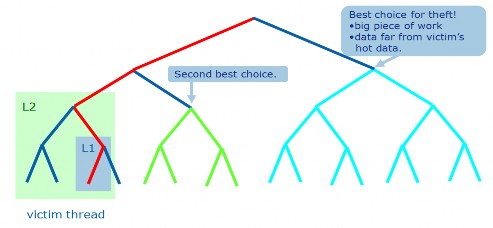
smaller tasks. A thread work on the task it meets depth first and steals the task breadth first following the principles:
do task from own queue (FIFO) steal task from another queue.
This can be applied to one, two or threedimensional ranges, allowing for
effective blocking on data structures with dimensions greater than one. Task stealing also enables better cache utilization and avoid false sharing as much as possible. The figures below illustrate the mechanism behind task stealing.
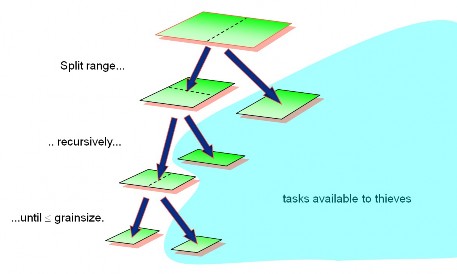
Figure 10 TBB’s range split
Có thể bạn quan tâm!
-

 A parallel implementation on modern hardware for geo electrical tomographical software - 1
A parallel implementation on modern hardware for geo electrical tomographical software - 1 -
 A parallel implementation on modern hardware for geo electrical tomographical software - 2
A parallel implementation on modern hardware for geo electrical tomographical software - 2 -
 Programming Tools For Scientific Computing On Personal Desktop Systems
Programming Tools For Scientific Computing On Personal Desktop Systems -
 A parallel implementation on modern hardware for geo electrical tomographical software - 5
A parallel implementation on modern hardware for geo electrical tomographical software - 5 -
 A parallel implementation on modern hardware for geo electrical tomographical software - 6
A parallel implementation on modern hardware for geo electrical tomographical software - 6 -
 A parallel implementation on modern hardware for geo electrical tomographical software - 7
A parallel implementation on modern hardware for geo electrical tomographical software - 7
Xem toàn bộ 65 trang tài liệu này.
Figure 11 TBB’s task stealing illustration
Normally, TBB calls using function objects can be quite verbose as parallelization is done through libraries. However, with the new C++0x lambda syntax, TBB code can be much shorter and easier to read.
Below is an example TBB call using C++0x lambdas:
void ParallelApplyFoo(float a[], size_t n ){ parallel_for( blocked_range<size_t>( 0, n ),
[=](const blocked_range<size_t>& range) { for(int i= range.begin();i!=range.end();++i)
Foo(a[i]);
},
auto_partitioner() );}
}
Another platform for multithreading development is Cilk++. Cilk++ extends
the C++ programming language with three new keywords: cilk_spawn, cilk_sync, cilk_for; and Cilk++ hyper objects which can be global variables but avoid data races. Parallelized code using Cilk++ can therefore be quite compact.
void matrix_multiply(matrix_t A,matrix_t B,matrix_t C)
{
cilk_for (int i = 0; i < A.rows; ++i) { cilk_for (int j = 0; j < B.cols; ++j) {
for (int k = 0; k < A.cols; ++k) C[i][j] += A[i][k] * B[k][j];
}
}
}
Matrix multiplication implementation in Cilk++
However, this requires the Cilk++ compiler which extends on a standard C++ compiler such as Visual C++ or GCC. Cilk++ also uses work stealing like TBB for scheduling threads but with its own modification. Both are based on the work stealing method by the MIT Cilk project. Intel has recently acquired the Cilk++ company and
Cilk++ will be integrated into Intel’s line of parallel programming tools together with TBB and other tools.
1.2.2 GPU programming with CUDA
The first GPU platform we present is CUDA [16]. CUDA is Nvidia’s parallel computing architecture that allows programmer to program GPGPU applications on Nvidia’s graphics card architecture including Geforce, Quadro and Tesla. CUDA was introduced in the late 2006 and received a lot of attention when released, especially from high performance computing communities. It is now the basis for all other kinds of parallel programming tools on the Nvidia hardware. CUDA is now the most popular tool for programming GPGPU applications with various research papers, libraries and commercial development tools. Previous to CUDA, GPGPU was done using graphics API. Although speedup for this was great, there were several drawbacks that limits the growth of GPGPU. Firstly, the programmer is required to possess indepth knowledge of graphics APIs and GPU architecture. Secondly, problems had to be expressed in terms of vertex coordinates, textures and shader programs, which results in greatly increased program complexity, low productivity and poor code maintenance. Thirdly, basic programming features such as random reads and writes to memory were not supported, greatly restricting the programming model and algorithms available. CUDA has to some extent made GPU programming more accessible to programmers with a more intuitive programming model and a good collections of libraries for popular tasks.
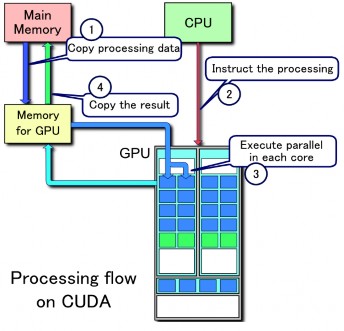
Figure 12 CUDA processing flow [16]
As CUDA is used for an architecture which supports massively data parallel programming, programming using CUDA is also different from traditional programming on the CPU. The processing flow for CUDA applications is shown in Figure 12.
As the GPU does not have direct access to main memory, processing data must be copied from the main memory to GPU memory through the PCI Express lanes. The GPU is also not a totally selfcontrol processor and needs the CPU to instruct the processing. The GPU then executes the data processing in parallel on its core using its hardware scheduler. When the processing is done, processed data is copied back the main memory. All the memory copy operations are much more expensive than computation operations so it is best to keep the processing on the GPU for as long as possible to avoid expensive memory copies.
C for CUDA extends C by allowing the programmer to define C functions, called kernels, that, when called, are executed N times in parallel by N different CUDA threads. A kernel is defined using theglobaldeclaration specifier and the number of CUDA threads for each call is specified using a new <<<…>>>syntax. The first parameter for the <<<…>>>call is the number of blocks and the second one is the block size. For example:
// Kernel definition
global void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x; C[i] = A[i] + B[i];
}
int main()
{
// Kernel invocation VecAdd<<<1, N>>>(A, B, C);
}
All files containing CUDA syntax must be compiled with the Nvidia nvcc compiler. It can be used together with both Visual C++, GCC and other compilers.
All the CUDA threads run the same kernel when invoked. Threads are grouped into blocks of the same size and blocks together form a grid. Both grid and block can be one, two or threedimensional. Through the CUDA extensions blockIdx, blockDim and threadIdx, the kernel implementer can get the coordinate of the thread in the grid and process the corresponding data element. Thread blocks are required to execute independently which means it must be possible to execute them in any order, in parallel or in series. This independence requirement allows thread blocks to be scheduled in any order across any number of cores, enabling programmers to write code that is scalable with the increasing number of cores. The number of blocks in a grid is typically governed by the size of the data being processed rather than by the number of stream processors in the system, which it can greatly exceed.
CUDA’s hierarchy of threads is mapped to the hierarchy of processors on the GPU. A GPU executes one or more kernel grids. A streaming multiprocessor (SM) executes one or more thread blocks, and CUDA cores and other execution units in the SM execute threads. The SM executes threads in groups of 32 threads called a warp. While programmers can generally ignore warp execution for functional correctness and think of programming one thread, greatly improved performance can be achieved
by having threads in a warp execute the same code path and access memory in nearby addresses.
Figure 13 shows an example of thread grids with each block in the grids containing executable threads.
For a problem of certain size, the number of threads per block and the number of blocks and the grid and block dimension can be manually controlled by the programmer at kernel launch. Choosing these numbers appropriately can have great effects on execution speed. As threads are scheduled in warps of 32 threads each, the number of threads per block should be a multiple of 32. Each generation of processor also has maximum limitations on number of threads, number of threads per stream processor and number of blocks per stream processor. Careful considerations of these parameters can enable the kernel to utilize the full potential of the GPU. For example the G80 architecture can schedule up to 8 blocks and 768 threads per stream processor. If there are 64 threads per block, there are 12 blocks but only 8 blocks can go into the stream processor so only 512 threads is scheduled. With 256 threads per block, each stream processor can execute three blocks and achieve full capacity. For 1024 threads per block, even one block can not fit into a stream processor and cannot be scheduled. Choosing the right parameter for kernel launch is a difficult problem which has different solutions for each situation and optimal execution can only be obtained with some amount of experiments.
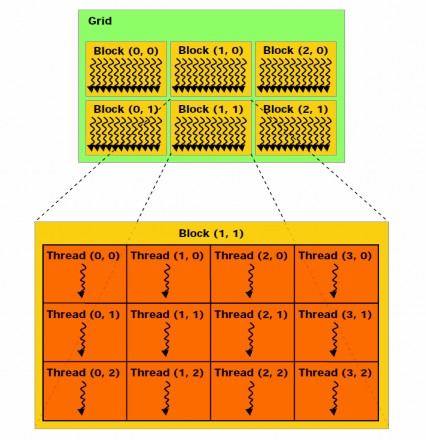
Figure 13 Grid of thread blocks [8]
The CUDA memory hierarchy is also different from that of traditional C programming with much more complexities. Each thread has a private local memory called registers. Registers are the fastest form of memory in the GPU but only accessible by the thread and has the life time of the thread. Each thread block has a shared memory visible to all threads of the block and with the same lifetime as the block. Shared memory can be as fast as registers when there are no bank conflicts or when reading from the same address. Finally, all threads have access to the same global memory. Global memory is much slower than shared memory and registers, requiring 400 to 600 clock cycles for one access. As a result, programmers should strive to utilize registers and shared memory to increase bandwidth. When reading from global memory, coalesced memory access also help avoid performance penalties of global memory access.
There are also two additional readonly memory spaces accessible by all threads: the constant and texture memory spaces. The global, constant, and texture memory spaces are optimized for different memory usages. Constant memory is read only from
kernels and is optimized for the case when threads read from the same memory location. Texture memory can offer the ability to cache global memory and interact with the dedicated graphics hardware of the GPU. In appropriate cases, using texture memory can provide considerable performance gain over global memory access. However, this depends on particular situations and using constant memory and texture memory effectively is still an expert topic in CUDA as careless uses of these advanced features can lead to even slower performance, erroneous execution or reduced code clarity.
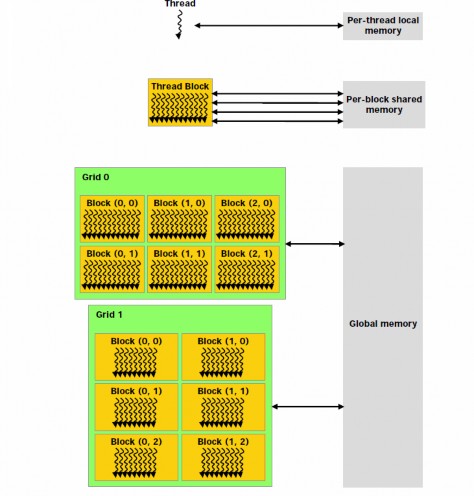
Figure 14 The CUDA Memory Hierarchy [8]
The CUDA programming model also assumes that the host (CPU) and the device (GPU) maintain separate memory as host memory and device memory. A CUDA application has to manually manage all the memory related to the device including memory allocation and deallocation using cudaMalloc and cudaFree; and data transfer between host and device using cudaMemcpy. Since CUDA 2.2, there is also
28