mềm Weka và lưu dưới dạng file excel ta có tập dữ liệu gồm 600 đối tượng, 10 thuộc tính điều kiện và thuộc tính quyết định “result” quyết định mỗi khách hàng là được vay và không được vay.
Các thuộc tính và giá trị của các thuộc tính của tập dữ liệu Bank_data được mô tả trong bảng sau:
Tên thuộc tính | Giá trị | Giải thích | |
1 | Tuoi | Tre, Trung nien, Gia | Trẻ, trung niên, già |
2 | Gioi_tinh | Nam, Nu | Nam, Nữ |
3 | Khu_vuc | NT, TTran, Ngoai o, TP | Nông thôn, Thị trấn, ngoại ô, thành phố |
4 | Thu_nhap | Thap, TB, Cao | Thấp, trung bình, cao |
5 | Ket_hon | C, K | Có, không |
6 | Con | 0_Con, 1_con, 2_con, 3_con | Không con, một con, hai con, ba con |
7 | Xe | C, K | Có, không |
8 | TKTK (tài khoản tiết kiệm) | C, K | Có, không |
9 | TK_Htai (tài khoản hiện tại) | C, K | Có, không |
10 | The_chap | C, K | Có, không |
11 | RESULT (Cho vay) | True, false | Có (True), không (False) |
Có thể bạn quan tâm!
-

 Ứng Dụng Cây Quyết Định Trong Khai Phá Dữ Liệu
Ứng Dụng Cây Quyết Định Trong Khai Phá Dữ Liệu -
 Thuật Toán Xây Dựng Cây Quyết Định Dựa Vào Độ Phụ Thuộc Của Thuộc Tính
Thuật Toán Xây Dựng Cây Quyết Định Dựa Vào Độ Phụ Thuộc Của Thuộc Tính -
 Thuật Toán Xây Dựng Cây Quyết Định Dựa Vào Entropy Và Độ Phụ Thuộc Của Thuộc Tính
Thuật Toán Xây Dựng Cây Quyết Định Dựa Vào Entropy Và Độ Phụ Thuộc Của Thuộc Tính -
 Phân tách cụm danh từ cơ sở tiếng việt sử dụng mô hình crfs - 8
Phân tách cụm danh từ cơ sở tiếng việt sử dụng mô hình crfs - 8
Xem toàn bộ 68 trang tài liệu này.
Bảng 4. Bảng các thuộc tính của tập dữ liệu Bank_data
3.3. Cài đặt ứng dụng
Ứng dụng này được viết trong môi trường Visual Studio 2008, viết bằng ngôn ngữ lập trình Visal Basic. Ứng dụng này tập trung vào xây dựng và đánh giá độ chính xác của các thuật toán được trình bày ở chương 2. Từ các cây quyết định hay các luật quyết định rút ra từ cây quyết định sẽ hỗ trợ cho các cán bộ tín dụng trong ngân hàng quyết định cho khách hàng được vay hay không.
3.4. Kết quả và đánh giá thuật toán
3.4.1. Mô hình cây quyết định tương ứng với tập dữ liệu Bank_data
Cây quyết định ứng với thuật toán ID3
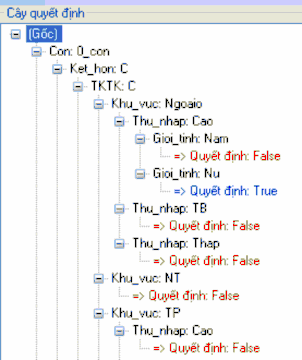
Hình 17. Dạng cây quyết định ID3
Cây quyết định ứng với thuật toán ADTDA

Hình 18. Dạng cây quyết định ADTDA
Cây quyết định ứng với thuật toán FID3
