![]()
Nền tảng về xử lý ngôn ngữ tự nhiên
2.2.1. Tìm kiếm ngữ nghĩa (Semantic search)
Tìm kiếm ngữ nghĩa là một cụm từ để chỉ các công cụ tìm kiếm có thể hiểu được các truy vấn ngôn ngữ tự nhiên và có thể nhiều hơn thế với việc hiểu được ngữ cảnh của người tìm kiếm tại thời điểm họ nhập truy vấn. Một ví dụ đơn giản như: nếu như truy vấn là “lượng nguyên liệu tiêu thụ của jaguar” thì cơ khả năng lớn từ “jaguar” là họ đang tìm kiếm thông tin của một chiếc xe hơn là muốn tìm một con vật.
Các yếu tố chính của tìm kiếm ngữ nghĩa:
- Hiểu ngôn ngữ tự nhiên
- Ngữ cảnh của luồng truy vấn
- Ngữ cảnh của người dùng
- Nhận biết thực thể

Hình 11: Bốn yếu tố quan trọng trong Semantic search
Việc hiểu rõ hơn về ý định tìm kiếm của người dùng sẽ tối đa hóa khả năng người dùng có được trải nghiệm tìm kiếm tốt nhất. Và đấy chính là cách mà các công cụ tìm kiếm nổi tiếng
trên thế giới như Google, Bing, Baidu… có thể mang lại cho bạn những thông tin sát nhất với thứ mà bạn đang cần.
2.2.2. TF-IDF
TF-IDF là viết tắt của từ term frequency – inverse document frequency, đây là một chỉ số để đánh giá mức độ quan trọng của một từ đối với một văn bản hoặc một tập tài liệu. TF- IDF thường được sử dụng trong các bài toán truy hồi thông tin và khai phá dữ liệu [2] [3] [4].
2.2.2.1. TF – term frequency
Đây là tần số xuất hiện một từ trong một văn bản, được tính bằng công thức:
𝑡𝑓(𝑡, 𝑑) =
𝑓(𝑡, 𝑑)
max {𝑓(𝑤, 𝑑) ∶ 𝑤 ∈ 𝑑}
Trong đó:
- f(t,d): số lần xuất hiện từ t trong văn bản d
- max {𝑓(𝑤, 𝑑) ∶ 𝑤 ∈ 𝑑}: số lần xuất hiện nhiều nhất của một từ bất kỳ trong văn bản
- giá trị của tf(t,d) sẽ thuộc khoảng [0, 1]
2.2.2.2. IDF – inverse document frequency
Đây là tần số nghịch của một từ trong tập văn bản, chỉ số này nhằm để giảm giá trị của những từ phổ biến. Mỗi từ chỉ có một giá trị IDF trong một văn bản và được tính bằng công thức:
Trong đó:
𝑖𝑑𝑓(𝑡, 𝐷) = 𝑙𝑜𝑔
|𝐷|
|{𝑑 ∈ 𝐷 ∶ 𝑡 ∈ 𝑑}|
- |D|: tổng số văn bản trong tập D
- |{𝑑 ∈ 𝐷 ∶ 𝑡 ∈ 𝑑}|: số văn bản chứa từ nhất định, với điều kiện t xuất hiện trong văn bản d tức là: 𝑡𝑓(𝑡, 𝑑) ≠ 0. Nếu từ đó không xuất hiện ở bất cứ 1 văn bản nào trong
tập thì mẫu số sẽ bằng 0 => phép chia cho không không hợp lệ, vì thế người ta thường thay bằng mẫu thức 1 + |{𝑑 ∈ 𝐷 ∶ 𝑡 ∈ 𝑑}|.
2.2.2.3. Giá trị TF-IDF
𝑡𝑓𝑖𝑑𝑓(𝑡, 𝑑, 𝐷) = 𝑡𝑓(𝑡, 𝑑) 𝑥 𝑖𝑑𝑓(𝑡, 𝐷)
Những từ có giá trị TF-IDF cao là những từ xuất hiện nhiều trong văn bản này, và xuất hiện ít trong các văn bản khác. Việc này giúp lọc ra những từ phổ biến và giữ lại những từ có giá trị cao (từ khoá của văn bản đó).
2.2.3. Phân tách từ (word segmentation)
Phân tách từ là bài toán phân tách một chuỗi ký tự đầu vào thành các từ độc lập.
Trong tiếng Anh và một số ngôn ngữ khác sử dụng chữ cái Latin, dấu cách gần như là một phương pháp tốt để phân tách các từ trong câu. Tuy nhiên, không phải tất cả các ngôn ngữ đầu có dấu phân cách như vậy. Trong tiếng Thái Lan, tiếng Lào, cụm từ và câu được phân cách nhưng từ thì lại không. Trong tiếng Trung Quốc và tiếng Nhật Bản, có dấu phân cách câu nhưng lại không có phân cách từ. Còn tiếng Việt lại được phân cách bằng âm tiết. Vì vậy, bài toán phân tách từ gặp khá nhiều khó khăn.
