doanh nghiệp trong 1.317 doanh nghiệp được dự báo là không vỡ nợ trong 3,5 năm tới từ năm 1972 đến năm 1975. Chỉ có 18 doanh nghiệp hay 6,2% đã đệ đơn xin vỡ nợ . Tuy nhiên, 66 doanh nghiệp trong số 290 doanh nghiệp được dự báo vỡ nợ đã không trải qua tình trạng vỡ nợ. Ngoài ra, trong số 100 doanh nghiệp thuộc danh sách 1.317 doanh nghiệp được dự báo không vỡ nợ, không có doanh nghiệp nào vỡ nợ. Mức độ chính xác trong phân loại các doanh nghiệp vỡ nợ dao động từ 20,5% đến 79,2%. Deakin đã áp dụng mô hình năm biến cho 47 doanh nghiệp vỡ nợ trong giai đoạn từ 1972 đến 1974. Mô hình này bao gồm các nguyên tắc trong mô hình tuyến tính và mô hình bậc hai, thì khá chính xác trong việc phân loại một doanh nghiệp vỡ nợ, với mức độ phân loại chính xác là 83%, 2% phân loại sai và 15% không phân loại được. Ông đã kết luận rằng sử dụng các tỷ số tài chính trong mô hình phân loại khác biệt cơ bản có thể dự báo nguy cơ vỡ nợ doanh nghiệp với độ chính xác cao, và vì ước tính của mô hình về số lượng các doanh nghiệp thất bại thì vượt quá số lượng doanh nghiệp thất bại thực tế, nên mô hình có tính hữu dụng hạn chế khi việc phân loại nhầm các doanh nghiệp không vỡ nợ thì khá tốn kém.
+ Mô hình dự báo của Edmister (1972)
Các nghiên cứu của Beaver (1966), Altman (1968), và Deakin (1972) chỉ ra rằng việc phân tích các tỷ số được lựa chọn rất hữu ích trong việc dự báo vỡ nợ của các doanh nghiệp có quy mô tài sản trung bình và lớn, do khó thu thập được đầy đủ số liệu từ các công ty quy mô nhỏ. Vào năm 1972, Robert O. Edmister cố gắng áp dụng một kỹ thuật tương tự mô hình của Altman cho các doanh nghiệp quy mô nhỏ. Mục đích của nghiên cứu của Edminster là để phát triển và kiểm tra một số phương pháp phân tích tỷ số tài chính để dự báo nguy cơ vỡ nợ của các doanh nghiệp nhỏ. Trong nghiên cứu này, vỡ nợ doanh nghiệp được xác định là rủi ro tín dụng thông qua việc sử dụng số liệu từ hồ sơ cho vay của Hội Quản lý doanh nghiệp nhỏ (Small Business Administration - SBA). Mẫu nghiên cứu bao gồm 42 doanh nghiệp có rủi ro tín dụng và 42 doanh nghiệp không có rủi ro tín dụng từ dữ liệu của SBA trong giai đoạn 1954 - 1969. Nghiên cứu này xem xét 19 tỷ số tài chính và 5 phương pháp phân tích hiện hành. Các tỷ số đã được phát hiện là những biến độc lập quan trọng trong dự vỡ nợ doanh nghiệp trong các nghiên cứu thực nghiệm trước đó. Edmister đã tối thiểu hóa các vấn đề về đa cộng tuyến bằng cách loại bỏ các biến có tương quan cao và bằng cách sử dụng phương pháp phân tích đa khác biệt tuyến tính từng bước trong nghiên cứu của mình. Khung khổ phương pháp luận của ông đã tập trung vào việc kiểm tra mức độ tỷ số, xu hướng trong 3 năm của một tỷ số và sự kết hợp xu thế của các ngành cho từng tỷ số và mức độ ngành cho mỗi tỷ số như
là một biến độc lập cho các doanh nghiệp quy mô nhỏ bị vỡ nợ. Ông đã áp dụng kỹ thuật hồi quy không - một. Mối quan hệ giữa các hệ số hồi quy là một hệ số tỷ lệ trong trường hợp hai nhóm. Ông đã phát triển một mô hình hàm số khác biệt có 7 biến. Mô hình này đã đạt được sự chính xác trong phân loại đến 93% và nó dường như là một phương pháp thành công để phân tích khác biệt cho những doanh nghiệp nhỏ vỡ nợ và không vỡ nợ. Những kết quả thu được cho thấy rằng sức mạnh dự báo của các tỷ số có tính tích lũy. Sức mạnh dự báo của các tỷ số phân tích phụ thuộc vào cả phương pháp phân tích lựa chọn và sự lựa chọn tỷ số. Kết quả tương tự Altman (1968) khi cho thấy sự cải thiện mức độ chính xác trong dự báo vượt qua mô hình của Beaver (1966) trong năm đầu tiên trước vỡ nợ Tuy nhiên, không giống như Beaver và Altman - những người đã phát hiện rằng một báo cáo tài chính là đủ cho sự phân loại chính xác, Edmister kết luận rằng cần phải có ba báo cáo tài chính trong 3 năm liên tiếp để có thể phân tích hiệu quả các doanh nghiệp quy mô nhỏ.
