Hơn nữa nhánh “low” có các mẫu {5, 9} cùng thuộc một lớp “TRUE ” nên nút lá được tạo ra với nhãn là “TRUE ”.
Kết quả phân chia sẽ là cây quyết định như sau:
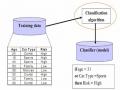
Humidity
{1, 2, …., 12}
high
low
Normal
ID3(U1, C-{humidity}, {d})
Có thể bạn quan tâm!
-
 Phân tách cụm danh từ cơ sở tiếng việt sử dụng mô hình crfs - 2
Phân tách cụm danh từ cơ sở tiếng việt sử dụng mô hình crfs - 2 -
 Một Bảng Quyết Định Với C={Age, Lems} Và D={Walk}
Một Bảng Quyết Định Với C={Age, Lems} Và D={Walk} -
 Ứng Dụng Cây Quyết Định Trong Khai Phá Dữ Liệu
Ứng Dụng Cây Quyết Định Trong Khai Phá Dữ Liệu -
 Thuật Toán Xây Dựng Cây Quyết Định Dựa Vào Entropy Và Độ Phụ Thuộc Của Thuộc Tính
Thuật Toán Xây Dựng Cây Quyết Định Dựa Vào Entropy Và Độ Phụ Thuộc Của Thuộc Tính -
 Phân tách cụm danh từ cơ sở tiếng việt sử dụng mô hình crfs - 7
Phân tách cụm danh từ cơ sở tiếng việt sử dụng mô hình crfs - 7 -
 Phân tách cụm danh từ cơ sở tiếng việt sử dụng mô hình crfs - 8
Phân tách cụm danh từ cơ sở tiếng việt sử dụng mô hình crfs - 8
Xem toàn bộ 68 trang tài liệu này.
{1, 2, 3, 6, 7, 12}
ID3(U2, C-{humidity}, {d})

{4, 8, 10, 11}
TRUE
{5, 9 }
Hình 8. Cây sau khi chọn thuộc tính Humidity (ID3)
Bước tiếp theo gọi thuật toán đệ quy: ID3(U1, C-{Humidity}, {d})
Tương tự để tìm điểm chia tốt nhất tại thuật toán này, phải tính toán chỉ số IG của các thuộc tính “Outlook”, “Windy”, “Temp”.
- Đầu tiên ta cũng tính Entropy cho toàn bộ tập huấn luyện trong U1 gồm một bộ {1} có thuộc tính nhãn là “TRUE ” và năm bộ {2, 3, 6, 7, 12} có thuộc tính nhãn là “FALSE”:
1 1 5 5
Entropy
(U 1 ) 6 log 2 6 6 log 2 6
0 .65
- Tiếp theo tính IG cho thuộc tính “Outlook”, thuộc tính này có ba giá trị là “Overcast”, “Sunny” và “Rainy”. Nhìn vào bảng dữ liệu:
Với giá trị “Overcast” chỉ có một bộ {1} có giá trị thuộc tính nhãn là “TRUE ”.
Tương tự giá trị “Sunny” chỉ có hai bộ {2, 3} đều có nhãn lớp là “FALSE”;
Với giá trị “Rainy” chỉ có ba bộ {6, 7, 12} đều có nhãn lớp “FALSE”.
Do đó, độ đo lượng thông tin thu thêm của thuộc tính “Outlook” xét trên
U1 là:
1 1 1 2 2
2 3 3 3
IG(U1, Outlook) =0.65 - [ 6 (1 log 2 1 ) 6 (2 log 2 2 ) 6 (3 log 2 3 )] = 0.65
- Tính tương tự ta cũng có:
1 1 1 5 5 5
IG(U1, Windy) = 0.65 - [ ( log 2 1 ) ( log 2 5 )] = 0.65
6 1 6 5
1 1 1 5 5 5
IG(U1, Temp) = 0.65 - [ ( log 2 1 ) ( log 2 5 )] = 0.65
6 1 6 5
Ta thấy chỉ số IG của ba thuộc tính “Outlook”, “Windy”, “Temp” là như nhau, ta có thể chọn bất kỳ thuộc tính nào để phân chia.
Giả sử ta chọn thuộc tính “Outlook” để phân chia. Do đó, thuộc tính “Outlook” làm nhãn cho nút bên trái nối với nhánh “high”.