Ví dụ:
Văn bản đầu vào | Kết quả | |
English | I am looking for my pen. | I am looking_for my_pen |
Vietnamese | Học sinh học sinh học | Học_sinh học sinh_học |
Japanese | 私は日本人です | 私_は 日_本_人 で_す |
… |
Có thể bạn quan tâm!
-
 Hệ thống tìm kiếm tri thức thông minh trên miền wikihow - 2
Hệ thống tìm kiếm tri thức thông minh trên miền wikihow - 2 -
 Thị Phần Sử Dụng Các Công Cụ Tìm Kiếm Trên Toàn Cầu Năm 2019
Thị Phần Sử Dụng Các Công Cụ Tìm Kiếm Trên Toàn Cầu Năm 2019 -
 Bảng Đối Chiếu Một Số Khái Niệm Của Elasticsearch Và Mysql
Bảng Đối Chiếu Một Số Khái Niệm Của Elasticsearch Và Mysql -
 Ma Trận Chỉ Số Tương Đồng Giữa Các Từ Theo Word2Vec
Ma Trận Chỉ Số Tương Đồng Giữa Các Từ Theo Word2Vec -
 Cấu Trúc Lưu Trữ Dữ Liệu Bài Viết Của Wikihow Trên Database
Cấu Trúc Lưu Trữ Dữ Liệu Bài Viết Của Wikihow Trên Database -
 Nội Dung Bài Viết Phù Hợp Với Truy Vấn Của Người Dùng
Nội Dung Bài Viết Phù Hợp Với Truy Vấn Của Người Dùng
Xem toàn bộ 81 trang tài liệu này.
Bảng 3: Phân tách từ trong các ngôn ngữ khác nhau
Có nhiều cách tiếp cận để giải quyết được bài toàn này [5].
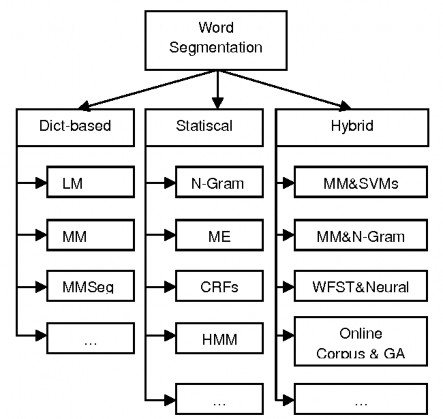
Hình 12: Các phương pháp tiếp cận của bài toán phân tách từ
Các phương pháp này được phân loại thành 3 nhóm chính:
- Dict-based: là tạo ra một từ điển và phân tách văn bản đầu vào thành các từ có trong từ điển đó. Hai kỹ thuật tiếp cận hiệu quả nhất của phương pháp này là Maximun Matching và Longest Matching.
- Statiscal: dựa vào việc sử dụng một tập dữ liệu cực lớn đã được gán nhãn. Một số phương pháp phổ biến như N-gram Language Model [6], Hidden Markov Model (HMM) [7], Conditional Random Fields (CRFs) [8] và Maximum Entropy (ME) [9].
- Hybrid: là sự kết hợp của nhiều phương pháp khác nhau để tận dụng ưu điểm của mỗi phương pháp và hạn chế nhược điểm của chúng. Đã có nhiều mô hình hybrid được công bố và áp dụng cho nhiều ngôn ngữ khác nhau. Chúng bao gồm các kỹ thuật dictionary-based (Maximun Matching, Longest Matching), statistics-based (N-
gram, CRFs, ME) và các thuật toán học máy (Support Vector Machines - SVMs, Genetic Algorithm – GA) [10] [11] [12].
2.2.4. Gán nhãn từ loại (Part of speech tagging – POSTag)
POSTag, còn được gọi là gán nhãn ngữ pháp, là quá trình đánh dấu một từ trong văn bản tương ứng với một phần của lời nói, dựa trên cả định nghĩa và ngữ cảnh, quan hệ của từ đó với các từ xung quanh và các từ liên quan trong cụm, câu, đoạn văn. Ví dụ: một số lớp từ trong tiếng Anh danh từ, giới từ, đại từ, liên từ, động từ, tính từ, trạng từ… Một trong những bước tiền xử lý bắt buộc của POSTag là phân tách từ (Word Segmentation).
Vấn đề của POS tagging là sử lý nhập nhằng, lựa chọn nhãn từ phù hợp với ngữ cảnh. Ví dụ: từ “đá” trong câu “Con ngựa này được làm bằng đá” là danh từ nhừn trong câu “Bọn trẻ đang đá bóng” thì lại là động từ.
Một số ví dụ của POSTag:
- Văn bản đầu vào: Học_sinh học sinh_học
- Kết quả sau khi đã gán nhãn từ loại: Học_sinh/N học/V sinh_học/N (Trong đó /N là danh từ, /V là động từ)
![]()
Công cụ hỗ trợ
2.3.1. VnCoreNLP
VnCoreNLP [13] là một bộ công cụ gán nhãn dành cho tiếng Việt, cung cấp các công cụ xử lý ngôn ngữ tự nhiên như: Word Segmentation, POS tagging, Named Entity Recognition và Dependency Parsing.
Các tính chất của VnCoreNLP:
- Chính xác: VnCoreNLP là bộ công cụ xử lý ngôn ngữ tiếng Việt với độ chính xác cao. Với một bộ dữ liệu chuẩn thì VnCoreNLP cho ra một kết quả cao hơn tất cả các công cụ đã từng được công bố trước đây.
- Xử lý những tập dữ liệu lớn trong thời gian rất nhanh.
- Dễ dàng triển khai.
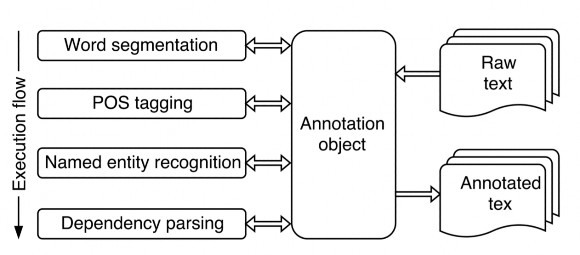
Hình 13: Luồng xử lý của VnCoreNLP
2.3.2. Word2vec
Word2vec là một kỹ thuật xử lý ngôn ngữ tự nhiên. Thuật toán này sử dụng mô hình neural network để học các liên kết từ một tập dữ liệu lớn. Sau khi huấn luyện một tập đủ lớn, mô hình này có thể phát hiện được những từ đồng nghĩa hoặc có thể áp dụng vào cho bài toán gợi ý từ cho một từ hoặc một phần văn bản.
Kỹ thuật này sẽ gán giá trị vector (một danh sách các số cụ thể) cho từng từ riêng biệt. Các vector này được tính toán sao cho: nếu hai từ càng tương đồng về mặt ngữ nghĩa thì chỉ số cosine similarity giữa hai vector biểu diễn chúng càng cao.
Word2vec có hai model là skip-grams và CBOW:
- Skip-grams là mô hình dự đoán từ xung quanh. Ví dụ khi áp dụng windows size là 3 cho câu “I love you so much” ra sẽ thu được tập {(I, love), love}, {(love, so), you},
{(you, much), so}. Khi cho đầu vào là từ “love” thì mô hình này sẽ dự đoán ra các từ xung quanh là “I” và “you”.
- CBOW (continous bag of word), mô hình này ngược lại với Skip-grams, tức là đầu vào sẽ là các từ và mô hình sẽ tính toán để đưa ra dự đoán từ liên quan đến các từ đầu vào.
Trong thực nghiệm thì CBOW huấn luyện dữ liệu nhanh hơn nhưng độ chính xác lại không cao hơn skip-grams và ngược lại, và chúng ta chỉ áp dụng một trong hai mô hình để huấn luyện tập dữ liệu.
2.3.3. Elasticsearch
Như đã giới thiệu, Elasticsearch là một công cụ tìm kiếm mã nguồn mở phân tán cho tất cả các loại dữ liệu bao gồm cả văn bản, số, không gian địa lý, cấu trúc và không có cấu trúc. Elasticsearch cung cấp các RESTful API để thực hiện các tác vụ trên server riêng biệt nên có thể tích hợp dễ dàng với bất kỳ hệ thống nào.
Chương 3
Hệ thống tìm kiếm tri thức trên miền Wikihow
![]()
Tính toán độ tương đồng giữa hai câu văn
Trong luận văn tôi đề xuất một phương pháp tính toán độ tương đồng giữa hai câu văn dựa trên chỉ số tương đồng Jaccard Similarity.
Chỉ số Jaccard còn được gọi là hệ số tương tự, chỉ số này có thể dùng để tính toán sự giống nhau giữa các tập mẫu hữu hạn ( trong đó các phần tử không trùng lặp) và được định nghĩa là kích thước của phần giao chia cho kích thước của phần hợp của các tập mẫu.
Biểu thức toán học của chỉ số được biểu diễn như sau:
𝐽(𝐴, 𝐵) =
|𝐴 ∩ 𝐵|
=
|𝐴 ∪ 𝐵|
|𝐴 ∩ 𝐵|
|𝐴| + |𝐵| − |𝐴 ∩ 𝐵|
Giá trị sẽ nằm trong khoảng [0, 1] và bằng 1 khi hai tập này có các phần tử giống hệt nhau.
Chỉ số này có thể được áp dụng để tính toán độ tương đồng giữa hai câu văn khi ta coi mỗi từ trong câu văn là một phần tử trong tập từ mà các phần tử này không trùng lặp. Nhưng nếu như chúng ta chỉ đơn thuần tìm các phần tử trong hai tập từ cần so sánh xem có xuất hiện trong tập từ còn lại không để tính số lượng từ giao nhau của hai tập thì sẽ không giải quyết được bài toán từ đồng nghĩa. Ở đây tôi muốn nói rằng, để tính toán độ tương đồng của hai câu văn dựa trên Jaccard Similarity thì phần giao ngoài việc tính số lượng từ xuất hiện ở cả hai câu văn dựa trên các ký tự thì phải tính toán thêm sự tương đồng về ngữ nghĩa. Vì vậy tôi đề xuất một công thức tính độ tương đồng cho hai chuỗi ký tự X và Y như sau: