Phân tích EFA ở trên cho thấy kết quả NC định lượng chính thức vượt trội hơn so với kết quả thu được trong bước NC định lượng sơ bộ. Điều này có thể được giải thích là do cỡ mẫu lớn hơn với n = 368> cỡ mẫu tối thiểu 255 nên mang tính đại diện và đáng tin cậy hơn. Cụ thể là, 2 nhân tố Rủi ro phần mềm và Rủi ro dữ liệu có các biến quan sát hội tụ chung về cùng nhân tố do có tương quan với nhau và mô hình không có nhân tố nào bị loại. Ở bước này chỉ có nhân tố Rủi ro văn hoá tổ chức là có 2 biến quan sát bị loại gồm OCR4 (Nhân viên theo đuổi công việc cá nhân hơn là hợp tác và cạnh tranh) và OCR5 (Thiếu sự ổn định trong vận hành HTTTKT) do có hệ số tải < 0,5.
Như đã trình bày ở trên, tất cả các cá nhân đại diện trả lời đều có chuyên môn chính là kế toán, phần lớn trong số họ không có nhiều người có am hiểu sâu hay chuyên môn sâu về CNTT nên họ đều quan niệm rằng dữ liệu nằm trong phần mềm, bởi theo nhiệm vụ hàng ngày họ tương tác với dữ liệu trực tiếp trên các phần mềm chuyên dụng như kế toán hay ERP. Họ chỉ biết làm sao để có thể hoàn thành việc nhập liệu, xử lý tính toán và in kết quả hay xuất ra file để phục vụ cho nhu cầu quản lý. Việc dữ liệu lưu ở đâu, được quản lý như thế nào thì đó
là nhiệm vụ
của phòng IT. Hơn nữa, thực tế ở
Việt Nam cho thấy phần lớn
người làm công tác kế toán chưa được đào tạo nhiều kiến thức về dữ liệu nói riêng hay CSDL nói chung nên cách họ hiểu dữ liệu nằm chung với phần mềm là điều dễ hiểu. Bởi lẽ ấy mà đặc điểm dữ liệu khảo sát thực tế thu về đã thể hiện quan niệm trên nên 2 nhân tố rủi ro phần mềm (SWR) và rủi ro dữ liệu (DATR) đã hội tụ thành một. Ngoài ra, thực tế ở góc độ chuyên ngành CNTT cũng cho thấy thực chất dữ liệu cũng là một phần mềm và để cho an toàn, tiện lợi cũng như tăng tính bảo mật thì dữ liệu sẽ được quản lý và lưu trữ bởi một phần mềm quản lý dữ liệu chuyên dụng, chẳng hạn như SQL, Oracle, Access, … Phân tích EFA cho nhóm nhân tố phụ thuộc:
Phụ lục 39 cho thấy KMO = 0,961 nên việc phân tích nhân tố là phù hợp. Sig. (Kiểm định của Bartlett) = 0,000 (Sig. <0,05) chỉ ra rằng các biến quan sát trong tổng thể có tương quan với nhau.
Extraction Sums of Squared Loadings (Cumulative %) (Tổng phương sai được trích xuất) = 53,530% > 50 %; điều này chỉ ra 53,530% sự thay đổi trong dữ liệu được giải thích bởi 2 nhân tố. (Phụ lục 40)
Bảng 4.10 – Ma trận xoay các nhân tố phụ thuộc (giai đoạn NC chính thức)
Nhân tố | ||
1 | 2 | |
AIQ1 | ,774 | |
AIQ4 | ,769 | |
AIQ9 | ,735 | |
AIQ8 | ,734 | |
Có thể bạn quan tâm!
-

 Ảnh hưởng của rủi ro công nghệ thông tin đến chất lượng thông tin kế toán trong các doanh nghiệp tại Việt Nam 1738937919 - 16
Ảnh hưởng của rủi ro công nghệ thông tin đến chất lượng thông tin kế toán trong các doanh nghiệp tại Việt Nam 1738937919 - 16 -
 Tóm Tắt Kết Quả Kiểm Định Chính Thức Độ Tin Cậy Các Thang Đo Bằng Cronbach’S Alpha
Tóm Tắt Kết Quả Kiểm Định Chính Thức Độ Tin Cậy Các Thang Đo Bằng Cronbach’S Alpha -
 Ma Trận Xoay Các Nhân Tố Thức)
Ma Trận Xoay Các Nhân Tố Thức) -
 Hệ Số Hồi Quy Chuẩn Hoá Của Các Biến Độc Lập Standardized Regression Weights: (Group Number 1 – Default Model)
Hệ Số Hồi Quy Chuẩn Hoá Của Các Biến Độc Lập Standardized Regression Weights: (Group Number 1 – Default Model) -
 Hệ Số Hồi Quy Chưa Chuẩn Hoá Của Các Biến Trong Phân Tích Sem
Hệ Số Hồi Quy Chưa Chuẩn Hoá Của Các Biến Trong Phân Tích Sem -
 Kết Quả Kiểm Định Sự Khác Biệt Trong Đánh Giá Về Mức Độ Ảnh Hưởng Của Các Rủi Ro Cntt Đến Clhtttkt Giữa Các Nhóm Dn Kinh Doanh Ở Những
Kết Quả Kiểm Định Sự Khác Biệt Trong Đánh Giá Về Mức Độ Ảnh Hưởng Của Các Rủi Ro Cntt Đến Clhtttkt Giữa Các Nhóm Dn Kinh Doanh Ở Những
Xem toàn bộ 405 trang tài liệu này.
,721 | ||
AIQ7 | ,718 | |
AIQ2 | ,711 | |
AIQ3 | ,691 | |
AIQ6 | ,654 | |
AISQ3 | ,789 | |
AISQ9 | ,783 | |
AISQ6 | ,763 | |
AISQ7 | ,724 | |
AISQ5 | ,715 | |
AISQ4 | ,694 |
,682 | ||
AISQ8 | ,648 | |
AISQ2 | ,592 | |
Phương pháp trích xuất: Principal Axis Factoring. Phương pháp quay: Promax with Kaiser Normalization. | ||
a. Phép quay hội tụ trong 3 lần lặp. | ||
Nguồn: Kết quả được tập hợp qua phân tích từ phần mềm SPSS
Bảng 4.11 – Tổng hợp các biến quan sát sau khi phân tích EFA chính thức
Nhân tố | Các biến quan sát giữ lại | Các biến quan sát bị loại | Phân loại biến |
SWR | SWR2, DATR1, DATR4, SWR4, SWR5, DATR2, DATR3, DATR5, SWR3, SWR1 (10 biến) | Không có (nhân tố SWR và DATR có sự hội tụ) | Độc lập | |
2 | HWR | HWR5, HWR2, HWR3, HWR4, HWR1 (5 biến) | Không có | Độc lập |
3 | MCR | MCR3, MCR4, MCR1, MCR2 (4 Biến) | Không có | Độc lập |
4 | HRR | HRR4, HRR3, HRR2, HRR1 (4 biến) | Không có | Độc lập |
5 | ITAR | ITAR1, ITAR4, ITAR3, ITAR2 (4 biến) | Không có | Độc lập |
6 | OCR | OCR3, OCR1, OCR2 (3 Biến) | OCR4 và OCR5 | Độc lập |
AISQ | AISQ3, AISQ9, AISQ6, AISQ7, AISQ5, AISQ4, AISQ1, AISQ8, AISQ2 (9 Biến) | Không có | Phụ thuộc/ Trung gian | |
8 | AIQ | AIQ1, AIQ4 AIQ9, AIQ8, AIQ5, AIQ7, AIQ2, AIQ3, AIQ6 (9 Biến) | Không có | Phụ thuộc |
Tổng số biến quan sát độc lập: 30 biến | ||||
Tổng số biến quan sát phụ thuộc: 18 biến | ||||
Nguồn: Tập hợp bởi tác
giả
Mô hình NC được điều chỉnh lại theo phân tích EFA:
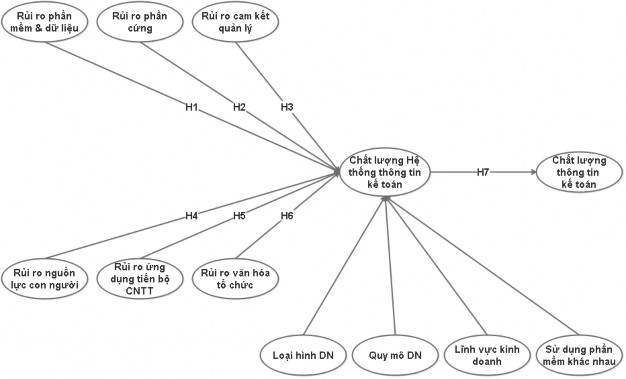
Hình 4.1 – Mô hình NC điều chỉnh (Nguồn: Xây dựng bởi tác giả)
Các giả thuyết NC điều chỉnh lại theo phân tích EFA
H1: Rủi ro phần mềm và dữ liệu có ảnh hưởng đến CLHTTTKT
H2: Rủi ro phần cứng có ảnh hưởng đến CLHTTTKT
H3: Rủi ro cam kết quản lý có ảnh hưởng đến CLHTTTKT
H4: Rủi ro nguồn lực con người có ảnh hưởng đến CLHTTTKT H5: Rủi ro ứng dụng tiến bộ CNTT có ảnh hưởng đến CLHTTTKT H6: Rủi ro văn hoá tổ chức có ảnh hưởng đến CLHTTTKT
H7: CLHTTTKT có ảnh hưởng lên CLTTKT Phân tích nhân tố khẳng định
Phân tích nhân tố khẳng định CFA cho nhóm các nhân tố độc lập:
Kết quả của phân tích EFA được tiếp tục chuyển sang phân tích nhân tố
khẳng định CFA để xác nhận lại sự phù hợp, các mối quan hệ nhân tố trong mô hình và độ tin cậy của thang đo khái niệm NC.
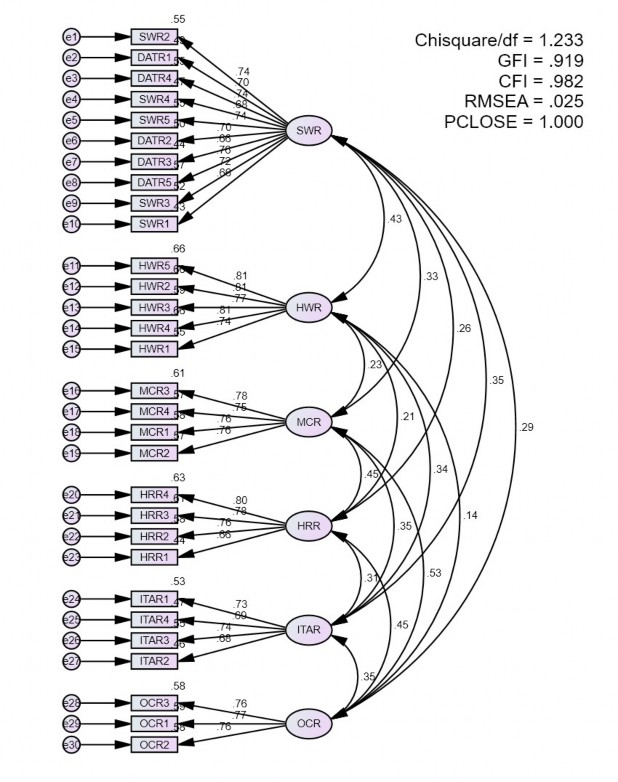
Hình 4.2 – Kết quả CFA nhóm biến độc lập theo dạng sơ đồ đã chuẩn hoá
(Nguồn: Kết quả được tập hợp qua phân tích từ phần mềm AMOS)