này sử dụng mẫu điều tra, trong đó đảm bảo nguyên tắc mẫu tối thiểu để nghiên cứu có tính tin cậy và đại diện được cho tổng thể. Đây là đề tài nghiên cứu dạng khám phá cùng với những nội dung phân tích ở trên, tác giả sử dụng phương pháp chọn mẫu ngẫu nhiên phân tầng và có lồng ghép phương pháp chọn mẫu giản đơn và thuận tiện. Tác giả soạn bảng câu hỏi nghiên cứu sẽ được gửi trực tiếp cho từng khách hàng đang sử dụng dịch vụ của các ngân hàng thương mại trên 5 thành phố lớn của Việt Nam (Cụ thể là các ngân hàng thương mại đang hoạt động trên 5 thành phố lớn bao gồm thành phố Cần Thơ, Hồ Chí Minh, Đà Nẵng, Hải Phòng và Hà Nội) nên rất thuận tiện cho việc khảo sát của tác giả. Có nghĩa là lấy mẫu dựa trên sự thuận lợi hay dựa trên tính dễ tiếp cận của đối tượng, ở những nơi mà tác giả điều tra có nhiều khả năng gặp được đối tượng.
3.3.2 Thu thập dữ liệu
3.3.2.1 Dữ liệu sơ cấp
Trong bài luận án này, tác giả thu thập dữ liệu sơ cấp sau khi xác định xong cỡ mẫu và cách lấy mẫu. Tác giả đã sử dụng bảng câu hỏi chính thức để tiến hành gửi đến từng khách hàng đang sử dụng dịch vụ (không phân biệt loại hình dịch vụ) của các ngân hàng thương mại trên 5 thành phố lớn của Việt Nam. Tác giả khảo sát 1,000 khách hàng đang sử dụng dịch vụ của các ngân hàng thương mại trên 5 thành phố lớn của Việt Nam thông qua phiếu hỏi gửi đến từng khách hàng. Mỗi thành phố tác giả khảo sát 200 khách hàng đại diện cho 10 ngân hàng thương mại lớn như: Vietcombank, ACB, Agribank, Vietinbank, Techcombank, TPBank, VPBank, MB, BIDV và HDB. Tác giả hướng dẫn trả lời và thu nhận phiếu trả lời sau khi đã hoàn thành phiếu trả lời, kiểm tra độ chính xác, làm sạch dữ liệu và bỏ những phiếu không hợp lệ. Thời gian tiến hành khảo sát từ 10/2020 đến 02/2021.
3.3.2.1 Dữ liệu thứ cấp
Trong bài luận án này, tác giả thu thập dữ liệu thứ cấp thông qua tài liệu thu thập tại phòng hành chính nhân sự, các báo cáo tổng kết hàng năm và số liệu từ các phòng liên quan các ngân hàng thương mại trong ba năm từ 2018 - 2020. Ngoài ra, tác giả thu thập số liệu thứ cấp trên các trang web của các ngân hàng thương mại.
3.3.3 Phương pháp xử lý số liệu
3.3.3.1 Thống kê mô tả
Trong luận án, tác giả sử dụng thống kê mô tả để mô tả những đặc tính cơ bản của dữ liệu thu thập được từ kết quả khảo sát 1,000 khách hàng đang sử dụng dịch vụ của các ngân hàng thương mại trên 5 thành phố lớn của Việt Nam. Thống kê mô tả thể hiện việc dùng đồ
Có thể bạn quan tâm!
