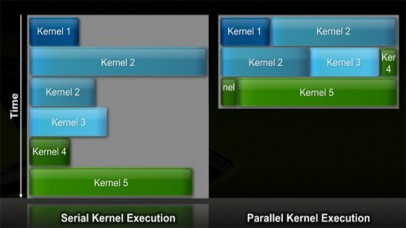

Figure 7 Nvidia GF100 (Fermi) processor with parallel kernel execution
Singleprecision performance of GF100 is about 1.7 Tflops but doubleprecision performance is only half at 800 Gflops, significantly better than the Radeon 5870. Previous architectures required that all SMs in the chip worked on the same kernel (function/program/loop) at the same time. In this generation the GigaThread scheduler can execute threads from multiple kernels in parallel. This chip is specifically designed to provide better support for GPGPU with memory error correction, native support for
C++ (including virtual functions, function pointers, dynamic memory management using new and delete and exception handling), and compatible with CUDA, OpenCL and DirectCompute. A true cache hierarchy with two levels is added with more shared memory than previous GPU generations. Context switching and atomic operations are also faster. Fortran compilers are also available from PGI. Specific versions for scientific computing will have from 3GB to 6GB GDDR5.
1.1.4 Future trends in hardware
Although the current parallel architectures are very powerful, especially for parallel workload, they won’t stay the same way in the future. From the current situation, we can present some trends for future hardware in the next few years.
The first is the change in the composition of clusters. A cluster node can now have several multicore processors and some graphics processors. Consequently, clusters with fewer nodes can still have the same processing power. This also enables the maximum limit of cluster processing capabilities to increase. Traditional clusters consisting of only CPU nodes have virtually reached their peak at about 1 Pflops. Adding more nodes would result in more system overhead with marginal increase in speed. Electricity consumption is also enormous for such systems. Supercomputing now accounts for 2 percents of the total electric consumption of the entire United States. Building supercomputer at the exascale (1000 Pflops) using traditional clusters is too much costly. Graphics processors or similar architectures provide a good Gflops/W ratio and are, therefore, vital to building supercomputers with larger processing power. The IBM Roadrunner supercomputer [21] using Cell processors is a clear example for this trend.
The second trend is the convergence of stream processors and CPUs.
Graphics cards currently act the role of coprocessors to the CPU in floating point intensive tasks. In the long term, all the functionalities of the graphics card may reside on the CPU, just like what happened in the case of math coprocessors which are now CPU floating point units. The Cell processor by Sony, Toshiba and IBM is heading towards that direction. AMD has also been continuously pursuing this with its Fusion project. The Nvidia GF100 is a GPU with many CPU features such as memory correction and large caches. The Intel’s Larrabee experiment project event went further by aiming to produce an x86compatible GPU that would later be integrated
14
Có thể bạn quan tâm!
-

 A parallel implementation on modern hardware for geo electrical tomographical software - 1
A parallel implementation on modern hardware for geo electrical tomographical software - 1 -
 A parallel implementation on modern hardware for geo electrical tomographical software - 2
A parallel implementation on modern hardware for geo electrical tomographical software - 2 -
 A parallel implementation on modern hardware for geo electrical tomographical software - 4
A parallel implementation on modern hardware for geo electrical tomographical software - 4 -
 A parallel implementation on modern hardware for geo electrical tomographical software - 5
A parallel implementation on modern hardware for geo electrical tomographical software - 5 -
 A parallel implementation on modern hardware for geo electrical tomographical software - 6
A parallel implementation on modern hardware for geo electrical tomographical software - 6
Xem toàn bộ 65 trang tài liệu này.
into Intel CPUs. These would all lead to a new kind of processor called Accelerated Processing Unit (APU).
The third trend is the evolution of multicore CPUs into manycore processors in which individual cores form a cluster system. In December 2009, Intel unveiled the newest product of its Terascale Computing Research program, a 48core x86 processor.


Figure 8 The Intel 48core processor. To the right is a dualcore tile. The processor has 24 such tiles in a 6 by 4 layout.
