ số tương quan giữa biến phụ thuộc với biến độc lập “Danh tiếng” là 0,496; hệ số tương quan giữa biến phụ thuộc với biến độc lập “Tiếp cận” là 0,523; hệ số tương quan giữa biến
phụ thuộc với biến độc lập “Chương trình đào tạo” là 0,698. Như vậy, các nhân tố này được sử dụng để đưa vào để phân tích hồi qui tuyến tính trong phần tiếp theo.
4.4.2 Phân tích hồi qui tuyến tính
Bảng 4.8: Kết quả hệ số hồi qui lần 1
Hệ số hồi qui chưa chuẩn hóa | Hệ số hồi qui đã chuẩn hóa | t (Kiểm định t – Test) | Mức ý nghĩa Sig. | |||
B | Sai số chuẩn | Beta | ||||
1 | Hằng số | -0,162 | 0,172 | -0,944 | 0,346 | |
Học thuật | 0,357 | 0,038 | 0,390 | 9,304 | 0,000 | |
Phi học thuật | 0,310 | 0,039 | 0,343 | 7,920 | 0,000 | |
Danh tiếng | 0,064 | 0,040 | 0,067 | 1,593 | 0,113 | |
Tiếp cận | 0,071 | 0,047 | 0,063 | 1,492 | 0,137 | |
Chương trình đào tạo | 0,233 | 0,046 | 0,239 | 5,048 | 0,000 |
(Nguồn: Tác giả xử lý dữ liệu bằng phần mềm SPSS) Kết quả phân tích hồi qui lần thứ nhất cho thấy giá trị hệ số tương quan là 0,880 > 0,5; hệ số xác định R2 hiệu chỉnh = 0,769 tại mức ý nghĩa 0,000 < 0,05, do đó R2 hiệu chỉnh có ý nghĩa về mặt thống kê hay nói cách khác 5 biến độc lập được đưa vào trong mô hình hồi qui ảnh hưởng 76,9% sự thay đổi của biến phụ thuộc, còn lại 23,1% là do các biến ngoài mô hình và sai số ngẫu nhiên. Bên cạnh đó chỉ số Durbin-Watson = 1,940 nằm trong khoảng cho phép từ 1 đến 3 nên không có hiện tượng tự tương quan. Tuy nhiên nhìn vào bảng 4.8 để xét độ tin cậy của các biến độc lập trong mô hình ta thấy có 2 biến độc lập là “Danh tiếng” và “Tiếp cận” có chỉ số Sig. (mức ý nghĩa) lần lượt là 0,113 và 0,137 > 0,05 (độ tin cậy 5%). Vì vậy 2 biến độc lập này sẽ bị loại trong phân tích hồi qui tiếp theo, nhưng biến độc lập nào có giá trị lớn hơn ta tiến hành loại trước. Do đó, trong trường hợp này biến “Tiếp cận” sẽ bị loại trước và tác giả tiến hành phân tích mô hình hồi qui lần thứ 2. Sau khi tiến hành loại biến “tiếp cận” để phân tích mô hình hồi qui lần tiếp theo, kết
quả cho thấy tất cả các thông số như VIF, Tolorence, tstat và Sig. đều thỏa (Phụ lục 12). Kết quả phân tích hồi qui tuyến tính được thể hiện như sau:
Bảng 4.9: Kết quả hệ số hồi qui lần 2
Hệ số hồi qui chưa chuẩn hóa | Hệ số hồi qui đã chuẩn hóa | t (Kiểm định t – Test) | Mức ý nghĩa Sig. | |||
B | Sai số chuẩn | Beta | ||||
1 | Hằng số | -0,47 | 0,154 | -0,308 | 0,758 | |
Học thuật | 0,368 | 0,038 | 0,402 | 9,725 | 0,000 | |
Phi học thuật | 0,310 | 0,039 | 0,343 | 7,885 | 0,000 | |
Danh tiếng | 0,081 | 0,038 | 0,085 | 2,115 | 0,036 | |
Chương trình đào tạo | 0,252 | 0,045 | 0,258 | 5,646 | 0,000 |
(Nguồn: Tác giả xử lý dữ liệu bằng phần mềm SPSS)
Bảng 4.10: Hệ số tổng hợp mô hình
R | R2 | R2 hiệu chỉnh | Sai số chuẩn của ước lượng | Durbin- Watson | |
1 | 0,879 | 0,773 | 0,768 | 0,30021 | 1,935 |
(Nguồn: Tác giả xử lý dữ liệu bằng phần mềm SPSS)
Kết quả cho thấy giá trị hệ số tương quan là 0,879 > 0,5; đây là mô hình thích hợp để sử dụng đánh giá mối quan hệ giữa biến phụ thuộc và các biến độc lập. Ngoài ra giá trị hệ số xác định R2 hiệu chỉnh là 0,768 có nghĩa là mô hình hồi qui tuyến tính đã xây dựng phù hợp với dữ liệu 76,8%. Nói khác đi, 76,8% sự hài lòng về CLDVĐT của sinh viên Khoa Du lịch Trường HUFI là do các thành phần biến độc lập của mô hình hồi qui này giải thích, phần còn lại là do sai số và các nhân tố khác. Điểm khác biệt này cũng có thể giải thích do mô hình nghiên cứu không tập trung vào những giá trị và đặc điểm cá nhân của sinh viên như tâm lý, tính cách… Vì vậy những giá trị biến quan sát trong nghiên cứu chỉ có thể giải thích cho 76,8% sự hài lòng về CLDVĐT của sinh viên Khoa Du lịch Trường HUFI. Và đây cũng chính là một trong những giới hạn của đề tài và sẽ được triển khai trong những nghiên cứu sau.
Bảng 4.11: Kiểm định độ phù hợp của mô hình hồi qui tuyến tính tổng thể
Mô hình | Tổng bình phương | Df | Bình phương trung bình | F | Sig. | |
1 | Hồi qui | 62,130 | 4 | 15,533 | 172,346 | 0,000b |
Số dư | 18,295 | 203 | 0,090 | |||
Tổng | 80,425 | 207 | ||||
(Nguồn: Tác giả xử lý dữ liệu bằng phần mềm SPSS)
Bản chất tổng thể là rất lớn, vì vậy rất tốn thời gian và chi phí cho việc thu thập tổng thể nên tác giả chọn kích thước mẫu trong tổng thể để suy diễn tổng thể. Vì vậy, khi thực hiện kiểm định ở bảng 4.11, tác giả mong muốn cỡ mẫu của mình đạt tiêu chí để có thể suy ra được tổng thể nghiên cứu. Kiểm định F được sử dụng để đánh giá tính phù hợp của mô hình hồi qui tuyến tính này có suy rộng và áp dụng được cho tổng thể hay không? Cụ thể trong trường hợp này, giá trị Sig. của kiểm định F là 0,000 < 0,05 như vậy, mô hình hồi qui tuyến tính xây dựng được phù hợp với tổng thể. Như vậy, cuối cùng trong phân tích mô hình hồi qui tuyến tính, ta có bảng kết quả sau:
Bảng 4.12: Kết quả hệ số hồi qui và thống kê đa cộng tuyến
Hệ số chưa chuẩn hóa | Hệ số chuẩn hóa | t | Mức ý nghĩa Sig. | Thống kê đa cộng tuyến | ||||
B | Sai số chuẩn | Beta | Tolerance | VIF | ||||
1 | Hằng số | -0,047 | 0,154 | -0,308 | 0,758 | |||
Học thuật | 0,368 | 0,038 | 0,402 | 9,725 | 0,000 | 0,656 | 1,525 | |
Phi học thuật | 0,310 | 0,039 | 0,343 | 7,885 | 0,000 | 0,594 | 1,685 | |
Danh tiếng | 0,081 | 0,038 | 0,085 | 2,115 | 0,036 | 0,696 | 1,437 | |
Chương trình đào tạo | 0,252 | 0,045 | 0,258 | 5,646 | 0,000 | 0,535 | 1,868 |
(Nguồn: Tác giả xử lý dữ liệu bằng phần mềm SPSS)
Dựa vào kết quả bảng 4.12, tác giả nhận thấy thứ nhất là giá trị Sig. của kiểm định t từng biến độc lập đều nhỏ hơn 0,05, có nghĩa là các biến độc lập được đưa vào mô hình đều có ý nghĩa. Thứ hai là hệ số hồi qui chuẩn hóa, các nhân tố có
trọng số hồi qui chuẩn hóa đạt dấu dương nghĩa là các biến độc lập này có tác động cùng chiều đến biến phụ thuộc. Cuối cùng là tất cả các hệ số VIF < 2 nên không xảy ra hiện tượng đa cộng tuyến (Nguyễn Đình Thọ, 2011).
Từ kết quả trên, phương trình hồi qui tuyến tính đã chuẩn hóa được xây dựng như sau:
Sự hài lòng về CLDVĐT của sinh viên Khoa Du lịch Trường HUFI = 0,402*Học thuật + 0,343*Phi học thuật + 0,085*Danh tiếng + 0,258* Chương trình đào tạo.