-

 Bảng Thể Hiện Kết Quả Thảo Luận 30 Nhà Quản Lý
Bảng Thể Hiện Kết Quả Thảo Luận 30 Nhà Quản Lý -
 Kết Quả Kiểm Định Thang Đo Thông Qua Định Lượng Sơ Bộ
Kết Quả Kiểm Định Thang Đo Thông Qua Định Lượng Sơ Bộ -
 Kết Quả Kiểm Định Thang Đo Phương Tiện Hữu Hình (Tan)
Kết Quả Kiểm Định Thang Đo Phương Tiện Hữu Hình (Tan) -
 Kết Quả Roa Và Roe Của Nhtm Việt Nam Giai Đoạn 2018-2020
Kết Quả Roa Và Roe Của Nhtm Việt Nam Giai Đoạn 2018-2020 -
 Kiểm Định Độ Tin Cậy Thang Đo Bằng Hệ Số Cronbach’S Alpha Cho Biến Độc Lập
Kiểm Định Độ Tin Cậy Thang Đo Bằng Hệ Số Cronbach’S Alpha Cho Biến Độc Lập -
 Phân Tích Nhân Tố Khám Phá Của Yếu Tố Khủng Hoảng
Phân Tích Nhân Tố Khám Phá Của Yếu Tố Khủng Hoảng
Xem toàn bộ 283 trang tài liệu này.
thị mô tả dữ liệu. Để hiểu được các hiện tượng và ra quyết định đúng đắn, các phương pháp cơ bản của mô tả dữ liệu thông qua bảng tần số, suất tuất, tần số tích lũy và tần suất tích lũy. Ngoài ra, trong luận án cũng sử dụng thống kê mô tả các giá trị trung bình, độ lệch chuẩn, phương sai, sai số chuẩn theo Hoàng Trọng và cộng sự (2008).
3.3.3.2 Kiểm định độ tin cậy Cronbach’s Alpha
Trong bài luận án này, tác giả sử dụng hệ số Cronbach’s Alpha để đánh giá độ tin cậy thang đo của dữ liệu khảo sát. Trong phần này các thang đo sẽ được đánh giá độ tin cậy thông qua hệ số tin cậy Cronbach’s Alpha bằng phần mềm SPSS 20.0. Mục đích nhằm tìm ra những mục câu hỏi cần giữ lại và những mục câu hỏi bị loại bỏ trong các mục đưa vào kiểm tra theo Hoàng Trọng và cộng sự (2008) hay nói cách khác là giúp loại đi những câu hỏi, những thang đo không đạt. Các câu hỏi có hệ số tương quan biến tổng (Corrected Item - Total Correlation) nhỏ hơn 0,3 sẽ bị loại và tiêu chuẩn chọn thang đo khi hệ số Cronbach’s Alpha từ 0,6 trở lên.
Nhiều nhà nghiên cứu đồng ý rằng khi hệ số Cronbach’s Alpha từ 0,8 trở lên đến gần 1 thì thang đo lường tốt, từ 0,7 đến gần 0,8 là sử dụng được. Cũng có nhà nghiên cứu đề nghị rằng Cronbach’s Alpha từ 0,6 trở lên là có thể sử dụng được trong trường hợp khái niệm đang đo lường là mới hoặc mới đối với người trả lời trong bối cảnh nghiên cứu và tối thiểu của hệ số Cronbach’s Alpha là 0,5.
3.3.3.3 Phân tích nhân tố khám phá (EFA)
Trong bài luận án này, tác giả sử dụng phân tích nhân tố khám phá chủ yếu để đánh giá giá trị hội tụ và giá trị phân biệt. Trong phân tích nhân tố khám phá các nhà nghiên cứu thường quan tâm đến một số tiêu chuẩn như sau: Một là, chỉ số KMO (Kaiser - Meyer - Olkin measure of sampling adequancy): Là một chỉ số được dùng để xem xét sự thích hợp của phân tích nhân tố. Trị số của KMO lớn (nằm giữa khoảng 0,5 và 1) là điều kiện đủ để phân tích nhân tố là thích hợp. Nếu chỉ số KMO nhỏ hơn 0.5 thì phân tích nhân tố có khả năng không thích hợp với các dữ liệu. Hai là, đại lượng Bartlett’s (Bartlett’s test of sphericity) là đại lượng xem xét giả thuyết về độ tương quan giữa các câu hỏi bằng không trong tổng thể. Nếu kiểm định này có ý nghĩa (Sig < 0,05) thì các câu hỏi có tương quan với nhau trong tổng thể. Ba là, hệ số nhân tố tải (factor loading): là những hệ số tương quan đơn giữa các biến và các nhân tố, hệ số này lớn hơn 0,5. Bốn là, thang đo được chấp nhận khi tổng phương sai trích lớn hơn 50%. Phương pháp trích “Principal Component Analysis” với phép quay “Varimax” hoặc phép quay promax được sử dụng trong phân tích nhân tố thang
đo các thành phần độc lập. Năm là, hệ số eigenvalue: Là đại diện cho phần biến thiên được giải thích bởi mỗi nhân tố. Chỉ số này phải lớn hơn 1 theo Hoàng Trọng và cộng sự (2008).
