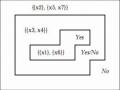
(Temp, d ) | posTemp (d ) | | {4,8,10,11} | 4 1
| U 2 | | U 2 | 4
Ta thấy (Temp, d ) là lớn nhất, nên thuộc tính “temp” được chọn để phân
chia. Do đó, thuộc tính “Temp” làm nhãn cho nút bên phải nối với nhánh “Normal”.
Tương tự như trong thuật toán ID3, cây cuối cùng như sau:
Humidity
{1, 2,…, 12}
high
Có thể bạn quan tâm!
-
 Một Bảng Quyết Định Với C={Age, Lems} Và D={Walk}
Một Bảng Quyết Định Với C={Age, Lems} Và D={Walk} -
 Ứng Dụng Cây Quyết Định Trong Khai Phá Dữ Liệu
Ứng Dụng Cây Quyết Định Trong Khai Phá Dữ Liệu -
 Thuật Toán Xây Dựng Cây Quyết Định Dựa Vào Độ Phụ Thuộc Của Thuộc Tính
Thuật Toán Xây Dựng Cây Quyết Định Dựa Vào Độ Phụ Thuộc Của Thuộc Tính -
 Phân tách cụm danh từ cơ sở tiếng việt sử dụng mô hình crfs - 7
Phân tách cụm danh từ cơ sở tiếng việt sử dụng mô hình crfs - 7 -
 Phân tách cụm danh từ cơ sở tiếng việt sử dụng mô hình crfs - 8
Phân tách cụm danh từ cơ sở tiếng việt sử dụng mô hình crfs - 8
Xem toàn bộ 68 trang tài liệu này.
low
Normal

Outlook
{1, 2, 3, 6, 7, 12}
Temp
{4, 8, 10 , 11}
Overcast Sunny
Rainy
hot
mild
TRUE
{5, 9 }
TRUE
{1 }
FALSE
{2, 3 }
FALSE
{6, 7, 12
FALSE
{14, 8, 11}
TRUE
{10 }
Hình 13. Cây kết quả (ADTDA)
2.4. Thuật toán xây dựng cây quyết định dựa vào Entropy và độ phụ thuộc của thuộc tính
2.4.1. Tiêu chí chọn thuộc tính để phân lớp
Xét bảng quyết định DT = (U, C {d}).
(d , c) * IG(U , c)
| c |
Lượng thông tin thu thêm ổn định IGfix - Fixed Information Gain [5] là tiêu chuẩn mới cho chọn thuộc tính thuộc tính điều kiện c nào đó để phân chia. IGfix được xác định theo công thức sau:
Trong đó:
IG fix
(U , c)
+ |c| là số các giá trị khác nhau của thuộc tính điều kiện c
+ (c, d) là độ phụ thuộc c vào d
+ IG(U, c) là lượng thông tin thu thêm
Lượng thông tin thu thêm ổn định của thuộc tính được sử dụng như một tiêu chuẩn cho việc chọn thuộc tính kiểm tra tại mỗi nút trong cây quyết định. Thuộc tính điều kiện với giá trị lượng thông tin thu thêm ổn định lớn nhất được chọn từ tập rút gọn thuộc tính và được sử dụng làm nút gốc của cây.
2.4.2. Thuật toán FID3 (Fixed Iterative Dichotomiser 3 [5] )
Dữ liệu vào: Bảng quyết định DT = (U, C {d})
Dữ liệu ra: Mô hình cây quyết định Function Create_tree (U, C, {d}) Begin
If tất cả các mẫu thuộc cùng nhãn lớp di then return một nút lá được gán nhãn di
else if C = null then
return nút lá có nhãn dj là lớp phổ biến nhất trong DT
else begin
bestAttribute:= getBestAttribute(U, C);
// Chọn thuộc tính tốt nhất để chia Lấy thuộc tính bestAttribute làm gốc;
C := C- {bestAttribute};
//xóa bestAttribute khỏi tập thuộc tính Với mỗi giá trị v in bestAttribute
begin
End
end
end
Uv := [U]v ;
//Uv là phân hoạch của DT theo thuộc tính
//bestAttribute có giá trị là v ChildNode:=Create_tree(Uv, C, {d});
//Tạo 1 nút con
Gắn nút ChildNode vào nhánh v;
Thuật toán FID3 giống thuật toán ID3, nhưng khác nhau ở hàm getBestAttribute.