Mô hình phân tích doanh nghiệp quy mô nhỏ của Edmister như sau:
Z = 0,951 - 0,423X1 - 0,293X2 -0,482X3 + 0,277X4 - 0,425X5 - 0,352X6 - 0,924X7
Có thể bạn quan tâm!
-

 Nghiên cứu cách tiếp cận kế toán và cách tiếp cận thị trường trong dự báo vỡ nợ của doanh nghiệp Việt Nam - 1
Nghiên cứu cách tiếp cận kế toán và cách tiếp cận thị trường trong dự báo vỡ nợ của doanh nghiệp Việt Nam - 1 -
 Nghiên cứu cách tiếp cận kế toán và cách tiếp cận thị trường trong dự báo vỡ nợ của doanh nghiệp Việt Nam - 2
Nghiên cứu cách tiếp cận kế toán và cách tiếp cận thị trường trong dự báo vỡ nợ của doanh nghiệp Việt Nam - 2 -
 = - 1,369 + 13,855X1 + 0,060X2 - 0,601X3 + 0,3 96X4 + 0,194X5
= - 1,369 + 13,855X1 + 0,060X2 - 0,601X3 + 0,3 96X4 + 0,194X5 -
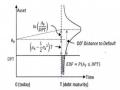 Nghiên Cứu Theo Cách Tiếp Cận Kế Toán Tại Việt Nam
Nghiên Cứu Theo Cách Tiếp Cận Kế Toán Tại Việt Nam -
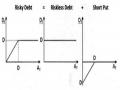 Một Số Nghiên Cứu Mô Hình Kmv- Merton Tại Việt Nam
Một Số Nghiên Cứu Mô Hình Kmv- Merton Tại Việt Nam -
 Các Nghiên Cứu So Sánh Cách Tiếp Cận Kế Toán Và Tiếp Cận Thị Trường Trong Dự Báo Vỡ Nợ Doanh Nghiệp
Các Nghiên Cứu So Sánh Cách Tiếp Cận Kế Toán Và Tiếp Cận Thị Trường Trong Dự Báo Vỡ Nợ Doanh Nghiệp
Xem toàn bộ 186 trang tài liệu này.
Trong đó:
Z = Biến phụ thuộc, nhận giá trị 1 đối với các doanh nghiệp không vỡ nợ và 1 cho các doanh nghiệp vỡ nợ.

X1 = 1 nếu Tiền / Nợ ngắn hạn <0,05; 0 nếu ngược lại. X2 = 1 Vốn CSH / Doanh thu < 0,07; 0 nếu ngược lại.
X3 = 1 nếu (Vốn lưu động ròng / Doanh thu) / Trung bình ngành < -0,02; 0 nếu ngược lại.
X4 = 1 nếu (Nợ ngắn hạn/ Vốn CSH) / Trung bình ngành < 0,48; 0 nếu ngược lại.
X5 = 1 nếu (Hàng tồn kho / Doanh thu) / Trung bình ngành <0,04 và có xu hướng tăng; 0 nếu ngược lại.
X6 = 1 nếu Tỷ số khả năng thanh toán nhanh / Trung bình ngành < 0,34 và có xu hướng giảm; 0 nếu ngược lại.
X7 = 1 nếu Tỷ số khả năng thanh toán nhanh / Trung bình ngành có xu hướng tăng; 0 nếu ngược lại.