Cuối cùng, phần trăm phương sai toàn bộ được giải thích bởi từng nhân tố (Percentage of variance) nghĩa là coi biến thiên là 100% thì giá trị này cho biết phân tích nhân tố cô đọng được bao nhiêu % và bị thất thoát bao nhiêu %. Chỉ tiêu này càng tiến tới 100 % càng tốt theo Hoàng Trọng và cộng sự (2008). Như vậy, sau khi đánh giá hệ số tin cậy Cronbach’s Alpha và phân tích nhân tố khám phá (EFA) tác giả tiếp tục kiểm định sự phù hợp của mô hình theo Hair và cộng sự (2010).
3.3.3.4 Phân tích nhân tố khẳng định (CFA)
Phân tích nhân tố khẳng định (CFA): sử dụng thích hợp khi nhà nghiên cứu có sẵn một số kiến thức về cấu trúc biến tiềm ẩn cơ sở. Trong đó mối quan hệ hay giả thuyết (có được từ lý thuyết hay thực nghiệm) giữa câu hỏi và nhân tố cơ sở thì được các nhà nghiên cứu mặc nhiên thừa nhận trước khi tiến hành kiểm định thống kê. Như vậy CFA là bước tiếp theo của EFA nhằm kiểm định xem có một mô hình lý thuyết có trước làm nền tảng cho một tập hợp các quan sát không. CFA cũng là một dạng của SEM. Khi xây dựng CFA, các câu hỏi cũng là các biến chỉ báo trong mô hình đo lường, bởi vì chúng cùng tải lên khái niệm lý thuyết cơ sở theo Hair và cộng sự (2010).
Phương pháp phân tích nhân tố khẳng định CFA chấp nhận các giả thuyết của các nhà nghiên cứu, được xác định căn cứ theo quan hệ giữa mỗi biến và một hay nhiều hơn một nhân tố. Sau đây là một mô hình SEM sử dụng kỹ thuật phân tích CFA theo Hoàng Trọng và cộng sự (2008). Phân tích nhân tố khẳng định (CFA) là mô hình hay gặp trong phân tích SEM (Structural Equation Model). CFA khác với phân tích nhân tố khám phá (Exploratory Factor Analysis: EFA) về phương pháp cũng như các giả định.
3.3.3.5 Phân tích mô hình cấu trúc tuyến tính (SEM)
Mô hình cấu trúc tuyến tính (SEM) được dùng để mô tả mối quan hệ giữa các câu hỏi được với mục tiêu cơ bản là kiểm định các giả thuyết thống kê. Cụ thể hơn, SEM có thể được sử dụng để kiểm định mối quan hệ giữa các khái niệm. Mô hình SEM phối hợp được tất cả các kỹ thuật như hồi quy đa biến, phân tích nhân tố và phân tích mối quan hệ hỗ tương giữa các phần tử trong sơ đồ mạng để cho phép chúng ta kiểm tra mối quan hệ phức hợp trong mô hình. Khác với những kỹ thuật thống kê khác chỉ cho phép ước lượng mối quan hệ riêng phần của từng cặp nhân tố trong mô hình cổ điển, SEM cho phép ước lượng đồng thời
các phần tử trong tổng thể mô hình, ước lượng mối quan hệ nhân quả giữa các khái niệm tiềm ẩn qua các chỉ số kết hợp cả đo lường và cấu trúc của mô hình lý thuyết.
