MỞ ĐẦU
Lý do chọn đề tài
Trong những năm gần đây Công nghệ thông tin phát triển mạnh mẽ và có những tiến bộ vượt bậc. Cùng với sự phát triển của Công nghệ thông tin là sự bùng nổ thông tin. Các thông tin tổ chức theo phương thức sử dụng giấy trong giao dịch đang dần được số hóa, do nhiều tính năng vượt trội mà phương thức này mang lại như: có thể lưu trữ lâu dài, cập nhật, sửa đổi, tìm kiếm một cách nhanh chóng. Đó là lý do khiến cho số lượng thông tin số hóa ngày nay đang tăng dần theo cấp số nhân.
Hiện nay, không một lĩnh vực nào lại không cần đến sự hỗ trợ của công nghệ thông tin và sự thành công của các lĩnh vực đó phụ thuộc rất nhiều vào việc nắm bắt thông tin một cách nhạy bén, nhanh chóng và hữu ích. Với nhu cầu như thế nếu chỉ sử dụng thao tác thủ công truyền thống thì độ chính xác không cao và mất rất nhiều thời gian. Do vậy việc khai phá tri thức từ dữ liệu trong các tập tài liệu lớn chứa đựng thông tin phục vụ nhu cầu nắm bắt thông tin có vai trò hết sức to lớn. Việc khai phá tri thức đã có từ lâu nhưng sự bùng nổ của nó thì mới chỉ xảy ra trong những năm gần đây. Các công cụ thu thập dữ liệu tự động và các công nghệ cơ sở dữ liệu được phát triển dẫn đến vấn đề một lượng dữ liệu khổng lồ được lưu trữ trong cơ sở dữ liệu và trong các kho thông tin của các tổ chức, cá nhân....Do đó việc khai phá tri thức từ dữ liệu là một trong những vấn đề đã và đang nhận được nhiều sự quan tâm của các nhà nghiên cứu. Một vấn đề quan trọng và phổ biến trong kỹ thuật khai phá dữ liệu là phân lớp, nó đã và đang được ứng dụng rộng rãi trong thương mại, y tế, công nghiệp...
Trong những năm trước đây, phương pháp phân lớp đã được đề xuất, nhưng không có phương pháp tiếp cận phân loại nào là cao hơn và chính xác hơn hẳn những phương pháp khác. Tuy nhiên với mỗi phương pháp có một lợi thế và bất lợi riêng khi sử dụng. Một trong những công cụ khai phá tri thức hiệu quả hiện nay là sử dụng cây quyết định để tìm ra các luật phân lớp.
Phân lớp sử dụng lý thuyết tập thô, được đề xuất bởi Zdzislaw Pawlak vào năm 1982, và đã được nghiên cứu rộng rãi trong những năm gần đây. Lý thuyết tập thô cung cấp cho nhiều nhà nghiên cứu và phân tích dữ liệu với nhiều kỹ thuật trong khai phá dữ liệu như là các khái niệm đặc trưng bằng cách sử dụng một số dữ kiện. Nhiều nhà nghiên cứu đã sử dụng lý thuyết tập thô trong các ứng dụng như phân biệt thuộc tính, giảm số chiều, khám phá tri thức, và phân
tích dữ liệu thời gian,... Đây là một công cụ toán học mới được áp dụng trong khai phá dữ liệu có thể được dùng để lựa chọn thuộc tính để phân nhánh trong việc xây dựng cấu trúc cây quyết định và có nhiều cách tiếp cận khác nhau để chọn thuộc tính phân nhánh tối ưu, làm cho cây có chiều cao nhỏ nhất. Chính vì vậy, trong luận văn này tôi đã tìm hiểu về các phương pháp xây dựng cây quyết định dựa vào tập thô. Việc ứng dụng cây quyết định để khai phá dữ liệu đã và đang được tiếp tục tìm hiểu, nghiên cứu. Với mong muốn tìm hiểu và nghiên cứu về lĩnh vực này, tôi đã chọn đề tài “Ứng dụng cây quyết định trong khai phá dữ liệu” làm luận văn tốt nghiệp.
