User Utterance: là câu dữ liệu đầu vào của người dùng
Hidden: là lớp ẩn được sử dụng trong thành phần NLU để vector hóa ngôn ngữ, phân loại ý định và trích xuất được các thông tin người dùng
Memory: là bộ nhớ lưu các giá trị vector hóa ngôn ngữ và ngữ cảnh hội thoại bao gồm cả slot
Slot: thông tin được trích xuất được lưu lại trong các câu nói người dùng
Action State: trạng thái action trước. Nó mang tính ngữ cảnh ở trong đoạn hội thoại
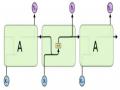
2.5.2 Mô hình Global-Locally Self-Attentive DST (GLAD)
Với các mô hình theo dõi trạng thái hội thoại khác thường xác định intent người dùng trực tiếp trên danh sách các đoạn hội thoại đã trainning cho bot sẽ gặp vấn đề về nhập nhằng xác định 1 intent trong các đoạn hội thoại có sử dụng cùng 1 intent. Tức là với cùng 1 câu nói người dùng xác định được 1 intent thì intent đó có thể được dùng nhiều trong các đoạn hội thoại. Với tư tưởng xác định cả ngữ cảnh cho từng đoạn hội thoại thì việc xác định intent nằm trong đoạn hội thoại nào sẽ tăng thêm độ chính xác.
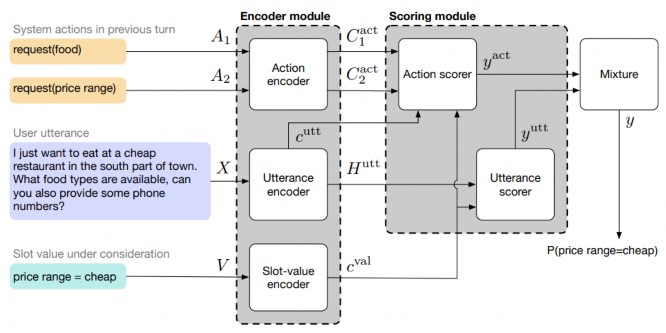
Hình 33: Mô hình Global-Locally Self-Attentive DST (GLAD) [21]
Các tham số đầu vào cho phần local và global là các giá trị intent người dùng (X), các slot và action state (C)
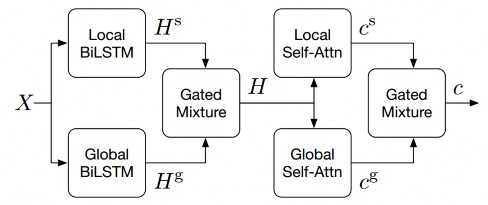
Hình 34 : Global-locally self-attentive encoder modul [21]
Việc dùng các slot trong mô hình cần lưu ý là sau kết thúc mỗi hội thoại thì nên xóa các slot không dùng nữa để tránh nhập nhằng xác định ví trí chính xác intent của người dùng trong danh sách các đoạn hội thoại mà bot được đào tạo.
CHƯƠNG 3 : XÂY DỰNG CHATBOT HỖ TRỢ NGƯỜI DÙNG LĨNH VỰC NGÂN HÀNG
Chương này sẽ mô tả từng bước xây dựng bài toán trên nền tảng mã nguồn mở Rasa. Phần thực nghiệm và đánh giá sẽ cho ta biết khả năng phục vụ của chatbot cũng như chỉ ra những điểm hạn chế của chatbot nhằm tìm cách cải tiến và tìm hướng đi mới cho việc xây dựng chatbot nhằm phục vụ các bài toán hỗ trợ người dùng trên nhiều lĩnh vực chứ không chỉ riêng trong lĩnh vực ngân hàng.
3.1 Bài toán
Có rất nhiều bài toán ứng dụng cho chatbot nhưng tôi chọn bài toán cho ngân hàng để giải quyết một số bài toán phức tạp như chuyển tiền và thanh toán nhằm đánh giá khả năng đáp ứng xử lý trong một số tác vụ khó của bot.
Hiện tại thì cũng có một số ngân hàng ở Việt Nam đã xây dựng chatbot trong lĩnh vực ngân hàng như MB bank, eximbank, TP bank… Hầu hết các ngân hàng hỗ trợ chatbot trên facebook cho phép người dùng thao tác một số đơn giản như kiểm tra số dư, truy vấn lãi suất, tỉ giá và có thể chuyển tiền trong giới hạn ít như MB cho phép chuyển dưới 1 triệu đồng.
Bài toán mà tôi xây dựng sẽ tập trung vào các chức năng hỗ trợ khách hàng cá nhân trên hệ thống ebanking. Các chức năng chính bao gồm:
- Thông tin tài khoản
- Truy vấn số dư
- Chuyển tiền: trong ngân hàng, ngoài ngân hàng, qua thẻ
- Lịch sử giao dịch
- Vay tiền
- Gửi tiền
- Thanh toán: điện, nước, điện thoại, vé máy bay…
- Thông tin các biểu phí
- Thông tin lãi suất, tỉ giá
3.2 Xây dựng chatbot hỗ trợ người dùng lĩnh vực ngân hàng
Cấu trúc hệ thống chatbot cho lĩnh vực ngân hàng sẽ được thiết kế như sau:
Lãi suất kỳ
hạn 12 tháng
Lãi suất vay
hay tiết kiệm
IONIC
RASA
NLU
intent :”interest” entity: “12 tháng”
DM
State tracker, policy, action
NLG
Template
Ebanking API
Hình 35: Cấu trúc chatbot cho hệ thống ebanking
Từ mô hình trên thì đầu vào hệ thống là một câu hỏi người dùng. Đầu ra là câu trả lời của bot. Các thành phần bên trong hệ thống chatbot sẽ đảm nhiệm như sau:
NLU: Có nhiệm vụ vector hóa ngôn ngữ, phân loại ý định người dùng và trích xuất ra các thông tin người dùng. Ví dụ câu đầu vào người dùng hỏi “Lãi suất kỳ hạn 12 tháng bao nhiêu?” thì hệ thống sẽ vector hóa nó rồi đối chiếu với các tập dữ liệu training đã được gán nhãn để đưa ra ý định là “interest”. Tiếp đến hệ thống trích xuất được thông tin với kỳ hạn là “12 tháng”.
DM: Dựa vào trạng thái và ngữ cảnh hội thoại để xác định ra action xử lý cho câu đầu vào trên. Thành phần này cũng có nhiệm vụ lấy dữ liệu từ hệ thống ebanking để phục vụ việc sinh dữ liệu trả lời của bot cho thành phần NLG. Ở ví dụ trên thì hệ thống xác nhận bot đang trong ngữ cảnh hỏi về thông tin lãi suất nhưng chưa rõ hỏi về lãi suất nào nên bot sẽ đưa ra quyết định hỏi lại người dùng. Trong trường hợp mà bot có đầy đủ thông tin hỏi về lãi suất nào thì sẽ lấy dữ liệu từ ebanking backend để trả về cho người dùng.
NLG: Bot sinh câu trả lời dựa vào dữ liệu từ thành phần DM theo các mẫu câu template đã được xây dựng trước.
Hiện tại có rất nhiều phương pháp làm chatbot do bên thứ 3 cung cấp như ahachat, Chatfuel, Messnow… dễ dàng xây dựng và tích hợp thông qua API nhưng lại không đảm bảo tính bảo mật về mặt dữ liệu người dùng nên trong bài toán này tôi quyết định sử dụng mã nguồn mở Rasa để xây dựng hệ thống chatbot riêng nhằm mục đích làm
chủ dữ liệu và bảo mật hệ thống lẫn thông tin người dùng. Bên cạnh đó với Rasa tôi có thể tùy chỉnh một số cơ chế học máy cho tương thích với tiếng việt hay có thể tùy ý kết nối tới nhiều hệ thống khác để trả lại dữ liệu cho chatbot. Hiện tại Rasa đang có cộng đồng phát triển mạnh với hơn 3500 thành viên, số lượng download là hơn 500000. Các tính năng và bug mới liên tục được cập nhật và sửa đổi. Trên thực tế thì Rasa cũng đã áp dụng thành công nhiều bài toán cho các lĩnh vực như: sức khỏe, bảo hiểm, du lịch, ngân hàng và viễn thông. Đó cũng chính là những động lực giúp em lựa chọn Rasa là framework để xây dựng chatbot giải quyết bài toán này. Chi tiết về việc tìm hiểu và làm chủ công cụ Rasa này sẽ đề cập trong mục 3 của chương.
Về phần xây dựng giao diện hiển thị và tương tác người dùng với bot tôi sử dụng ionic framework cho phép dễ dàng build app các nền tảng ios và android.
Một khía cạnh khác cũng rất quan trọng trong việc xây dựng hệ thống chatbot và là yếu tố gần như quyết định bot có đáp ứng được yêu cầu người dùng hay không đó là việc xây dựng tập dữ liệu tranning cho bot. Việc xây dựng dữ liệu cho bot sẽ được đề cập chi tiết trong mục 3 của chương.
3.3 Ứng dụng RASA xây dựng chatbot
Rasa cung cấp cho ta 2 phương pháp chính xây dựng dữ liệu trainning cho bot:
- Pretrained Embeddings (Intent_classifier_sklearn) : Việc phân loại ý định người dùng sẽ dựa trên các tập dữ liệu được lọc trước, sau đó được sử dụng để thể hiện từng từ trong thông điệp người dùng dưới dạng từ nhúng (word embedding) hay biểu diễn ngôn ngữ dưới dạng vector(word2vec). Các tập dữ liệu này có thể được cung cấp từ Spacy hoặc MITIE …
- Supervised Embeddings (Intent_classifier_tensorflow_embedding): Nhúng được giám sát. Với phương pháp này thì người dùng sẽ phải tự xây dựng dữ liệu từ đầu do ko có dữ liệu đào tạo sẵn có. Nhưng với các bài toán trong một lĩnh vực nhỏ thì nó sẽ đảm bảo tính chính xác hơn nhiều và tránh dư thừa dữ liệu so với phương pháp ở trên.
Với bài toán tập trung vào miền đóng như trợ lý ảo hỗ trợ dịch vụ ebanking, cộng thêm việc khó tìm kiếm tập dữ liệu pretrained (do hầu hết dữ liệu pretrained đều là tiếng anh) thì ta không cần sử dụng tập dữ liệu đào tạo từ trước (pretrained word embeddings) thay vào đó thì ta sẽ tự tạo tập dữ liệu training riêng của mình. Điều này cũng đảm bảo bot có thời gian training ngắn mà độ chính xác cao hơn.
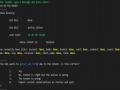
Một số cấu hình trong Rasa mà tôi lựa chọn để training cho bot bao gồm từ việc phân tích câu, phân loại ý định(intent) đến trích chọn thông tin người dùng… như sau:
language: vi
##pipeline: tensorflow_embedding
pipeline:
- name: tokenizer_whitespace
- name: ner_crf
- name: ner_synonyms
- name: intent_featurizer_count_vectors
- name: intent_classifier_tensorflow_embedding intent_tokenization_flag: true intent_split_symbol: "+"
Hình 362 : Cấu hình pipeline xử lý ngôn ngữ tự nhiên
Thuật toán tách từ tôi sử dụng tokenizer_whitespace tức các từ có thể phân tách bởi dấu cách. Điều này có thể sai trong một số trường hợp đối với từ ghép.
Để trích chọn thông tin (slot filter) thì tôi cấu hình dùng mô hình CRF. Bên cạnh đó cũng hỗ trợ cấu hình việc nhận dạng các từ đồng nghĩa (ner_synonyms). Rasa cũng tích hợp với framework hỗ trợ trích xuất thông tin nổi tiếng như duckling có hỗ trợ tiếng việt và rất thông minh trong việc trích xuất được thời gian và dữ liệu số như tiền tệ. Với bài toán demo thì CRF là một lựa chọn hợp lý hơn khi đã tích hợp sẵn trong Rasa mà không phải cấu hình thêm như duckling.
Thành phần chính là trình phân loại ý định intent_classifier_tensorflow_embedding dựa trên kỹ thuật starspace [9] đang được facebook phát triển.
3.4 Xây dựng dữ liệu chatbot
Nguồn dữ liệu xây dựng chatbot hỗ trợ hệ thống ebanking của ngân hàng được thu thập và tham khảo qua một số người dùng, một số chatbot cho ngân hàng ở Việt Nam như eMbee(MB bank), Timo (VP bank) và demo chatbot về ngân hàng của FPT.AI.
Một đoạn hội thoại giữa người và bot là để giải quyết một vấn đề nào đó. Ví dụ đoạn hội thoại hỏi về thông tin lãi suất:
Bot | |
Cho tôi biết thông tin lãi suất | Bạn hỏi lãi suất vay hay tiết kiệm |
Lãi suất tiết kiệm | Mời bạn nhập kỳ hạn |
13 tháng | Lãi suất 13 tháng là: 8,1% |
Có thể bạn quan tâm!
-
 Nghiên cứu và xây dựng chatbot hỗ trợ người dùng trong ngân hàng - 3
Nghiên cứu và xây dựng chatbot hỗ trợ người dùng trong ngân hàng - 3 -
 Một Số Kỹ Thuật Sử Dụng Trong Chatbot
Một Số Kỹ Thuật Sử Dụng Trong Chatbot -
 Nghiên cứu và xây dựng chatbot hỗ trợ người dùng trong ngân hàng - 5
Nghiên cứu và xây dựng chatbot hỗ trợ người dùng trong ngân hàng - 5 -
 Nghiên cứu và xây dựng chatbot hỗ trợ người dùng trong ngân hàng - 7
Nghiên cứu và xây dựng chatbot hỗ trợ người dùng trong ngân hàng - 7 -
 Nghiên cứu và xây dựng chatbot hỗ trợ người dùng trong ngân hàng - 8
Nghiên cứu và xây dựng chatbot hỗ trợ người dùng trong ngân hàng - 8 -
 Nghiên cứu và xây dựng chatbot hỗ trợ người dùng trong ngân hàng - 9
Nghiên cứu và xây dựng chatbot hỗ trợ người dùng trong ngân hàng - 9
Xem toàn bộ 81 trang tài liệu này.
Đây cũng chính là một khung kịch bản để người dùng có thể hỏi về thông tin lãi suất. Và ta cũng có một đoạn hội thoại khác để hỏi về thông tin lãi suất như sau:
Bot | |
Lãi suất tiết kiệm 1 năm là bao nhiêu | Lãi suất tiết kiệm 12 tháng là: 8,1% |
Như vậy với bài toán xây dựng dữ liệu chatbot theo miền đóng là ta đi xây dựng danh sách các khung kịch bản như trên.
Ứng với mỗi một câu trong đoạn hội thoại là một ý định (intent). Ý định của người dùng có thể là một danh sách các câu nói có cùng chung một thông điệp. Ví dụ với mục đích là chào hỏi thì người dùng có thể nói “xin chào”, “chào bạn”…
Để ý tiếp ta thấy trong mỗi intent thì cần trích xuất ra thông tin người dùng. Đó chính là các entity. Các entity này có thể được lưu lại thông tin vào các slot để phục vụ cho các hành động sau của bot. Như ở ví dụ trên ta có thông tin tháng lãi suất là “13 tháng”
Xây dựng câu trả lời cho bot
Việc xây dựng chatbot sẽ thực hiện qua một số bước chính như hình 3.2:
Xây dựng ý định (intent)
Xây dựng entity (slot)
Xây dựng khung kịch bản
Đào tạo cho bot
Test, phân tích cải tiến bot
Hình 37.3 : Các bước xây dựng chatbot
3.4.1 Xây dựng ý định
Việc xây dựng ý định sẽ theo nguyên tắc là những mẫu câu hỏi của người dùng phổ biến nhất, thông dụng nhất có thể. Hiện tại bot đang hỗ trợ khoảng 30 intent. Ví dụ cho
một ý định muốn xem thông tin số dư tài khoản thì người dùng có thể hỏi nhiều câu như sau:
## intent:balance
- số dư
- số tiền trong tài khoản của tôi
- truy vấn số dư
- số dư tài khoản
Hình 38.4 : Xây dựng ý định người dùng
3.4.2 Xây dựng entity
Entity là các thông tin trích xuất từ ý định người dùng. Slot là các thông tin được trích lọc trong các câu nói người dùng được bot lưu lại trong bộ nhớ để sử dụng trong các action hay câu trả lời của bot và tránh việc hỏi lại thông tin từ phía người dùng. Việc trích xuất slot được cấu hình theo CRF như đã đề cập ở trên. Hiện tại bot đang được cấu hình khoảng 15 slot.
entities:
- location
- card
- receiver
- money
- otp
- content
- number
- account
- bank
- name
- data
- term
- branch
- count
- short_name
Hình 3.5 : Danh sách các thông tin người dùng
3.4.3 Xây dựng câu trả lời cho bot
Ứng với mỗi câu hỏi của người dùng thì ta cũng phải xây dựng các mẫu câu (template) trả lời của bot tương ứng :
utter_balance:
- text: "Số dư tài khoản của quý khách là {&balance}"
- text: "Số tiền trong tài khoản là : {&balance}"
Hình 39 : Mẫu câu trả lời của bot cho ý định hỏi số dư tài khoản