Qua phương trình hồi qui đa biến đã chuẩn hóa ở trên ta thấy có 4 nhân tố bao gồm Học thuật, Phi học thuật, Danh tiếng và Chương trình đào tạo đều có ảnh hưởng tỷ lệ thuận đến sự hài lòng về CLDVĐT của sinh viên Khoa Du lịch Trường HUFI. Thêm vào đó, khi giá trị Beta của các biến này càng cao thì có mức ảnh hưởng càng lớn đến sự hài lòng về CLDVĐT của sinh viên Khoa Du lịch Trường HUFI. Tác giả sắp xếp theo thứ tự mức độ ảnh hưởng của từng biến độc lập đến biến phụ thuộc theo hướng từ mạnh nhất đến thấp nhất lần lượt như sau:
- Đầu tiên là “Học thuật” có ảnh hưởng nhiều nhất với hệ số β = 0,402.
- Thứ hai là “Phi học thuật” có ảnh hưởng kế tiếp với hệ số β = 0,343.
- Thứ ba là “Chương trình đào tạo” với hệ số β = 0,258.
- Cuối cùng là “Danh tiếng” có tác động yếu nhất với hệ số β = 0,085.
4.4.3 Dò tìm sự vi phạm các giả định cần thiết trong hồi qui tuyến tính
- Giả định phần dư có phân phối chuẩn
Để dò tìm sự vi phạm giả định phân phối chuẩn của phần dư ta sẽ dùng hai công cụ vẽ của phần mềm SPSS là biểu đồ Histogram và đồ thị P-P plot.
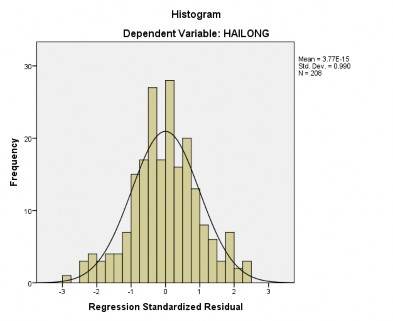
Hình 4.1: Biểu đồ Histogram phân tán phần dư chuẩn hóa
(Nguồn: Kết quả xử lý số liệu khảo sát của tác giả)
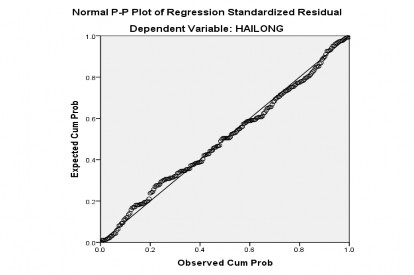
Hình 4.2: Đồ thị P-P Plot của phần dư chuẩn hóa hồi qui
(Nguồn: Kết quả xử lý số liệu khảo sát của tác giả)
Hình 4.1 cho thấy hầu hết tất cả các cột tần số đều nằm trong biểu đồ hình chuông với trung bình sai số gần bằng 0 (giá trị Mean = 3,77E-15 và độ lệch chuẩn Std.Dev. = 0,990). Thêm vào đó hình 4.2 cho thấy hầu hết tất cả các quan sát đều phân phối xung quanh đường hồi qui tuyến tính mẫu. Do đó bài nghiên cứu của
chúng ta có phân phối tương đối chuẩn, tức là giả định về phân phối chuẩn của phần dư không bị vi phạm.
- Giả định tuyến tính và phương sai của sai số không đổi
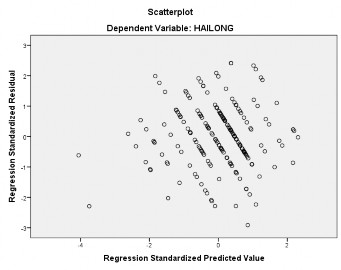
Hình 4.3: Biểu đồ phân tán phần dư và giá trị dự đoán của mô hình hồi qui tuyến tính
(Nguồn: Kết quả xử lý số liệu khảo sát của tác giả)
Hình 4.3 cho thấy tổng cộng 208 quan sát được tụ lại thành những đường thẳng, có rất ít các quan sát nằm ngoài do đó có thể kết luận rằng liên hệ của biến độc lâp và biến phụ thuộc trong nghiên cứu này là liên hệ tuyến tính.
4.4.4 Kiểm định giả thuyết của mô hình nghiên cứu chính thức
Dựa vào kết quả bảng 4.12, tác giả kết luận rằng có 4 giả thuyết gồm H1, H2, H3 và H5 có giá trị Sig đều nhỏ hơn 0,05 và các hệ số β đều mang dấu dương nên các giả thuyết này đều được chấp nhận, cũng như các nhân tố đều có tác động thuận chiều đến sự hài lòng của sinh viên đối với CLDVĐT tại Khoa Di lịch trường HUFI với độ tin cậy 95%; tuy nhiên có giả thuyết H4 bị bác bỏ hay không được chấp nhận vì có Sig > 0,05. Giả thuyết H4 cho rằng sự tiếp cận có tác động thuận chiều đến sự hài lòng của sinh viên đối với CLDVĐT tại Khoa Di lịch trường HUFI. Cuối cùng, qua việc phân tích và đánh giá mô hình nghiên cứu được điều chỉnh lại như sau: