2.3. Một số thuật toán khai thác tập phổ biến
2.3.1. Thuật toán Apriori :
Phương pháp sinh ứng viên để tìm tập phổ biến được Agrawal [3] đề xuất từ năm 1993 với thuật toán Apriori. Ý tưởng của thuật toán Apriori dựa trên kết luận: nếu một tập danh mục là phổ biến thì tất cả tập con của nó cũng phải phổ biến (tính chất 2 – tập phổ biến). Do vậy không thể có trường hợp một tập phổ biến có tập con là không phổ biến hay nói cách khác tập phổ biến nhiều danh mục hơn chỉ có thể được tạo ra từ các tập phổ biến ít danh mục hơn. Nguyên lý hoạt động cơ bản của thuật toán Apriori như sau:
Bắt đầu từ các tập phổ biến chỉ có một danh mục
- Dùng tập phổ biến kích thước k-1 phần tử để tạo các tập ứng cử k phần tử
- Duyệt cơ sở dữ liệu và đối sánh mẫu để đếm số lần xuất hiện của các tập ứng viên trong các giao tác, nếu số lần xuất hiện của tập ứng viên lớn hơn hoặc bằng minsup thì là tập phổ biến, ngược lại không phải tập phổ biến.
Quá trình lặp lại cho đến khi không còn tập phổ biến nào được tạo ra
Thuật toán Apriori
Input: cơ sở dữ liệu D, minsup
Output: L
1) L1 ={tập hợp 1 danh mục};
2) For (k = 2; Lk-1 ≠ ; k++) do begin
3)
4)
5)
6)
7)
8)
9)
Ck = apriori-gen (Lk-1); // Tạo ứng viên mới.
Forall giao tác t D do begin //duyệt CSDL
Ct = subset(Ck, t); //các tập danh mục ứng viên có trong giao tác t
Forall ứng viên c Ct do
c. count ++;
End
Lk = {c Ck | c.count ≥ minsup}
10) End
11) Answer = k Lk; // Trả về tập hợp của các tập phổ biến
Hình 2.1 Thuật toán Apriori
Diễn giải thuật toán:
- Bước đầu tiên của thuật toán đơn giản chỉ tính các danh mục xuất hiện để xác định tập hợp của các tập phổ biến 1 danh mục.
- Lặp bước k :
+ Tập hợp Lk-1 được sử dụng để tạo nên tập ứng viên Ck : sử dụng hàm apriori- gen được miêu tả là hàm lấy Lk-1 (tập hợp của các tập phổ biến k-1 danh mục) là đầu vào và trả về Ck là tập hợp của tất cả các tập chứa k danh mục phát sinh từ tập hợp Lk-1 bằng cách hợp các tập k-1 danh mục trong tập hợp Lk-1. Chú ý một ứng viên thuộc Ck thì tất cả các tập con của ứng viên đó phải có mặt trong Lk-1 (theo tính chất 2 của tập phổ biến)
+ Bước kế tiếp, duyệt CSDL để tính độ phổ biến của các ứng viên trong tập hợp Ck. Từ đó, tính được tập hợp Lk.
+ Nếu Lk = thì dừng lại.
- Hợp của các Lk chính là các tập phổ biến cần tìm.
Ví dụ 2.9: Xét CSDL mẫu trong bảng 2.1 với minSup =50% = 50% * 6 = 3
Bước 1 : Duyệt CSDL để tìm ra L1 là các tập phổ biến có 1 danh mục có độ phổ biến
3 :
Database (D) | |
ID | Nội dung |
1 | a, b, d, e |
2 | b, c, e |
3 | a, b, d, e |
4 | a, b, c, e |
5 | a, b, c, d, e |
6 | b, c, d |
Có thể bạn quan tâm!
