88
3.3.3 Kết quả phân tích nhân tố khám phá
Tiến hành phân tích nhân tố khám phá EFA ta thu được kết quả theo bảng
sau:
Bảng 3.15 KMO and Bartlett’s Test
Hệ số KMO (Kaiser-Meyer-Olkin) | 0,825 | |
Mô hình kiểm tra của Bartlett’s | Giá trị Chi-Square | 3286,628 |
Bậc tự do | 496 | |
Sig (giá trị P – Value) | 0,000 | |
Có thể bạn quan tâm!
-

 Sẽ Giới Thiệu Về Quy Trình Nghiên Cứu, Phương Pháp Nghiên Cứu, Đồng Thời Cũng Giới Thiệu Về Cách Xây Dựng Thang Đo, Phương Pháp Đánh Giá Thang Đo,
Sẽ Giới Thiệu Về Quy Trình Nghiên Cứu, Phương Pháp Nghiên Cứu, Đồng Thời Cũng Giới Thiệu Về Cách Xây Dựng Thang Đo, Phương Pháp Đánh Giá Thang Đo, -
 Mối quan hệ giữa định hướng thị trường, định hướng học hỏi với kết quả kinh doanh của các doanh nghiệp khách sạn – nhà hàng Trường hợp nghiên cứu tại thành phố Hồ Chí Minh - 12
Mối quan hệ giữa định hướng thị trường, định hướng học hỏi với kết quả kinh doanh của các doanh nghiệp khách sạn – nhà hàng Trường hợp nghiên cứu tại thành phố Hồ Chí Minh - 12 -
 Kết Quả Kiểm Định Cronbach’S Alpha
Kết Quả Kiểm Định Cronbach’S Alpha -
 Tổng Quan Về Ngành Khách Sạn – Nhà Hàng
Tổng Quan Về Ngành Khách Sạn – Nhà Hàng -
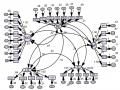 Mô Hình Không Xem Xét Vai Trò Của Biến Điều Tiết
Mô Hình Không Xem Xét Vai Trò Của Biến Điều Tiết -
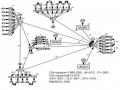 Kiểm Định Về Kqkd Đối Với Quy Mô Lao Động Của Doanh Nghiệp
Kiểm Định Về Kqkd Đối Với Quy Mô Lao Động Của Doanh Nghiệp
Xem toàn bộ 296 trang tài liệu này.

(Nguồn: Kết quả khảo sát, 2019) Bảng KMO và kiểm định Bartlett’s có giá trị KMO = 0,825 ≤ 1 nên tập dữ liệu nghiên cứu được chấp nhận. Giá trị Sig của Bartlett’s Test = 0,000 < 0,05 nên phân
tích nhân tố EFA là phù hợp.
Bảng 3.16 Ma trận xoay
Nhân tố | |||||
1 | 2 | 3 | 4 | 5 | |
MO8 | 0,872 | ||||
MO3 | 0,851 | ||||
MO4 | 0,812 | ||||
MO7 | 0,759 | ||||
MO9 | 0,723 | ||||
MO5 | 0,658 | ||||
MO1 | 0,564 | ||||
MO2 | 0,558 | ||||
MO6 | 0,552 | ||||
BE1 | 0,922 | ||||
BE6 | 0,843 | ||||
BE7 | 0,821 | ||||
BE3 | 0,738 | ||||
BE2 | 0,714 | ||||
BE4 | 0,655 | ||||
BE5 | 0,563 | ||||
BP1 | 0,965 | ||||
BP4 | 0,835 | ||||
BP5 | 0,769 |
89
0,678 | |||
BP2 | 0,659 | ||
BP3 | 0,650 | ||
IN5 | 0,984 | ||
IN2 | 0,975 | ||
IN4 | 0,676 | ||
IN3 | 0,676 | ||
IN1 | 0,616 | ||
LO4 | 0,897 | ||
LO5 | 0,792 | ||
LO1 | 0,727 | ||
LO3 | 0,681 | ||
LO2 | 0,625 |
(Nguồn: Kết quả khảo sát, 2019)
3.4 Nghiên cứu định lượng chính thức
3.4.1 Thiết kế bảng câu hỏi cho nghiên cứu chính thức
Sau quá trình khảo sát định lượng sơ bộ, tác giả đưa ra thang đo chính thức. Sau khi đưa ra thang đo chính thức tác giả hoàn thiện bảng câu hỏi chính thức để tiến hành khảo sát chính thức chuẩn bị cho giai đoạn nghiên cứu định lượng chính thức. Nội dung bảng câu hỏi gồm 2 phần chính. Phần 1 gồm những câu hỏi giữa các thành phần và KQKD của doanh nghiệp. Phần 2 gồm những câu hỏi nhằm thu thập thông tin doanh nghiệp về: giới tính, quy mô của doanh nghiệp, loại hình của doanh nghiệp, trình độ học vấn và thời gian làm việc.
3.4.2 Thiết kế mẫu nghiên cứu chính thức
Theo Nguyễn Đình Thọ (2013), kích thước mẫu cũng là một vấn đề được các nhà nghiên cứu quan tâm vì nó liên quan trực tiếp đến độ tin cậy của các tham số thống kê. Mỗi phương pháp phân tích thống kê đòi hỏi kích thước mẫu khác nhau và hiện nay để tính kích thước mẫu cho từng phương pháp phân tích thống kê, nhà nghiên cứu thường dựa vào các công thức kinh nghiệm.
Nghiên cứu chính thức là một nghiên cứu định lượng nhằm đánh giá độ tin cậy của thang đo, kiểm định mô hình nghiên cứu và các giả thuyết nghiên cứu. Nghiên cứu này được thực hiện tại các doanh nghiệp MTKD trên địa bàn TP. Hồ
90
Chí Minh. Đây là các doanh nghiệp điển hình đã hoạt động và có đóng góp cho cộng đồng đáp ứng nhu cầu của khách du lịch về chỗ nghỉ ngơi và ăn uống. Đây cũng chính là lĩnh vực đang phát triển và thu hút được sự quan tâm của xã hội hiện nay. Đối tượng khảo sát là lãnh đạo các doanh nghiệp KS-NH (Tổng giám đốc/Phó tổng giám đốc, Giám đốc các bộ phận như marketing, kinh doanh, nhân sự, chăm sóc và hỗ trợ khách hàng) trên địa bàn TP. Hồ Chí Minh.
Luận án chọn phương pháp phân tích dữ liệu theo SEM nên đòi hỏi cỡ mẫu lớn vì nó dựa vào lý thuyết phân phối mẫu lớn. Theo Tabachnick và Fidell (2001) kinh nghiệm cho thấy: “kích thước mẫu 300 là tốt, 500 là rất tốt và 1.000 là tuyệt vời”. Vì vậy, kích thước mẫu của luận án này trong khoảng từ 500 – 600.
Phương pháp chọn mẫu: từ tổng thể chung gồm 520 doanh nghiệp KS-NH trên địa bàn TP. Hồ Chí Minh (nguồn: Cục thống kê TP. Hồ Chí Minh). Căn cứ vào mục tiêu nghiên cứu, để có thể khái quát hóa được kết quả nghiên cứu, nên mẫu nghiên cứu chính thức bằng kỹ thuật lấy mẫu phi xác suất bằng cách chọn mẫu chỉ định, và với độ tin cậy 95%, sai số tiêu chuẩn 5% cỡ mẫu tối thiểu được ước tính theo Yamane (1967):
n = N/ (1 + N* 0.052)
Trong đó: n là cỡ mẫu; N là số lượng tổng thể; 5% là sai số chuẩn
Số lượng Tổng giám đốc/Phó tổng giám đốc, Giám đốc bộ phận của 520 doanh nghiệp KS-NH là 1560 quan sát. Như vậy, theo Yamane (1967) với giá trị Chi bình phương tương ứng với độ tin cậy 95%, sai số tiêu chuẩn 5% thì cỡ mẫu tối thiểu là:
n = 1560/ (1 + 1560* 0.052) = 318
Như vậy, mẫu tối thiểu của cần đạt là 318. Lập luận bù đắp một tỷ lệ các bảng câu hỏi bị loại bỏ do không đạt yêu cầu và những khó khăn trong quá trình điều tra và để đạt được kích thước mẫu như trên, tác giả sẽ tăng 80% của kích thước mẫu tối tiểu:
n = 318*(1 + 80%) = 572 phiếu
91
Kết quả thu về được 515 phiếu, trong đó 12 phiếu không hợp nên kích thước mẫu nghiên cứu chính thức hợp lệ là 503 quan sát > mẫu tối thiểu là 318 nên chấp nhận được. Cuộc khảo sát được thực hiện từ tháng 9 năm 2019 đến tháng 12 năm 2019.
Bảng 3.18 Số lượng doanh nghiệp khảo sát
Số DN | Số lượng BLĐ | Tỷ lệ (%) | Số lượng khảo sát | |
Quận 1 | 200 | 553 | 35 | 113 |
Quận 2 | 11 | 38 | 2 | 8 |
Quận 3 | 60 | 185 | 12 | 38 |
Quận 4 | 7 | 20 | 1 | 4 |
Quận 5 | 26 | 83 | 5 | 17 |
Quận 6 | 4 | 13 | 1 | 3 |
Quận 7 | 49 | 152 | 10 | 31 |
Quận 8 | 6 | 20 | 1 | 4 |
Quận 9 | 3 | 8 | 1 | 2 |
Quận 10 | 26 | 83 | 5 | 17 |
Quận 11 | 5 | 17 | 1 | 3 |
Quận 12 | 8 | 29 | 2 | 6 |
Gò vấp | 14 | 47 | 3 | 10 |
Phú nhuận | 10 | 35 | 2 | 7 |
Tân bình | 63 | 194 | 12 | 40 |
Tân phú | 7 | 24 | 2 | 5 |
Thủ đức | 4 | 12 | 1 | 2 |
Bình Thạnh | 12 | 35 | 2 | 7 |
Bình Tân | 3 | 7 | 0,4 | 1 |
Bình Chánh | 2 | 5 | 0,3 | 1 |
Tổng | 520 | 1560 | 100 | 318 |
(Nguồn: Kết quả xử lý của tác giả, 2019)
Bảng 3.18 cho thấy tổng thể ban giám đốc của 520 doanh nghiệp KS-NH là 1560. Luận án sử dụng phương pháp chọn mẫu chủ định và thuận tiện để xác định số lượng các giám đốc tại các quận trên địa bàn TP. Hồ Chí Minh. Chẳng hạn, Quận 1, luận án khảo sát 113 là ban giám đốc của KS-NH. Tương tự cho các quận còn lại trên địa bàn TP. Hồ Chí Minh theo phương pháp chọn mẫu chủ định.
3.4.3 Thu thập thông tin mẫu nghiên cứu
Mẫu nghiên cứu được thu thập bằng phương pháp phỏng vấn lãnh đạo bằng bảng câu hỏi, bảng câu hỏi được gửi trực tiếp đến ban giám đốc của doanh nghiệp
92
KS-NH. Ngoài ra, do không thuận tiện, một số bảng câu hỏi được khảo sát bằng hình thức online qua google form.
Kết quả sau khi kiểm tra, tác giả loại bỏ các bảng hỏi không đạt yêu cầu (thiếu thông tin, đánh giá cùng 1 mức độ hoặc không đáng tin cậy) và được xử lý bằng phần mềm SPSS 22.0, AMOS để tiến hành thống kê, phân tích dữ liệu.
3.4.4 Phương pháp phân tích dữ liệu
3.4.4.1 Kiểm định độ tin cậy của thang đo
Để đánh giá độ tin cậy của thang đo chúng ta sử dụng kiểm định Cronbach’s Alpha. Theo Nguyễn Đình Thọ (2011) cho rằng: “hệ số Cronbach’s alpha có giá trị biến thiên trong đoạn [0,1]. Về lý thuyết, hệ số này càng cao càng tốt (thang đo càng có độ tin cậy cao). Tuy nhiên, điều này không hoàn toàn chính xác. Hệ số Cronbach’s alpha quá lớn (khoảng từ 0,95 trở lên) cho thấy có nhiều biến trong thang đo không có khác biệt gì nhau, hiện tượng này gọi là trùng lắp trong thang đo. Nếu một biến đo lường có hệ số tương quan biến tổng ≥ 0,3 thì biến đó đạt yêu cầu”.
Theo Hoàng Trọng và Chu Nguyễn Mộng Ngọc (2011) cho rằng: “hệ số Cronbach’s Alpha từ 0,8 đến gần 1 thì thang đo lường tốt, từ 0,7 đến 0,8 là có thể sử dụng được. Hệ số Cronbach’s Alpha từ 0,6 trở lên là thang đo đủ điều kiện. Thang đo có thể sử dụng được phải có hệ số tương quan biến tổng từ 0,3 trở lên (Hair và cộng sự, 2010)”.
3.4.4.2 Phân tích nhân tố khám phá EFA
Theo Hoàng Trọng và Chu Nguyễn Mộng Ngọc (2008) cho rằng hệ số KMO là một chỉ số dùng để xem xét sự thích hợp của phân tích nhân tố. Trị số KMO phải nằm trong khoảng (0,5 ≤ KMO ≤ 1) thì thích hợp. Theo Nguyễn Đình Thọ (2011): “Kiểm định Bartlett để xem xét các biến quan sát trong nhân tố có tương quan với nhau hay không. Kiểm định Bartlett có ý nghĩa thống kê (sig Bartlett‘s test < 0,05), chứng tỏ các biến quan sát có tương quan với nhau trong nhân tố. Phương sai trích hệ số sử dụng (principal axis components) với phép quay vuông góc (Promax) và
93
điểm dừng khi trích các yếu tố (Eigenvalue) ≥ 1. Thang đo được chấp nhận khi tổng phương sai trích ≥ 50%”.
Bên cạnh, theo Nguyễn Đình Thọ (2013), kiểm định Bartlett để xem xét các biến quan sát trong nhân tố có tương quan với nhau hay không đòi hỏi các biến quan sát trong cùng một nhân tố phải có mối tương quan với nhau. Do đó, giá trị hội tụ trong phân tích EFA, kiểm định Bartlett có giá trị Sig Bartlett’s Test < 0,05), cho thấy các biến quan sát có tương quan với nhau.
Theo Hair và cộng sự (2011) thì trọng số nhân tố của biến Xi trên nhân tố mà nó là một biến đo lường sau khi quay phải cao và các trọng số trên các nhân tố khác nó không đo lường phải thấp. Đạt được điều kiện này, thang đo đạt giá trị hội tụ.
- Trọng số nhân tố ≥ 0,35: Điều kiện tối thiểu để biến quan sát được giữ lại (với kích thước mẫu > 250).
- Trọng số nhân tố ≥ 0,4: Biến quan sát có giá trị hội tụ tốt (với số mẫu >
200).
120).
- Trọng số nhân tố ≥ 0,5: Biến quan sát có giá trị hội tụ tốt (với số mẫu > Với tiêu chí chấp nhận: trọng số nhân tố ≥ 0,4 (với kích thước mẫu tối thiểu
200) để đảm bảo ý nghĩa thiết thực của phân tích khám phá nhân tố. Trong trường hợp cỡ mẫu trên 300, hệ số tải > 0,5 sẽ cho thấy các biến quan sát của nhân tố đó đạt yêu cầu về giá trị hội tụ (Nguyễn Đình Thọ, 2014).
3.4.4.3 Phân tích nhân tố khẳng định (CFA)
Theo Hair và cộng sự (2010) cho thấy: “Khi phân tích CFA để đo lường mức độ phù hợp của mô hình với thông tin thị trường, người ta thường sử dụng Chi- square điều chỉnh theo bậc tự do (CMIN/df); Chỉ số thích hợp so sánh (CFI_ Comparative Fit Index); Chỉ số Tucker & Lewis (TLI_ Tucker & Lewis Index); Chỉ số RMSEA (Root Mean Square Error Approximation); chỉ số GFI”. Khi kiểm định Chi- square có P-value < 0,05; các giá trị GFI, TLI, CFI ≥ 0,9; hoặc > 0,8; CMIN/df ≤ 3, RMSEA ≤ 0,08 thì mô hình được xem là phù hợp với dữ liệu, hay tương thích với dữ
94
liệu, nếu các chỉ số đạt giá trị thấp hơn lân cận thì mô hình vẫn có thể tương thích với dữ liệu.
Trong luận án này, để đánh giá mức độ phù hợp của dữ liệu thì: TLI, CFI ≥ 0,9, GFI hoặc > 0,8; CMIN/df ≤ 3, RMSEA ≤ 0,08.
Phân tích nhân tố khẳng định (Confirmatory Factor Analysis – CFA) cho thấy các biến quan sát đại diện cho các nhân tố tốt đến mức nào. Phương pháp CFA được sử dụng để khẳng định lại tính đơn hướng, tin cậy, giá trị hội tụ và phân biệt của bộ thang đo cho các khái niệm nghiên cứu có liên quan được đề cập trong luận án:
Độ tin cậy của thang đo: Độ tin cậy thang đo là một trong những giá trị của thang đo cần kiểm định chắc hơn. Độ tin cậy thông qua phân tích CFA được đo lường bằng các chỉ số độ tin cậy tổng hợp (CR), tổng phương sai rút trích (AVE) và hệ số Cronbach’s Alpha.
Tính đơn hướng: Việc xác định tính đơn nguyên đơn hướng của thang đo dựa vào các giá trị đánh giá mức độ phù hợp của mô hình để ta có thể kết luận rằng thang đo đạt được tính đơn nguyên, đơn hướng.
Giá trị hội tụ: Theo Hair và cộng sự (1995) cho rằng: “Thang đo được xem là đạt giá trị hội tụ khi các trọng số chuẩn hóa của các thang đo trong phân tích CFA lớn hơn 0,5 và có ý nghĩa thống kê. Ngoài ra, còn một tiêu chí khác để kiểm tra giá trị hội tụ đó là tổng phương sai rút trích (AVE) của các khái niệm tối thiểu > 0.5”.
Giá trị phân biệt: Giá trị phân biệt được đánh giá hệ số tương quan giữa các nhân tố có khác 1 và giá trị kiểm định P-value.
3.4.4.4 Phân tích mô hình cấu trúc tuyến tính (SEM)
SEM được dùng để mô tả mối quan hệ giữa các biến quan sát được với mục tiêu cơ bản là kiểm định các giả thuyết thống kê. Cụ thể hơn, SEM có thể được sử dụng để kiểm định mối quan hệ giữa các khái niệm, SEM được dung để kiểm định các mô hình lý thuyết bằng cách sử dụng các phương pháp khoa học về kiểm định giả thuyết để mở rộng tầm hiểu biết của chúng ta về mối quan hệ giữa các khái niệm.
95
Theo Hair và cộng sự (2010) khi phân tích SEM về đánh giá mức độ phù hợp của mô hình cũng được xem xét giống như khi phân tích CFA, các chỉ số đánh giá như CMIN/df (<3 hoặc < 4), chỉ số TLI, CFI >=0,9 (lân cận 0,9), chỉ số GFI >=0,8, hệ số RMSEA < 0.08 thì mô hình được xem là thích hợp với dữ liệu nghiên cứu.
Phương pháp phân tích cấu trúc tuyến tính SEM cho thấy được ưu điểm hơn phương pháp hồi quy tuyến tính bội vì giải quyết được mô hình ước lượng đồng thời, các mối quan hệ phức tạp sẽ được thể hiện một cách dễ dàng, chúng ta không phải thực hiện hồi quy từng phần sau đó mới tính mức độ phù hợp mô hình tổng thể.
3.4.4.5 Kiểm định Bootstrap
Để đánh giá độ tin cậy của các hệ số ước lượng ban đầu thay vì chia mẫu ra hoặc lặp lại nghiên cứu. Tuy nhiên, trên thực thực tế hai cách trên thường không thực tế vì đòi hỏi mẫu lớn và tốn kém nhiều thời gian và chi phí (Anderson & Gerbing, 1988). Phương pháp Bootstrap là phương pháp lấy mẫu lặp lại, thay thế với mẫu ban đầu giữ vai trò là đám đông.
3.4.4.6 Kiểm định sự khác biệt giữa các nhóm
- Kiểm định sự khác biệt:
Independent Samples Test được dùng để kiểm tra sự khác biệt trung bình giữa hai nhóm: Nếu sig Levene's Test nhỏ hơn 0,05 thì phương sai giữa 2 nhóm là khác nhau và có sự khác biệt giữa hai nhóm và ngược lại. Nếu sig Levene's Test lớn hơn 0,05 thì phương sai giữa 2 nhóm là không khác nhau và không có sự khác biệt có ý nghĩa thống kê giữa hai nhóm.
- Kiểm định Anova
Phân tích ANOVA để kiểm định sự khác biệt giữa nhiều nhóm. Giá trị Test of Homogeneity of Variances có giá trị Sig. < 0,05 thì phương sai đánh giá nhân khẩu học khác nhau có ý nghĩa thống kê. Khi đó phân tích phương sai ANOVA dừng. Ngược lại, nếu giá trị Sig > 0,05 thì phương sai đánh giá nhân khẩu học không khác nhau một cách có ý nghĩa thống kê. Khi đó, kết quả phân tích ANOVA có thể sử dụng được. Sau đó, tiến hành phân tích dựa vào kết quả ở bảng ANOVA,