gồm một số amino acid mang tính kiềm được mã hóa b i một chuỗi oligonucleotide, đó là điểm cắt của enzym protease, đây là vùng quyết định độc lực của virus (Bosch và cs, 1981; Gambotto và cs, 2008). Protein HA có khối lượng phân tử khoảng 63.103 Da (nếu không được glycosyl hóa) và .103 Da (nếu được glycosyl hóa, trong đó HA1 là 48.103 Da và HA2 là 29.103 Da) (Keawcharoen và cs, 200 ; Luong và Palese, 1992).
- hân đoạn 5 (gen NP) kích thước khoảng 1 6 bp, mã hóa tổng hợp nucleoprotein (NP) - thành phần của phức hệ phiên mã, chịu trách nhiệm vận chuyển NA giữa nhân và bào tương tế bào chủ. NP là một protein được glycosyl hóa, có đặc tính kháng nguyên biểu hiện theo nhóm virus, tồn tại trong các hạt virus dạng kết hợp với mỗi phân đoạn NA, có khối lượng phân tử theo tính toán khoảng 6.103 Da (trên thực tế là 0 - 60.103 Da) (Luong và Palese, 1992; urphy và Webster, 1996; ӧmer-Oberdӧrfer và cs, 2008).
- hân đoạn 6 (gen NA) là một gen kháng nguyên của virus, có chiều dài thay đổi theo từng chủng virus cúm A ( A H6N2 là 1413 bp, A H N1 thay đổi khoảng từ 13 0 - 1410 bp) (Lê Thanh Hòa, 2004). Đây là gen mã hóa tổng hợp protein NA, kháng nguyên bề mặt capsid của virus, có khối lượng phân tử theo tính toán khoảng 0.103 Da (trên thực tế là 0 - 60.103 Da). Các nghiên cứu phân tử gen NA của virus cúm cho thấy phần đầu ’- của gen này (hay phần tận cùng N của polypeptide NA) có tính biến đổi cao và phức tạp giữa các chủng virus cúm A, sự thay đổi này liên quan đến quá trình thích ứng và gây bệnh của virus cúm trên nhiều đối tượng vật chủ khác nhau (Castrucci và Kawaoka, 1993; Baigent và c Cauley, 2001; Uiprasertkul và cs 200 ). Đặc trưng biến đổi của gen NA trong virus cúm A là hiện tượng đột biến trượt-xóa một đoạn gen là nucleotide, rồi sau đó là 60 nucleotide, làm cho độ dài vốn có trước đây của NA(N1) là 1410 bp còn 13 0 bp (Castrucci và Kawaoka, 1993; Lê Thanh Hòa, 2006; Kaewcharoen và cs, 200 ).
Các phân đoạn gen , NP và NS mã hóa tổng hợp các protein chức năng khác nhau của virus, có độ dài tương đối ổn định giữa các chủng virus cúm A, bao gồm:
- hân đoạn 7 (gen ) có kích thước khoảng 102 bp, mã hóa cho protein đệm (matrix protein - ) của virus (gồm hai tiểu phần là 1 và 2 được tạo ra b i những khung đọc m khác nhau của cùng một phân đoạn NA), cùng với HA và NA có khoảng 3000 phân tử P trên bề mặt capsid của virus cúm A, có mối quan hệ tương tác bề mặt với hemagglutinin (Scholtissek và cs, 2002). Protein 1 là một protein nền, là thành phần chính của virus có chức năng bao bọc NA tạo nên phức hợp NP và tham gia vào quá trình “nảy chồi” của virus (Luong và Palese, 1993; urphy và Webster, 1996; Basler, 200 ). Protein 2 là chuỗi polypeptide bé, có khối lượng phân tử theo tính toán là 11.103 Da (trên thực tế là 1 .103 Da), là protein chuyển màng - kênh ion (ion channel) cần thiết cho khả năng lây nhiễm của virus, chịu trách nhiệm “c i áo” virus trình diện hệ gen bào tương tế bào chủ trong quá trình xâm nhiễm trên vật chủ (Scholtissek và cs, 2002).
- hân đoạn 8 (gen NS), là gen mã hóa protein không cấu trúc (non structural protein), có độ dài ổn định nhất trong hệ gen của virus cúm A, kích thước khoảng 890 bp, mã hóa tổng hợp hai protein là NS1 và NS2 (còn gọi là NEP, nuclear export protein), có vai trò bảo vệ hệ gen của virus nếu thiếu chúng virus sinh ra sẽ bị thiểu năng ( urphy và Webster, 1996; Sekellick và cs, 2000). Độc tính của virus có sự liên quan với gen không cấu trúc (non-structural gen) này được tìm thấy biến chủng A H N1 9 (Tian và cs, 200 ), trong tự nhiên, việc đột biến xóa đi một phần gen có liên quan đến giảm độc lực (Zhou và cs, 2007). NS1 có khối lượng phân tử theo tính toán là 2 .103 Da (trên thực tế là
25.103 Da), chịu trách nhiệm vận chuyển NA thông tin của virus từ nhân ra bào tương tế bào nhiễm, và tác động lên các NA vận chuyển cũng như các quá trình cắt và dịch mã của tế bào chủ. NEP hay NS2, là gen hình thành từ hai đoạn gen (30 bp và 336 bp) mã hóa loại protein có khối lượng phân tử theo tính toán khoảng 14.103 Da (trên thực tế là 12x103 Da), đóng vai trò vận chuyển các NP của virus ra khỏi nhân tế bào nhiễm để lắp ráp với capsid tạo nên hạt virus mới (Sekellick và cs, 2000; Zhu và cs, 2008).
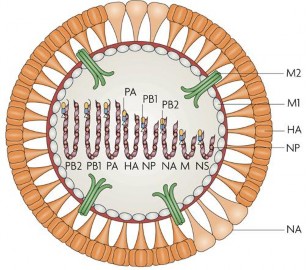
Hình 1.4. M hình hệ gen i c A (St bb, 1965
Có thể bạn quan tâm!
-

 Nghiên cứu một số đặc tính sinh học của vi rút cúm A/H5N1 Clade 7 phân lập ở Việt Nam - 1
Nghiên cứu một số đặc tính sinh học của vi rút cúm A/H5N1 Clade 7 phân lập ở Việt Nam - 1 -
 Nghiên cứu một số đặc tính sinh học của vi rút cúm A/H5N1 Clade 7 phân lập ở Việt Nam - 2
Nghiên cứu một số đặc tính sinh học của vi rút cúm A/H5N1 Clade 7 phân lập ở Việt Nam - 2 -
 Bi Đồ Bi U Diễn Dịch C Gi Cầ Do I C A/h5N1 Theo Thời Gi N (Cục Th Y, 2012)
Bi Đồ Bi U Diễn Dịch C Gi Cầ Do I C A/h5N1 Theo Thời Gi N (Cục Th Y, 2012) -
 Đặc Đi Tiến Hó À Hình Thành Genotype Củ I C Gi Cầ Gi I Đoạn 1996-2008
Đặc Đi Tiến Hó À Hình Thành Genotype Củ I C Gi Cầ Gi I Đoạn 1996-2008 -
 C C Genotype Củ I C Gi Cầ A/h5N1 Đ C Lực Cao (Li À C , 2007)
C C Genotype Củ I C Gi Cầ A/h5N1 Đ C Lực Cao (Li À C , 2007) -
 Kết Quả Tiê Phòng Vacxin C Gi Cầ Chương T Ình Q C Gia
Kết Quả Tiê Phòng Vacxin C Gi Cầ Chương T Ình Q C Gia
Xem toàn bộ 162 trang tài liệu này.
Các phân đoạn 4 và 6 mã hóa cho các protein (HA và NA) bề mặt capsid của virus, có tính kháng nguyên đặc trưng theo từng chủng virus cúm A. Nói cách khác protein HA và NA cho phép xác định subtype của virus cúm A nói chung và virus cúm gia cầm nói riêng.
Như vậy, virus cúm A (c thể: cúm A/H5N1 ) có hệ gen được cấu trúc từ 8 phân đoạn riêng biệt và không có gen mã hóa enzyme sửa chữa NA, tạo điều kiện thuận lợi cho sự xuất hiện các đột biến điểm trong các phân đoạn gen hệ gen qua quá trình sao chép nhân lên của virus, hoặc trao đổi các phân đoạn gen giữa các chủng virus cúm đồng nhiễm trên cùng một tế bào, rất có thể dẫn đến thay đổi đặc tính kháng nguyên tạo nên các chủng virus cúm A mới (Suarez và Schultz-Cherry, 2000).
1.3.2. Kh ng ng yên củ i c gi cầ
Virus cúm type A được xác định subtype dựa trên cơ s kháng nguyên (protein) bề mặt là HA (Hemagglutinin-viết tắt là H) và NA (Neuraminidase-viết tắt là N) có vai trò quan trọng trong miễn dịch bảo hộ. Hemagglutinin được coi là yếu tố vừa quyết định tính kháng nguyên, vừa quyết định độc lực của virus cúm A.
1.3.2.1. Protein HA (Hemagglutinin)
Protein hemagglutinin là một glycoprotein thuộc protein màng type I (lectin), có khả năng gây ngưng kết hồng cầu gà trong ống nghiệm (in vitro), kháng thể đặc hiệu với HA có thể phong tỏa sự ngưng kết đó, được gọi là kháng
thể ngăn tr ngưng kết hồng cầu (HI- Hemagglutinin Inhibitory antibody). Có 16 subtype HA đã được phát hiện (H1 - H16), subtype H16 mới được tìm thấy virus gây bệnh cho hải âu đầu đen - Th y Điển, 1999), ba subtype (H1, H2 và H3) thích ứng lây nhiễm gây bệnh người liên quan đến các đại dịch cúm trong lịch sử ( urphy và Webster, 1996). Có khoảng 400 phân tử HA trên bề mặt capsid của một virus, có vai trò quan trọng trong quá trình nhận diện virus và kh i động quá trình xâm nhiễm của virus vào tế bào chủ (Bender và cs, 1999; Wagner và cs, 2002). Phân tử HA có dạng hình tr , dài khoảng 130 ăngstron (Å), cấu tạo gồm 3 đơn phân (trimer), mỗi đơn phân (monomer) được tạo thành từ hai tiểu đơn vị HA1 (36 kDa) và HA2 (2 kDa), liên kết với nhau b i các cầu nối disulfide (-S-S-). Các đơn phân sau khi tổng hợp đã được glycosyl hóa (glycosylation) và gắn vào mặt ngoài capsid là tiểu đơn vị HA2, phần đầu tự do hình chỏm cầu được tạo b i dưới đơn vị HA1 chứa đựng vị trí gắn với th thể thích hợp của HA trên bề mặt màng tế bào đích (Bosch và cs, 1981; Wagner và cs, 2002).
Hình 1.5. M ph ng cấ t c kh ng ng yên H e l tinin à Neuraminidase (www.aht.org.uk)
Sự kết hợp của HA với th thể đặc hiệu (glycoprotein chứa sialic acid) trên bề mặt màng tế bào, kh i đầu quá trình xâm nhiễm của virus trên vật chủ giúp cho virus xâm nhập, hòa màng và giải phóng NA hệ gen thực hiện quá
trình nhân lên trong tế bào cảm nhiễm. Quá trình kết hợp ph thuộc vào sự phù hợp cấu hình không gian của th thể chứa acid sialic của tế bào đích với vị trí gắn với th thể này trên phân tử HA của virus cúm, quyết định sự xâm nhiễm dễ dàng của virus các loài vật chủ khác nhau (Wagner và cs, 2002; Wasilenko và cs, 2008). Vị trí amino acid 226 (aa226) của HA1 được xác định là vị trí quyết định phù hợp gắn HA với th thể đặc hiệu của nó, hầu hết các chủng virus cúm A lưu hành trong tự nhiên vị trí này là Glycine, thích ứng với th thể Gal α-2,3 sialic acid (chứa sialic acid liên kết với nhóm hydroxyl (4-OH) của galactose góc quay α-2,3) của tế bào biểu mô đường hô hấp của chim và gia cầm (vật chủ tự nhiên của virus cúm A). Ngoài ra, một số vị trí amino acid khác: Glutamine 222, Glycine 224, hay cấu trúc SGVSS và NGQSG cũng có sự liên quan chặt chẽ đến khả năng thích ứng với th thể chứa sialic acid bề mặt màng tế bào chủ (Luong và Palese, 1993). Đặc biệt, một số chủng virus cường độc A H Nx; A H Nx lưu hành hiện nay có thể xâm nhiễm trên người, khi chúng có tải lượng cao trong đường hô hấp (do tiếp xúc trực tiếp với chất thải hay gia cầm nhiễm bệnh) (Bauer và cs, 2006; Hui, 2008; Wasilenko và cs, 2008).
Trình tự mã hóa chuỗi nối, và thành phần chuỗi nối trên protein HA cũng như các vị trí amino acid liên quan đến khả năng gắn với th thể thích ứng, được coi là các chỉ thị phân tử trong nghiên cứu phân tích gen kháng nguyên HA (Luong và Palese, 1993). Protein HA còn là kháng nguyên bề mặt quan trọng của virus cúm A, kích thích cơ thể sinh ra đáp ứng miễn dịch dịch thể đặc hiệu với từng type HA, và tham gia vào phản ứng trung hòa virus, được coi là protein vừa quyết định tính kháng nguyên, vừa quyết định độc lực của virus, là đích của bảo vệ miễn dịch học nh m ngăn chặn sự xâm nhiễm của virus cơ thể nhiễm, cơ s điều chế các vacxin phòng cúm hiện nay (Bosch và cs, 198; Horimoto và Kawaoka, 2001; atrosovich và cs, 1999).
1.3.2.2. Protein NA (neuraminidase)
Protein neurominidase còn gọi là sialidase (mã số quốc tế là E.C 3.2.1.18), là một protein enzyme có bản chất là glycoprotein được gắn trên bề mặt capsid
của virus cúm A, mang tính kháng nguyên đặc trưng theo từng subtype NA (Baigent và c Cauley, 2001; Uiprasertkul và cs, 2007). Có 9 subtype (từ N1 đến N9) được phát hiện chủ yếu virus cúm gia cầm, hai subtype N1 và N2 được tìm thấy virus cúm người liên quan đến các đại dịch cúm trong lịch sử (Wasilenko và cs, 2008). Có khoảng 100 phân tử NA xen giữa các phân tử HA trên bề mặt capsid hạt virus. Phân tử NA có dạng nút lồi hình nấm, đầu tự do (chứa vùng hoạt động) gồm 4 dưới đơn vị giống như hình cầu n m trên cùng một mặt phẳng, và phần kị nước gắn vào vỏ capsid (Castrucci và Kawaoka, 1993).