-

 Phương pháp khai thác theo chiều ngang để trích xuất các tập phổ biến - 1
Phương pháp khai thác theo chiều ngang để trích xuất các tập phổ biến - 1 -
 Phương pháp khai thác theo chiều ngang để trích xuất các tập phổ biến - 2
Phương pháp khai thác theo chiều ngang để trích xuất các tập phổ biến - 2 -
 Phương Pháp Khai Thác Theo Chiều Ngang Để Trích Xuất Các Tập Phổ Biến
Phương Pháp Khai Thác Theo Chiều Ngang Để Trích Xuất Các Tập Phổ Biến -
 Phương pháp khai thác theo chiều ngang để trích xuất các tập phổ biến - 5
Phương pháp khai thác theo chiều ngang để trích xuất các tập phổ biến - 5 -
 Phương pháp khai thác theo chiều ngang để trích xuất các tập phổ biến - 6
Phương pháp khai thác theo chiều ngang để trích xuất các tập phổ biến - 6 -
 Phương Pháp Tìm Kiếm Theo Chiều Rộng Và Theo Chiều Sâu
Phương Pháp Tìm Kiếm Theo Chiều Rộng Và Theo Chiều Sâu
Xem toàn bộ 84 trang tài liệu này.

L1 | |
Danh mục | Độ phổ biến |
a | 4 |
b | 6 |
c | 4 |
d | 4 |
e | 5 |
Bảng 2.5 Các tập phổ biến có 1 danh mục
Bước 2: tính tập ứng viên C2 dựa trên L1 bằng phép hợp. Sau đó duyệt CSDL tính độ phổ biến của các ứng viên thuộc C2, loại bỏ những ứng viên có độ phổ biến bé hơn minSup, để tạo thành L2 là các tập phổ biến có 2 danh mục.
C2 | |
Danh mục | Độ phổ biến |
ab | 4 |
ac | 2 |
ad | 3 |
ae | 4 |
bc | 4 |
bd | 4 |
be | 5 |
cd | 2 |
ce | 3 |
de | 3 |
L2 | |
Danh mục | Độ phổ biến |
ab | 4 |
ad | 3 |
ae | 4 |
bc | 4 |
bd | 4 |
be | 5 |
ce | 3 |
de | 3 |
Bảng 2.6 Các tập phổ biến có 2 danh mục
Bước 3: Tương tự bước 2 tạo C3 và L3 từ L2 . Chú ý khi tạo C3 thì loại bỏ những ứng viên có tập con 2 danh mục không nằm trong L2. Từ L2 để tạo C3 có thể bằng cách từ tập hợp tất cả danh mục có trong L2, rồi lần lượt kiểm tra các tập danh mục 3 thuộc tính trong tập hợp đó theo chú ý ở dòng trên.
C3 | |
Danh mục | Độ phổ biến |
abd | 3 |
abe | 4 |
ade | 3 |
bce | 3 |
bde | 3 |
L3 | |
Danh mục | Độ phổ biến |
abd | 3 |
abe | 4 |
ade | 3 |
bce | 3 |
bde | 3 |
Bảng 2.7 Các tập phổ biến có 3 danh mục
Bước 4: Tạo C4 và L4 từ L3
C4 | |
Danh mục | Độ phổ biến |
abde | 3 |
L4 | |
Danh mục | Độ phổ biến |
abde | 3 |
Bảng 2.8 Các tập phổ biến có 4 danh mục
Bước 5: Tạo C5 và L5 từ L4. Ta có C5 = . Như vậy thuật toán dừng lại ở bước 5 vì L5 = Kết quả: với minSup =50% thì :
Tập hợp các tập phổ biến = L1 L2 L3 L4
= {a, b, c, d, e, ab, ad, ae, bc, bd, be, ce, de, abd, abe, ade, bce, bde, abde}
Hạn chế của thuật toán Apriori:
Để xác định độ phổ biến của các tập ứng viên, thuật toán Apriori phải quét lại toàn bộ giao tác trong CSDL, do đó sẽ tiêu tốn rất nhiều thời gian khi phải quét CSDL nhiều lần để kiểm tra một lượng lớn các ứng viên, đặc biệt khi số danh mục lớn.