Có thể bạn quan tâm!
-

 Phân tách cụm danh từ cơ sở tiếng việt sử dụng mô hình crfs - 1
Phân tách cụm danh từ cơ sở tiếng việt sử dụng mô hình crfs - 1 -
 Một Bảng Quyết Định Với C={Age, Lems} Và D={Walk}
Một Bảng Quyết Định Với C={Age, Lems} Và D={Walk} -
 Ứng Dụng Cây Quyết Định Trong Khai Phá Dữ Liệu
Ứng Dụng Cây Quyết Định Trong Khai Phá Dữ Liệu -
 Thuật Toán Xây Dựng Cây Quyết Định Dựa Vào Độ Phụ Thuộc Của Thuộc Tính
Thuật Toán Xây Dựng Cây Quyết Định Dựa Vào Độ Phụ Thuộc Của Thuộc Tính
Xem toàn bộ 68 trang tài liệu này.
Mục tiêu nghiên cứu
Mục đích của luận văn là nghiên cứu các vấn đề cơ bản của lý thuyết tập thô, cây quyết định và các thuật toán xây dựng cây quyết định trên hệ thông tin đầy đủ dựa trên tập thô; cài đặt và đánh giá các thuật toán xây dựng cây quyết định đã nghiên cứu; bước đầu áp dụng mô hình cây quyết định đã xây dựng vào trong khai phá dữ liệu (hỗ trợ ra quyết định trong vay vốn).
Bố cục luận văn
Luận văn gồm 3 chương chính:
Chương 1: Tổng quan về khai phá tri thức và lý thuyết tập thô
Trong chương này trình bày tổng quan về khai phá dữ liệu và lý thuyết tập
thô.
Chương 2: Cây quyết định và các thuật tóan xây dựng cây quyết định.
Trong chương này giới thiệu tổng quan về cây quyết đinh, phương pháp tổng quát xây dựng cây quyết định và ba thuật toán xây dựng cây quyết định: ID3, ADTDA, FID3
Chương 3: Thực nghiệm và đánh giá.
Phát biểu bài toán, cài đặt ứng dụng và đánh giá.
Chương 1 - TỔNG QUAN VỀ KHAI PHÁ DỮ LIỆU VÀ LÝ THUYẾT TẬP THÔ
1.1. Giới thiệu về khai phá dữ liệu
1.1.1 Khám phá tri thức
Trong thời đại bùng nổ công nghệ thông tin, các công nghệ lưu trữ dữ liệu ngày càng phát triển nhanh chóng tạo điều kiện cho các đơn vị thu thập dữ liệu nhiều hơn và tốt hơn. Đặc biệt trong lĩnh vực kinh doanh, các doanh nghiệp đã nhận thức được tầm quan trọng cuả việc nắm bắt và xử lí thông tin. Nó hỗ trợ các chủ doanh nghiệp trong việc đưa ra các chiến lược kinh doanh kịp thời mang lại những lợi nhuận to lớn cho doanh nghiệp của mình. Tất cả lí do đó khiến cho các cơ quan, đơn vị và các doanh nghiệp đã tạo ra một lượng dữ liệu khổng lồ cỡ Gigabyte thậm chí là Terabyte cho riêng mình. Các kho dữ liệu ngày càng lớn và tiềm ẩn nhiều thông tin có ích. Sự bùng nổ đó dẫn tới một yêu cầu cấp thiết là phải có những kĩ thuật và công cụ mới để biến kho dữ liệu khổng lồ kia thành những thông tin cô đọng và có ích. Khám phá tri thức từ dữ liệu (Knowledge Discovery from Data - KDD) ra đời như một kết quả tất yếu đáp ứng các nhu cầu đó.