Thuộc tính này có ba giá trị “Overcast”, “Sunny” và “Rainy” nên ta tiếp tục tạo thành ba nhánh mới là “Overcast”, “Sunny” và “Rainy”:
Với nhánh “Overcast” gồm một mẫu {1} và có giá trị quyết định là “TRUE ” nên ta tạo nút lá là “TRUE ”.
Với nhánh “Sunny” gồm hai mẫu {2, 3} và có cùng giá trị quyết định là “FALSE” nên tạo nút lá là “FALSE”.
Với nhánh “Rainy” có ba mẫu {6, 7, 12} và đều có giá trị quyết định là “FALSE” nên ta tạo nút lá là “FALSE”.
Sau khi thực hiện xong thuật toán đệ quy: ID3(U1, C-{Humidity}, {d}), ta có cây như sau:
Humidity
{1, 2,…, 12}
high
low
Normal
Outlook
{1, 2, 3, 6, 7, 12}
ID3(U2, C-{humidity}, {d})
{4, 8, 10 , 11}
Overcast Sunny
Rainy
TRUE
{5, 9 }
TRUE
{1 }
FALSE
{2, 3 }
FALSE
{6, 7, 12 }
Hình 9. Cây sau khi chọn thuộc tính Outlook (ID3)
Bước tiếp theo gọi thuật toán đệ quy: ID3(U2, C-{ Humidity}, {d})
Tính một cách tương tự như trên ta có:
1 1 3 3
Entropy (U2) =
log 4 log 4
4 2 4 2
0.811
IG(U2, Outlook) =
1 1 1 3 1 1 2 2
0.811 - [ ( log 2 1 ) ( log 2 3 log 2 3 )] = 0.811-0.689 = 0.123
4 1 4 3 3
IG(U2, Windy) =
3 1 1 2 2 1 1
0.811 - [ ( log 2 3 log 2 3 ) 1/ 4( log 2 1 )]
4 3 3 1
IG(U2, Temp) =
= 0.811-0.689 = 0.123
3 3 3 1 1 1
0.811 - [ ( log 2 3 ) ( log 2 1 )]
4 3 3 1
= 0.811-0 = 0.811
Ta thấy chỉ số IG của “Temp” là lớn nhất, nên nó được chọn để phân chia.
Do đó, thuộc tính “Temp” làm nhãn cho nút bên phải nối với nhánh “Normal”.
Trong U2, thuộc tính này có hai giá trị “hot” và “mild” nên ta tiếp tục tạo thành hai nhánh mới là “hot” và “mild”:
Với nhánh “hot” gồm ba mẫu {4, 8, 11} và đều có giá trị quyết định là “FALSE” nên ta tạo nút lá là “FALSE”.
Với nhánh “mild” gồm một mẫu {10} và có giá trị quyết định là “TRUE ” nên tạo nút lá là “TRUE ”.
Cây cuối cùng như sau:
Humidity
{1, 2,…, 12}
high
low
Normal
Outlook
{1, 2, 3, 6, 7, 12}
Temp
{4, 8, 10 , 11}
hot
mild
Overcast Sunny
Rainy
TRUE
{5, 9 }
FALSE
{4, 8, 11 }
TRUE
{10 }
TRUE
{1 }
FALSE
{2, 3 }
FALSE
{6, 7, 12 }
Hình 10. Cây kết quả (ID3)
2.3. Thuật toán xây dựng cây quyết định dựa vào độ phụ thuộc của thuộc tính
2.3.1. Độ phụ thuộc của thuộc tính theo lý thuyết tập thô
Xét bảng quyết định DT = (U, C {D}). Ta nói D phụ thuộc C với độ phụ thuộc k (0 k 1) [10]:
Dễ dàng thấy rằng:
k = γ(C,D) =
| POSC (D) |
| U |
0 (C, D) 1
γ(C,D) =
XU / IND(D)
| CX |
| U |
Độ phụ thuộc (C, D) có các tính chất sau:
- Nếu (C, D) = 1 thì D phụ thuộc hoàn toàn vào C
- Nếu 0 < (C, D) < 1 thì d phụ thuộc một phần vào B
- Nếu (d, B) = 0 thì không có đối tượng nào của U có thể được phân lớp đúng (như d) dựa vào tập thuộc tính B.
