ROA | 𝐿ợ𝑖 𝑛ℎ𝑢ậ𝑛 𝑡𝑟ướ𝑐 𝑡ℎ𝑢ế 𝑇ổ𝑛𝑔 𝑡à𝑖 𝑠ả𝑛 | +/- | http://www.cophieu68.vn / và http://vietstock.vn/ | |
Tỷ lệ an toàn vốn cấp 1 | CAR1 | 𝑁𝑔𝑢ồ𝑛 𝑣ố𝑛 𝑡ự 𝑐ó 𝑇ổ𝑛𝑔 𝑡à𝑖 𝑠ả𝑛 𝑟ủ𝑖 𝑟𝑜 | - | http://www.cophieu68.vn / và http://vietstock.vn/ |
Tính thanh khoản | LIQ | Tài sản thanh khoản 𝑇ổ𝑛𝑔 𝑡à𝑖 𝑠ả𝑛 | - | http://www.cophieu68.vn / và http://vietstock.vn/ |
Lấy giá trị GDP danh | ||||
GDP thực | GDP | nghĩa điều chỉnh theo chỉ số CPI, lấy năm | +/- | Trang web thomsonreuters.com |
2010 là năm gốc | ||||
Được tính theo tốc độ | ||||
Lạm phát | INF | tăng trưởng của chỉ số giá hàng tiêu dùng (CPI), lấy năm 2010 là | - | International Financial Statistics (IFS) |
năm gốc | ||||
Tỷ lệ thất nghiệp | UNEM P | - | Tổng cục Thống kê Việt Nam (gso.gov.vn) | |
Chỉ số thị trường chứng khoán VN_Index | CK | Lấy Logarithm của giá trị đóng cửa đã được điều chỉnh chỉ số VN_Index trong ngày cuối cùng của quý | +/- | Trang web stockbiz.vn |
Có thể bạn quan tâm!
-

 Các Nhân Tố Tác Động Đến Tăng Trưởng Tín Dụng Cho Vay
Các Nhân Tố Tác Động Đến Tăng Trưởng Tín Dụng Cho Vay -
 Các Yếu Tố Bên Trong Tác Động Đến Tốc Độ Tăng Trưởng Tín Dụng Của Các Ngân Hàng Thương Mại
Các Yếu Tố Bên Trong Tác Động Đến Tốc Độ Tăng Trưởng Tín Dụng Của Các Ngân Hàng Thương Mại -
 Tổng Hợp Tác Động Của Các Nhân Tố Vĩ Mô Đến Hoạt Động Tín Dụng Của Các Ngân Hàng Thương Mại Trong Các Nghiên Cứu Trước Đây.
Tổng Hợp Tác Động Của Các Nhân Tố Vĩ Mô Đến Hoạt Động Tín Dụng Của Các Ngân Hàng Thương Mại Trong Các Nghiên Cứu Trước Đây. -
 Tương Quan Pearson – Mối Tương Quan Đơn Biến Giữa Các Biến Số
Tương Quan Pearson – Mối Tương Quan Đơn Biến Giữa Các Biến Số -
 Các yếu tố ảnh hưởng đến tốc độ tăng trưởng tín dụng ở các ngân hàng thương mại Việt Nam - 8
Các yếu tố ảnh hưởng đến tốc độ tăng trưởng tín dụng ở các ngân hàng thương mại Việt Nam - 8 -
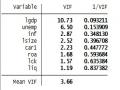 Các yếu tố ảnh hưởng đến tốc độ tăng trưởng tín dụng ở các ngân hàng thương mại Việt Nam - 9
Các yếu tố ảnh hưởng đến tốc độ tăng trưởng tín dụng ở các ngân hàng thương mại Việt Nam - 9
Xem toàn bộ 80 trang tài liệu này.

Nguồn: Tổng hợp của tác giả
3.4. Các phương pháp hồi quy sử dụng trong bài luận văn
Trong luận văn này, tác giả sử dụng phương pháp phân tích dữ liệu theo dạng bảng. Theo Gujarati, phương pháp dữ liệu bảng có một số ưu điểm hơn so với dữ liệu chuỗi thời gian và dữ liệu chéo trong việc phân tích dữ liệu. Cụ thể như sau:
- Dữ liệu bảng có thể xem xét được tính không đồng nhất của các đối tượng trong mẫu dữ liệu thu thập. Trong trường hợp này, tác giả có thể xem xét được tính đặc thù của các biến số theo từng đối tượng khảo sát. Các đối tượng khảo sát ở đây có thể là từng cá nhân, doanh nghiệp, quốc gia…
- Do dữ liệu bảng là sự kết hợp các chuỗi dữ liệu theo không gian và thời gian nên các thông tin thu thập từ việc khảo sát sẽ trở nên đa dạng hơn. Ngoài ra, trong dữ liệu bảng, khả năng xảy ra hiện tượng đa cộng tuyến giữa các biến số cũng sẽ ít hơn.
- Sử dụng dữ liệu bảng trong việc phân tích sẽ giúp mở rộng số quan sát hơn. Trong một số trường hợp của chuỗi thời gian (thường là các chuỗi dữ liệu theo năm), dữ liệu thường sẽ bị hạn chế về số lượng quan sát. Khi đó, việc sử dụng các dữ liệu dạng bảng sẽ giúp mở rộng hơn số quan sát thông qua đặc tính mở rộng về mặt không gian dữ liệu. Điều này sẽ giúp giảm thiểu sự sai lệch trong các ước tính.
Thông thường, khi thực hiện hồi quy dữ liệu dạng bảng, có 03 phương pháp phân tích thường được sử dụng là phương pháp hồi quy OLS gộp (Pooled OLS), mô hình các ảnh hưởng cố định (Fixed Effective Model – FEM) và mô hình các ảnh hưởng ngẫu nhiên (Random Effective Model – REM). Đây là các phương pháp truyền thống trong phân tích dữ liệu bảng, được sử dụng trong hầu hết các nghiên cứu. Do đó, trong luận văn này, tác giả cũng sẽ sử dụng 03 phương pháp này để ước lượng, phân tích đánh giá tác động của các nhân tố vĩ mô đến tỷ suất sinh lợi của các ngân hàng thương mại trong nước.
3.4.1. Mô hình Pooled OLS
Đây là phương pháp tiếp cận bình phương bé nhất thông thường trong hồi quy dữ liệu bảng. Phương pháp này sẽ bỏ qua các đặc tính về không gian và thời gian của các chuỗi dữ liệu dạng bảng. Nói cách khác, phương pháp này sẽ không xem xét các đặc tính về không gian và thời gian của các đối tượng trong mẫu khảo sát. Tuy nhiên, thông thường phương pháp này dễ xảy ra hiện tượng tự tương quan giữa các chuỗi dữ liệu (điều này được thể hiện qua giá trị thống kê Durbin Watson khá thấp)
3.4.2. Mô hình các ảnh hưởng cố định (Fixed Effective Model – FEM)
Mô hình các ảnh hưởng cố định xem xét đặc điểm của các chuỗi dữ liệu theo đơn vị không gian (tính đặc thù riêng của từng đối tượng trong mẫu dữ liệu). Do đó, giá trị tung độ gốc sẽ thay đổi theo từng đối tượng nhưng hệ số độ dốc vẫn được giả định là hằng số đối với các đối tượng
Đặt Yi,t = (Y1,i,…, Yn,i ) đại diện cho biến phụ thuộc của n đối tượng trong i năm; Xi,t = (x1,i, …, xn,i) là đại diện cho các biến độc lập của n đối tượng trong i năm. Khi đó, mô hình ước lượng sẽ có dạng như sau:
𝑌𝑖,𝑡 = 𝛽1𝑖 + 𝛽2𝑋𝑖,𝑡 + 𝑢𝑖,𝑡 (1)
Ký hiệu i trong tung độ gốc cho thấy sự khác nhau trong tung độ gốc của các. Sự khác biệt này sẽ phản ánh đặc điểm riêng của từng đối tượng. Giá trị tung độ gốc của mỗi đối tượng không thay đổi theo thời gian (bất biến theo thời gian)
Về mặt kỹ thuật, so với mô hình Pooled OLS, mô hình FEM đưa thêm biến giả theo công ty để xem xét xem có sự khác biệt giữa các đối tượng trong mẫu khảo sát hay không. Do đó, nếu biến giả đưa thêm vào không có ý nghĩa thống kê, mô hình FEM sẽ chính là mô hình Pooled OLS
3.4.3. Mô hình các ảnh hưởng ngẫu nhiên (Random Effective Model
– REM)
Theo Gujarati, việc đưa thêm biến giả vào mô hình sẽ làm mất đi một bậc tự do của dữ liệu. Ngoài ra, theo ông, những người làm nghiên cứu có thể đưa một sai số ước tính vào trong mô hình để biểu thị sự khác biệt về tung độ gốc giữa các đối tượng thay cho việc đưa biến giả này. Khi đó, mô hình (1) sẽ được biểu thị như sau:
𝑌𝑖,𝑡 = 𝛽1𝑖 + 𝛽2𝑋𝑖,𝑡 + 𝑢𝑖,𝑡 (2)
Với 𝛽1𝑖 = 𝛽1 + 𝑒𝑖 i = 1, 2, …, n
𝑒
Trong đó, 𝑒𝑖 là sai số ngẫu nhiên với một giá trị trung bình bằng 0 và phương sai bằng 𝜎2
Khi đó, các đối tượng trong mẫu khảo sát sẽ có sự khác biệt với nhau về thành phần 𝑒𝑖. Các 𝑒𝑖 này là các giá trị không quan sát được. Các giá trị 𝑒𝑖 này không có tương quan với nhau và không bị tự tương quan giữa các đơn vị theo không gian và thời gian.