Quá trình khám phá tri thức từ dữ liệu thông thường gồm các bước chính sau [2]-[7]:
Bước 1: Xác định vấn đề và lựa chọn nguồn dữ liệu (Problem Understanding anh Data Understanding)
Trong giai đoạn này các chuyên gia trong lĩnh vực cần phải thảo luận với các chuyên gia tin học, để xác định được chúng ta mong muốn khám phá những gì, thống nhất giải pháp cho quá trình khám phá dữ liệu (muốn có các luật hay muốn phân lớp, phâm cụm dữ liệu…). Đây là một giai đoạn quan trọng vì nếu xác định sai vấn đề thì toàn bộ quá trình phá sản, nó trở nên vô ích.
Bước 2: Chuẩn bị dữ liệu (Data preparation)
Bao gồm các quá trình sau:
- Thu thập dữ liệu (data gathering)
- Làm sạch dữ liệu (data cleaning)
- Tích hợp dữ liệu ( data integeration)
- Chọn dữ liệu (data selection)
- Biến đổi dữ liệu (data transformation)
Đây cũng là một giai đoạn rất quan trọng vì nếu dữ liệu đầu vào không chính xác thì hiển nhiên sẽ không thể nào có một kết quả chính xác được.
Bước 3 : Khai phá dữ liệu (Data Mining)
Đây là bước xác định nhiệm vụ khai phá dữ liệu và lựa chọn kỹ thuật khai phá dữ liệu. Kết quả của quá trình này sẽ tìm ra các tri thức, mô hình hay các quy luật tiềm ẩn bên trong dữ liệu.
Bước 4: Đánh giá mẫu (Partern Evalution)
Đánh giá xem tri thức thu được có chính xác và có giá trị hay không, nếu không có thể quay lại các bước trên. Việc đánh giá này được thực hiện thông qua các chuyên gia trong lĩnh vực và người dùng là chính chứ không phải là các chuyên gia tin học.
Bước 5: Biểu diễn tri thức và triển khai (Knowlegde presentation and Deployment)
Biểu diễn tri thức phát hiện được dưới dạng tường minh, thân thiện và hữu ích với đa số người dùng và tiến hành đưa tri thức phát hiện được vào các ứng dụng cụ thể.
1.1.2. Khai phá dữ liệu
Khai phá dữ liệu chỉ là một bước trong quá trình khám phá tri thức từ cơ sở dữ liệu. Khai phá dữ liệu bao gồm các giai đoạn sau [7]:
Giai đoạn 1: Gom dữ liệu (Gathering)
Đây là bước tập hợp các dữ liệu được khai thác trong một cơ sở dữ liệu, một kho dữ liệu và thậm chí các dữ liệu từ các nguồn ứng dụng Web.
Giai đoạn 2: Trích lọc dữ liệu (Selection)
Ở giai đoạn này dữ liệu được lựa chọn hoặc phân chia theo một số tiêu chuẩn nào đó, ví dụ chọn tất cả những người có tuổi đời từ 25 – 35 và có trình độ đại học.
Giai đoạn 3: Làm sạch, tiền xử lý và chuẩn bị trước dữ liệu (Cleansing, Pre-processing and Preparation)
Giai đoan thứ ba này là giai đoạn hay bị sao lãng, nhưng thực tế nó là một bước rất quan trọng trong quá trình khai phá dữ liệu. Một số lỗi thường mắc phải trong khi gom dữ liệu là tính không đủ chặt chẽ, logíc. Vì vậy, dữ liệu thường chứa các giá trị vô nghĩa và không có khả năng kết nối dữ liệu. Ví dụ: tuổi = 673. Giai đoạn này sẽ tiến hành xử lý những dạng dữ liệu không chặt chẽ nói trên. Những dữ liệu dạng này được xem như thông tin dư thừa, không có giá trị. Bởi vậy, đây là một quá trình rất quan trọng vì dữ liệu này nếu không được “làm sạch - tiền xử lý - chuẩn bị trước” thì sẽ gây nên những kết quả sai lệch nghiêm trọng.
Giai đoạn 4: Chuyển đổi dữ liệu (Transformation)
Dữ liệu sẽ được chuyển đổi phù hợp với mục đích khai thác.