2.3.2. Độ phụ thuộc chính xác theo lý thuyết tập thô
Xét bảng quyết định DT = (U, C {D}) và tập con thuộc tính điều kiện B
C. Giả sử U/D = {Y1, Y2, …, Ym} và U/B = {X1, X2, …, Xn}. Đặt
(B, D)
xB
| | xB
| xB
| U |
Y |
|
(B, D) gọi là độ phụ thuộc chính xác dùng để đo tỉ lệ các đối tượng được phân lớp với mức độ chính xác , trong đó giá trị (0.5 ≤ ≤ 1) dùng để xác định tỉ lệ các phân lớp đúng [10].
2.3.3. Tiêu chí chọn thuộc tính để phân lớp
Theo cách tiếp cận tập thô, độ phụ thuộc (c, d) được sử dụng làm tiêu chuẩn lựa chọn thuộc tính kiểm tra tại mỗi nút trong quá trình phát triển cây quyết định: thuộc tính được chọn là thuộc tính c cho giá trị (c, d) lớn nhất trong số các thuộc tính còn lại tại mỗi bước [10]. Nếu tất cả độ phụ thuộc (c, d) của các thuộc tính bằng không thì thuộc tính được chọn là thuộc có độ phụ thuộc chính xác lớn nhất.
2.3.4. Thuật toán xây dựng cây quyết định ADTDA
Thuật toán ADTDA - Algorithm for Buiding Decision Tree Based on Dependency of Attributes [10] là thuật toán dùng để xây dựng cây quyết định được Longjun Huang, Minghe Huang, Bin Guo, and Zhiming Zhang trình bày. Ý tưởng chính của thuật toán ADTDA là để xây dựng cây quyết định bằng cách ứng dụng từ trên xuống chiến lược tham lam thông qua các tập đã cho để kiểm tra từng thuộc tính ở mọi nút của cây. Để chọn thuộc tính "tốt nhất" (để có cây tối ưu – có độ sâu nhỏ nhất), người ta phải tính độ phụ thuộc của thuộc tính quyết định vào thuộc tính điều kiện. Thuộc tính được chọn phải có độ phụ thuộc lớn nhất.
Giả mã của thuật toán ADTDA như sau:
Dữ liệu vào: Bảng quyết định DT = (U, C {d})
Dữ liệu ra: Mô hình cây quyết định Function Create_tree (U, C, {d}) Begin
If tất cả các mẫu thuộc cùng nhãn lớp di then return một nút lá được gán nhãn di
else if C = null then
return nút lá có nhãn dj là lớp phổ biến nhất trong DT
else begin
bestAttribute:= getBestAttribute(U, C);
// Chọn thuộc tính tốt nhất để chia Lấy thuộc tính bestAttribute làm gốc;
C := C- {bestAttribute};
//xóa bestAttribute khỏi tập thuộc tính Với mỗi giá trị v in bestAttribute
begin
end
Uv := [U]v ;
//Uv là phân hoạch của DT theo thuộc tính
//bestAttribute có giá trị là v ChildNode:=Create_tree(Uv, U, {d});
//Tạo 1 nút con
Gắn nút ChildNode vào nhánh v;
End
end
Thuật toán ADTDA giống thuật toán ID3, nhưng khác nhau ở hàm
getBestAttribute.
Giả mã của hàm getBestAttribute như sau:
Dữ liệu vào: Bảng quyết định DT = (U, C{d})
Dữ liệu ra: Thuộc tính điều kiện tốt nhất
Function getBestAttribute (U, C);
Begin
maxDependency := 0;
Với mỗi c in C
begin
k : = DependencyGama(U, c);
// Tính độ phụ thuộc của thuộc tính γ(c,d)
If (k > maxDependency) then begin
end
return kq;
end
maxDependency := k; kq := c;
//Hàm trả về thuộc tính có độ phụ thuộc của thuộc tính γ(c,d) lớn nhất
End
2.3.5. Ví dụ
Xét bảng quyết định cho trong Bảng 5
Để xây dựng cây ta tính độ phụ thuộc của tất cả các thuộc tính điều kiện vào thuộc tính quyết định d.
- Thuộc tính quyết định d có 4 mẫu {1, 5, 9, 10} có giá trị “TRUE ” và 6 mẫu {2, 3, 4, 6, 7, 8, 11, 12} có giá trị “FALSE” , nên ta có:
[U]d = {{1, 5, 9 ,10}, {2, 3, 4, 6, 7, 8, 11, 12}}
- Thuộc tính “Outlook” có ba giá trị “Overcast” gồm 3 mẫu {1, 4, 9}, “sunny” gồm 3 mẫu {2, 3, 5} và “rainy” gồm sáu mẫu {6, 7, 8, 10, 11, 12} nên :
[U]Outlook= {{1, 4, 9}, {2, 3, 5}, {6, 7, 8, 11, 11, 12}}
Do đó: (Outlook, d ) | posOutlook (d ) | | {} | 0 0
Tương tự, ta có:
| U |
| U | 12
[U]Windy = {{1, 5, 9, 11},{2, 3, 4, 6, 7, 8, 10, 12}}
(Windy, d) | posWindy (d ) | | {} | 0
0.
| U | | U | 12
[U]Temp={{1}, {2, 6, 10}, {3, 4, 5, 7, 8, 9, 11, 12}
(Temp, d ) | posTemp (d ) | | {1} | 1 .
| U | | U | 12
[U]Humidity = {{1, 2, 3, 6, 7, 12}, {4, 8, 10, 11}, {5, 9}}
(Humidity, d ) | posHumidity (d ) | | {5,9} | 2 .
| U | | U | 12
Ta thấy
(Humidity , d )
có giá trị lớn nhất nên ta chọn thuộc tính
“Humidity” làm thuộc tính phân chia. Như vậy nút gốc có nhãn là “Humidity” và có 3 nhánh được tạo ra lần lượt với tên là: “high”, “Normal”, “low”.
Hơn nữa nhánh “low” có các mẫu {5, 9} cùng thuộc một lớp “TRUE ” nên nút lá được tạo ra với nhãn là “TRUE ”.
Kết quả phân chia sẽ là cây quyết định như sau:
Humidity
U={1, 2, …., 12}
high
low
Normal
ADTDA(U1, C-{humidity}, {d})
U1={1, 2, 3, 6, 7, 12}
ADTDA(U2, C-{humidity}, {d}) U2={4, 8, 10, 11}
TRUE
{5, 9 }
Hình 11. Cây sau khi chọn thuộc tính Humidity (ADTDA)
Bước tiếp theo gọi thuật toán đệ quy: ADTDA (U1, C-{Humidity},
{d})
Ta có: [U1]d = {{1}, {2, 3, 6, 7, 12}}
[U1]Outlook= {{1}, {2, 3}, {6, 7, 12}}
Do đó, (Outlook, d ) | posOutlook (d ) | | {1,2,3,6,7,12} | 6 1
| U1 |
[U1]windy = {{1}, {2, 3, 6, 7, 12}
| U1 | 6
(windy, d ) | poswindy (d ) | | {1,2,3,6,7,12} | 6 1
| U1 | | U1 | 6
[U1]Temp={{1}, {2, 6}, {3, 7, 12}}
(Temp, d ) | posTemp (d ) | | {1,2,3,6,7,12} | 6 1
| U1 | | U1 | 6
Ta thấy độ phụ thuộc của ba thuộc tính “Outlook”, “Windy”, “Temp” vào thuộc tính quyết định d là như nhau, nên ta có thể chọn bất kỳ thuộc tính nào để phân chia.
Tương tự như ở thuật toán ID3, ta có cây như sau:
Humidity
U={1, 2, …., 12}
high
low
Normal
outlook
U1={1, 2, 3, 6, 7, 12}
ADTDA(U2, C-{humidity}, {d}) U2={4, 8, 10 , 11}
Overcast Sunny
Rainy
TRUE
{5, 9 }
TRUE
{1 }
FALSE
{2, 3 }
FALSE
{6, 7, 12 }
Hình 12. Cây sau khi chọn thuộc tính Outlook (ADTDA)
Bước tiếp theo gọi thuật toán đệ quy: ADTDA(U2, C-{Humidity}, {d})
Một cách tương tự như trên ta có: [U2]d= {{10}, {4, 8, 11}}
[U2]Outlook = {{4}, {8, 10, 11}}
Do đó, (Outlook, d ) | posOutlook (d ) | | {4} | 1
| U 2 |
[U2]windy = {{4, 8, 10}, {11}
(windy, d ) | poswindy (d ) | | {11} | 1
| U 2 | 4
| U 2 | | U 2 | 4
[U2]Temp={{4, 8, 11}, {10}}