Mục tiêu của phân tích SEM là để xác định mô hình lý thuyết nào được củng cố bởi bộ dữ liệu. Nếu mẫu khảo sát ủng hộ cho mô hình lý thuyết thì các mô hình lý thuyết phức tạp hơn sẽ được nghiên cứu trong các nghiên cứu sau đó. Ngược lại, mô hình ban đầu có thể được điều chỉnh và kiểm định lại. Tóm lại, SEM được dùng để kiểm định các mô hình lý thuyết bằng cách sử dụng các phương pháp khoa học về kiểm định giả thuyết theo Hair và cộng sự (2010).
Để đo lường mức độ phù hợp của mô hình với thông tin khảo sát, các nghiên cứu thường sử dụng các chỉ tiêu như chi bình phương, chi bình phương điều chỉnh theo bậc tự do (CMIN/df). Cũng dùng để đo mức độ phù hợp một cách chi tiết hơn của cả mô hình. Một số tác giả đề nghị 1 < χ2/df < 3 theo Hair và cộng sự (2010); một số khác đề nghị χ2 càng nhỏ càng tốt theo Hair và cộng sự (2010). và cho rằng χ2/df < 3:1 theo Hair và cộng sự (2010). Ngoài ra, trong một số nghiên cứu thực tế người ta phân biệt ra 2 trường hợp: χ2/df
< 5(với mẫu N > 200); hay < 3 (khi cỡ mẫu N < 200) thì mô hình được xem là phù hợp tốt theo Hair và cộng sự (2010).
GFI: đo độ phù hợp tuyệt đối (không điều chỉnh bậc tự do) của mô hình cấu trúc và mô hình đo lường với bộ dữ liệu khảo sát theo Hair và cộng sự (2010).
Chỉ số thích hợp so sánh CFI (Comparative Fit Index), chỉ số NFI (Normal Fit Index), RFI (Relative Fit Index), chỉ số IFI (Incremental Fix Index), chỉ số TLI (Tucker & Lewis Index) và chỉ số RMSEA (Root Mean Square Error Approximation). Một mô hình được gọi là thích hợp khi phép kiểm định chi bình phương có giá trị p-value lớn hơn 5% (hay p < 0.05). Trong tạp chí nghiên cứu IS, các tác giả cho rằng chỉ số RMSEA, RMR yêu cầu < 0.05 thì mô hình phù hợp tốt. Trong một số trường hợp giá trị này < 0.08 mô hình được chấp nhận theo Hair và cộng sự (2010).
Tuy nhiên, Chi bình phương có nhược điểm là nó phụ thuộc vào kích thước mẫu, bởi Chi bình phương = (n-1)*FML. Khi cỡ mẫu, n, càng lớn thì giá trị thống kê Chi bình phương càng lớn. Điều này sẽ làm giảm mức độ phù hợp của mô hình, nghĩa là làm tăng khả năng bác bỏ mô hình khi cở mẫu lớn. Vì vậy, một số chỉ tiêu tương thích khác sẽ được sử dụng để so sánh. Nếu giá trị NFI, RFI, IFI, TLI và CFI càng gần đến 1 thì mô hình càng phù hợp (tốt nhất đạt giá trị từ 0.9 đến 1). Tuy nhiên có một số trường hợp lớn hơn 0.85 tạm chấp nhận được. CMIN/df có giá trị nhỏ hơn 2 hoặc 3, RMSEA có giá trị nhỏ hơn 0.08 thì
mô hình có thể được xem là phù hợp (tương thích) với dữ liệu khảo sát theo Hair và cộng sự (2010). Về phương pháp ước lượng, mô hình SEM sử dụng phương pháp ước lượng hợp lý cực đại ML (Maximum Likelihood). Phương pháp ML sẽ cho kết quả ước lượng phù hợp vì các câu hỏi không lệch nhiều so với phân phối chuẩn đa biến (Multivariate normality). Các tiêu chí về độ nhọn (Kurtosis) và độ trôi (Skewness) nằm trong khoảng [-1; +1] nên ước lượng ML vẫn là phương pháp thích hợp theo Hair và cộng sự (2010).