It represents the sequel to Intel's 2007 Polaris 80core prototype that was based on simple floating point units. This device is called a "Singlechip Cloud Computer" (SCC). The structure of the chip resembles that of a cluster with cores connected through a messagepassing network with 256 GB/s bandwidth. Sharedmemory is simulated on software. Cache coherence and power management is also software based. Each core can run its own OS and software, which resembles a cloud computing center. Each tile (2 cores) can have its own frequency, and groupings of four tiles (8 cores) can each run at their own voltage. The SCC can run all 48 cores at one time over a range of 25W to 125W and selectively vary the voltage and frequency of the mesh network as well as sets of cores. This 48 core device consists of 1.3 billion transistors produced using 45nm highk metal gate. Intel are currently handing out these processors to its partners in both industry and academy to enhance further research in parallel computing.
15
Tilera corporation is also producing processors with one hundred cores. Each core can run a Linux OS independently. The processor also has Dynamic Distributed Cache technology which provides a fully coherent shared cache system across an arbitrary sized array of tiles. Programming can be done normally on a Linux derivative with full support for C and C++ and Tilera parallel libraries. The processor utilizes VLIW (Very Long Instruction Word) with RISC instructions for each core. The primary focus of this processor is for networking, multimedia and clouding computing with a strong emphasis on integer computation to complement GPU’s floating point computation.
From all these trends, it would be reasonable to assume that in the near future, we will be able to see new architectures which resemble all current architectures, such as manycore processors where each core has a CPU core and streamprocessors as co processors. Such systems would provide tremendous computing power per processor that would cause major changes in the field of computing.
1.2 Programming tools for scientific computing on personal desktop systems
Traditionally, most scientific computing tasks have been done on clusters. However, with the advent of modern hardware that provide great level of parallelism, many small to mediumsized tasks can now be run on a single highend desktop computer in reasonable time. Such systems are called “personal supercomputers”. Although they have variable configurations, most today employ multicore CPUs with multiple GPUs. An example is the Fastra II desktop supercomputer [3] at University of Antwep, Belgium, which can achieve 12 Tflops computing power. The FASTRA II contains six NVIDIA GTX295 dualGPU cards, and one GTX275 singleGPU card with a total cost of less than six thousands euros. The real processing speed of this system can equal that of a cluster with thousands of CPU cores.
Although these systems are more costeffective, consume less power and provide greater convenience for their users, they pose serious problems for software developers.
Traditional programming tools and algorithms for cluster computing are not appropriate for exploiting the full potential of multicore CPUs and GPUs. There are many kinds of interaction between components in such heterogeneous systems. The
link between the CPU and the GPUs is through the PCI Express bus. The GPU has to go through the CPU to access system memory. The inside of the multicore CPU is a SMP system. As each GPU has separate graphics memory, the relationship between GPUs is like in a distributedmemory system. As these systems are in early stages of development, programming tools do not provide all the functionalities programmers need and many tasks still need to be done manually. Algorithms also need to be adapted to the limitations of current hardware and software tools.
In the following parts, we will present some programming tools for desktop systems with multicore CPUs and multi GPUs that we that we consider useful for exploiting parallelism in scientific computing. The grouping is just for easy comparison between similar tools as some tools provide more than one kind of parallelization.
1.2.1 CPU Threadbased Tools: OpenMP, Intel Threading Building Blocks, and Cilk++
Windows and Linux (and other Unixes) provide API’s for creating and manipulating operating system threads using WinAPI threads and POSIX threads (Pthreads), respectively. These threading approaches may be convenient when there's a natural way to functionally decompose an application for example, into a user interface thread, a compute thread or a render thread.
However, in the case of more complicated parallel algorithms, the manual creating and scheduling thread can lead to more complex code, longer development time and not optimal execution.
The alternative is to program atop a concurrency platform — an abstraction layer of software that coordinates, schedules, and manages the multicore resources.
Using thread pools is a parallel pattern that can provide some improvements. A thread pool is a strategy for minimizing the overhead associated with creating and destroying threads and is possibly the simplest concurrency platform. The basic idea of a thread pool is to create a set of threads once and for all at the beginning of the program. When a task is created, it executes on a thread in the pool, and returns the thread to the pool when finished. A problem is when the task arrives and the pool has no thread available. The pool then suspends the task and wakes it up when a new
thread is available. This requires synchronization such as locks to ensure atomicity and avoid concurrency bugs. Thread pools are common for the serverclient model but for other tasks, scalability and deadlocks still pose problems.