Giả mã của hàm getBestAttribute như sau [5]:
Dữ liệu vào: Bảng quyết định DT = (U, C{d})
Dữ liệu ra: Thuộc tính điều kiện tốt nhất
Function getBestAttribute (U, C);
Begin
C’:= C ;
Với mỗi c in C
begin
end
k := DependencyGama(U, c);
// Tính độ phụ thuộc của thuộc tính γ(c,d)
If (k =0) then C’:= C’ - {c};
Với mỗi c in C’
begin
tg := Igfix(U,c);
//Tính lượng thông tin thu thêm ổn định
If (tg>maxIGfix) then begin
end
end
maxIGfix:= tg; kq := c;
End
return kq;
//Hàm trả về thuộc tính có lượng thông tin thu thêm IGfix(U,c) lớn nhất
2.4.3. Ví dụ
Xét bảng quyết định DT= (U, C {d}} cho trong Bảng 5 Trong thuật toán ADTDA ở trên, ta đã tính được:
γ(Outlook,d) = 0
γ(Windy,d) = 0
γ(Temp,d) = 1
12
(Humidity, d ) 2 .
12
Nên thuộc tính mới C’ = {Temp, Humidity}. Ta tính IGfix(U,Temp) và IGfix(U, Humidity) :
Trong thuật toán ID3 ở trên ta có: IG(U, Temp)= 0.148
IG(U, Humidity)= 0.323 Do đó:
IGfix
(U,Temp) =
0.064
(Temp, d ) * IG(U , Temp)
| Temp |
1 * 0.148
12 3
(Humidity, d ) * IG(U , Humidity)
| Temp |
IGfix(U,Humidity) =
=
2 * 0.323
12 3
0.134
Ta thấy IGfix(U,Humidity) có giá trị lớn nhất nên ta chọn thuộc tính “Humidity” làm thuộc tính phân chia. Tương tự như thuật toán ID3, ta có cây như sau:
TRUE
U={1, 2, …., 12}
high
low
Normal
FID3(U1, C-{humidity}, {d})
U1={1, 2, 3, 6, 7, 12}
TRUE
{5, 9 }
FID3(U2, C-{humidity}, {d}) U2={4, 8, 10, 11}
Hình 14. Cây quyết định sau khi chọn thuộc tính Humidity (FID3)
Bước tiếp theo gọi thuật toán đệ quy: FID3(U1, C-{Humidity}, {d})
Theo thuật toán ADTDA ta có: [U1]d = {{1}, {2, 3, 6, 7, 12}
[U1]Outlook= {{1}, {2, 3}, {6, 7, 12}}
Do đó, (Outlook, d ) | posOutlook (d ) | | {1,2,3,6,7,12} | 6 1
| U1 |
[U1]windy = {{1}, {2, 3, 6, 7, 12}
| U1 | 6
(windy, d ) | poswindy (d ) | | {1,2,3,6,7,12} | 6 1
| U1 | | U1 | 6
[U1]Temp={{1}, {2, 6}, {3, 7, 12}}
(Temp, d ) | posTemp (d ) | | {1,2,3,6,7,12} | 6 1
| U1 |
Theo thuật toán ID3 ta có: IG(U1, Windy) = 0.65 IG(U1, Outlook) = 0.65 IG(U1, Temp) = 0.65
Vậy:
(Windy, d ) * IG(U1,Windy)
| Windy |
IGfix(U1, Windy)=
(Outlook, d ) * IG(U1, Outlook)
| Outlook |
IGfix(U1, Outlook)=
(Temp, d ) * IG(U1, Temp)
| Temp |
IGfix(U1, Temp)=
| U1 | 6
1* 0.65
2
1* 0.65
3
1* 0.65
3
Ta thấy IGfix(U1, Windy) có giá trị lớn nhất nên thuộc tính “Windy” được chọn làm thuộc tính phân chia.
Do đó, thuộc tính “Windy” làm nhãn cho nút bên trái nối với nhánh “high”.
Thuộc tính này có hai giá trị “true” và “false” nên ta tiếp tục tạo thành hai nhánh mới là “true” và “false”:
Với nhánh “true” gồm một mẫu {1} và có giá trị quyết định là “Y” nên ta tạo nút lá là “Y”.
Với nhánh “false” gồm năm mẫu {2, 3, 6, 7, 12} và có cùng giá trị quyết định là “N” nên tạo nút lá là “N”.
Sau khi thực hiện xong thuật toán đệ quy: FID3(U1, C-{Humidity}, {d}), ta có cây như sau:
Humidity
{1, 2,…, 12}
high
low
Normal
windy
{1, 2, 3, 6, 7, 12}
FID3(U2, C-{humidity}, {d})
{4, 8, 10 , 11}
true
false
TRUE
{5, 9 }
TRUE
{1 }
FALSE
{2, 3, 6, 7, 12 }
Hình 15. Cây quyết định sau khi chọn thuộc tính Windy (FID3)
Bước tiếp theo gọi thuật toán đệ quy: FID3(U2, C-{Humidity}, {d})
Theo thuật toán ADTDA ta có: [U2]d= {{10}, {4, 8, 11}}
[U2]Outlook = {{4}, {8, 10, 11}}
Do đó, (Outlook, d ) | posOutlook (d ) | | {4} | 1
| U 2 |
[U2]windy = {{4, 8, 10}, {11}
(windy, d ) | poswindy (d ) | | {11} | 1
| U 2 | 4
| U 2 | | U 2 | 4
[U2]Temp={{4, 8, 11}, {10}}
(Temp, d ) | posTemp (d ) | | {4,8,10,11} | 4 1
| U 2 |
Theo thuật toán ID3 ta có:
IG(U2, Outlook) =0.123
IG(U2, Windy) = 0.123
IG(U2, Temp) = 0.811
Vậy:
(Windy, d ) * IG(U 2,Windy)
| Windy |
IGfix(U2, Windy)=
| U 2 | 4
1 * 0.123
4 2
0.124
(Outlook, d ) * IG(U 2, Outlook)
| Outlook |
IGfix(U2, Outlook)=
1 * 0.1235
4 3
0.101
IGfix(U2, Temp)=
0.519
(Temp, d ) * IG(U 2, Temp)
| Temp |
1* 0.811
3
Ta thấy chỉ số IGfix(U2,Temp) là lớn nhất, nên nó được chọn để phân chia.
Tương tự như thuật toán ID3 ta có cây cuối cùng như sau:
Humidity
{1, 2,…, 12}
high
low
Normal
windy
{1, 2, 3, 6, 7, 12}
temp
{4, 8, 10 , 11}
true
false
hot
mild
TRUE
{5, 9 }
FALSE
{4, 8, 11}
TRUE
{1 }
FALSE
{2, 3, 6, 7, 12 }
TRUE
{10 }
Hình 16. Cây kết quả (FID3)
2.5. Kết luận chương 2
Trong chương này đã trình bày phương pháp tổng quát xây dựng cây quyết định; ba thuật toán xây dựng cây quyết định ID3, ADTDA, FID3; các ví dụ cụ thể để minh họa từng bước trên mỗi thuật toán;
Chương 3 - ỨNG DỤNG KIỂM CHỨNG VÀ ĐÁNH GIÁ
3.1. Giới thiệu bài toán
Chúng ta đang sống trong thế giới thừa thông tin thiếu tri thức – đó là nhận định của nhiều người trong thời đại bùng nổ thông tin hiện nay.
Sử dụng phương pháp khai phá tri thức từ dữ liệu để dự đoán rủi ro tín dụng là một phương pháp mới nhằm nâng cao chất lượng tín dụng của Ngân hàng.
Rủi ro tín dụng có thể được hiểu là nguy cơ một người đi vay không thể trả được gốc và/hoặc lãi đúng thời hạn quy định.
Hiện nay, để phòng ngừa rủi ro tín dụng, các chuyên gia Ngân hàng thực hiện các phương pháp thu thập, phân tích và đánh giá các thông tin về khách hàng, tài sản bảo đảm của khoản vay… Phương pháp truyền thống này có nhiều hạn chế do phụ thuộc vào trình độ, tâm lý và yếu tố chủ quan khác của các cán bộ thẩm định hồ sơ vay nợ của khách hàng. Chính vì vậy mà một công cụ trợ giúp thẩm định và ước đoán chất lượng tín dụng một cách khách quan dựa trên các cơ sở khoa học là hết sức có ý nghĩa và cần thiết. Việc đề xuất cho vay hay không dựa vào các luật quyết định (phân lớp) được xây dựng thông qua cây quyết định đã được nghiên cứu. Nhờ các luật quyết định này sẽ hỗ trợ cán bộ tín dụng có quyết định cho khách hàng vay hay không.
Trong phạm vi luận văn này tôi đã tập trung nghiên cứu đối với công tác tín dụng tiêu dùng của khách hàng với tập dữ liệu Bank_data. Dựa vào tập Bank_data sẽ xây dựng mô hình cây quyết định, từ cây quyết định rút ra các luật quyết định. Dựa vào các luật quyết định đó ta sẽ phân lớp được tập dữ liệu mới (dữ liệu về khách hàng xin vay tiêu dùng, nhưng chưa được phân lớp) và tập dữ liệu sau khi được phân lớp sẽ hỗ trợ cho các cán bộ tín dụng ra quyết định cho khách hàng vay hay không.
3.2. Giới thiệu về cơ sở dữ liệu
Trong quá trình thử nghiệm, tôi sử dụng tập dữ liệu Bank_data trích từ cơ sở dữ liệu được sưu tầm bởi giáo sư Bamshad Mobasher của Khoa “School of Computing, College of Computing and Digital Media” tại đại học “DePaul University” tại Mỹ (http://maya.cs.depaul.edu/classes/ect584/WEKA/data/ bank-data.csv). Tập dữ liệu này gồm 600 đối tượng, sau khi tiền sử lí với phần