Trong trường hợp này, giá trị phương sai của sai số trong các ước tính sẽ bao gồm 2 thành phần là 𝜎2 và 𝜎2. Nếu 𝜎2 = 0 thì tức là không có sự khác biệt
𝑢 𝑒 𝑒
giữa mô hình Pooled OLS và mô hình REM.
Giữa mô hình FEM và mô hình REM, Hausman (1978) đã xây dựng một kiểm định nhằm xem xét việc lựa chọn giữa hai mô hình này. Giả thiết H0: không có sự khác biệt đáng kể giữa mô hình FEM và mô hình REM (trong trường hợp này lựa chọn mô hình REM). Nói cách khác, trong trường hợp này, tung độ gốc (ngẫu nhiên) của từng đơn vị không tương quan với các biến độc lập. Khi bác bỏ giả thiết H0 tức là có sự khác biệt đáng kể giữa mô hình FEM và mô hình REM (khi đó mô hình FEM tốt hơn), tức là tung độ gốc của từng cá nhân có thể tương quan với một hay nhiều biến độc lập
CHƯƠNG 4: KẾT QUẢ NGHIÊN CỨU VÀ THẢO LUẬN KẾT QUẢ
Trong chương này, tác giả sẽ trình bày các kết quả nghiên cứu của luận văn. Đầu tiên, tác giả sẽ thực hiện thống kê mô tả dữ liệu để xem xét tổng quan về các dữ liệu trong bài nghiên cứu. Sau đó, tác giả sẽ đi vào phân tích mối quan hệ đơn biến trong cùng thời điểm giữa các biến số trong mô hình nghiên cứu, trong đó, tác giả sẽ tập trung xem xét mối quan hệ của các biến số độc lập đến biến phụ thuộc thông qua các hệ số tương quan Pearson. Tiếp theo đó, tác giả sẽ xem xét tác động của các biến số độc lập đến biến phụ thuộc trong mô hình hồi quy đa biến. Mô hình hồi quy đa biến sẽ được ước tính bằng 03 phương pháp phân tích dữ liệu dạng bảng: Phương pháp hồi quy OLS gộp (Pooled OLS); phương pháp mô hình các ảnh hưởng cố định – Fixed Effective Model (FEM) và phương pháp mô hình các ảnh hưởng ngẫu nhiên – Random Effective Model (REM)). Sau đó, tác giả thực hiện các kiểm định nhằm chọn ra phương pháp hồi quy tốt nhất đối với trường hợp dữ liệu của các ngân hàng thương mại cổ phần Việt Nam, từ đó đưa ra các thảo luận dựa trên kết quả của mô hình hồi quy tốt nhất này
4.1. Phân tích thống kê mô tả về đặc điểm các chuỗi dữ liệu nghiên cứu
Trước khi đi vào thực hiện các ước lượng, tác giả thực hiện thống kê mô tả để đưa ra cái nhìn toàn diện về dữ liệu, từ đó giúp tác giả phát hiện được những quan sát sai khác trong cỡ mẫu. Kết quả thống kê mô tả được trình bày trong bảng 4.1 dưới đây
Bảng 4.1. Kết quả thống kê mô tả | ||||||
Số quan | Trung | Độ lệch | ||||
sát | bình | chuẩn | ||||
GCR | % | 200 | 0,213 | 0,189 | -0,465 | 0,919 |
GDP | Ngàn tỷ đồng | 200 | 2.280 | 491 | 1.630 | 3.050 |
INF | % | 200 | 9,099 | 6,474 | 0,630 | 23,118 |
UNEMP | % | 200 | 3,765 | 0,731 | 2,30 | 4,65 |
CK | Điểm | 200 | 549,117 | 172,370 | 417,425 | 1.017,473 |
SIZE | Tỷ đồng | 200 | 146.000 | 180.000 | 3.480 | 1.010.000 |
ROA | Tỷ lệ | 200 | 0,011 | 0,007 | 0,000 | 0,052 |
CAR1 | Tỷ lệ | 200 | 0,099 | 0,045 | 0,043 | 0,293 |
LIQ | Tỷ lệ | 200 | 0,019 | 0,023 | 0,003 | 0,129 |
Biến ĐVT Nhỏ nhất Lớn nhất
Nguồn: Tác giả tổng hợp từ phân tích trên Phần mềm Eviews.
Ghi chú: Các biến trong bảng kết quả lần lượt tương ứng như sau: GCR: Biến phụ thuộc thể hiện tốc độ tăng trưởng tín dụng của các ngân hàng; GDP: Tổng sản lượng quốc nội thực – biến độc lập; INF: Tỷ lệ lạm phát – biến độc lập; UNEMP: Tỷ lệ thất nghiệp của nền kinh tế – biến độc lập; CK: Chỉ số thị trường chứng khoán – biến độc lập; ROA: Tỷ suất sinh lợi trên tổng tài sản – biến độc lập; LSIZE: Logarithm tự nhiên của quy mô ngân hàng – biến độc lập; CAR1: Tỷ lệ an toàn vốn cấp 1 – biến độc lập; LIQ: Tính thanh khoản của ngân hàng – biến độc lập . Trong ngoặc () là kết quả của giá trị thống kê p – value. Ký hiệu *,** và *** cho thấy các biến số có ý nghĩa thống kê lần lượt ở mức 10%, 5% và 1%
Kết quả thống kê mô tả giữa các biến số theo bảng 4.1 của 20 ngân hàng trong 10 năm (tương ứng 200 quan sát) cho thấy:
Giá trị trung bình của biến phụ thuộc GCR là 0,213, giá trị nhỏ nhất là -0,465, giá trị lớn nhất là 0,919 và độ lệch chuẩn là 0,189. Điều này cho thấy mức tăng trưởng tín dụng cho vay trung bình hàng năm của một ngân hàng thương mại cổ phần trong mẫu khảo sát là 21,3%. Mức tăng trưởng tín dụng cao nhất của 1 ngân hàng thương mại trong một năm là 91,9% (Mã ngân hàng NVB năm 2007); tuy nhiên ở một số thời điểm nhất định, có ngân hàng thương mại có tăng trưởng tín dụng âm với mức tăng trưởng tín dụng âm cao nhất là -46,5% (Mã ngân hàng SeaBank năm 2008). Ngoài ra, sai lệch trung bình của chỉ số này ở các ngân hàng là 18,9%.
Giá trị trung bình của biến độc lập GDP là 2.280 ngàn tỷ đồng, giá trị nhỏ nhất là 1.630 ngàn tỷ đồng, giá trị lớn nhất là 3.050 ngàn tỷ đồng và độ lệch chuẩn là 491. Điều này cho thấy trung bình giá trị GDP hàng năm của Việt Nam là 2.280 ngàn tỷ đồng. Năm 2007 là năm có GDP thấp nhất với giá trị khoảng 1.630 ngàn tỷ đồng, trong khi năm 2016 là năm có giá trị GDP cao nhất khoảng 3.054 ngàn tỷ đồng. Sai lệch trung bình của GDP so với giá trị trung bình là 491 ngàn tỷ đồng.
Giá trị trung bình của biến độc lập tỷ lệ lạm phát (INF) là khoảng 9,099%/ năm, giá trị nhỏ nhất là khoảng 0,63%/ năm, giá trị lớn nhất là khoảng 23,118%/ năm và độ lệch chuẩn là 6,474%. Điều này cho thấy trung bình tỷ lệ lạm phát hàng năm của Việt Nam là 9,099%. Năm 2008 là năm có tỷ lệ lạm phát cao nhất với giá trị khoảng 23,118%, trong khi năm 2015 là năm có tỷ lệ lạm phát thấp nhất là 0,63%. Sai lệch trung bình của tỷ lệ lạm phát so với giá trị trung bình là 6,474%/ năm.
Giá trị trung bình của biến độc lập tỷ lệ thất nghiệp (UNEMP) là khoảng 3,765%/ năm, giá trị nhỏ nhất là khoảng 2,30%/ năm, giá trị lớn nhất là khoảng 4,65%/ năm và độ lệch chuẩn là 0,731%. Điều này cho thấy trung bình tỷ lệ thất nghiệp hàng năm của Việt Nam là 3,765%. Năm 2008 là năm có tỷ lệ thất nghiệp cao nhất với giá trị khoảng 4,65%, trong khi năm 2016 có tỷ lệ lạm phát thấp nhất là 2,30%.
Giá trị trung bình hàng năm của biến độc lập chỉ số thị trường chứng khoán (CK) là khoảng 549,12 điểm, giá trị nhỏ nhất là khoảng 417,43 điểm, giá trị lớn nhất là khoảng 1.017,47 điểm, độ lệch chuẩn là 172,37 điểm. Điều này cho thấy trung bình chỉ số thị trường chứng khoán của Việt Nam qua các năm là 549,12 điểm. Năm 2012 là năm có chỉ số chứng khoán trung bình thấp nhất là 417,43 điểm, trong khi năm 2007 là năm có số điểm cao nhất với giá trị khoảng 1.017,47 điểm.
Giá trị trung bình của biến độc lập quy mô ngân hàng (SIZE) là 146.000 tỷ đồng với giá trị nhỏ nhất là 3.480 tỷ đồng, giá trị lớn nhất là 1.010.000 tỷ đồng và độ lệch chuẩn là 180.000 tỷ đồng. Điều này cho thấy, trung bình quy mô tổng tài sản của các ngân hàng trong mẫu khảo sát là 146 ngàn tỷ đồng. Ngân hàng có quy mô tổng tài sản cao nhất trong một năm là 1.010 ngàn tỷ đồng (mã ngân hàng BID trong năm 2016); ngân hàng có quy mô tổng tài sản thấp nhất trong một năm là 3,48 ngàn tỷ đồng (ngân hàng MBB năm 2007). Biến động giá trị tài sản so với giá trị trung bình của các ngân hàng trong mẫu khảo sát là 180 ngàn tỷ đồng.
Giá trị trung bình của biến độc lập tỷ suất sinh lợi trên tổng tài sản (ROA) là 0,011, giá trị nhỏ nhất là 0 trong khi giá trị lớn nhất là 0,052. Độ lệch chuẩn của ROA ở các ngân hàng là 0,019. Điều này cho thấy, trung bình tỷ suất sinh lợi trên tổng tài sản của các ngân hàng là 1,1%. Ngân hàng có ROA lớn nhất trong 1 năm là 5,2% (mã ngân hàng SGB trong năm 2010); tuy nhiên cũng có một số ngân hàng có chỉ số ROA rất thấp trong một năm nào đó, thậm chí là gần bằng 0 (ngân hàng NVB năm 2015). Độ lệch chuẩn trung bình của chỉ tiêu này là 0,7%.
Giá trị trung bình của biến độc lập tỷ lệ an toàn vốn cấp 1 (CAR1) là 0,099, giá trị nhỏ nhất là 0,003 trong khi giá trị lớn nhất là 0,129. Độ lệch chuẩn của chỉ tiêu này ở các ngân hàng là 0,023. Điều này cho thấy, trung bình tỷ lệ an toàn vốn cấp 1 của các ngân hàng là 9,9%. Ngân hàng có chỉ số CAR1 lớn nhất là 29,3% (mã ngân hàng ABBank trong năm 2008); ngân hàng có chỉ số CAR1 thấp nhất trong một năm là 4,3% (ngân hàng ACB năm 2011). Độ lệch chuẩn trung bình của chỉ tiêu là 4,5%.