Giai đoạn 5: Phát hiện và trích mẫu dữ liệu (Pattern Extraction and Discovery)
Ở giai đoạn này nhiều thuật toán khác nhau đã được sử dụng để trích ra các mẫu từ dữ liệu. Thuật toán thường dùng là nguyên tắc phân loại, nguyên tắc kết hợp hoặc các mô hình dữ liệu tuần tự,. v.v.
Giai đoạn 6: Đánh giá kết quả mẫu (Evaluation of Result)
Đây là giai đoạn cuối trong quá trình khai phá dữ liệu. Ở giai đoạn này, các mẫu dữ liệu được chiết xuất ra bởi phần mềm khai phá dữ liệu. Không phải bất cứ mẫu dữ liệu nào cũng đều hữu ích, đôi khi nó còn bị sai lệch. Vì vậy, cần phải ưu tiên những tiêu chuẩn đánh giá để chiết xuất ra các tri thức (Knowlege) cần chiết xuất ra.
1.2. Ứng dụng của khai phá dữ liệu
Hiện nay, kĩ thuật khai phá dữ liệu đang được áp dụng một cách rộng rãi trong rất nhiều lĩnh vực kinh doanh và đời sống khác nhau như marketing, tài chính, ngân hàng và bảo hiểm, khoa học, y tế, an ninh, internet, …
+ Y học và chăm sóc sức khỏe : chẩn đoán bệnh trong y tế dựa trên kết quả xét nghiệm đã giúp cho bảo hiểm y tế Australia phát hiện ra nhiều trường hợp xét nghiệm không hợp lí tiết kiệm được 1 triệu $/năm.
+ Marketing: IBM Surf – Aid đã áp dụng khai phá dữ liệu vào phân tích các lần đăng nhập Web vào các trang có liên quan đến thị trường để phát hiện sở thích khách hàng, từ đó đánh giá hiệu quả của việc tiếp thị qua Web và cải thiện hoạt động của các Website; Trang Web mua bán qua mạng Amazon cũng tăng doanh thu nhờ áp dụng Khai phá dữ liệu trong việc phân tích sở thích mua bán của khách hàng…
+ Tài chính và thị trường chứng khoán: Áp dụng vào việc phân tích các thẻ tín dụng tiêu biểu của các khách hàng, phân đoạn tài khoản nhận được, phân tích đầu tư tài chính như chứng khoán, giấy chứng nhận, và các quỹ tình thương, đánh giá tài chính, và phát hiện kẻ gian, .... Dự báo giá của các loại cổ phiếu trong thị trường chứng khoán, ...
+ Bảo hiểm: Áp dụng vào việc phân tích mức độ rủi ro xảy ra đối với từng loại hàng hoá, dịch vụ hay chiến lược tìm kiếm khách hàng mua bảo hiểm, ...
+ Quá trình sản xuất: Các ứng dụng giải quyết sự tối ưu của các nguồn tài nguyên như các máy móc, nhân sự, và nguyên vật liệu; thiết kế tối ưu trong quá trình sản xuất, bố trí phân xưởng và thiết kế sản phẩm, chẳng hạn như quá trình tự động dựa vào yêu cầu khách hàng...
1.3. Một số phương pháp khai phá dữ liệu thông dụng
Nhiệm vụ chính của khai phá dữ liệu là mô tả và dự đoán. Trong đó mô tả nhằm biểu thị các đặc điểm chung của dữ liệu có trong CSDL, còn dự đoán nhằm thực hiện, suy luận trên dữ liệu hiện có để đưa ra các kết luận của dự đoán đó. Dưới đây giới thiệu 3 phương pháp thông dụng nhất là: phân cụm dữ liệu, phân lớp dữ liệu và luật kết hợp.
1.3.1. Phân lớp (Classification)
Mục tiêu của phương pháp phân lớp dữ liệu là dự đoán nhãn lớp cho các mẫu dữ liệu. Quá trình phân lớp dữ liệu thường gồm 2 bước:
Bước 1: Xây dựng mô hình
Trong bước này, một mô hình sẽ được xây dựng dựa trên việc phân tích các mẫu dữ liệu sẵn có. Đầu vào của quá trình này là một tập dữ liệu có cấu trúc
được mô tả bằng các thuộc tính và được tạo ra từ tập các bộ giá trị của các thuộc tính đó. Mỗi bộ giá trị được gọi chung là một mẫu (sample). Trong tập dữ liệu này, mỗi mẫu được giả sử thuộc về một lớp định trước, lớp ở đây là giá trị của một thuộc tính được chọn làm thuộc tính gán nhãn lớp hay thuộc tính quyết định. Đầu ra của bước này thường là các quy tắc phân lớp dưới dạng luật dạng if-then, cây quyết định, công thức logic, hay mạng nơron. Quá trình này được mô tả như trong hình 1
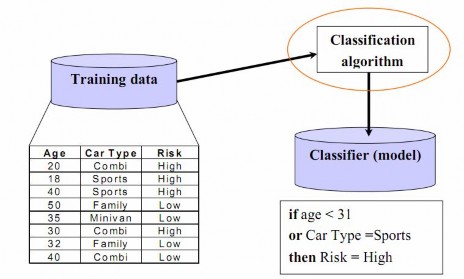
Hình 1. Quá trình phân lớp dữ liệu – Bước xây dựng mô hình
Bước 2: Sử dụng mô hình đã xây dựng để phân lớp dữ liệu
Trong bước này việc đầu tiên là phải làm là tính độ chính xác của mô hình. Nếu độ chính xác là chấp nhận được mô hình sẽ được sử dụng để dự đoán nhãn lớp cho các mẫu dữ liệu khác trong tương lai.
Độ chính xác mang tính chất dự đoán của mô hình phân lớp vừa tạo ra được ước lượng. Holdout là một kỹ thuật đơn giản để ước lượng độ chính xác đó. Kỹ thuật này sử dụng một tập dữ liệu kiểm tra với các mẫu đã được gán nhãn lớp. Các mẫu này được chọn ngẫu nhiên và độc lập với các mẫu trong tập dữ liệu đào tạo. Độ chính xác của mô hình trên tập dữ liệu kiểm tra đã đưa là tỉ lệ phần trăm các các mẫu trong tập dữ liệu kiểm tra được mô hình phân lớp đúng (so với thực tế).
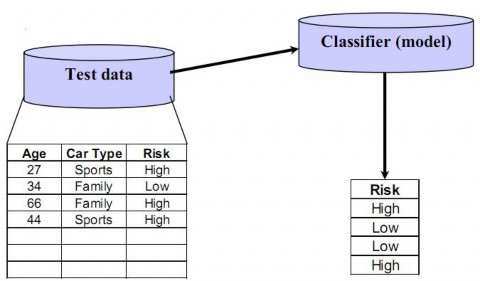
Hình 2. Quá trình phân lớp dữ liệu – Ước lượng độ chính xác mô hình
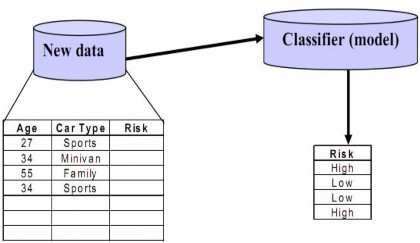
Hình 3. Quá trình phân lớp dữ liệu –Phân lớp dữ liệu mới
1.3.2. Phân cụm (Clustering)
Mục tiêu chính phân cụm dữ liệu là nhóm các đối tượng tương tự nhau trong tập dữ liệu vào các cụm sao cho các đối tượng thuộc cùng một lớp là tương đồng còn các đối tượng thuộc các cụm khác nhau sẽ không tương đồng.
Phân cụm dữ liệu là một ví dụ của phương pháp học không giám sát. Trong phương pháp này ta sẽ không thể biết kết quả các cụm thu được sẽ như thế nào khi bắt đầu quá trình. Vì vậy, cần có một chuyên gia về lĩnh vực đó để đánh giá các cụm thu được.
Phân cụm dữ liệu được sử dụng nhiều trong các ứng dụng về phân loại thị trường, phân loại khách hàng, nhận dạng mẫu, phân loại trang web,… Ngoài ra