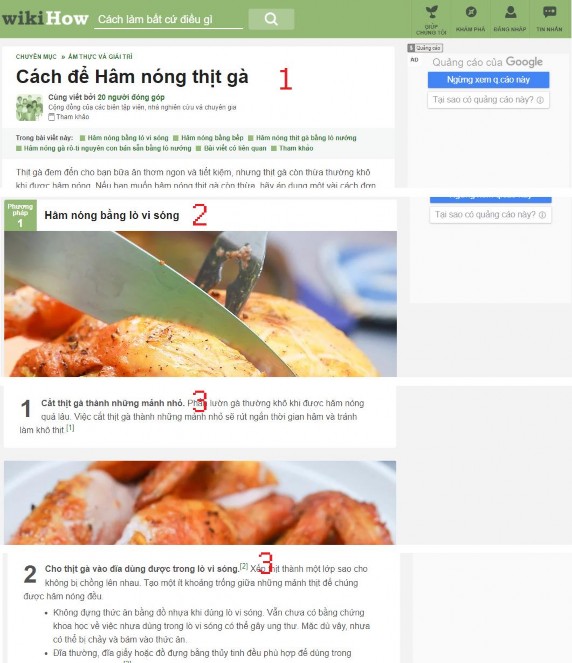
Hình 17: Bố cục của bài viết trên wikiHow
Sau khi trích xuất được nội dung của bài viết, bước tiếp theo sẽ là lưu trữ dữ liệu vào trong cơ sở dữ liệu. Cấu trúc dữ liệu sẽ bao gồm ba bảng chính:
- article: lưu thông tin chung của bài viết:
o title: tiêu đề của bài viết.
o summarization: mô tả ngắn gọn của bài viết.
o warning: các lưu ý.
o recommendation: một số lời khuyên.
- method: lưu thông tin chung của các phương pháp trong bài viết:
o article_id: id của bài viết (article).
o title: tiêu đề của phương pháp.
o summarization: mô tả ngắn gọn của phương pháp.
- step: lưu thông tin các bước trong mỗi phương pháp thực hiện:
o mehod_id: id của phương pháp (method).
o title: mô tả chính về bước thực hiện.
o content: cách thực hiện cụ thể.
o image_url: đường dẫn ảnh minh họa trong bước thực hiện.

Hình 18: Cấu trúc lưu trữ dữ liệu bài viết của wikiHow trên database
3.3.1.2. Index dữ liệu vào công cụ ElasticSearch
Do công cụ tìm kiếm chủ yếu sẽ dựa trên nội dung của tiêu đề và phần mô tả ngắn gọn của bài viết nên hệ thống sẽ tiến hành bước tiền xử lý dữ liệu và index dữ liệu này vào trong Elasticsearch để phục vụ cho việc tìm kiếm.
Sau khi thu thập được dữ liệu bài viết trên wikiHow, hệ thống sẽ sử dụng VnCoreNLP để thực hiện phân tách các từ trong tiêu đề và phần mô tả ngắn gọn của bài viết. Như đã phân tích ở bên trên thì Elasticssearch sẽ gặp trở ngại với từ đồng nghĩa trong quá trình thực hiện tìm kiếm. Chính vì vậy, dữ liệu được index vào trong Elasticsearch sẽ được tôi xử lý để đưa về một chuẩn chung. Các bước được thực hiện như sau:
- Xây dựng các cụm từ đồng nghĩa và xác định từ đại diện cho tập từ này dựa vào Word2vec. Ví dụ: Với từ “xinh_đẹp” chúng ta sẽ có được một số từ có độ tương đồng cao với từ này như:
W2 | Score | |
xinh_đẹp | khả_ái | 0.61770927 |
xinh_đẹp | long_lanh | 0.45318955 |
xinh_đẹp | lộng_lẫy | 0.59213918 |
xinh_đẹp | đoan_trang | 0.53585093 |
xinh_đẹp | đằm_thắm | 0.54625511 |
xinh_đẹp | ưa_nhìn | 0.46228677 |
xinh_đẹp | yêu_kiều | 0.63439822 |
xinh_đẹp | rạng_rỡ | 0.58222419 |
Có thể bạn quan tâm!
-
 Bảng Đối Chiếu Một Số Khái Niệm Của Elasticsearch Và Mysql
Bảng Đối Chiếu Một Số Khái Niệm Của Elasticsearch Và Mysql -
 Các Phương Pháp Tiếp Cận Của Bài Toán Phân Tách Từ
Các Phương Pháp Tiếp Cận Của Bài Toán Phân Tách Từ -
 Ma Trận Chỉ Số Tương Đồng Giữa Các Từ Theo Word2Vec
Ma Trận Chỉ Số Tương Đồng Giữa Các Từ Theo Word2Vec -
 Nội Dung Bài Viết Phù Hợp Với Truy Vấn Của Người Dùng
Nội Dung Bài Viết Phù Hợp Với Truy Vấn Của Người Dùng -
 Hệ thống tìm kiếm tri thức thông minh trên miền wikihow - 9
Hệ thống tìm kiếm tri thức thông minh trên miền wikihow - 9 -
 Hệ thống tìm kiếm tri thức thông minh trên miền wikihow - 10
Hệ thống tìm kiếm tri thức thông minh trên miền wikihow - 10
Xem toàn bộ 81 trang tài liệu này.
Bảng 5: Các từ tương đồng với "xinh đẹp"
Chỉ số tương đồng càng cao sẽ cho thấy 2 từ có nghĩa càng sát nhau và chúng ta sẽ coi chúng nằm trong 1 tập từ. Trong luận văn, mức được lựa chọn để xác định 2 từ nằm trong một tập từ gốc sẽ là 0.57 (theo khảo sát của dữ liệu được lấy từ word2vec). Chúng ta sẽ kết nạp các từ: xinh_đẹp, khả_ái, lộng_lẫy, yêu_kiều, rạng_rỡ vào tập từ hiện tại. Và đại diện cho tập từ trên sẽ là từ “xinh_đẹp”.
- Thay thế những từ trong dữ liệu đã được phân tách từ thành từ đại diện nếu như chúng nằm trong tập từ đồng nghĩa. Ví dụ với câu: “Cách để khiến cho bạn trở_nên lộng_lẫy hơn” chúng ta sẽ thay thế từ “lộng_lẫy” thành từ “xinh_đẹp” và thay thế vào câu trên.
Dữ liệu index vào trong Elasticsearch sẽ bao gồm các fields:
- article_id: id của bài viết.
- original_title: tiêu đề gốc của bài viết.
- standardized_title: tiêu đề đã được chuẩn hóa.
- original_summarization: nội dung tóm tắt gốc của bài viết.
- standardized_summarization: nội dung tóm tắt đã được chuẩn hóa.
3.3.2. Tìm kiếm bài viết phù hợp với truy vấn
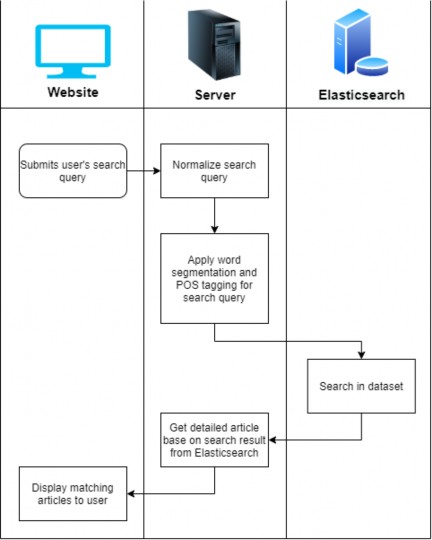
Hình 19: Luồng xử lý truy vấn dữ liệu của người dùng
Cùng với việc chuẩn hóa các dữ liệu được index vào trong Elasticsearch thì truy vấn của người dùng cũng sẽ được chuẩn hóa để việc tìm kiếm có thể mang lại hiệu quả cao nhất: Câu truy vấn sẽ được phân tách từ (word segmentation) sau đó các từ trong câu sẽ được thay thế bằng từ đại diện (nếu có) để làm dữ liệu đầu vào (input) cho phần tìm kiếm trong Elasticsearch.
Kết quả tìm kiếm của Elasticsearch sẽ cho ra danh sách các kết quả có mức độ tương đồng cao nhất so với câu truy vấn tìm kiếm bên trên. Tuy nhiên do dữ liệu index trong
Elasticsearch và câu truy vấn đầu vào đã được chuấn hóa, nên cần tính toán lại độ tương đồng trên dữ liệu gốc (trước khi được chuẩn hóa) dựa vào các kết quả mà Elasticsearch đã trả về trước đó. Với công thức tính độ tương đồng được đề xuất trong mục 3.1, chúng ta sẽ áp dụng cho 30 kết quả tìm kiếm có điểm cao nhất nhận được qua Elasticsearch để có được những bài viết phù hợp với truy vấn đầu vào. Giá trị của S(X, Y) càng lớn thì kết quả của hệ thống và truy vấn của người dùng càng tương đồng. Vì vậy, dữ liệu trả về cho người dùng sẽ là những kết quả có chỉ số S(X, Y) giảm dần.
3.3.3. Xây dựng website tìm kiếm tri thức trên miền wikiHow
3.3.3.1. Xây dựng cơ sở dữ liệu với MySQL
Hệ quản trị cơ sở dữ liệu trong luận văn sử dụng là MySQL phiên bản 5.7
3.3.3.2. ElasticSearch server
Luận văn sử dụng công cụ ElasticSearch phiên bản 7.13
3.3.3.3. Backend server sử dụng Play framework
Play framework là một công cụ xây dựng web application với Java và Scala (nhưng trong luận , tôi chỉ sử dụng để xây dựng server với Java) một cách dễ dàng. Play được thiết kế với khuynh hướng phát triển những web nhẹ và thân thiện với người dùng.
Framework này được xây dựng dựa trên Akka, Play cung cấp công cụ để có thể dự đoán và giảm thiểu tối đa việc sử dụng tài nguyên phần cứng (CPU, bộ nhớ đệm, thread…), giúp cho ứng dụng có thể mở rộng được một cách tối đa.
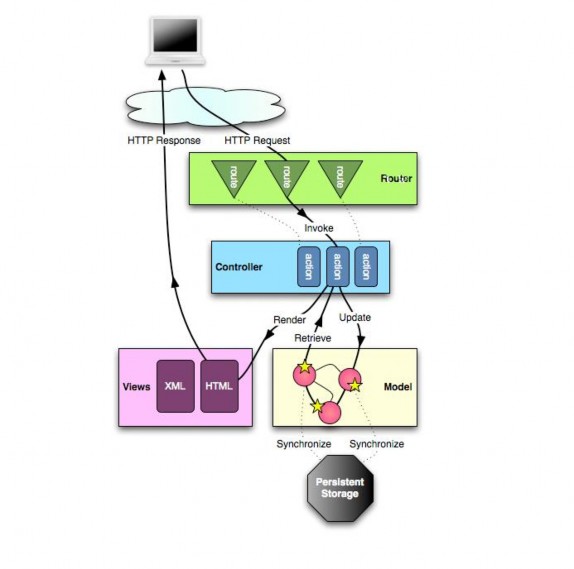
Hình 20: Vòng đời Play framework
Hình trên mô tả vòng đời của một request gửi lên server. Khi có một request được nhận, phần route sẽ tìm kiếm xem request đó thuộc action nào để thực thi. Và sau đó tùy vào mục đích của hàm để hệ thống có thể cập nhật dữ liệu trong cơ sở dữ liệu hoặc là tạo ra một view để trả về với HTTP response.
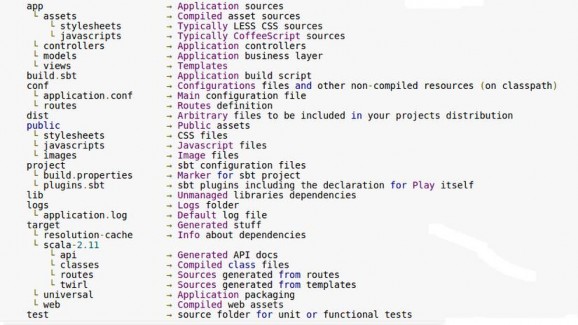
Hình 21: Bố cục của ứng dụng Play
Bố cục của một Play application một số thành phần chính như sau:
- Thư mục /app : Chứa tất cả các file thực thi logic với các mã nguồn java, scala, các mẫu html. Trong thư mục này thường được chia nhỏ ra làm 3 thành phần chính:
o app/controller: chứa các giao thức giao tiếp bên ngoài
o app/model: chứa các thực thể (có thể là thực thể tương ứng với các bảng trong cơ sở dữ liệu)
o app/view: chứa các mã lệnh html để sinh ra giao diện trả về
- Thư mục /conf : Chứa các file cấu hình của hệ thống, và sẽ có 2 file cấu hình chính là application.conf và routes.conf
- Thư mục /lib : Chứa các mã nguồn mà ứng dụng sử dụng đến.
- File build.sbt : Nơi khai báo cấu hình build chính của ứng dụng.
- Thư mục /target : Chứa mọi file được sinh ra bởi phần mềm sau khi được compile.
3.3.3.4. Xây dựng giao diện người dùng với AngularJs
AngularJs là một framework có cấu trúc cho các ứng dụng web động. Nó cho phép người dùng có thể sử dụng html như là một ngôn ngữ mẫu và cho phép chúng ta có thể mở rộng
cú pháp của html để bố trí các thành phần của ứng dụng một cách có bố cục rõ ràng. Một số đặc trưng của AngularJs như:
- Được phát triển dựa trên ngôn ngữ javascript.
- Tạo ứng dựng theo mô hình MVC.
- Khả năng tương thích cao.
- Mã nguồn mở.
- Chạy được trên nhiều nền tảng trình duyệt trên máy tính cũng như điện thoại.
- Cung cấp khả năng data binding với html.
Nhưng đi cùng với đó AngularJs cũng vẫn còn một số hạn chế nhất định:
- Không an toàn nên cần có sự bảo mật và xác thực phía server để ứng dụng có thể trở nên an toàn hơn.
- Không thể sử dụng được nếu như người dùng vô hiệu hóa Javascript trên trình duyệt web.
Một số hình anh về giao diện của ứng dụng “Tìm kiếm tri thức thông minh trên miền wikiHow”