Bảng 4.11 Kết quả phân tích EFA tất cả các biến
% of phương sai
TVE
Lũy kế TVE %
KMO=.934 | Kiểm định Bartlett: Sig.=.000 | ||
Nhân tố | Eigenvalue | ||
1 | 11.642 | 40.415 | 40.415 |
2 | 2.873 | 9.070 | 49.485 |
3 | 1.773 | 5.097 | 54.582 |
4 | 1.537 | 4.158 | 58.740 |
5 | 1.424 | 3.907 | 62.647 |
6 | 1.157 | 3.111 | 65.758 |
… | ….. | ….. | ….. |
Có thể bạn quan tâm!
-

 Sự Cần Thiết Phải Nghiên Cứu Lòng Trung Thành Của Khách Hàng Gửi Tiền Tại Các Ngân Hàng Thương Mại Việt Nam
Sự Cần Thiết Phải Nghiên Cứu Lòng Trung Thành Của Khách Hàng Gửi Tiền Tại Các Ngân Hàng Thương Mại Việt Nam -
 Thực Trạng Hoạt Động Huy Động Vốn Tiền Gửi Của Các Nhtm Việt Nam Trên Địa Bàn Tp. Hồ Chí Minh
Thực Trạng Hoạt Động Huy Động Vốn Tiền Gửi Của Các Nhtm Việt Nam Trên Địa Bàn Tp. Hồ Chí Minh -
 Thang Đo Lòng Trung Thành Của Khách Hàng Sau Hiệu Chỉnh
Thang Đo Lòng Trung Thành Của Khách Hàng Sau Hiệu Chỉnh -
 Phân Tích Đa Nhóm Theo Đặc Điểm Sản Phẩm Dịch Vụ Ngân Hàng
Phân Tích Đa Nhóm Theo Đặc Điểm Sản Phẩm Dịch Vụ Ngân Hàng -
 Thống Kê Số Liệu Các Ngân Hàng Thương Mại Việt Nam Tính Đến 31/12/2016
Thống Kê Số Liệu Các Ngân Hàng Thương Mại Việt Nam Tính Đến 31/12/2016 -
 Ảnh hưởng của trách nhiệm xã hội doanh nghiệp đến lòng trung thành của khách hàng gửi tiền tại các ngân hàng thương mại Việt Nam - 9
Ảnh hưởng của trách nhiệm xã hội doanh nghiệp đến lòng trung thành của khách hàng gửi tiền tại các ngân hàng thương mại Việt Nam - 9
Xem toàn bộ 82 trang tài liệu này.
(Nguồn: tính toán của tác giả từ SPSS, phụ lục 7)
Thứ nhất, KMO=.934 > .5 do đó phân tích EFA là thích hợp cho dữ liệu thực tế. Kiểm định Bartlett có ý nghĩa thống kê (Sig=.000 < .005) nên các biến có tương quan với nhau trong tổng thể.
Thứ hai, kết quả EFA phân tích được 6 nhân tố và các Eigenvalue đều lớn hơn 1 (hệ số nhỏ nhất là 1.157), do đó giữ lại cả 6 nhân tố như phân tích ban đầu, không cần rút gọn bớt tập nhân tố. Tổng phương sai trích là 65.758% (lớn hơn 50%), tức là 65.758% thay đổi của các nhân tố được giải thích bởi biến quan sát.
Bảng 4.12 Ma trận thành phần các nhân tố
Nhân tố Biến quan sát | Nhận dạng KH | Niềm tin KH | TNXH DN | Cảm xúc của KH | Sự hài lòng KH | Lòng trung thành KH |
ND3 ND5 ND4 ND6 ND2 ND1 | .907 .865 .859 .780 .721 .637 | |||||
NT5 NT3 NT4 | .852 .845 .826 |
NT2 NT1 | .742 .718 | |||||
TN3 TN4 TN2 TN5 TN1 | .905 .860 .822 .779 .770 | |||||
CX4 CX3 CX2 CX1 | .874 .816 .812 .714 | |||||
HL3 HL2 HL4 HL1 | .793 .789 .642 .620 | |||||
TT3 TT4 TT1 TT2 | 1.025 .742 .605 .587 |
(Nguồn: tính toán của tác giả từ SPSS, phụ lục 7)
Thứ ba, các hệ số tải nhân tố thành phần của 6 nhân tố tải về đều lớn hơn 0.5 (thấp nhất là 0.587), cho thấy nghiên cứu đạt được ý nghĩa thực tiễn.
Thứ tư, khác biệt hệ số tải giữa các nhân tố đạt tối thiểu 0.3 (xem phụ lục 7), thỏa mãn điều kiện để mỗi biến quan sát tồn tại trong mô hình tập trung giải thích cho một nhân tố duy nhất.
Với những chỉ số trên, có thể kết luận, mô hình phân tích nhân tố hoàn toàn có ý nghĩa thực tiễn, khả năng giải thích cho thực tế cao và hình thành 6 nhân tố có ý nghĩa giống trong mô hình nghiên cứu đề xuất. Sáu nhân tố bao gồm 28 biến quan sát được tiếp tục giữ lại để phân tích CFA trong bước tiếp theo.
4.5.4 Phân tích nhân tố khẳng định CFA
Tác giả tiến hành phân tích nhân tố khẳng định đối với 6 khái niệm trong nghiên cứu, và dùng 5 chỉ tiêu trong quá trình kiểm định bộ thang đo. Thứ nhất: đánh giá mức độ phù hợp của dữ liệu với thực tế. Thứ hai: độ tin cậy tổng hợp và tổng phương sai trích. Thứ ba: kiểm định giá trị phân biệt. Thứ tư: kiểm định giá trị hội tụ của bộ thang đo. Cuối cùng là kiểm tra tính đơn hướng của mô hình. Kết quả CFA lần 1 được trình bày như hình 4.3:
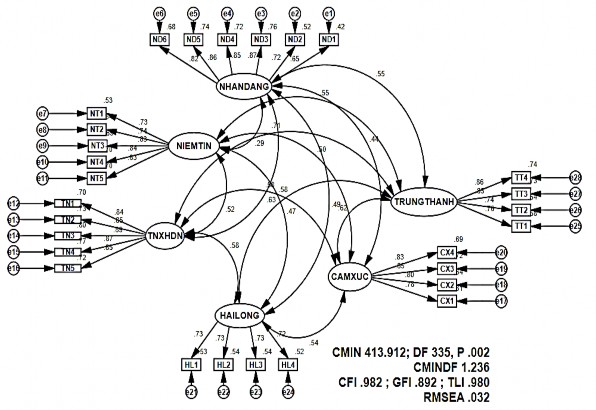
Hình 4.3 Kết quả phân tích CFA chuẩn hóa lần 1
Kết quả phân tích cho thấy, kiểm định Chi-bình phương thì mô hình đạt mức khác biệt không có ý nghĩa ở mức 5% (P=.002). Tuy nhiên, các chỉ số đo lường độ phù hợp khác đều đạt yêu cầu (CMIN/DF= 1.236; GFI=.892; TLI =.980; CFI =.982; RMSEA =0.032). Các chỉ số CMIN/DF, TLI và CFI đều ở mức chấp nhận rất tốt, còn chỉ số GFI chỉ nằm trong vùng tạm chấp nhận. Các trọng số chuẩn hoá λ của các biến đo lường khá cao, không có chỉ số nào thấp hơn 0.5 (chỉ số thấp nhất là .652 của biến ND1) và đạt mức ý nghĩa thống kê. Chỉ số RMSEA = .032 thể hiện kết quả rất tốt, chứng tỏ độ tương thích với dữ liệu thị trị trường cao.
Tuy nhiên, kết quả CFA còn cho thấy một số sai số trong mô hình có tương quan lớn. Khi nối các sai số có tương quan lớn với nhau, có thể cải thiện được mô hình nghiên cứu. Cụ thể một số cặp sai số có chỉ số MI cao (Modification Indices) như e12 và e13 (MI=10.978), e7 và e8 (MI=7.519), e15 và e16 (MI=6.612), e2 và e5
(MI=5.732), e2 và e3 (MI=4.787). Ý nghĩa chỉ số MI là khi móc các sai số này lại với nhau thì Chi-bình phương sẽ giảm đúng một lượng bằng MI. Kết quả là mô hình sẽ được cải thiện. Kết quả phân tích CFA lần 2 sau khi đã móc các sai số trong mô hình chuẩn hóa được thể hiện ở hình 4.4.
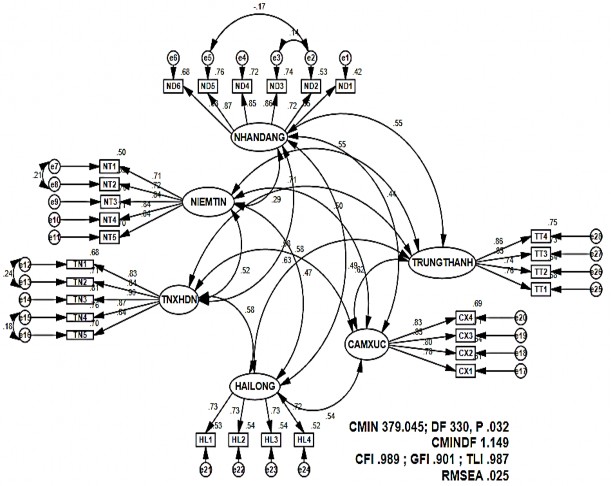
Hình 4.4 Mô hình tới hạn sau khi nối các sai số có hệ số tương quan lớn
Thứ nhất, kiểm định mức độ phù hợp với thực tế. Mô hình ở hình 4.4 sau khi móc nối sai số có chỉ số MI lớn đã cải thiện được so với mô hình ở hình 4.3. Mặc dù, P đã tăng đáng kể (P=.032), kiểm định Chi-bình phương vẫn không có ý nghĩa ở mức 5%. Tuy nhiên, các chỉ số CFI=.989, GFI=.901, TLI=.987 chứng tỏ kết quả rất tốt, tất cả
các chỉ số đều lớn hơn 0.9 như yêu cầu. Chỉ số RMSEA=.025, CMIN/DF=1.149 với kích cở mẫu là 236 chứng tỏ mức độ phù hợp của dữ liệu so với thực tế là rất cao.
Bảng 4.13 Các chỉ số kiểm định độ tin cậy bộ thang đo
Khái niệm | i | i2 | 1-i2 | Chỉ số | Giá trị | ||
Trách nhiệm xã hội doanh nghiệp | |||||||
TN1 | <--- | TN | 0.83 | 0.68 | 0.32 | α | 0.935 |
TN2 | <--- | TN | 0.84 | 0.71 | 0.29 | c | 0.935 |
TN3 | <--- | TN | 0.90 | 0.81 | 0.19 | vc | 0.732 |
TN4 | <--- | TN | 0.87 | 0.76 | 0.24 | ||
TN5 | <--- | TN | 0.84 | 0.70 | 0.30 | ||
Nhận dạng khách hàng | |||||||
ND1 ND2 | <--- <--- | ND | 0.65 | 0.42 | 0.58 | α | 0.913 |
ND | 0.73 | 0.53 | 0.47 | c | 0.914 | ||
ND3 | <--- | ND | 0.86 | 0.74 | 0.26 | vc | 0.643 |
ND4 | <--- | ND | 0.85 | 0.72 | 0.28 | ||
ND5 | <--- | ND | 0.87 | 0.76 | 0.24 | ||
ND6 | <--- | ND | 0.83 | 0.68 | 0.32 | ||
Niềm tin của khách hàng | |||||||
NT1 | <--- | NT | 0.71 | 0.50 | 0.50 | α | 0.895 |
NT2 | <--- | NT | 0.72 | 0.52 | 0.48 | c | 0.895 |
NT3 | <--- | NT | 0.84 | 0.70 | 0.30 | vc | 0.625 |
NT4 | <--- | NT | 0.84 | 0.71 | 0.29 | ||
NT5 | <--- | NT | 0.84 | 0.70 | 0.30 | ||
Cảm xúc của khách hàng | |||||||
CX1 | <--- | CX | 0.78 | 0.61 | 0.39 | α | 0.888 |
CX2 | <--- | CX | 0.80 | 0.64 | 0.36 | c | 0.889 |
CX3 | <--- | CX | 0.85 | 0.71 | 0.29 | vc | 0.666 |
CX4 | <--- | CX | 0.83 | 0.69 | 0.31 | ||
Sự hài lòng của khách hàng | |||||||
HL1 | <--- | HL | 0.73 | 0.53 | 0.47 | α | 0.819 |
HL2 | <--- | HL | 0.74 | 0.54 | 0.46 | c | 0.820 |
HL3 | <--- | HL | 0.73 | 0.54 | 0.46 | vc | 0.532 |
HL4 | <--- | HL | 0.72 | 0.52 | 0.48 | ||
Lòng trung thành của khách hàng | |||||||
TT1 | <--- | TT | 0.76 | 0.58 | 0.42 | α | 0.877 |
TT2 | <--- | TT | 0.74 | 0.54 | 0.46 | c | 0.881 |
TT3 | <--- | TT | 0.85 | 0.73 | 0.27 | vc | 0.649 |
TT4 | <--- | TT | 0.86 | 0.74 | 0.26 | ||
(Nguồn: tính toán của tác giả từ SPSS và Excel)
Thứ hai, đánh giá độ tin cậy tổng hợp(ρc) và tổng phương sai trích(ρvc). Bộ thang đo đạt độ tin cậy khi các giá trị độ tin cậy tổng hợp c và tổng phương sai trích vc đạt giá trị >0.5 (Hair và cộng sự, 2010) và độ tin cậy tổng hợp ρc ≥ Cronbach’s alpha (α). Với i là trọng số chuẩn hóa của biến quan sát thứ i; p là số biến quan sát của thang
(∑𝑝 2
(∑𝑝
2)
đo: =
𝑖=1
𝑖)
; = 𝑖=1 𝑖
𝑐 (∑𝑝
2∑𝑝
2 𝑣𝑐
(∑𝑝
𝑖2)+∑𝑝
(1−𝑖2)
𝑖=1
𝑖) +
𝑖=1(1−𝑖 )
𝑖=1
𝑖=1
Kết quả tính toán từ bảng 4.13 cho thấy các khái niệm đều có độ tin cậy tổng hợp và tổng phương sai trích lớn hơn 50% (thấp nhất lần lượt là 82% và 53,2%), do đó các chỉ số thỏa các điều kiện yêu cầu. Bên cạnh đó, các khái niệm trong mô hình còn có độ tin cậy tổng hợp ≥ giá trị Cronbach’s Alpha. Kết hợp lại các giá trị, thì các thang đo trong mô hình nghiên cứu đã đạt được độ tin cậy.
Thứ ba, đánh giá giá trị phân biệt. Trong nghiên cứu này, các thang đo được xây dựng không bao gồm nhiều khái niệm thành phần. Do đó, tác giả chỉ thực hiện đánh giá giá trị phân biệt bên ngoài, tức là giữa các khái niệm bên ngoài với nhau. Từ hệ số tương quan giữa các biến (r), tiến hành tính toán độ lệch chuẩn (SE), CR và giá trị Pvalue theo các công thức: SE=SQRT((1-r2)/(n-2)); CR=(1-r)/SE; P_value
=TDIST(CR, n-2, 2), với n là độ lớn của mẫu.
Bảng 4.14 Hệ số tương quan giữa các khái niệm
Khái niệm | r | SE | CR | P-value | ||
ND | <--> | NT | 0.288 | 0.063 | 11.373 | 0.000 |
ND | <--> | TN | 0.633 | 0.051 | 7.252 | 0.000 |
ND | <--> | CX | 0.436 | 0.059 | 9.587 | 0.000 |
ND | <--> | HL | 0.485 | 0.057 | 9.008 | 0.000 |
ND | <--> | TT | 0.549 | 0.055 | 8.254 | 0.000 |
NT | <--> | TN | 0.518 | 0.056 | 8.620 | 0.000 |
NT | <--> | CX | 0.496 | 0.057 | 8.879 | 0.000 |
NT | <--> | HL | 0.471 | 0.058 | 9.173 | 0.000 |
NT | <--> | TT | 0.549 | 0.055 | 8.254 | 0.000 |
TN | <--> | CX | 0.579 | 0.053 | 7.899 | 0.000 |
TN | <--> | HL | 0.580 | 0.053 | 7.887 | 0.000 |
TN | <--> | TT | 0.711 | 0.046 | 6.287 | 0.000 |
CX | <--> | HL | 0.542 | 0.055 | 8.337 | 0.000 |
CX | <--> | TT | 0.619 | 0.051 | 7.421 | 0.000 |
HL | <--> | TT | 0.576 | 0.053 | 7.934 | 0.000 |
(Nguồn: tính toán của tác giả từ Amos và Excel)
Các hệ số tương quan và sai lệch chuẩn đều khác với 1 và có ý nghĩa thống kê tại mức ý nghĩa 1%, như vậy các khái niệm nghiên cứu đạt được giá trị phân biệt.
Thứ tư, đánh giá giá trị hội tụ của bộ thang đo. Bộ thang đo đạt giá trị hội tụ khi các biến quan sát của bộ thang đo một khái niệm nghiên cứu phải tương quan cao hay các λ chuẩn hóa cao (≥0.5) và đạt mức ý nghĩa thống kê (P <0.05). Quan sát từ mô hình tới hạn ở hình 4.4, ta thấy các hệ số chuẩn hóa của các biến quan sát đều lớn hơn .5 (hệ số thấp nhất là .65) và các hệ số này đều đạt ý nghĩa thống kê P=.000 (xem phụ lục 9) do đó có thể kết luận, các thang đo được sử dụng trong mô hình đạt giá trị hội tụ.
Thứ năm, tính đơn hướng của bộ thang đo. Bộ thang đo đạt tính đơn hướng khi không có mối tương quan giữa sai số các biến quan sát. Ở mô hình tới hạn (hình 4.4) cho thấy bộ thang đo 3 khái niệm nghiên cứu đạt tính đơn hướng. Các bộ thang đo đó là: sự hài lòng, cảm xúc, lòng trung thành của khách hàng. Riêng bộ thang đo khái niệm TNXHDN, nhận dạng khách hàng, niềm tin của khách hàng có mối quan hệ giữa các cặp sai số (e12 và e13; e7 và e8; e15 và e16; e2 và e5; e2 và e3) nên không đạt tính đơn hướng.
4.5.5 Kiểm định mô hình lý thuyết bằng phân tích SEM
4.5.5.1 Kiểm định mô hình lý thuyết
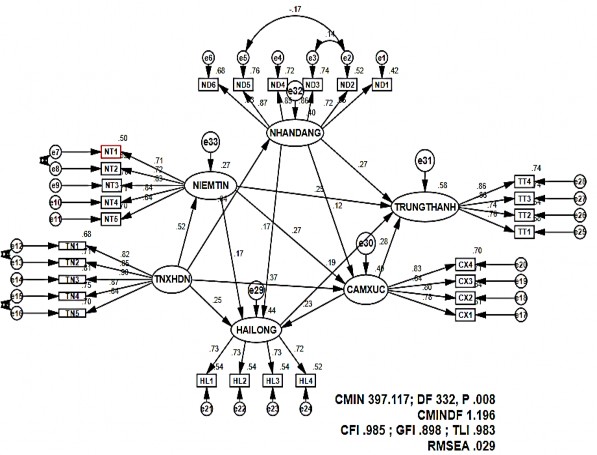
Hình 4.5. Kết quả SEM cho mô hình lý thuyết (chuẩn hóa)
Kết quả phân tích cấu trúc tuyến tính cho thấy mô hình nghiên cứu có giá trị thống kê Chi –bình phương là 397.117 với 332 bậc tự do, giá trị P = .008. Nếu điều chỉnh theo bậc tự do có CMIN/df = 1.196 < 3, đạt yêu cầu cho độ tương thích. Các chỉ tiêu khác như CFI = .985 > .9, TLI=.983 >.9, RMSEA = .029 < .05 đạt yêu cầu rất tốt. Tuy giá trị GFI=.898 không lớn hơn .9 nhưng chêch lệch không đáng kể (.002). Vì vậy có thể kết luận mô hình phù hợp với dữ liệu thị trường.