3.3.3.6 Kiểm định ANOVA
Trong bài luận án này, trước khi phân tích phương sai ANOVA, thực hiện kiểm định xem kết quả phân tích ANOVA có thể sử dụng được hay không. Dựa vào kết quả ở bảng Test of Homogeneity of Variances, nếu giá trị Sig. < 0,05 thì phương sai đánh giá chất lượng dịch vụ ngân hàng khác nhau một cách có ý nghĩa thống kê. Khi đó, bài toán phân tích phương sai ANOVA kết thúc. Ngược lại, nếu giá trị Sig. > = 0,05 thì phương sai đánh giá chất lượng dịch vụ ngân hàng không khác nhau một cách có ý nghĩa thống kê.
3.3.3.7 Kiểm định sự khác biệt giữa các nhóm
Phân tích Independent Samples Test và phương sai ANOVA (Analysis of variance) để so sánh sự khác biệt về chất lượng dịch vụ ngân hàng theo thông tin nhân khẩu học cá nhân. Phân tích Independent Samples Test dùng để kiểm tra sự khác biệt trung bình giữa hai nhóm: Nếu sig Levene's Test <= 0,05 thì phương sai giữa 2 nhóm là khác nhau, chúng ta sẽ sử dụng giá trị sig T-Test ở hàng Equal variances not assumed. Nếu sig Levene's Test > = 0,05 thì phương sai giữa 2 nhóm là không khác nhau, chúng ta sẽ sử dụng giá trị sig T-Test ở hàng equal variances assumed theo Hair và cộng sự (2010).
Tóm tắt chương 3
Chương 3, tác giả trình bày nghiên cứu sơ bộ và nghiên cứu chính thức. Nghiên cứu sơ bộ là tham khảo các nghiên cứu trong và ngoài nước trước đó có liên quan tới vấn đề nghiên cứu. Trong đó, tác giả nghiên cứu định lượng sơ bộ với dữ liệu 500 khách hàng đang sử dụng dịch vụ ngân hàng trên 5 thành phố lớn bao gồm thành phố Cần Thơ, Hồ Chí Minh, Đà Nẵng, Hải Phòng và Hà Nội. Kế đến, nghiên cứu chính thức được tiến hành thiết kế thang đo cho bảng câu hỏi nghiên cứu, diễn đạt và mã hoá lại thang đo, thu thập và phân tích dữ liệu của 1,000 khách hàng đang sử dụng dịch vụ của các ngân hàng thương mại trên 5 thành phố lớn của Việt Nam. Cuối cùng, xây dựng được quy trình thực hiện nghiên cứu, lý thuyết đánh giá thang đo, phân tích Cronbach’Alpha, phân tích nhân tố khám phá, phân tích nhân tố khẳng định, phân tích mô hình cấu trúc tuyến tính và phân tích phương sai.
CHƯƠNG 4. KẾT QUẢ NGHIÊN CỨU VÀ THẢO LUẬN
4.1 Phân tích thực trạng về hoạt động dịch vụ của các ngân hàng thương mại Việt Nam
4.1.1 Giới thiệu tổng quan về các ngân hàng thương mại Việt Nam
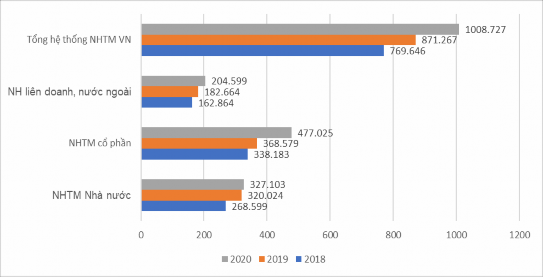
Năm 2019, tình hình quốc tế diễn biến phức tạp và có nhiều yếu tố không thuận lợi. Trong nước, thiên tai, biến đổi khí hậu, dịch bệnh ảnh hưởng đến sản xuất và đời sống nhân dân. Tuy nhiên, với phương châm hành động “Kỷ cương, liêm chính, hành động, sáng tạo”. Chính phủ đã quyết liệt chỉ đạo các bộ, ngành, địa phương triển khai đồng bộ, hiệu quả các nhiệm vụ, giải pháp đề ra. Trong đó, kiên định mục tiêu “ổn định kinh tế vĩ mô, kiểm soát lạm phát… tập trung cải thiện môi trường đầu tư, kinh doanh, thúc đẩy tăng trưởng kinh tế”. Nhờ đó, năm 2019 là năm thứ hai liên tiếp Việt Nam đạt và vượt toàn bộ 12 chỉ tiêu phát triển kinh tế - xã hội. Tăng trưởng kinh tế vượt mục tiêu đề ra, lạm phát được kiểm soát, các cân đối lớn của nền kinh tế được củng cố thông qua hệ thống ngân hàng. Giai đoạn 2018- 2020, theo số liệu báo cáo thường niên 2020 của NHNN thể hiện qua hình 4.1 sau:
(Nguồn: Báo cáo thường niên 2020 của NHNN)
Hình 4.1: Vốn tự có của hệ thống NHTM Việt Nam giai đoạn 2018-2020
Hình 4.1 cho thấy vốn tự có của hệ thống ngân hàng Việt Nam là hơn 871 nghìn tỉ. Trong đó, vốn tự có của các NHTM Nhà nước bất ngờ tăng mạnh gần 51.425 tỉ đồng lên
320.024 tỷ đồng (tương đương tăng 19,15%). Vốn tự có của khối ngân hàng Liên doanh nước ngoài cũng tăng 12,16%, lên 182.664 tỷ đồng. Vốn tự có của khối NHTMCP có sự tăng trưởng trong 2019 với mức tăng 8,99%. Bên cạnh đó, tổng tài sản có của khối NHTM
Việt Nam những năm qua luôn có sự tăng trưởng khá ổn định. Các NHTM vẫn đang nỗ lực nâng cao năng lực tài chính, đặc biệt là khối NHTMCP mức tăng trưởng tải sản có ổn định qua ba năm 2018-2020 như sau.
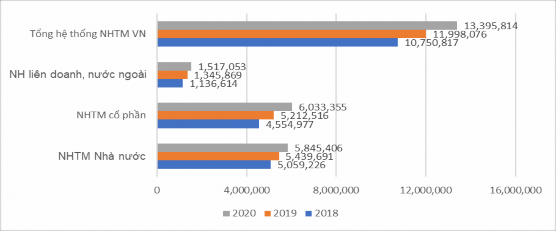
(Nguồn: Báo cáo thường niên 2020 của NHNN)
Hình 4.2: Tổng tài sản có của hệ thống NHTM Việt Nam giai đoạn 2018-2020
Hình 4.2 số liệu cho thấy, tổng tài sản có của khối NHTM Việt Nam những năm qua luôn có sự tăng trưởng khá ổn định. Các NHTM vẫn đang nỗ lực nâng cao năng lực tài chính, đặc biệt là khối NHTMCP mức tăng trưởng tải sản có ổn định qua các năm. Tổng tài sản có khối NHTMCP năm 2019 đã đạt mức 5.212.516 tỷ đồng, gần bằng với tài sản có của NHTMNN. Mặc dù có giá trị tài sản có thấp hơn nhiều so với NHTM trong nước nhưng NH liên doanh và NH nước ngoài lại có sự tăng trưởng cao nhất với tốc độ tăng lên tới 18-19%.
Bên cạnh đó, hệ số tỷ lệ giữa vốn tự có so với tổng tài sản của các NHTM Việt Nam được thể hiện hình 4.3 như sau:
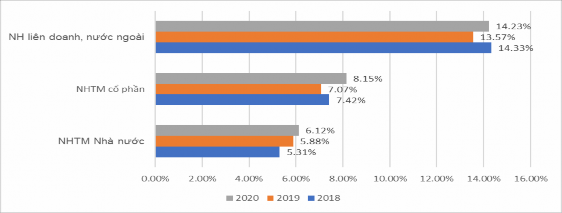
(Nguồn: Báo cáo thường niên 2020 của NHNN)
Hình 4.3: Tỷ lệ giữa vốn tự có so với tổng tài sản của hệ thống NHTM Việt Nam giai đoạn 2018-2020
Hình 4.3 số liệu trên cho thấy có hai thái cực khác hẳn nhau, một nhóm ngân hàng có hai hệ số tỷ lệ giữa vốn tự có so với tổng tài sản thật cao, và có một nhóm ngân hàng có hai hệ số này thật thấp. Nhóm ngân hàng có hệ số cao như NH liên doanh, nước ngoài chưa hẳn đã tốt xét về khía cạnh lợi nhuận; hơn nữa, có thể các ngân hàng này không phải chủ động duy trì lỷ lệ cao như vậy, mà có thể huy động vốn gặp khó khăn hay có những vấn đề về thanh khoản. Bên cạnh đó, tỷ lệ an toàn vốn tối thiểu của NHTM giai đoạn 2018-2020.
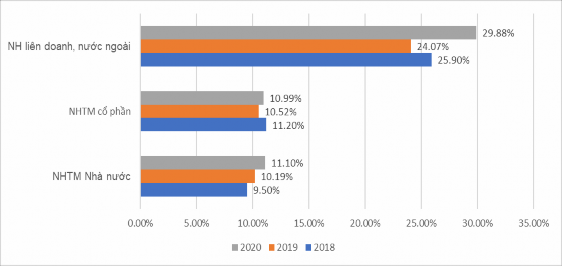
(Nguồn: Báo cáo thường niên 2020 của NHNN) Hình 4.4: Tỷ lệ an toàn vốn tối thiểu của NHTM Việt Nam giai đoạn 2018-2020 Hình 4.4 cho thấy hệ số an toàn vốn tối thiểu (CAR) của hệ thống NHTM Việt Nam
duy trì khá ổn định ở các nhóm ngân hàng và trên mức 9%. Tuy nhiên quy định về cách tính
hệ số CAR của các NHTM ở Việt Nam vẫn chỉ đang dần tiếp cận với chuẩn mực quốc tế và vẫn còn khoảng cách. Vì vậy, giá trị của hệ số CAR chưa phản ánh đúng thực tế về mức độ rủi ro của các ngân hàng. Ngoài ra, tác giả tiếp tục phân tích hai chỉ số khá quan trọng đó là: ROA và ROE. Đây là hai chỉ số quan trọng trong phân tích tài chính để đánh giá khả năng hoạt động, sản xuất kinh doanh của một ngân hàng, giúp nhà đầu tư tìm ra các cổ phiếu có tiềm năng. ROA (Return on Assets) là chỉ số thể hiện tỷ suất sinh lời trên tài sản. Chỉ số này thể hiện tỷ lệ giữa lợi nhuận so với tài sản được đem vào hoạt động sản xuất kinh doanh nhằm đánh giá hiệu quả trong việc sử dụng tài sản của ngân hàng. Ngoài ra, chỉ số ROE thể hiện tỷ lệ giữa lợi nhuận so với vốn chủ sở hữu mà ngân hàng sử dụng vào hoạt động của ngân hàng nhằm đánh giá hiệu quả trong việc sử dụng vốn. Sau đây là kết quả hai chỉ số ROA và ROE của NHTM qua ba năm 2018-2020 như sau: