HL= B0 + B1*DV + B2*ATTP + B3*PV + B4*NV + B5*CS
Tác giả kí hiệu như sau;
- DV: Dịch vụ (X1)
- ATTP: An toàn thực phẩm (X2)
- PV: Phục vụ (X3)
- NV: Nhân viên (X4)
- CS: Cơ sở vật chất (X5)
- HL: Sự hài lòng của khách hàng
* Kiểm định hệ số tương quan
Dữ liệu dùng trong phân tích hồi quy tương quan được người nghiên cứu lựa chọn là dữ liệu chuẩn hóa (được xuất ra từ phần mềm SPSS sau quá trình phân tích nhân tố khám phá). Để xác định mối quan hệ nhân quả giữa các biến trong mô hình, bước đầu tiên ta cần phân tích tương quan giữa các biến xem thử có mối liên hệ tuyến tính giữa biến độc lập và biến phụ thuộc hay không. Kết quả của phần phân tích này dù không xác định được mối quan hệ nhân quả giữa biến phụ thuộc và biến độc lập nhưng nó đóng vai trò làm cơ sở cho phân tích hồi quy. Các biến biến phụ thuộc và biến độc lập có tương quan cao với nhau báo hiệu sự tồn tại của mối quan hệ tiềm ẩn giữa hai biến. Đồng thời, việc phân tích tương quan còn làm cơ sở để dò tìm sự vi phạm giả định của phân tích hồi quy tuyến tính: các biến độc lập có tương quan cao với nhau hay hiện tượng đa cộng tuyến.
Bảng 4.14: Kiểm định hệ số tương quan
HL | DV | ATTP | PV .471** | NV | CS | ||
HL | Pearson Correlation | 1 | .572** | .424** | .479** | .594** | |
Sig. (2-tailed) | .000 | .000 | .000 | .000 | .000 | ||
N | 312 | 312 | 312 | 312 | 312 | ||
DV | Pearson Correlation | 1 | .235** .000 | .328** | .258** .000 | .457** | |
Sig. (2-tailed) | .000 | .000 | |||||
N | 312 | 312 | 312 | 312 | |||
ATTP | Pearson Correlation | 1 | .157** | .376** | .140** | ||
Có thể bạn quan tâm!
-

 Nguồn Nhân Lực Của Khách Sạn Park Hyatt Sài Gòn Từ Năm 2011- 2016
Nguồn Nhân Lực Của Khách Sạn Park Hyatt Sài Gòn Từ Năm 2011- 2016 -
 Các Yếu Tố Khác Tác Động Đến Chất Lượng Dịch Vụ Của Khách Sạn
Các Yếu Tố Khác Tác Động Đến Chất Lượng Dịch Vụ Của Khách Sạn -
 Phân Tích Nhân Tố Nhóm Biến Độc Lập
Phân Tích Nhân Tố Nhóm Biến Độc Lập -
 Đề Xuất Một Số Giải Pháp Nâng Cao Chất Lượng Dịch Vụ Tại Khách Sạn Park Hyatt Saigon
Đề Xuất Một Số Giải Pháp Nâng Cao Chất Lượng Dịch Vụ Tại Khách Sạn Park Hyatt Saigon -
 Các Giải Pháp Liên Quan Đến Hoạt Động Quản Lý Chất Lượng Dịch Vụ
Các Giải Pháp Liên Quan Đến Hoạt Động Quản Lý Chất Lượng Dịch Vụ -
 Promise That All Of Your Information Just For Survey Purpose Of The Thesis, Never For Others Commercial Purpose. All The Information Will Be Keep Secret And Just Provide For My Professor When She
Promise That All Of Your Information Just For Survey Purpose Of The Thesis, Never For Others Commercial Purpose. All The Information Will Be Keep Secret And Just Provide For My Professor When She
Xem toàn bộ 136 trang tài liệu này.
Sig. (2-tailed) | .005 | .000 | .002 | ||||
N | 312 | 312 | 312 | ||||
PV | Pearson Correlation | 1 | .434** | .282** | |||
Sig. (2-tailed) | .000 | .000 | |||||
N | 312 | 312 | |||||
NV | Pearson Correlation | 1 | .256** | ||||
Sig. (2-tailed) | .000 | ||||||
N | 312 | ||||||
CS | Pearson Correlation | 1 | |||||
Sig. (2-tailed) | |||||||
N |
(Nguồn: Kết quả phân tích SPSS, 2017)
Ta thấy rằng các hệ số tương quan giữa biến độc lập và biến phụ thuộc đều có ý nghĩa (sig<0.05), do vậy các biến độc lập đưa vào phân tích hồi quy là phù hợp. Như vậy, giữa các thang đo đo lường mức độ thỏa mãn sự hài lòng trong mô hình nghiên cứu không có mối tương quan tuyến tính với nhau. Vì thế, sẽ không xuất hiện đa cộng tuyến trong phân tích hồi quy.
Bên cạnh đó, kết quả phân tích cũng cho thấy mức tương quan tuyến tính giữa từng thang đó trên với thang đo Sự hài lòng của khách hàng, trong đó mối quan hệ tương quan cao nhất là giữa thang đo Cơ sở vật chất và Dịch vụ.
* Phân tích hồi quy
Phân tích hồi quy tuyến tính sẽ giúp chúng ta biết được cường độ ảnh hưởng của các biến độc lập lên biến phụ thuộc. Để tiến hành phân tích hồi quy tuyến tính bội, các biến đưa vào mô hình theo phương pháp Enter. Tiêu chuẩn kiểm định là tiêu chuẩn được xây dựng vào phương pháp kiểm định giá trị thống kê F và xác định xác suất tương ứng của giá trị thống kê F, kiểm định mức độ phù hợp giữa mẫu và tổng thể thông qua hệ số xác định R2. Công cụ chẩn đoán giúp phát hiện sự tồn tại của cộng tuyến trong dữ liệu được đánh giá mức độ cộng tuyến làm thoái hóa tham số ước lượng là: Hệ số phóng đại phương sai (Variance inflation factor - VIF). Quy tắc khi VIF vượt quá 10, đó là dấu hiệu của đa cộng tuyến (Hoàng Trọng và
Chu Nguyễn Mộng Ngọc, 2005).
Dựa vào cơ sở lý thuyết và kết quả phân tích ở trên, ta sẽ đưa tất cả các biến độc lập trong mô hình hồi quy đã điều chỉnh bằng phương pháp đưa vào cùng một lúc Enter để chọn lọc dựa trên tiêu chí chọn những biến có mức ý nghĩa < 0.05.
Kết quả phân tích hồi quy tuyến tính cho các biến số được thể hiện thông qua các bảng sau:
Bảng 4.15: Hệ số R-Square từ kết quả phân tích hồi quy Model Summaryb
R | R Square | Adjusted R Square | Std. Error of the Estimate | Durbin- Watson | |
1 | .784a | .614 | .608 | .28531 | 1.670 |
(Nguồn: Kết quả phân tích SPSS, 2017)
a. Predictors: (Constant), CS, ATTP, PV, DV, NV
b. Dependent Variable: HL
So sánh hai giá trị R Square và Adjusted R Square có thể thấy Adjusted R Square nhỏ hơn, dùng nó để đánh giá độ phù hợp của mô hình sẽ an toàn hơn vì nó không thổi phồng mức độ phù hợp của mô hình. Vậy, nghiên cứu sẽ sử dụng R2 hiệu chỉnh để đánh giá mức độ phù hợp của mô hình nghiên cứu. Độ phù hợp của mô hình được kiểm định bằng trị thống kê F được tính từ R2 của mô hình tương ứng với mức ý nghĩa sig., với giá trị sig. càng nhỏ (trừ hằng số). Mô hình hồi quy tuyến tính bội đưa ra là phù hợp với dữ liệu và có thể sử dụng được.
Kết quả từ kiểm định hệ số tương quan cho thấy tất cả các biến độc lập đều có tác động có ý nghĩa lên biến phụ thuộc (sig<0.05) các nhân tố đưa vào phân tích hồi quy đều được giữ lại trong mô hình.
Hệ số xác định hiệu chỉnh Adjusted R-Square là 0.608, nghĩa là mô hình hồi quy tuyến tính đã xây dựng phù hợp với tập dữ liệu đến 60.8%, điều này cho thấy mối quan hệ giữa biến phụ thuộc và các biến độc lập là khá chặt chẽ, cả 5 biến trên góp phần giải thích 60.8% sự khác biệt của Sự hài lòng của khách hàng. Như vậy, mức độ phù hợp của mô hình tương đối cao. Tuy nhiên sự phù hợp này chỉ đúng với
dữ liệu mẫu. Để kiểm định xem có thể suy diễn mô hình cho tổng thể thực hay không ta phải kiểm định độ phù hợp của mô hình.
Đồng thời, để kiểm tra hiện tượng tự tương quan thông qua kiểm định Durbin-Watson:
Nếu 1< D < 3: mô hình không xảy ra hiện tượng tự tương quan. Nếu 0< D < 1: mô hình tư tương quan dương.
Nếu 3< D <4: mô hình tự tương quan âm.
Ta có D=1.670: mô hình không xảy ra hiện tượng tự tương quan
Kiểm định F sử dụng trong bảng phân tích phương sai vẫn là một phép giả thuyết về độ phù hợp của mô hình hồi quy tuyến tính tổng thể. Kết quả phân tích cho thấy, kiểm định F có giá trị là 101.398 với Sig. = 000(a) chứng tỏ mô hình hồi quy tuyến tính bội là phù hợp với tập dữ liệu và có thể sử dụng được để suy rộng ra cho tổng thể.
Bảng 4.16. Kết quả ANOVA từ kết quả phân tích hồi quy
ANOVAa
Sum of Squares | Df | Mean Square | F | Sig. | ||
Regression | 40.275 | 5 | 8.055 | 101.398 | .000b | |
1 | Residual | 24.308 | 306 | .079 | ||
Total | 64.583 | 311 |
(Nguồn: Kết quả phân tích SPSS, 2017)
a. Dependent Variable: HL
b. Predictors: (Constant), CS, ATTP, PV, DV, NV
Kết quả thống kê theo bảng 4.16 cho thấy, các hệ số hồi quy chuẩn hóa của phương trình hồi quy đều khác 0 và Sig <0.05, chứng tỏ thành phần đều tham dự vào Sự hài lòng khách hàng của khách. So sánh giá trị (độ lớn) của hệ số chưa chuẩn hóa cho thấy: tác động theo thứ tự từ mạnh đến yếu của các thành phần: Cơ sở vật chất, Dịch vụ, An toàn thực phẩm, Nhân viên, Qui trình phục vụ.
Hệ số phóng đại phương sai VIF (Variance inflation factor – VIF) rất nhỏ và dao động từ 1.196 tới 1.420 (nhỏ hơn 10) cho thấy các biến độc lập này không có quan hệ chặt chẽ với nhau nên không có hiện tượng đa cộng tuyến.
Bảng 4.17: Kết quả phân tích hồi quy tuyến tính
Coefficientsa
Unstandardized Coefficients | Standardized Coefficients | t | Sig. | Collinearity Statistics | |||
B | Std. Error | Beta | Tolerance | VIF | |||
(Constant) | -.424 | .206 | - 2.061 | .040 | |||
DV | .264 | .043 | .257 | 6.167 | .000 | .726 | 1.378 |
1 ATTP | .206 | .035 | .226 | 5.829 | .000 | .837 | 1.195 |
PV | .164 | .037 | .183 | 4.456 | .000 | .751 | 1.331 |
NV | .159 | .043 | .158 | 3.728 | .000 | .702 | 1.424 |
CS | .317 | .036 | .353 | 8.677 | .000 | .762 | 1.313 |
(Nguồn: Kết quả phân tích SPSS, 2017)
a. Dependent Variable: HL
HL= -0.424 + 0.257*DV + 0.226*ATTP + 0.183*PV + 0.158*NV + 0.353*CS
* Dò tìm sự vi phạm các giả định cần thiết trong hồi quy tuyến tính
Tiếp đến, luận văn trình bày các kiểm định về độ phù hợp và kiểm định ý nghĩa của các hệ số hồi quy.
Mô hình hồi quy tuyến tính bằng phương pháp Enter được Sự tiện lợi với một số giả định và mô hình chỉ thực sự có ý nghĩa khi các giả định này được đảm bảo. Do vậy, để đảm bảo cho Độ tin cậy của mô hình, đề tài còn phải Sự tiện lợi một loạt các dò tìm sự vi phạm các giả định cần thiết trong hồi quy tuyến tính.
* Giả định liên hệ tuyến tính và phương sai không đổi: nếu giả định liên hệ tuyến tính và phương sai bằng nhau được thỏa mãn thì không nhận thấy có liên hệ gì giữa các giá trị dự đoán và phần dư, chúng sẽ phân tán rất ngẫu nhiên. Nếu giả định tuyến tính được thỏa mãn (đúng) thì phần dư phải phân tán ngẫu nhiên trong một vùng xung quanh đường đi qua tung độ 0 của đồ thị phân tán của phần dư chuẩn hóa (Standardized Residual) và giá trị dự đoán chuẩn hóa (Standardized Predicted Value). Và nếu phương sai không đổi thì các phần dư phải phân tán ngẫu nhiên quanh trục 0 (tức quanh giá trị trung bình của phần dư) trong một phạm vi không đổi (Hoàng Trọng và Chu Nguyễn Mộng Ngọc, 2008).
Đầu tiên là giả định liên hệ tuyến tính. Phương pháp được sử dụng là biểu đồ Scatterplot với giá trị phần dư chuẩn hóa trên trục tung và giá trị dự đoán chuẩn hóa
trên trục hoành. Nhìn vào biểu đồ ta thấy phần dư không thay đổi theo một trật tự nào đối với giá trị dự đoán. Vậy giả thuyết về liên hệ tuyến tính không bị vi phạm.
Giả định tiếp theo cần xem xét là phương sai của phần dư không đổi. Để Sự tiện lợi kiểm định này, chúng ta sẽ tính hệ số tương quan hạng Spearman của giá trị tuyệt đối phần dư và các biến độc lập. Giá trị sig. của các hệ số tương quan với Độ tin cậy 95% cho thấy không đủ cơ sở để bác bỏ giả thuyết H0 là giá trị tuyệt đối của phần dư độc lập với các biến độc lập. Như vậy, giả định về phương sai của sai số không đổi không bị vi phạm.
Để dò tìm sự vi phạm giả định phân phối chuẩn của phần dư ta sẽ dùng hai công cụ vẽ của phần mềm SPSS là biểu đồ Histogram và đồ thị P-P plot. Nhìn vào biểu đồ Histogram ta thấy phần dư có phân phối chuẩn với giá trị trung bình gần bằng 0 và độ lệch chuẩn của nó gần bằng 1 (= 0.992).
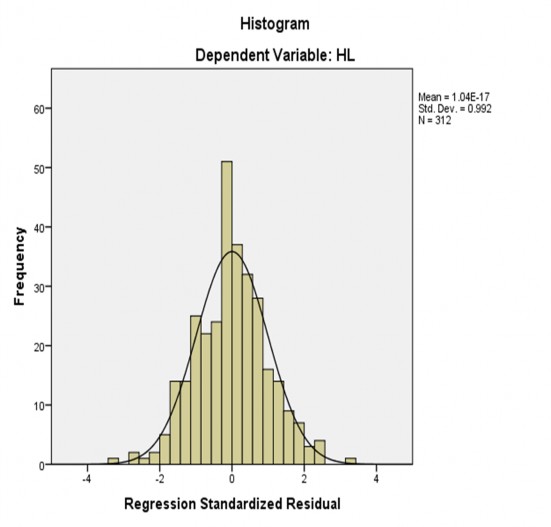
Biểu đồ 4.4: Biểu đồ Histogram
(Nguồn: Kết quả phân tích SPSS, 2017)
Nhìn vào đồ thị P-P plot (biểu đồ 4.2) biểu diễn hầu hết các điểm quan sát thực tế tập trung gần như quanh đường chéo những giá trị kỳ vọng, có nghĩa là dữ liệu phần dư có phân phối chuẩn. Dựa vào đồ thị phân tán của phần dư chuẩn hóa và giá trị dự đoán chuẩn hóa cho thấy các giá trị dự đoán chuẩn hóa và hầu hết phần dư phân tán chuẩn hóa phân tán ngẫu nhiên trong một vùng xung quanh đường đi qua tung độ 0.

Biểu đồ 4.5: Biểu đồ P-P lot
(Nguồn: Kết quả phân tích SPSS, 2017)
Theo biểu đồ Scatterplort (biểu đồ 4.3), các giá trị kỳ vọng được phân tán ngẫu nhiên thành một vùng nhất định. Vì vậy mà các giả thuyết tuyến tính không bị vi phạm hay nói cách khác đảm bảo được Độ tin cậy của mô hình
Biểu đồ 4.6: Biểu đồ Scatterplot
(Nguồn: Kết quả phân tích SPSS, 2017)
* Kết quả kiểm định giả thuyết thống kê
Bảng 4.18: Tóm tắt kết quả phân tích hồi quy tuyến tính
Nhân tố | Sig | B | Kết quả | |
H1 | Dịch vụ | 0.000 | .264 | Chấp nhận |
H2 | An toàn thực phẩm | 0.000 | .206 | Chấp nhận |
H3 | Qui trình phục vụ | 0.000 | .164 | Chấp nhận |
H4 | Nhân viên | 0.000 | .159 | Chấp nhận |