This calls for concurrency platforms with higher levels of abstraction that provide more scalability, productivity and maintainability. Some examples are OpenMP, Intel Threading Building Blocks, and Cilk++.

OpenMP (Open Multiprocessing) [25] is an open concurrency platform with support for multithreading through compiler pragmas in C, C++ and Fortran. It is an API specification and compilers can provide different implementations. OpenMP is governed by the OpenMP Architecture Review Board (ARB). The first OpenMP specification came out in 1997 with support for Fortran, followed by C/C++ support in 1998. Version 2.0 was released in 2000 for Fortran and 2002 for C/C++. Version 3.0 was released in 2008 and is the current API specification. It contains many major enhancements, especially the task construct. Most recent compilers have added some level of support for OpenMP. Programmers can inspect the code to find places that require parallelization and insert the pragmas to tell the compiler to produce multithreaded code. This makes the code have a forkjoin model, in which when the parallel section has finished; all the threads join back the master thread. Workloads in one loop are given to threads using worksharing. There are four kinds of loop workload scheduling in OpenMP:
Static scheduling, each thread is given an equal chunk of iterations.
Dynamic scheduling, the iterations are assigned to threads as the threads request them. The thread executes the chunk of iterations (controlled through the chunk size parameter), then requests another chunk until there are no more chunks to work on.
Guided scheduling is almost the same as dynamic scheduling, except that for a chunk size of 1, the size of each chunk is proportional to the number
of unassigned iterations, divided by the number of threads, decreasing to
1. For a chunk size of “k” (k >1), the size of each chunk is determined in the same way, with the restriction that the chunks do not contain fewer than k iterations.
Runtime scheduling, if this schedule is selected, the decision regarding scheduling kind is made at run time. The schedule and (optional) chunk size are set through the OMP_SCHEDULE environment variable.
Beside scheduling clauses, OpenMP also has clauses for data sharing attribute, synchronization, IF control, initialization, data copying, reduction and other concurrent operations.
A typical OpenMP parallelized loop may look like:
#pragma omp for schedule(dynamic, CHUNKSIZE) for(int i = 2; i <= N-1; i++)
for(int j = 2; j <= i; j++) for(int k = 1; k <= M; k++)
b[i][j]+=a[i-1][j]/k+a[i+1][j]/k;
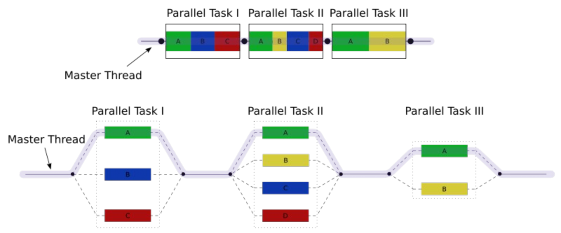
Figure 9 OpenMP forkjoin model.
Intel’s Threading Building Blocks (TBB) [4] is an open source C++ template library developed by Intel for writing task based multithreaded applications with ideas and models inherited from many previous languages and libraries. While OpenMP uses the pragma approach for parallelization, TBB uses the library approach. The first version came out in August 2006 and since then TBB has seen widespread use in
many applications, especially game engines such as Unreal. TBB is available with both a commercial license and an open source license. The latest version 2.2 was introduced in August 2009. The library has also received Jolt Productivity award and InfoWorld OSS award.
It is a library based on generic programming, requires no special compiler support, and is processor and OS independent. This makes TBB ideal for parallelizing legacy applications. TBB has support for Windows, Linux, OS X, Solaris, PowerPC, Xbox, QNX, FreeBSD and can be compiled using Visual C++, Intel C++, gcc and other popular compilers.
TBB is not a threadreplacement library but provides a higher level of abstraction. Developers do not work directly with threads but tasks, which are mapped to threads by the library runtime. The number of threads are automatically managed by the library or set manually by the user, just like the case with OpenMP. Beside basic loop parallelizing parallel_for constructs, TBB also have parallel patterns such as parallel_reduce, parallel_scan, parallel_do; concurrent data containers including vectors, queues and hash map; scalable memory allocator and synchronization primitives such as atomics and mutexes; and pipelining. TBB parallel algorithms operate on the concept of blocked_range, which is the iteration space. Work is divided between threads using work stealing, in which the range is recursively divided into