Protein NA có vai trò là một enzyme cắt đứt liên kết giữa gốc acid sialic của màng tế bào nhiễm với phân tử cacbonhydrate của protein HA, giải phóng hạt virus ra khỏi màng tế bào nhiễm, đẩy nhanh sự lây nhiễm của virus trong cơ thể vật chủ, và ngăn cản sự tập hợp của các hạt virus mới trên màng tế bào. ặt khác, NA tham gia vào phân cắt liên kết này trong giai đoạn “hòa àng”, đẩy nhanh quá trình c i áo “uncoating” giải phóng hệ gen của virus vào trong bào tương tế bào nhiễm, giúp cho quá trình nhân lên của virus diễn ra nhanh hơn (Uiprasertkul và cs, 200 ). Ngoài ra, NA còn phân cắt các liên kết glycoside, giải phóng neuraminic acid làm tan loãng màng nhầy bề mặt biểu mô đường hô hấp, tạo điều kiện cho virus nhanh chóng tiếp cận tế bào biểu mô và thoát khỏi các chất ức chế không đặc hiệu. Cùng với vai trò của kháng nguyên HA, cả 3 khâu tác động trên của NA đều tham gia làm gia tăng độc lực gây bệnh của virus cúm A cơ thể vật chủ. Do đó, NA là đích tác động của các thuốc, hóa dược ức chế virus không đặc hiệu hiện nay, đặc biệt là Oseltamivir (biệt dược là Tamiflu) phong tỏa enzyme này, ngăn cản sự giải phóng hạt virus mới khỏi các tế bào đích, bảo vệ cơ thể (Aoki và cs, 200 ; Castrucci và Kawaoka, 1993).
Bên cạnh đó, NA còn là một kháng nguyên bề mặt của virus, tham gia kích thích hệ thống miễn dịch của cơ thể chủ, sinh ra kháng thể đặc hiệu với kháng nguyên NA của các chủng virus đương nhiễm có tác d ng phong tỏa protein NA (Doherty và cs, 2006). Như vậy, kháng nguyên NA cùng với kháng nguyên HA của virus là các đích chủ yếu của cơ chế bảo hộ miễn dịch của cơ thể
với virus cúm A, và là cơ s điều chế các vacxin phòng cúm hiện nay cho người và gia cầm, nh m ngăn chặn dịch cúm gia cầm và hạn chế lây truyền sang người (Suarez và Schultz-Cherry, 2000; Wu và cs, 2008).
1.3.2.3. C c phương thức biến đổi kh ng ng yên
Có ba phương thức chủ yếu làm biến đổi kháng nguyên virus cúm A (Wu và cs, 2008).
a. Hiện tượng lệch kháng nguyên
Lệch kháng nguyên (antigenic drift) thực chất là các đột biến điểm xảy ra các phân đoạn gen hệ gen của virus. Do virus cúm A kí sinh nội bào bắt buộc, không có cơ chế “đọc và sửa bản sao - proof reading” trong quá trình phiên mã và sao chép nhân tế bào đích. Sự thiếu h t enzyme sửa chữa NA dẫn đến các enzyme sao chép ph thuộc NA sẽ có thể “gài” thêm (đột biến giãn nở), làm mất đi hoặc thay thế (đột biến trượt-xóa) (Lê Thanh Hòa và cs, 2006) một hay nhiều nucleotide mà không được sửa chữa trong phân tử NA chuỗi đơn mới của virus (Conenello và cs, 200 ; urphy và Webster, 1996). Tuỳ thuộc vị trí xảy ra các đột biến trong bộ ba mã hóa, mà có thể trực tiếp làm thay đổi các amino acid trong trình tự của protein được mã hóa biểu hiện, dẫn đến thay đổi thuộc tính của protein, hoặc được tích lũy trong phân đoạn gen xảy ra đột biến (đột biến điểm). Tần suất xảy ra đột biến điểm rất cao, cứ mỗi 10.000 nucleotide (tương ứng với độ dài của NA hệ gen của virus cúm A) thì có 1 nucleotide sai khác (Prel và cs, 2008; Wagner và cs, 2002). Như vậy, gần như mỗi hạt virus mới được sinh ra đều chứa đựng một đột biến điểm trong hệ gen của nó, và các đột biến này được tích lũy qua nhiều thế hệ virus sẽ làm xuất hiện một subtype virus mới có những đặc tính kháng nguyên mới có thể bị sai lệch (Hình 1.6).
Hiện tượng này thường xảy ra các phân đoạn gen kháng nguyên NA và HA, tạo ra các bộ mã tổng hợp các amino acid mới, hoặc làm thay đổi cấu trúc dẫn đến thay đổi đặc tính của protein đó, hoặc có khả năng glycosyl hóa rất cao trong cấu trúc chuỗi polypeptide kháng nguyên, tạo ra một biến thể virus mới thay đổi độc lực gây bệnh hay đặc tính kháng nguyên mới (Wasilenko và cs, 2008, acken và cs, 2006; Chen và cs, 2008).
b. Hiện tượng trộn kháng nguyên
Hiện tượng trộn kháng nguyên (còn gọi là trao đổi hay tái tổ hợp) các gen kháng nguyên (antigenic shift) chỉ có virus cúm, và rất ít một số virus NA gây bệnh gia cầm khác, cho phép virus có khả năng biến chủng rất cao. Hệ gen gồm 8 phân đoạn gen riêng biệt của virus cúm A được 2 chủng virus cúm A khác nhau khi đồng nhiễm trong một tế bào trao đổi cho nhau, để có thể xảy ra sự hoà trộn (reassort) hoặc trao đổi (swap) các phân đoạn gen của hai chủng virus đó trong quá trình kết hợp lại NA hệ gen, tạo ra các trạng thái khác nhau của NA hệ gen của các hạt virus mới từ hai NA hệ gen của những virus ban đầu. Kết quả là đã tạo ra thế hệ virus mới có các phân đoạn gen kết hợp, và đôi khi giúp cho chúng có khả năng lây nhiễm loài vật chủ mới hoặc gia tăng độc lực gây bệnh (Hình 1. ) (Hilleman, 2002; acken và cs, 2006; Chen và cs, 2006).
c. Hiện tượng glycosyl hóa
Glycosyl hóa (glycosylation) là sự gắn kết của một chuỗi carbonhydrate (oligosaccharide) vào với amino acid Asparagine (N) một số vị trí nhất định trong chuỗi polypeptide HA hay NA, hay một số polypeptide khác của virus cúm. Thông thường chuỗi oligosaccharide được gắn tại vị trí N-X-S/T (N = Asparagine; X = amino acid bất kì, trừ Proline; S T = Serine hoặc Threonine) (Baigent và cCauley, 2001). Đây là những vị trí được cho là gắn kết với các kháng thể được cơ thể sinh ra do kích thích của kháng nguyên, nh m bảo vệ cơ thể nhiễm. Hiện tượng lệch kháng nguyên sinh ra đột biến điểm hình thành bộ mã của Asparagine, tạo tiền đề cho hiện tượng glycosyl hóa xảy ra khi tổng hợp chuỗi polypeptide HA hay NA, làm thay đổi biểu hiện đặc tính kháng nguyên của HA và NA, giúp cho virus thoát khỏi tác động miễn dịch bảo hộ của cơ thể chủ và điều hoà sự nhân lên của virus (Baigent và McCauley, 2001).
Hiện tượng “lệch kháng nguyên” và “glycosyl hóa” xảy ra liên t c theo thời gian, còn hiện tượng “trộn kháng nguyên” có thể xảy ra với tất cả các chủng của virus cúm A, khi đồng nhiễm trong một tế bào tất cả các loài vật chủ khác nhau. Đây cũng chính là vấn đề đáng lo ngại của virus cúm A/H5N1 hiện nay, mặc dù virus này chưa có sự thích nghi lây nhiễm dễ dàng người, nhưng nó có khả năng gây bệnh được cho người, và rất có thể A H N1 tái tổ hợp (vay ượn) gen HA hay