Trong quá trình thực nghiệm tác giả thấy trong thuật toán FID3 nếu áp dụng trên 1 cơ sở dữ liệu lớn thì độ phục thuộc của các thuộc tính điều kiền vào thuộc tính quyết định đều bằng 0 (ở bước đầu tiên khi xây dựng cây quyết định). Do đó, lượng thông tin thu thêm ổn định IGfix của các thuộc tính điều kiện cũng bằng 0. Trong trường hợp này thì thuật toán sẽ chọn một thuộc tính bất kỳ (thuộc tính đầu tiên) làm thuộc tính phân chia, và như vậy cây quyết định sẽ không tối ưu. Vì vậy, tác giả đã mạnh dạn cải tiến dựa theo thuật toán ADTDA, đó là nếu tất các các độ phụ thuộc của thuộc tính điều kiện vào thuộc tính quyết định là bằng 0, thì lượng thông tin thu ổn định IGfix sẽ được tính dựa vào độ phụ thuộc chính xác , tức là:
IG fix
(U , c)
(d , c) * IG(U , c)
| c |
Và khi đó cây quyết định của thuật toán FID3 trên cơ sở dữ liệu Bank_data như sau:
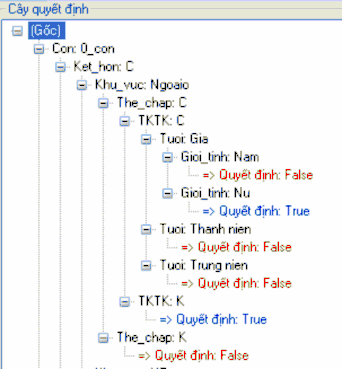
Hình 19. Dạng cây quyết định FID3
3.4.2. Các luật quyết định tương ứng với tập dữ liệu Bank_data
Các luật quyết định ứng với cây quyết định ID3

Hình 20. Một số luật của cây quyết định ID3
Các luật quyết định ứng với cây quyết định ADTDA
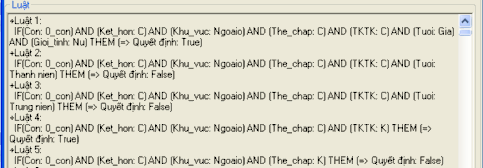
Hình 21. Một số luật của cây quyết định ADTDA
Các luật quyết định ứng với cây quyết định FID3

Hình 22. Một số luật của cây quyết định FID3
3.4.3. Đánh giá thuật toán
Đánh giá độ chính xác của thuật toán với số nếp gấp (fold) là 10 trên bộ dữ liệu tennis (Bảng 3) và bộ dữ liệu Bank_data, ta được kết quả như sau:
Số mẫu | Số thuộc tính | ID3 | ADTDA | FID3 | |
Bank_data | 600 | 11 | 77.33% | 78.57% | 80.71% |
Tennis | 12 | 5 | 80% | 80% | 80% |
Trung bình | 78.67% | 79.29% | 80.36% |
Bảng 5. Độ chính xác của các thuật toán
3.4.4. Ứng dụng cây quyết định trong khai phá dữ liệu
Ứng dụng hỗ trợ các bộ ngân hàng ra quyết định cho khách hàng vay hay không. Với những tin về khách hàng xin vay (đã biết giá trị của các thuộc tính điều kiện nhưng chưa được phân lớp) dựa vào mô hình cây quyết định đã được xây dựng ta dự đoán được lớp của bộ dữ liệu đó (cho vay hay không cho vay). Từ đó hỗ trợ cho cán bộ ngân hàng trong quá trình ra quyết định cho vay hay không.
Trong ứng dụng, khi xây dựng mô hình cây quyết định có đánh giá độ chính xác của từng luật quyết định dựa trên bộ dữ liệu đưa vào để training. Do đó, việc phân lớp các mẫu dữ liệu mới đã đưa ra được độ tin cậy của việc phân lớp đó.
Ví dụ khi đánh giá độ chính xác của luật 9 dựa trên bộ dữ liệu training là 90%. Quá trình phân lớp trên mẫu dữ liệu nào đó dựa vào luật 9, thì độ tin cậy của lớp đó sẽ là 90%.
Độ tin cậy của các luật quyết định phụ thuộc rất lớn vào bộ dữ liệu training, dữ liệu training càng đủ lớn thì độ tin cậy của các luật càng cao. Tuy nhiên, trong ứng dụng này việc xây dựng cây quyết định chỉ dựa trên bộ dữ liệu training gồm 600 dữ liệu, do đó độ tin cậy của các luật chỉ mang tính chất minh họa (tính chính xác không cao).