4.5.5.2 Ước lượng mô hình lý thuyết bằng Bootstrap
Bootstrap là phương pháp lấy mẫu lặp lại có thay thế trong đó mẫu ban đầu đóng vai trò là đám đông. Để đánh giá độ tin cậy của các ước lượng, trong các phương pháp nghiên cứu định lượng bằng phương pháp lấy mẫu, thông thường chúng ta phải chia mẫu ra làm hai mẫu con: một phần dùng để ước lượng các tham số mô hình và một phần dùng để đánh giá lại. Hoặc có thể đánh giá lại nghiên cứu
bằng một mẫu khác. Tuy nhiên, các cách làm này tốn kém nhiều thời gian và chi phí do yêu cầu trong phân tích SEM đòi hỏi quy mô mẫu lớn (Nguyễn Khánh Duy, 2009). Trong những trường hợp như vậy thì Bootstrap là phương pháp phù hợp để thay thế. Nghiên cứu này sử dụng phương pháp Bootstrap với số lượng quan sát lặp lại N = 500. Phần mềm AMOS lúc này sẽ chọn ra 500 quan sát theo phương pháp lặp lại có thay thế từ đám đông n=236 quan sát.
Bảng 4.15 Kết quả ước lượng Bootstrap với N = 500
Quan hệ | SE | SE-SE | Mean | Bias | SE-Bias | |CR| | ||
NT | <--- | TN | 0.070 | 0.002 | 0.514 | -0.008 | 0.003 | 2.67 |
ND | <--- | TN | 0.047 | 0.002 | 0.634 | -0.002 | 0.002 | 1.00 |
CX | <--- | TN | 0.090 | 0.003 | 0.365 | -0.004 | 0.004 | 1.00 |
CX | <--- | ND | 0.072 | 0.002 | 0.125 | 0.003 | 0.003 | 1.00 |
CX | <--- | NT | 0.076 | 0.002 | 0.266 | -0.001 | 0.003 | 0.33 |
HL | <--- | TN | 0.103 | 0.003 | 0.255 | 0.000 | 0.005 | 0.00 |
HL | <--- | ND | 0.082 | 0.003 | 0.171 | -0.001 | 0.004 | 0.25 |
HL | <--- | CX | 0.086 | 0.003 | 0.231 | 0.001 | 0.004 | 0.25 |
HL | <--- | NT | 0.075 | 0.002 | 0.168 | -0.005 | 0.003 | 1.67 |
TT | <--- | NT | 0.067 | 0.002 | 0.271 | 0.002 | 0.003 | 0.67 |
TT | <--- | CX | 0.076 | 0.002 | 0.282 | -0.002 | 0.003 | 0.67 |
TT | <--- | HL | 0.091 | 0.003 | 0.188 | 0.003 | 0.004 | 0.75 |
TT | <--- | NT | 0.072 | 0.002 | 0.243 | -0.002 | 0.003 | 0.67 |
(Nguồn: tính toán của tác giả từ Amos và Excel)
Nguyên tắc xác định: Nếu |CR| = |Bias/SE-Bias| > 2 thì có độ chệch xuất hiện và ngược lại, với SE là sai lệch chuẩn, SE-SE là sai lệch chuẩn của sai lệch chuẩn, Mean: Giá trị trung bình, Bias: độ chệch, SE-Bias: sai lệch chuẩn của độ chệch. Ngoại trừ mối quan hệ giữa niềm tin và trách nhiệm xã hội doanh nghiệp thì các mối quan hệ khác đều có |CR|<2, có nghĩa độ chệch là rất nhỏ, không có ý nghĩa thống kê ở độ tin cậy 95%. Như vậy, các ước lượng trong mô hình có thể tin cậy được.
4.5.5.3 Kiểm định giả thuyết nghiên cứu
Kết quả kiểm định các giả thuyết nghiên cứu được trình bày trong bảng 4.16:
Bảng 4.16 Kết quả kiểm định giả thuyết ở mức ý nghĩa 5%.
Giả thuyết | Mối quan hệ | Uớc lượng chưa chuẩn hóa | Sai lệch chuẩn S.E | Giá trị tới hạn C.R | P* | Kết quả | Uớc lượng chuẩn hóa | ||
H1 | HL | <--- | TN | .163 | .064 | 2.548 | .011 | Chấp nhận | .255 |
H2 | TT | <--- | HL | .208 | .088 | 2.365 | .018 | Chấp nhận | .175 |
H3 | ND | <--- | TN | .430 | .054 | 7.930 | *** | Chấp nhận | .636 |
H4 | TT | <--- | ND | .286 | .072 | 3.960 | *** | Chấp nhận | .269 |
H5 | CX | <--- | TN | .279 | .070 | 3.989 | *** | Chấp nhận | .369 |
H6 | TT | <--- | CX | .270 | .071 | 3.812 | *** | Chấp nhận | .284 |
H7 | NT | <--- | TN | .363 | .052 | 6.941 | *** | Chấp nhận | .522 |
H8 | TT | <--- | NT | .254 | .071 | 3.571 | *** | Chấp nhận | .245 |
H9 | CX | <--- | ND | .137 | .089 | 1.531 | .126 | Không chấp nhận | |
H10 | HL | <--- | ND | .162 | .080 | 2.035 | .042 | Chấp nhận | .171 |
H11 | HL | <--- | CX | .195 | .073 | 2.683 | .007 | Chấp nhận | .231 |
H12 | HL | <--- | NT | .159 | .073 | 2.174 | .030 | Chấp nhận | .173 |
H13 | CX | <--- | NT | .290 | .081 | 3.566 | *** | Chấp nhận | .267 |
Ghi chú: *** tương ứng p<.001 (Nguồn : tính toán của tác giả từ AMOS)
Mối quan hệ giữa các khái niệm trong mô hình nghiên cứu chính thức đều có ý nghĩa thống kê (p<.05), ngoại trừ ảnh hưởng của nhận dạng khách hàng đến cảm xúc của khách hàng. Giả thuyết H9 có p-value=.126, do đó giả thuyết này không được chấp nhận trong phạm vi nghiên cứu này. Các hệ số hồi quy chuẩn hóa đều mang dấu dương giống như giả thuyết đặt ra. Như vậy, trong 13 giả thuyết được đưa ra ở mô hình về mối quan hệ giữa các khái niệm thì có 12 giả thuyết được chấp nhận bao gồm H1, H2, H3, H4, H5, H6, H7,H8, H10, H11, H12, H13.
Xét các hệ quả của TNXHDN, thì TNXHDN ảnh hưởng trực tiếp mạnh nhất đến nhận dạng khách hàng, kế tiếp là niềm tin và sau đó đến cảm xúc của khách hàng rồi đến sự hài lòng. Các hệ số ước lượng chuẩn hóa lần lượt là .636, .522, .369 và
.255. Và những nhân tố này tiếp tục ảnh hưởng trực tiếp đến lòng trung thành của khách hàng.Trong đó, cảm xúc ảnh hưởng nhiều nhất (giá trị ước lượng là .284), tiếp theo là nhận dạng khách hàng (.269), sự hài lòng (.255) và cuối cùng là niềm tin của khách hàng (.245).
Bảng 4.17 Kết quả ảnh hưởng trực tiếp, gián tiếp của các giả thuyết nghiên cứu
Giả thuyết | Ảnh hưởng | P | |||
Trực tiếp | Gián tiếp | Tổng | |||
H1 | TNXHDN Sự hài lòng của KH | .255 | .316 | .571 | <.05 |
H2 | Sự hài lòng KHLòng trung thành của KH | .175 | .000 | .175 | <.05 |
H3 | TNXHDN Nhận dạng khách hàng | .636 | .000 | .636 | <.001 |
H4 | Nhận dạng khách hàng lòng trung thành | .269 | .030 | .299 | <.001 |
H5 | TNXHDN Cảm xúc của KH | .369 | .139 | .508 | <.001 |
H6 | Cảm xúc của KHLòng trung thành của KH | .284 | .040 | .324 | <.001 |
H7 | TNXHDN Niềm tin của KH | .522 | .000 | .522 | <.001 |
H8 | Niềm tin của KHLòng trung thành của KH | .245 | .117 | .362 | <.001 |
H10 | Nhận dạng KH Sự hài lòng của KH | .171 | .000 | .171 | <.05 |
H11 | Cảm xúc của KH Sự hài lòng của KH | .231 | .000 | .231 | <.01 |
H12 | Niềm tin của KH Sự hài lòng của KH | .173 | .062 | .235 | <.05 |
H13 | Niềm tin của KH Cảm xúc của KH | .267 | .000 | .267 | <.001 |
(Nguồn: tính toán của tác giả từ Excel, chi tiết tại phụ lục 12)
Như vậy, kết quả SEM cho thấy:
- TNXHDN ảnh hưởng trực tiếp đến nhận dạng khách hàng ( =.636), niềm tin của khách hàng (=.522). TNXHDN ảnh hưởng trực tiếp và gián tiếp đến sự hài lòng của khách hàng (tổng ảnh hưởng =.571), cảm xúc của khách hàng (tổng ảnh hưởng =.508).
- Niềm tin của khách hàng ảnh hưởng trực tiếp và gián tiếp đến sự hài lòng của khách hàng gửi tiền (trực tiếp =.173, gián tiếp =.062, tổng=.235); ảnh hưởng trực tiếp đến cảm xúc của khách hàng (=.276); ảnh hưởng trực tiếp và gián tiếp đến lòng trung thành của khách hàng gửi tiền (tổng=.362).
- Nhận dạng khách hàng ảnh hưởng trực tiếp đến sự hài lòng của khách hàng
(=.171); ảnh hưởng trực tiếp và gián tiếp đến lòng trung thành (=.299).
- Sự hài lòng của khách hàng ảnh hưởng trực tiếp đến lòng trung thành của khách hàng gửi tiền (=.175).
R2 = .404
Nhận dạng KH
.171*
.636***
R2 = .405
Cảm xúc
của KH
.269***
.369* .284*
.267***
TNXHDN
.522***
Niềm tin của KH
R2 = .272
.231**
.245***
Lòng trung thành của KH
.255*
.173*
R2 = .579
R2 = .442
.175*
Ghi chú:
Sự hài lòng của KH
- Cảm xúc ảnh hưởng trực tiếp đến sự hài của khách hàng gửi tiền (=.231); ảnh hưởng trực tiếp và gián tiếp đến lòng trung thành của khách hàng gửi tiền (tổng=.324).
*p<0.05;**p<0.01; ***p<.001
chưa tìm ra mối quan hệ
Hình 4.6 Kết quả ước lượng (chuẩn hóa)
Như vậy, tồn tại ảnh hưởng gián tiếp của TNXHDN đến lòng trung thành của khách hàng gửi tiền tại các NHTMVN tại Tp.Hồ Chí Minh. Ảnh hưởng gián tiếp thông qua 4 nhân tố nhận dạng khách hàng; niềm tin; cảm xúc; sự hài lòng khách hàng với với mức độ ảnh hưởng giảm dần lần lượt là .190, .189, .120, .045. Tổng
ảnh hưởng là βtổng = 0.543 (xem tính toán chi tiết tại phụ lục 12). Bên cạnh đó, biến lòng trung thành có giá trị R2 (Square Multiple Correlations) =.579, tức là các biến
độc lập giải thích được 57.9% sự thay đổi của biến phụ thuộc là lòng trung thành của khách hàng gửi tiền. Nói cách khác, nếu hỏi khách hàng gửi tiền rằng nếu KH cảm thấy ngân hàng này thực hiện tốt TNXHDN thì họ sẽ tiếp tục gắn bó với ngân hàng hay không, thì câu trả lời là không. Nhưng thông qua TNXHDN, sẽ làm niềm tin, sự hài lòng, cảm xúc và nhận dạng khách hàng thay đổi. Điều đó làm thay đổi lòng trung thành của họ.
4.5.6 Phân tích mô hình đa nhóm
Phương pháp phân tích cấu trúc đa nhóm để so sánh mô hình nghiên cứu theo các nhóm nào đó của một biến định tính. Phân tích đa nhóm cho ta kết quả liệu có sự khác nhau về lòng trung thành của khách hàng đối với các nhóm khác nhau về tuổi tác, giới tính,…Tác giả sẽ chia làm 2 mô hình: Mô hình khả biến và mô hình bất biến (từng phần). Trong mô hình khả biến, các tham số ước lượng trong từng mô hình của các nhóm không bị ràng buộc. Trong mô hình bất biến, thành phần đo lường không bị ràng buộc nhưng các mối quan hệ giữa các khái niệm trong mô hình nghiên cứu được ràng buộc có giá trị như nhau cho tất cả các nhóm. Kiểm định Chi-square được sử dụng để so sánh giữa 2 mô hình. Nếu kiểm định chi-square là cho thấy giữa mô hình bất biến và mô hình khả biến không có sự khác biệt (P-value > α, với α là mức ý nghĩa có thể là 1%, 5%, 10%) thì mô hình bất biến sẽ được chọn (có bậc tự do cao hơn). Ngược lại, nếu sự khác biệt Chi-square là có ý nghĩa giữa hai mô hình (P-value
< α) thì chọn mô hình khả biến có độ tương thích cao hơn (Nguyễn Khánh Duy, 2009). Trong nghiên cứu này, tác giả tiến hành phân tích đa nhóm dựa trên (1) đặc điểm khách hàng (giới tính, thời gian sử dụng dịch vụ, thu nhập) , (2) đặc điểm ngân hàng và sản phẩm dịch vụ (tính chất sở hữu ngân hàng, loại hình sản phẩm dịch vụ).
4.5.6.1 Phân tích mô hình đa nhóm theo đặc điểm khách hàng
Phân tích đa nhóm theo giới tính
Đối tượng trả lời phỏng vấn có thể nam hoặc nữ. Kết quả SEM mô hình khả biến và bất biến được trình bày chi tiết ở phụ lục 13. Sự khác biệt Chi-bình phương (2) và hệ số bậc tự do của hai mô hình lần lượt là 15.283 và 13 (Bảng 4.18). Mức
khác biệt của hai mô hình này không có ý nghĩa (p=0.290 >0.05) vì vậy mô hình bất biến từng phần được chọn.
Bảng 4.18 Phân tích đa nhóm theo giới tính
Mô hình so sánh | 2 | df | P | CMIN/df | TLI | CFI | GFI | RMSEA |
Bất biến từng phần | 790.718 | 677 | .002 | 1.168 | .972 | .974 | .819 | .027 |
Khả biến | 775.435 | 664 | .002 | 1.168 | .972 | .975 | .822 | .027 |
Giá trị khác biệt | 15.283 | 13 | .290 | 0.000 | .000 | -.001 | -.003 | .000 |
P_value=TDIST(2, df) (Nguồn : tính toán của tác giả từ AMOS và Excel)
Mô hình bất biến từng phần được chọn (có bậc tự do cao hơn). Điều đó cũng có nghĩa là mối quan hệ giữa các khái niệm: trách nhiệm xã hội doanh nghiệp, niềm tin, sự hài lòng, cảm xúc của khách hàng, nhận dạng khách hàng và lòng trung thành của khách hàng gửi tiền tại các NHTM VN tại Tp.Hồ Chí Minh là không khác nhau giữa nhóm khách hàng khác nhau về giới tính. Điều này cũng dễ dàng lý giải, bởi vì các sản phẩm tiền gửi ở Việt Nam đa phần không chỉ dành riêng cho một giới tính hoặc là nam hoặc là nữ, mà hướng đến cả hai nhóm khách hàng nam, nữ. Do đó, sẽ không có sự khác biệt trong cảm nhận giữa nam và nữ ở mức ý nghĩa 5%.
Mô hình so sánh | 2 | df | P | CMIN/df | TLI | CFI | GFI | RMSEA |
Bất biến từng phần | 951.15 | 677 | .000 | 1.405 | .934 | .941 | .810 | .042 |
Khả biến | 930.624 | 664 | .000 | 1.402 | .934 | .942 | .813 | .041 |
Giá trị khác biệt | 20.526 | 13 | .083 | .003 | .000 | -.001 | -.003 | .001 |
Phân tích đa nhóm theo thời gian sử dụng dịch vụ Bảng 4.19 Phân tích đa nhóm theo thời gian sử dụng dịch vụ
(Nguồn : tính toán của tác giả từ AMOS và Excel)
Thời gian sử dụng dịch vụ gửi tiền được chia làm 2 nhóm: 3 năm trở xuống và trên 3 năm. Sự khác biệt Chi-bình phương (2) và hệ số bậc tự do của hai mô hình lần lượt là 20.526 và 13 (Bảng 4.19). Mức khác biệt của hai mô hình này không có ý nghĩa (p=0.083 >0.05) vì vậy mô hình bất biến từng phần được chọn. Tuy nhiên, nếu sử dụng mức ý nghĩa là 10%, thì mô hình khả biến được chọn tức là có sự khác biệt về ảnh hưởng của TNXHDN đến lòng trung thành của KH gửi tiền tại các ngân hàng
thương mại Việt Nam. Điều này cũng có thể dễ dàng giải thích bởi vì một số khách hàng chọn gửi tiền tiết kiệm tại NHTM với kỳ hạn dài ví dụ 36 tháng, 60 tháng. Đôi khi, qua thời gian giao dịch, họ cảm thấy không hài lòng và có ý định chuyển đổi ngân hàng, nhưng họ không thể tất toán ngay lập tức tài khoản tiết kiệm tại ngân hàng họ giao dịch, nên thời gian quan hệ lâu dài với ngân hàng cũng chưa thể khẳng định họ chính là những khách hàng trung thành với dịch vụ tiền gửi tại ngân hàng đó.
Phân tích đa nhóm theo thu nhập
Theo kết quả phân tích mẫu, có 148 khách hàng có thu nhập dưới 10,000,000 đồng, có 88 khách hàng thu nhập từ 10 triệu đồng trở lên.Tác giả tiến hành phân tích đa nhóm theo hai nhóm này.
Bảng 4.20 Phân tích đa nhóm theo thu nhập
Mô hình so sánh | 2 | df | P | CMIN/df | TLI | CFI | GFI | RMSEA |
Bất biến từng phần | 829.321 | 677 | .000 | 1.225 | .962 | .966 | .814 | .031 |
Khả biến | 813.817 | 664 | .000 | 1.226 | .962 | .967 | .816 | .031 |
Giá trị khác biệt | 15.504 | 13 | .277 | -0.001 | .000 | -.001 | -.002 | .000 |
(Nguồn : tính toán của tác giả từ AMOS và Excel)
Sự khác biệt Chi-bình phương (2) và hệ số bậc tự do của hai mô hình lần lượt là 15.504 và 13 (Bảng 4.20). Mức khác biệt của hai mô hình này không có ý nghĩa (p=0.277 >0.05) vì vậy mô hình bất biến từng phần được chọn. Như vậy, mô hình bất biến từng phần được chọn, tức là mối quan hệ giữa các khái niệm: trách nhiệm xã hội doanh nghiệp, niềm tin, sự hài lòng, cảm xúc của khách hàng, nhận dạng khách hàng và lòng trung thành của khách hàng gửi tiền tại các NHTM VN tại Tp.Hồ Chí Minh là không khác nhau giữa những khách hàng có thu nhập khác nhau.
4.5.6.2 Phân tích mô hình đa nhóm theo đặc điểm và sản phẩm dịch vụ của ngân hàng
Phân tích đa nhóm theo đặc điểm của ngân hàng
Theo đặc điểm của NHTM, trong nghiên cứu này tác giả phân thành 2 nhóm:
- Nhóm 1 – NHTMCP nhà nước (121 bảng khảo sát): Agribank và 3 ngân hàng có tỷ lệ sở hữu của nhà nước cao là BIDV, Vietcombank, VietinBank. Kết quả thống