Khi chọn CSDL thực nghiệm, quan tâm đến số lượng giao tác và số lượng hạng mục để từ đó ghi nhận kết quả và thời gian chương trình xử lý.
4.2. Kết quả chương trình thực nghiệm
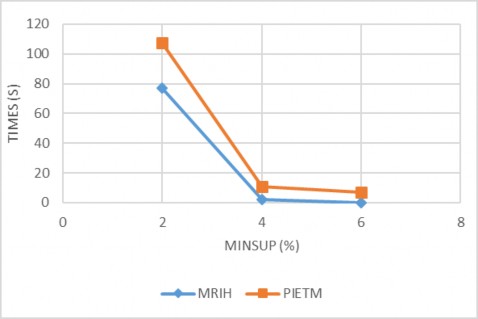
Hình 4.1 Kết quả thực nghiệm với CSDL T10I4D100K (D1)
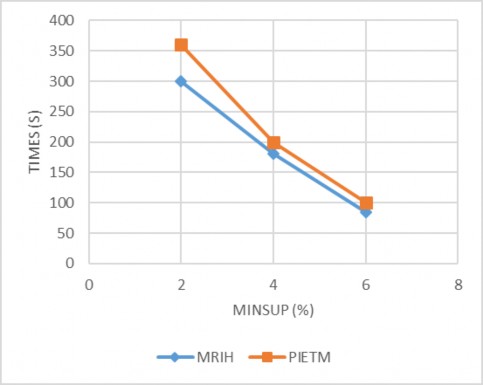
Hình 4.2 Kết quả thực nghiệm với CSDL T40I10D100K (D2)
Chúng ta có thể thấy trong hình 4.1 và 4.2 thì trong hai tập dữ liệu D1, D2 trong bảng 4.2 có cùng số lượng giao tác trong mỗi tập dữ liệu nhưng một số khác biệt giữa số lượng hạng mục trong mỗi tập dữ liệu đã dẫn đến nhiều khác biệt về hiệu quả. Với minsup = 2% (= 2000) chúng ta có thể thấy thuật toán MRIH trích xuất các tập phổ biến từ D1 trong khoảng 77.7 giây nhưng trong khi thời gian này là khoảng
Có thể bạn quan tâm!
-
 Phương pháp khai thác theo chiều ngang để trích xuất các tập phổ biến - 6
Phương pháp khai thác theo chiều ngang để trích xuất các tập phổ biến - 6 -
 Phương Pháp Tìm Kiếm Theo Chiều Rộng Và Theo Chiều Sâu
Phương Pháp Tìm Kiếm Theo Chiều Rộng Và Theo Chiều Sâu -
 Biểu Diễn Tập Dữ Liệu Trên Ma Trận Bit
Biểu Diễn Tập Dữ Liệu Trên Ma Trận Bit -
 Phương pháp khai thác theo chiều ngang để trích xuất các tập phổ biến - 10
Phương pháp khai thác theo chiều ngang để trích xuất các tập phổ biến - 10
Xem toàn bộ 84 trang tài liệu này.
300.92 giây trong D2.
Với Sự khác biệt này cho thấy rằng một yếu tố khác tác động vào thời gian khai thác trong tập dữ liệu đó là độ dài trung bình giao tác. Chúng ta có thể thấy trong bảng 4.2 hai tập dữ liệu D1 và D2 có cùng số lượng giao tác và số lượng hạng mục có hai kích thước khác nhau. Lý do chính sự khác biệt về kích thước này là số lượng hạng mục trung bình trong mỗi giao tác (chiều dài trung bình giao tác). Vì vậy, chúng ta có thể nói rằng kích thước trung bình giao tác có một mối quan hệ trực tiếp và các minsup có mối quan hệ ngược lại với thời gian khai thác.