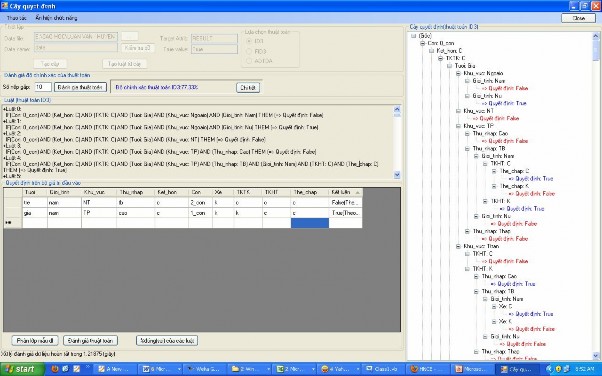
Hình 23. Giao diện ứng dụng
3.5. Kết luận chương 3
Trong chương này đã phát biểu bài toán để kiểm chứng các thuật toán xây dựng cây quyết định ở chương 2 trên bộ dữ liệu mẫu Bank_data. Đồng thời cài đặt, đánh giá độ chính xác của từng thuật toán và đánh giá độ chính xác của các luật. Dựa vào mô hình cây quyết định (các luật quyết định) đã được xây dựng, phân lớp các mẫu dữ liệu mới.
KẾT LUẬN
Khai phá dữ liệu là một lĩnh vực đã, đang và luôn luôn thu hút các nhà nghiên cứu bởi nó là một lĩnh vực cho phép phát hiện tri thức trong cơ sở dữ liệu khổng lồ bằng các phương thức thông minh. Nghiên cứu lĩnh vực này đòi hỏi người nghiên cứu phải biết tổng hợp các kết quả nghiên cứu ở nhiều lĩnh vực của khoa học máy tính và việc ứng dụng nó trong từng nhiệm vụ của khai phá dữ liệu.
Qua hai năm học tập, tìm tòi, nghiên cứu, đặc biệt là trong khoảng thời gian làm luận văn, tác giả đã hoàn thiện luận văn với các mục tiêu đặt ra ban đầu. Cụ thể luận văn đã đạt được những kết quả sau:
- Trình bày các kiến thức cơ bản về khai phá dữ liệu; hệ thống hóa các kiến thức cơ bản của lý thuyết tập thô được áp dụng để xây dựng cây quyết định.
- Giới thiệu phương pháp tổng quát xây dựng cây quyết định, và trình bày ba thuật toán xây dựng cây quyết định ID3, ADTDA, FID3 và một số ví dụ minh họa cho các phương pháp xây dựng cây quyết định cũng được trình bày.
- Cài đặt bằng Visual Basic ba thuật toán xây dựng cây quyết định ID3, ADTDA, FID3 trên cơ sở dữ liệu mẫu Bank_data. Đánh giá độ chính xác của các thuật toán trên và đánh giá độ chính xác của từng luật trong mô hình cây quyết định.
Qua quá trình học tập, nghiên cứu tác giả không những tích lũy được thêm các kiến thức mà còn nâng cao được khả năng lập trình, phát triển ứng dụng. Tác giả nhận thấy luận văn đã giải quyết tốt các nội dung, yêu cầu nghiên cứu đặt ra, có các ví dụ minh họa cụ thể. Song do thời gian có hạn nên luận văn vẫn còn tồn tại một số thiếu sót, một số vấn đề mà tác giả còn phải tiếp tục nghiên cứu, tìm hiểu.
Hướng phát triển của đề tài là:
Về lý thuyết:
- Cần tiếp tục nghiên cứu các thuật toán khai phá dữ liệu bằng cây quyết định dựa vào tâp thô như: thuật toán ADTCCC (dựa vào CORE và đại
lượng đóng góp phân lớp của thuộc tính), thuật toán ADTNDA (dựa vào độ phụ thuộc mới của thuộc tính), …
- Nghiên cứu các phương pháp xây dựng cây quyết định trên hệ thống thong tin không đầy đủ, dữ liệu liên tục và không chắc chắn.
Về chương trình demo:
- Cần bổ sung thêm dữ liệu cho tập training để mô hình cây quyết định có độ tin cậy cao hơn và hoạt động hiệu quả hơn.
- Cần tiếp tục phát triển hoàn thiện theo hướng trở thành phần mềm khai phá dữ liệu trong tín dụng tiêu dùng nhằm hỗ trợ cho cán bộ tín dụng đưa ra quyết định cho khách hàng vay hay không.
- Tìm hiểu nhu cầu thực tế để từ đó cải tiến chương trình, cài đặt lại bài toán theo các thuật toán đã nghiên cứu để làm việc tốt hơn với các cơ sở dữ liệu lớn và có thể có được sản phẩm trên thị trường..