- Lowercasing: hay còn được gọi là normalizing, đây là bước chuyển toàn bộ nội dung văn bản thành chữ thường.
- Remove stop words: hay còn gọi là remove common words, là bước loại bỏ các từ chung và không có nhiều ý nghĩa trong miền giữ liệu tìm kiếm.
- Streaming: hay còn gọi là root form, là bước giảm số lượng từ từ văn bản đưa vào.
Các bước trên còn được gọi chung là bước tokenization, mục đích chính là chuyển văn bản thành các đoạn nhỏ, ở đây được gọi là các token. Các token này được kết hợp với field name của chúng để trở thành các terms – được dùng để tìm kiếm một cách trực tiếp.
d. Truy vấn và tìm kiếm:
Lucene cung cấp lớp IndexSearcher để thực hiện tìm kiếm thông qua hàm search. Với mỗi tìm kiếm lucene sẽ trả về các kết quả (hits) chứa các thông tin đã tìm được và được sắp xếp theo độ chính xác. Lucene cung cấp các loại Query như: QueryParse, BooleanQuery, RangeQuery và TermQuery để người dùng có thể sử dụng linh hoạt cho mỗi mục đích tìm kiếm.
2.1.2.2. Elasticsearch
Elasticsearch là một công cụ tìm kiếm và phân tích phân tán dựa trên nền tảng của thư viện Lucene. Nó có thể tìm kiếm và phân thích tất cả các loại dữ liệu gần như tức thời, cho dù văn bản có cấu trúc hay không có cấu trúc, dữ liệu số, dữ liệu không gian. Elasticsearch có thể lưu trữ và lập chỉ mục một cách hiệu quả để hỗ trợ tìm kiếm nhanh. Thay vì chỉ đơn giản là truy xuất dữ liệu, công cụ này có thể tập hợp thông tin để phát hiện ra xu hướng và các mẫu từ dữ liệu của bạn. Khi dữ liệu và khối lượng truy vấn tăng lên, tính chất phân tán của Elasticsearch cho phép chúng ta có thể triển khai hệ thống một cách liền mạch [1].
a. Một số khái niệm cơ bản trong Elasticsearch
Dưới đây là một số khái niệm cơ bản trong Elasticsearch
- Documents, types và indices: Documents là đơn vị nhỏ nhất để lưu trữ dữ liệu trong Elasticsearch được lưu trữ dưới dạng JSON. Nếu chúng ta đối chiếu sang một hệ cơ sở quản trị dữ liệu thân thuộc hơn là MySQL thì document ở đây sẽ tương đương như một row, types sẽ ứng với tables và indices tương ứng với databases.
Elasticsearch | |
Databases | Indices |
Table | Types |
Columns/Rows | Documents with Properties |
Có thể bạn quan tâm!
-
 Hệ thống tìm kiếm tri thức thông minh trên miền wikihow - 1
Hệ thống tìm kiếm tri thức thông minh trên miền wikihow - 1 -
 Hệ thống tìm kiếm tri thức thông minh trên miền wikihow - 2
Hệ thống tìm kiếm tri thức thông minh trên miền wikihow - 2 -
 Thị Phần Sử Dụng Các Công Cụ Tìm Kiếm Trên Toàn Cầu Năm 2019
Thị Phần Sử Dụng Các Công Cụ Tìm Kiếm Trên Toàn Cầu Năm 2019 -
 Các Phương Pháp Tiếp Cận Của Bài Toán Phân Tách Từ
Các Phương Pháp Tiếp Cận Của Bài Toán Phân Tách Từ -
 Ma Trận Chỉ Số Tương Đồng Giữa Các Từ Theo Word2Vec
Ma Trận Chỉ Số Tương Đồng Giữa Các Từ Theo Word2Vec -
 Cấu Trúc Lưu Trữ Dữ Liệu Bài Viết Của Wikihow Trên Database
Cấu Trúc Lưu Trữ Dữ Liệu Bài Viết Của Wikihow Trên Database
Xem toàn bộ 81 trang tài liệu này.
Bảng 2: Bảng đối chiếu một số khái niệm của Elasticsearch và MySQL
- Inverted Index: được thiết kế để tăng tốc độ của full text search. Một inverted index bao gồm một danh sách tất cả những từ không lặp lại xuất hiện trong một hoặc nhiều văn bản, và với mỗi từ sẽ đi kèm với danh sách văn bản chứa nó. Ví dụ: ta có nội dung của 2 document:
o Document 1: The quick brown fox jumped over the lazy dog
o Document 2: Quick brown foxes leap over lazy dogs in summer
Để tạo inverted index đầu tiên chúng ta phân tách nội dung của mỗi văn bản thành các từ đơn âm (gọi là term hoặc token), sắp xếp lại danh sách các term (không trùng lặp) và sau đó và liệt kê các document có chứa term đó. Kết quả thu được sẽ có dạng như sau:
Term Doc_1 Doc_2
-------------------------
| | | X | | | | X | |
brown dog | | | | X X | | | | X |
dogs | | | | | X | |
fox | | | X | | | |
foxes | | | | | X | |
in | | | | | X | |
jumped | | | X | | | |
lazy leap | | | | X | | | | X X |
over | | | X | | | X |
quick | | | X | | | |
summer | | | | | X | |
the | | | X | | |
-------------------------
Giả sử khi chúng ta muốn tìm kiếm cụm từ “quick brown” ta chỉ cần tìm các document mà chứa các term tương ứng:
Term Doc_1 Doc_2
-------------------------
brown | X | X quick | X |
-------------------------
Total | 2 | 1
-------------------------
Cả hai document đều chứa ít nhất 1 term nhưng document 1 thì có chứa nhiều term trong cụm từ tìm kiếm hơn. Giả sử chúng ta tính độ tương tự của 2 văn bản chỉ bằng cách đếm số lượng term trùng nhau giữa 2 văn bản đó thì ta có thể nói rằng document 1 sẽ là kết quả phù hợp hơn cho câu tìm kiếm “quick brown”.
Có một vài vấn đề còn tồn đọng:
o Phân biệt giữa viết hoa và viết thường: Quick và quick đang được coi là 2 từ gốc khác nhau.
o Phân biệt giữa số ít và số nhiều: fox và foxes hoặc là dog và dogs khá là giống nhau, và có thể được xem là một từ gốc.
o Phân biệt từ đồng nghĩa: jumped và leap là hai từ đồng nghĩa nhưng lại được tính thành hai từ gốc khác nhau.
Vì vậy chúng ta chuẩn hóa các term theo một định dạng chuẩn để có thể tìm được document dù không chứa chính xác các term mà người dùng truy vấn, nhưng vẫn đủ sát nghĩa để có thể coi là phù hợp. Ví dụ:
o Chuyển các document thành văn bản viết thường.
o Chuyển các từ số nhiều thành số ít
o Chỉ index các từ đồng nghĩa thông qua một từ đại diện
Sau khi áp dụng một số chuẩn hóa trên dữ liệu index sẽ trông như sau:
Term Doc_1 Doc_2
-------------------------
| | X | | | X | |
dog | | | X | | | X |
fox | | | X | | | X |
in | | | | | X | |
jump | | | X | | | X |
lazy | | | X | | | X |
over | | | X | | | X |
quick | | | X | | | X |
summer the | | | | X | | | | X X |
------------------------
Và đương nhiên khi chúng ta thực hiện tìm kiếm thì văn bản đầu vào cũng phải được chuẩn hóa theo các quy tắc bên thì mới có kết quả tìm kiếm chính xác hơn.
- Node: là nơi lưu trữ dữ liệu, tham gia vào việc đánh index của cluster và thực hiện tìm kiếm. Mỗi một mode được định danh bằng một tên duy nhất và có giá trị mặc định là UUID (universally unique identifier) tiến thành khi thiết lập hoặc tự định danh. Và tên của node là rất quan trọng trong việc xác định node đó thuộc cluster nào trong hệ thống Elasticsearch.
- Cluster: là tập hợp của một hoặc nhiều node hoạt động cùng nhau và các node này sẽ có chung giá trị của thuộc tính cluster.name. Mỗi cluster cũng được định danh bằng một giá trị không trùng lặp (unique name) và được sử dụng chung cho tất cả
các nodes. Vì vậy khi tên của các cluster trùng nhau sẽ gây nên hiện tượng các node join vào nhầm cluster và sinh ra sự cố. Cluster sẽ có một node chính và được gọi là master sẽ được lựa chọn tự động và có thể được thay đổi nếu như có sự cố xảy ra. Các nodes trong cluster có thể hoạt động trên các server khác nhau để đảm bảo được khi có sự cố xảy ra thì các server khác có thể hoạt động một cách bình thường với đầy đủ các chức năng.
b. Mô hình tính toán độ tương tự (Similarity module)
Sự tương tự định nghĩa các văn bản khớp với nhau như thế nào thông qua một chỉ số. Chúng ta có thể tự thiết lập một mô hình tính toán độ tương tự, tuy nhiên những mô hình có sẵn đã khá tốt cho những trường hợp phổ biến trong thực tế.
Một số mô hình tính toán độ tương tự có sẵn của Elasticsearch:
- BM25 similarity (Mô hình mặc định): được dựa trên TF/IDF, mô hình này có sẵn bộ chuẩn hóa TF, và được cho là hiệu quả hơn với các trường có độ dài ngắn (như là tên). Các thông số cơ bản của mô hình:
o k1: Kiểm soát việc chuẩn hóa tần số từ phi tuyến tính (độ bão hòa). Giá trị mặc định là 1.2
o b: Kiếm soát tỉ lệ giữa độ dài của văn bản so với độ dài trung bình của tất cả các văn bản.
o discount_overlaps: Xác định việc tính toán có phụ thuộc vào các từ trùng lặp hay không.
- Một số mô hình khác như:
o DFR similarity
o IB similarity
o LM Dirichlet similarity
o LM Jelinek Mercer similarity
o Scripted similarity
c. Một số ưu và nhược điểm của Elasticsearch
- Ưu điểm:
o Do dựa trên nền tảng Apache lucene(near-realtime searching) nên tốc độ tìm kiếm dữ liệu của elasticsearch là rất nhanh.
o Cung cấp công cụ truy vấn với cấu trúc phức tạp một các cụ thể và rõ ràng thông qua JSON.
o Khả năng mở rộng (scale-up).
o Có hỗ trợ tìm kiếm fuzzy search. Khi từ khóa tìm kiếm bị sai chính tả hoặc không đúng cú pháp thì elasticsearch vẫn có thể trả về kết quả gần sát nhất với câu truy vấn.
o Có khả năng phân tích dữ liệu.
o Hỗ trợ nhiều ngôn ngữ tích hợp như: Java, php, Javascript, ruby .net hay Python.
- Nhược điểm:
o Do Elasticsearch được sinh ra với mục đích chính là tìm kiếm dữ liệu. Vậy nên các tác vụ liên quan đến CRUD thì lại là nhược điểm của nó khi được mang ra so sánh với các database khác như: MySQL, PostgreSQL, Mongodb,… Vì vậy trong thực tế người ta không dùng Elasticsearch làm database chính mà sẽ kết hợp nó với một hệ quản trị cơ sở dữ liệu khác.
o Một lý do để Elasticsearch không được sử dụng làm database chính vì nó không có tính transaction.
o Do việc đánh index của Elasticsearch khá mất nhiều thời gian với lượng dữ liệu lớn vậy nên với những hệ thống thường xuyên thay đổi bộ dữ liệu sẽ gặp trở ngại.
2.1.3. Các dạng câu trả lời nhanh của Google
Google thường xử lý và trả lời các câu hỏi theo 3 dạng câu trả lời bao gồm: câu trả lời trực tiếp, câu trả lời ngắn, câu trả lời dài:
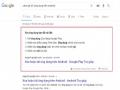
- Câu trả lời trực tiếp thường sẽ là các câu hỏi có chứa các từ: “ai”, “cái gì”, “ở đâu”, “khi nào”… Đối với những câu hỏi thế này Google sẽ cung cấp một câu trả lời trực tiếp từ một nguồn đáng tin cậy và mang nội dung lên trên đoạn trích nổi bật để người dùng có thể thấy nhanh nhất.
Hình 8: Câu trả lời trực tiếp của Google
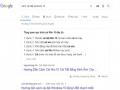
- Câu trả lời ngắn thường xuất hiện những cụm từ như: “tại sao”, “có thể”… Các thông tin sẽ được Google tính toán theo các tiêu chí để chọn ra một câu trả lời ngắn tốt nhất và hiển thị vào đoạn trích nổi bật.
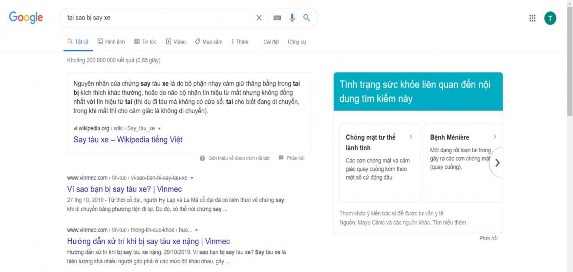
Hình 9: Câu trả lời ngắn của Google
- Câu trả lời dài: thường xuất hiện với các cụm từ như: “làm thế nào”, “cách để”, “tại sao”… Các câu trả lời ở dạng này sẽ thường có thông tin chi tiết cho người dùng có thể hình dung được cụ thể được thông tin mà họ đang tìm kiếm.
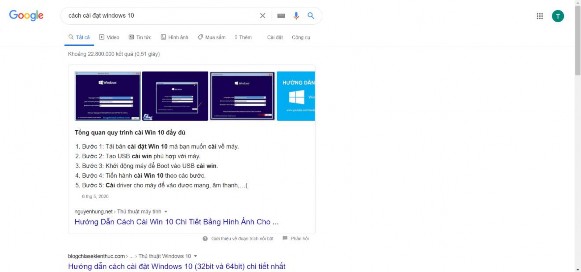
Hình 10: Câu trả lời dài của Google