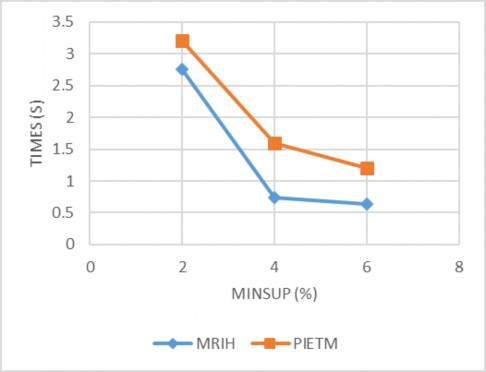
Hình 4.3 Kết quả thực nghiệm với CSDL Retail
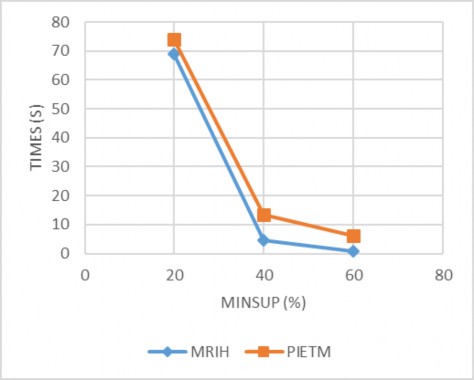
Hình 4.4 Kết quả thực nghiệm với CSDL Mushroom
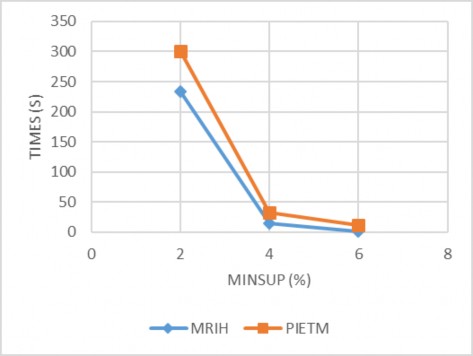
Hình 4.5 Kết quả thực nghiệm với CSDL Accident
Qua kết quả thực nghiệm cho thấy thuật toán MRIH chưa thật sự khai thác tốt khi minsup ở ngưỡng thấp và CSDL đặc ví dụ như tập dữ liệu D1, D2, Accident, do trung bình số lượng hạng mục trong mỗi giao tác rất lớn dẫn đến thời gian khai thác
rất chậm và tốn không gian bộ nhớ. Như vậy thuật toán hiệu quả khi khai thác tập dữ liệu thưa và chưa tốt đối với tập dữ liệu đặc.
4.3. Kết luận chương
Trong chương này, thực nghiệm thuật toán khai thác ngang để tiến hành khai thác các hạng mục phổ biến trong tập dữ liệu rất lớn. Trong thuật toán sử dụng cơ sở dữ liệu giao tác được cắt tỉa theo thứ tự và phân chia để thực hiện. Thuật toán phân chia bộ dữ liệu của tất cả các trích xuất các hạng mục phổ biến của tập dữ liệu vào danh mục n trong đó, n là số mục phổ biến của tập dữ liệu. Kết quả thử nghiệm cho thấy thuật toán đạt được hiệu quả khai thác tốt trên một số các đầu vào dữ liệu khác nhau. Hơn nữa, nghiên cứu hiệu suất cho thấy thuật toán này hoạt động tốt hơn so với thuật toán PIETM.
Chương trình đã cho ra kết quả chính xác theo mô tả thuật toán, tuy nhiên nếu CSDL có độ dài trung giao tác lớn thì thời gian thực hiện trên CSDL chưa thật sự tốt đây cũng là hướng phát triển tiếp theo của đề tài trong thời gian tới.
Chương 5. KẾT LUẬN
Luận văn đã tìm hiểu cơ sở lý thuyết về tập phổ biến, một số thuật toán khai thác tập phổ biến thông dụng theo phương pháp tuần tự, trọng tâm của luận văn đã thực hiện được kết quả sau:
- Biểu diễn tập dữ liệu trên ma trận bit.
- Sử dụng phương pháp chia để trị và cắt tỉa trong khai thác ngang để giảm kích thước cơ sở dữ liệu giao tác và giải quyết vấn đề khai thác cho các tập dữ liệu lớn hiệu quả hơn.
- Phương pháp nén trích xuất để lưu các tập phổ biến được trích từ cơ sở dữ liệu giao tác được xây dựng để cải thiện thời gian khai thác và giảm kích thước của tập tin đầu ra.
- Xây dựng chương trình thực nghiệm và đánh giá kết quả đạt được.
Luận văn đã hoàn thành được mục tiêu đề ra là nghiên cứu và tìm hiểu một tiếp cận mới trong khai thác tập phổ biến: “Phương pháp khai thác theo chiều ngang để trích xuất các tập phổ biến”. Hướng nghiên cứu và phát triển tiếp theo là áp dụng phương pháp khai thác song song và vector bit động vào thuật toán để xử lý song song trong mô hình chia để trị làm tăng hiệu quả cho thuật toán này.
Luận văn mới chỉ dừng lại trên nghiên cứu lý thuyết về khai thác ngang với đích cuối cùng là chương trình thực nghiệm ứng dụng thuật toán MRIH để kiểm chứng trên các CSDL mẫu, chưa xây dựng được chương trình ứng dụng vào thực tiễn cuộc sống.
Ngày nay, khối lượng thông tin được chia sẻ trên internet là vô cùng lớn và đa dạng về thể loại, chúng ta có thể khai thác các thông tin đó phục vụ cho các công việc như tuyển sinh, quảng cáo,...Hướng phát triển tiếp theo của đề tài là tiếp tục ứng dụng phương pháp khai thác ngang kết hợp với các phương pháp xử lý ngôn ngữ tự nhiên để xây dựng ứng dụng phân tích dữ liệu tiếng Việt được thu thập từ Facebook; xem xét dữ liệu nào liên quan tới học sinh phổ thông, xử lý thông tin đưa ra định hướng tư vấn cho học sinh phổ thông lựa chọn học nghề./.
CÔNG BỐ KHOA HỌC CỦA TÁC GIẢ LUẬN VĂN
[1]. Nguyễn Quý Tín, Cao Tùng Anh (2018). Phương pháp khai thác theo chiều ngang để trích xuất các tập phổ biến. Kỷ yếu hội thảo khoa học công nghệ thông tin và truyền thông ICT 2018, Trường Đại học Thông tin Liên lạc – Trường Đại học Nha Trang – Trường Đại học Đà Lạt – Sở Thông tin và Truyền thông Khánh Hòa ngày 21 tháng 12 năm 2018, 49-53.
TÀI LIỆU THAM KHẢO
Tiếng việt:
[1]. Lê Hoài Bắc (2013), Bài giảng môn Data Mining, Đại học KHTN (Đại học Quốc gia Tp.HCM).
[2]. Nguyễn Tấn Thành (2015), Khai thác song song tập phổ biến dựa trên vector bit động. Luận văn thạc sĩ Khoa học máy tính, Đại học Công nghệ Thông tin TP.HCM
Tiếng anh:
[3]. R.Agrawal, T.Imielinski, and A.Swami (1993), “Mining association rules between sets of items in large databases”, In Pro. 1993 ACM-SIGMOD Int. Conf.Management of Data, pages 207-216, Washington, D.C.
[4]. J. Han, J. Pei, Y. Yin (2000), Mining frequent patterns without candidate generation, in: Proceeding of the 2000 ACM-SIGMOD International Conference on Management of Data (SIGMOD’00), Dallas, TX, 2000, pp. 1– 12.
[5]. G. Grahne, J. Zhu (2005), Fast algorithms for frequent itemset mining using FP-trees, Transactions on Knowledge and Data Engineering (TKDE), vol. 17, no. 10, pp. 1347-1362, 2005.
[6]. J. Pei, J. Han, R. Mao (2000), CLOSET an effective algorithm for mining frequent closed itemsets, in: Proceeding of the 2000 ACM-SIGMOD SIGMOD International Workshop Data Mining and Knowledge Discovery (DMKD’00), Dallas, TX, 2000, pp. 11–20.
[7]. Burdick D, Calimlim M, Gehrke J (2001), MAFIA: a maximal frequent itemset algorithm for transactional databases. In: Proceeding of the 2001 international conference on data engineering (ICDE’01), Heidelberg,
Germany, pp 443–452
[8]. Madhavi Dabbiru, Moghalla Shashi (2010), An efficient approach to colossal pattern mining, in: International Journal of Computer Science and Network Security (IJCSNS), 2010, pp. 304–312.
[9]. M.K. Sohrabi, A.A. Barforoush (2012), Efficient colossal pattern mining in high Dimensional datasets, Knowledge Based Systems (2012)
[10]. Dong J., Han M. (2007), BitTableFI: an efficient mining frequent itemsets algorithm, Knowledge Based Systems vol. 20, pp.329–335
[11]. M. T. Tran, B. Vo, B. Le (2015), Combination of dynamic bit vectors and transaction information for mining frequent closed sequences efficiently, Engineering Applications of Artificial Intelligence, vol. 38, pp 183-189.
[12]. T. Le, B. Vo (2014), MEI: An efficient algorithm for mining erasable itemsets,
Engineering Applications of Artificial Intelligence, vol. 27, pp 155-166.
[13]. H. Duong, T. Truong, B. Vo (2014), An efficient method for mining frequent itemsets with double constraints, Engineering Applications of Artificial Intelligence, vol. 27, pp 148-154.
[14]. A. Tran, T. Truong, B. Le (2014), Simultaneous mining of frequent closed Itemsets and their generators: Foundation and algorithm, Engineering Applications of Artificial Intelligence, vol. 36, pp 64-80.
[15]. R. Vimieiro, P. Moscato (2014), Disclosed: An efficient depth-first, top-down algorithm for mining disjunctive closed itemsets in high-dimensional data, Information Sciences, vol. 280, pp 171-187.
[16]. K. C. Lin, I. Liao, T. P. Chang, S. F. Lin (2014), A frequent Itemset mining algorithm based on the Principle of Inclusion– Exclusion and transaction mapping, Information Sciences, vol. 276, pp 278-289.
[17]. Frequent Itemset Mining Implementations Repository. http://fimi.ua.ac.be/data/.