+ Mô hình dự báo của Blum (1974)
Năm 1974, Marc Blum đã phát triển mô hình doanh nghiệp vỡ nợ (Failing
Company Model - FCM) để hỗ trợ các bộ phận chống độc quyền của Bộ Tư pháp trong việc đánh giá khả năng vỡ nợ của doanh nghiệp. Blum đã xây dựng một mô hình phân tích đa khác biệt để đánh giá khả năng vỡ nợ. Nghiên cứu của ông đã định nghĩa vỡ nợ dựa trên các tiêu chí là mất khả năng chi trả các khoản nợ đến hạn, bước vào thủ tục hoặc quy trình vỡ nợ, hoặc thỏa thuận với các chủ nợ để giảm nợ. Blum đã thu thập số liệu trong ít nhất 3 đến 8 năm cho 115 doanh nghiệp vỡ nợ từ năm 1954 đến năm 1968. Chỉ những doanh nghiệp lớn (có khoản nợ tối thiểu là 1 triệu đôla tại thời điểm vỡ nợ) được lựa chọn vì các doanh nghiệp nhỏ hơn thì hiếm khi tuân theo chính sách chống độc quyền. Trong số các doanh nghiệp vỡ nợ được nghiên cứu, 90% đệ đơn vỡ nợ theo Đạo luật vỡ nợ Liên bang, và 10% là theo các thỏa thuận cá nhân. Để phù hợp giữa các doanh nghiệp vỡ nợ và không vỡ nợ, ông đã lựa chọn mẫu theo từng cặp trên cơ sở ngành, doanh thu, công nhân viên và năm tài chính. Phân tích khác biệt đã được sử dụng để xác định tính chính xác trong phân loại của các tỷ số. Trong nghiên cứu của Blum, việc lựa chọn các biến được dựa trên khái niệm doanh nghiệp vỡ nợ như là các nguồn lực tài chính với xác suất vỡ nợ được thể hiện qua dòng tiền kỳ vọng. Mô hình đã được xây dựng với ba yếu tố theo khung khổ dòng tiền: tính thanh khoản; khả năng sinh lợi và khả năng biến đổi. Blum đã lựa chọn 12 biến để đo lường hệ số hồi quy này của dòng tiền. Kết quả chỉ ra rằng các doanh nghiệp vỡ nợ và không vỡ nợ có thể được dự báo dựa trên một mô hình thống kê đa biến bao gồm các tỷ số tài chính được coi như các biến độc lập. Mô hình Marc Blum đạt mức chính xác từ 93% đến 95% khi vỡ nợ diễn ra trong một năm của kỳ báo cáo. Độ chính xác giảm xuống 80% vào năm thứ hai trước vỡ nợ, và xuống khoảng 70% vào các năm thứ ba, thứ tư, và thứ năm trước vỡ nợ. Sự khác biệt giữa các doanh nghiệp vỡ nợ và không vỡ nợ không có ý nghĩa thống kê vào năm thứ sáu trước vỡ nợ.
+ Mô hình dự báo của Fulmer, Moon, Gavin, and Erwin (1984)
Mô hình nghiên cứu với 30 doanh nghiệp vừa và nhỏ trong các ngành sản xuất, bán lẻ và dịch vụ. Kết quả mô hình 9 biến để dự báo để phân loại doanh nghiệp vỡ nợ và không vỡ nợ như sau:
H = - 6,075 + 5,528V1 + 0,212V2 + 0,073V3 + 1,270V4
- 0,120V5 + 2,335V6 + 0,575V7 + 1,083V8 + 0,894V9
Trong đó: H = Chỉ số tổng hợp V1 = LN giữ lại / TTS
V2 = DT/TTS
V3 = LN trước thuế và lãi vay / Vốn CSH V4 = Tiền /Tổng nợ
V5 = Nợ / TTS V6 = NNH/TSNH
V7 = Logarit của tài sản cố định hữu hình V8 = VLĐ / Tổng nợ
V9 = Logarit của LN trước thuế và lãi vay / Lãi vay
Trong mô hình 9 biến của Fulmer và cộng sự, các doanh nghiệp có H-score nhỏ hơn 0 được phân loại thành doanh nghiệp vỡ nợ, và các doanh nghiệp có H-score lớn hơn 0 được phân loại thành các doanh nghiệp không vỡ nợ. Mô hình này đã đạt được mức độ phân loại chính xác tổng thể lần lượt là 98% và 81% cho năm thứ nhất và năm thứ hai trước vỡ nợ. Mặc dù độ chính xác của mô hình tương đối cao với mẫu lựa chọn tuy nhiên do lượng doanh nghiệp nghiên cứu ít, chỉ trên một số ngành nghề và là doanh nghiệp nhỏ nên mô hình không đại diện cho các doanh nghiệp.
+ Nghiên cứu của Ben McClure (2004)
Qua nghiên cứu của mình, ông khẳng định ích lợi của mô hình Z-Score vì tính tiện lợi của mô hình dự trên các số liệu có sẵn. Ông đưa ra các khuyến nghị đối với các nhà đầu tư nên thường xuyên kiểm tra điểm số Z-Score cho danh mục đầu tư của mình để hỗ trợ trong các quyết định. Do có những khuyến khuyết của mô hình nên việc kiểm tra không nhất thiết phải sử dụng để dự báo vỡ nợ doanh nghiệp mà thông qua biến động của chỉ số Z-Score để đánh giá biến động sức khỏe của doanh nghiệp tốt lên hay xấu đi.
Mặc dù nghiên cứu cho việc vận dụng mô hình Z-Score cho các nhà đầu tư sử dụng trong các quyết định của mình nhưng nghiên cứu vẫn chưa đưa ra được cụ thể là với chỉ số như vậy thì mức độ rủi ro ở mức nào và có đầu tư hay không đầu tư cho từng doanh nghiệp này.
* Mô hình phân tích logit và probit
Một số nhà nghiên cứu gần đây đã sử dụng các mô hình xác suất đa biến có điều kiện trong nghiên cứu dự báo vỡ nợ doanh nghiệp. Hai kỹ thuật thống kê là phân tích logit và probit dựa vào một hàm xác suất tích lũy cung cấp xác suất có điều kiện của một quan sát thuộc về một nhóm nhất định, căn cứ vào các đặc điểm tài chính của quan sát đó (Jones, 1987; Zopounidis và Dimitras, 1998). Cả hai kỹ thuật logit và probit đều
được sử dụng trong phân loại và hồi quy và là các mô hình xác suất phi tuyến, trong đó biến phụ thuộc (các nghiên cứu về phá sản doanh nghiệp bao gồm phá sản và không phá sản) không phải là biến liên tục nhưng đại diện cho một lựa chọn cụ thể (Kmenta, 1971). Ngoài ra, kỹ thuật xác suất tối đa (maximum likelihood techniques) cũng được sử dụng thông qua việc ước tính một nhóm các hệ số hồi quy có nhiều khả năng làm tăng mức độ ý nghĩa của các quan sát trong số liệu vỡ nợ. Trong các nghiên cứu về dự báo vỡ nợ doanh nghiệp, phân tích logit đo lường trọng số của các biến độc lập và chấm điểm cho mỗi doanh nghiệp. Mô hình Z-score có thể được sử dụng để xác định xác suất một doanh nghiệp sẽ vỡ nợ, khi đó xác suất vỡ nợ là:
P(B) = 1/(l+e-z)
Trong đó: Z = a + P1X1 + ... + PnXn
Z = Chỉ số xác suất được xác định bởi các tỷ số tài chính và trọng số nhân tố.
Các hệ số hồi quy Pi được đo lường để tối đa hóa xác suất vỡ nợ chung của các doanh nghiệp vỡ nợ và xác suất của các doanh nghiệp không vỡ nợ (Jones, 1987). Phân tích probit cũng tương tự như phân tích logit, ngoại trừ trong các ước tính xác suất thì phân tích logit sử dụng hàm logistic tích lũy, trong khi phân tích probit sử dụng hàm phân phối chuẩn tích lũy (Dismitras và cộng sự, 1996).
+ Mô hình dự báo của Ohlson (1980)
Nghiên cứu của Ohlson (1980) là nghiên cứu đầu tiên sử dụng hồi quy đa logistic (Multiple Logistic Regression – Logit) để xây dựng mô hình xác suất vỡ nợ trong dự báo vỡ nợ doanh nghiệp. Ông đã lựa chọn 105 doanh nghiệp công nghiệp vỡ nợ trong giai đoạn 1970 - 1976. Tất cả các doanh nghiệp vỡ nợ phải được giao dịch trên thị trường chứng khoán (SEC) hoặc giao dịch trên thị trường OTC trong giai đoạn 3 năm trước vỡ nợ và 2.058 doanh nghiệp không vỡ nợ được lựa chọn ngẫu nhiên. Mẫu các doanh nghiệp không vỡ nợ được thu thập từ COMPUSTAT. Mục đích của nghiên cứu này là xây dựng ba mô hình có thể dự báo vỡ nợ của doanh nghiệp trong 3 năm trước khi vỡ nợ thực sự. Các mô hình được xây dựng theo 9 biến độc lập sau:
X1 = logarit (TTS / Chỉ số GDP) X2 = Tổng nợ / TTS
X3 = VLĐ/TTS X4 = NNH/ TSNH
X5 = 1 nếu tổng nợ > TTS; 0 nếu ngược lại
X6 = LN ròng / TTS
X7 = Ngân quỹ từ hoạt động kinh doanh / Tổng nợ
X8 = 1 nếu lợi nhuận ròng < 0 trong hai năm cuối cùng; 0 nếu ngược lại
X9 = (Thu nhập ròng (t) – Thu nhập ròng(t-1)) / (Thu nhập ròng(t) + Thu nhập ròng(t-1))
Mô hình đã đạt được độ chính xác phân loại tổng thể là 85,1%, trong đó 87,6% cho các doanh nghiệp vỡ nợ và 82,6% cho các doanh nghiệp không vỡ nợ. Nghiên cứu cho thấy rằng hiệu quả của mô hình logit không tốt hơn mô hình phân tích đa khác biệt. Ohlson kết luận rằng các khiếm khuyết của mô hình do vấn đề đa cộng tuyến giữa các biến gây nên.
+ Mô hình dự báo của Zmijewski (1984)
Trong nghiên cứu của Zmijewski (1984), hai vấn đề mang tính phương pháp luận đã được xem xét có mối liên quan tới sự ước tính các mô hình dự báo vỡ nợ, đó là choice-based sample biases và sample selection biases. Dựa trên 40 doanh nghiệp vỡ nợ và 800 doanh nghiệp không vỡ nợ, mô hình của Zmijewski là mô hình được sử dụng phổ biến nhất bởi các nhà nghiên cứu kế toán (Grice & Dugan, 2003). Zmijewski đã sử dụng kỹ thuật probit để xây dựng mô hình dự báo nguy cơ vỡ nợ doanh nghiệp. Tỷ lệ chính xác của mô hình Zmijewski cho mẫu ước tính là 99%. Tổng thể các doanh nghiệp trong nghiên cứu của Zmijewski bao gồm tất cả các doanh nghiệp niêm yết trên thị trường chứng khoán New York và thị trường chứng khoán Mỹ trong giai đoạn 1972 – 1978 và có mã SIC nhỏ hơn 6000. Điều đó có nghĩa là các doanh nghiệp thuộc ngành tài chính, dịch vụ và quản lý công không được xem xét trong nghiên cứu này.
Zmijewski định nghĩa các doanh nghiệp vỡ nợ là hành động đệ đơn vỡ nợ. Các doanh nghiệp bị vỡ nợ được xác định là bị vỡ nợ nếu đã đệ đơn kiến nghị vỡ nợ trong giai đoạn này và được xác định là không bị vỡ nợ nếu không đệ đơn. Mẫu ước tính cuối cùng trong nghiên cứu của Zmijewski bao gồm 40 doanh nghiệp vỡ nợ và 800 doanh nghiệp không vỡ nợ và một mẫu để dành (hold-out sample) gồm 41 doanh nghiệp vỡ nợ và 800 doanh nghiệp không vỡ nợ. Hàm probit được xây dựng với các biến và ước tính các hệ số hồi quy từ nghiên cứu của Zmijewski được xác định như sau:
Zmijewski = – 4,3 – 4,5X1 + 5,7X2 + 0,004X3
Trong đó: X1 = LN ròng / TTS
X2 = Tổng nợ / TTS X3 = TSNH/NNH
Trong khi Altman sử dụng tỷ số LN trước thuế và lãi vay/TTS (EBIT/TA) để đo lường khả năng sinh lợi thì Zmijewski sử dụng tỷ số lợi nhuận ròng/TTS (NI/TA). Cũng giống như hàm logit, hàm probit đưa ra các giá trị 0 và 1. Zmijewski đã phân loại chính xác các doanh nghiệp theo cách khác Ohlson (1980). Các doanh nghiệp với xác suất lớn hơn hoặc bằng 0,5 được phân vào nhóm phá sản hoặc có dữ liệu hoàn chỉnh. Các doanh nghiệp có xác suất nhỏ hơn 0,5 được phân vào nhóm không vỡ nợ hoặc có số liệu chưa hoàn chỉnh. Mô hình probit của Zmijewski được ưa thích trong so sánh với MDA vì hàm probit đưa ra hai giá trị là 0 và 1 và dễ suy luận kết quả. Đây cũng là trường hợp của mô hình logit. Như đã đề cập trước đó, Zmijewski (1984) đã cố gắng tránh lựa chọn lệch (choice-based sample bias). Ông đã quan sát thấy rằng hầu hết các mô hình dự báo vỡ nợ trước đó đều có hiện tượng này.
+ Mô hình của Fulmer (1984):
Fulmer (1984) nghiên cứu với 30 doanh nghiệp vỡ nợ và 30 doanh nghiệp không vỡ nợ tại Mỹ với quy mô doanh nghiệp nhỏ. Mô hình được Fulmer đưa ra như sau:
H = 5,528 (V1) + 0,212 (V2) + 0,073 (V3) + 1,270 (V4) - 0,120 (V5) + 2,335
(V6) + 0,575 (V7) + 1,083 (V8) + 0,894 (V9) - 6,075.
Trong đó: H = Chỉ số tổng hợp V1 = LN giữ lại/TTS;
V2: DT/TTS;
V3: LN trước thuế và lãi vay/vốn CSH; V4: dòng tiền/tổng số nợ;
V5: Nợ/TTS; V6: NNH/TTS;
V7: Log [TTS hữu hình];
V8: Vốn hoạt động thuần/tổng số nợ; V9: Log EBIT/lãi.
Với H < 0 thì doanh nghiệp vỡ nợ; mô hình với độ chính xác đạt tỷ lệ chính xác 81% so với một năm trước khi vỡ nợ. Ngoài các vấn đề như mô hình Z-Score gặp phải
thì điểm yếu của mô hình là mẫu không đại diện cho các doanh nghiệp nên gặp khó khi áp dụng thực tế.
+ Mô hình dự báo của Zavgren (1985)
Nghiên cứu đã sử dụng kỹ thuật logit để phát triển và kiểm tra một mô hình dự báo vỡ nợ mới. Zavgren đã lựa chọn một mẫu các doanh nghiệp vỡ nợ và không vỡ nợ sử dụng phương pháp cặp đôi theo ngành và quy mô tài sản. Mẫu nghiên cứu bao gồm 45 doanh nghiệp vỡ nợ và 45 doanh nghiệp không vỡ nợ đều thuộc ngành sản xuất. Nghiên cứu không bao gồm ngành bán sỉ và bán lẻ trong mẫu. Số liệu 5 năm được thu thập cho mỗi doanh nghiệp. Thông tin báo cáo tài chính được lấy từ các hồ sơ COMPUSTAT. Các tỷ số được lựa chọn dựa trên nghiên cứu của Pinches và cộng sự (1973) – người đã sử dụng phân tích nhân tố để tìm ra các tỷ số tài chính phù hợp nhất. Các tỷ số và mô hình của Zavgren phân loại dự báo vỡ nợ như sau:
Yi = - 0,23883 – 0,00108X1 + 0,01583X2 + 0,1078X3 – 0,03074X4
– 0,0086X5 + 0,0435X6 – 0,0011X7
P = (1 + exp{-Yi}-1), do đó Yi = log[P / (1 -P)]
Trong đó: P = Xác suất thất bại tổng thể
X1 = Vòng quay hàng tồn kho (Hàng tồn kho / DT)
X2 = Vòng quay khoản phải thu (Khoản phải thu / Hàng tồn kho) X3 = Tỷ lệ tiền (Tiền / TTS)
X4 = Khả năng thanh khoản ngắn hạn (TSNH /NNH) X5 = Lợi tức đầu tư (Tổng thu nhập / Tổng vốn)
X6 = Đòn bẩy tài chính (Nợ / Tổng vốn)
X7 = Vòng quay vốn (DT /Tài sản đầu tư ròng)
Mô hình có tỷ lệ chính xác trong dự báo phân loại doanh nghiệp lần lượt là 82%, 83%, 72%, 73% và 80% trong 5 năm trước vỡ nợ. Tuy nhiên, hiệu quả mô hình logit vẫn không được cải thiện. Sự chính xác trong phân loại cho những năm trước thấp hơn đáng kể so với mô hình của Altman (1968, 1983 và 1993). Zavgren đã xác lập mô hình từ một mẫu để dành bao gồm 16 doanh nghiệp vỡ nợ và 16 doanh nghiệp không vỡ nợ trong hai năm 1979 và 1980. Số liệu được thu thập từ thị trường chứng khoán New York. Mô hình có tỷ lệ sai lệch 31% khi áp dụng cho mẫu để dành (hold-out sample), hay 69% chính xác trong dự báo phân loại doanh nghiệp trong 5 năm.
Có thể nhận thấy trong suốt thời gian qua, các nhà nghiên cứu theo cách tiếp cận