Để khắc phục hạn chế phát sinh tập ứng viên quá lớn của thuật toán Apriori, các nhà nghiên cứu đã đề nghị xây dựng cây FP-Tree và thuật toán FP-Growth ra đời nhằm khai thác tập phổ biến mà không phát sinh các tập ứng viên.
2.3.2. Thuật toán FP-Growth
Thuật toán Apriori [3] được coi là thuật toán nền tảng về khai thác tập phổ biến bằng cách sử dụng kỹ thuật tỉa để rút gọn kích thước của các tập ứng viên. Tuy nhiên, thuật toán gặp phải hai chi phí lớn: sinh ra số lượng khổng lồ các tập ứng viên, phải duyệt cơ sở dữ liệu nhiều lần.
Để khắc phục những chi phí lớn của thuật toán Apriori, nhóm tác giả Jiawei Han, Jian Pei và Yiwen Yin đã đề xuất thuật toán FP-Growth [4] vào năm 2000. Thuật toán này sử dụng một cấu trúc cây FP-Tree để lưu trữ thông tin tập phổ biến của dữ liệu gốc ở một dạng nén trong bộ nhớ và dùng phương pháp duyệt cây theo chiều rộng để tìm tập phổ biến. Kỹ thuật xây dựng cây FP-Tree như sau:
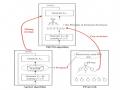
Bước 1:
Duyệt CSDL, lấy ra tập các hạng mục phổ biến X và tính độ phổ biến của chúng.
Duyệt CSDL
Sắp xếp các hạng mục trong tập X theo thứ tự giảm dần của độ phổ biến, ta được tập kết quả là L.
![]()
Lấy ra tập phổ biến L
Hình 2.2 Lưu đồ thuật toán xây dựng cây FP-Tree (bước 1)
L bao gồm các hạng mục phổ biến theo thứ tự giảm dần của độ phổ biến
Bước 2:
Tạo nút gốc cho cây T và tên của nút gốc sẽ là Null.
Sau đó duyệt CSDL lần thứ hai. Ứng với mỗi giao tác trong CSDL thực hiện 2 công việc sau:
Chọn các hạng mục phổ biến trong các giao tác và sắp xếp chúng theo thứ tự giảm dần độ phổ biến trong tập L
![]()
Gọi hàm Insert_tree([p|P],T) để đưa các hạng mục vào trong cây T
![]()
Tạo nút gốc cho cây
Hết
Còn
Dừng
Kiểm tra hết giao tác chưa?
{Cây FP-Tree}
Duyệt CSDL
Chọn 01 giao tác trong CSDL
Chọn hạng mục phổ biến trong các giao tác và sắp xếp tập L theo thứ tự giảm dần độ phổ biến
Gọi hàm Insert_tree([p|P], T)
Hình 2.3 Lưu đồ thuật toán xây dựng cây FP-Tree (bước 2)
Ví dụ 2.10:
Xây dựng cây FP-Tree cho CSDL gồm các hạng mục sau:
Nội dung giao tác | |
1 | f, a, c, d, g, i, m,p |
2 | a, b, c, f, l, m, o |
3 | b, f, h, j, o |
4 | b, c, k, s, p |
5 | a, f, c, e, l, p, m, n |
Bảng 2.9 Cơ sở dữ liệu dùng làm dữ liệu xây dựng cây FP-Tree
Cho minsup = 60%
Bước 1: Ta có một danh sách các hạng mục phổ biến L là: <(f:4), (c:4), (a:3), (b:3), (m:3), (p:3)>; các hạng mục đã được sắp thứ tự giảm dần theo độ phổ biến
Bước 2: Duyệt CSDL lần thứ hai, chọn hạng mục phổ biến trong mỗi giao tác:
Nội dung giao tác | Sắp xếp theo độ phổ biến | |
1 | f, a, c, d, g, i, m,p | f, c, a, m, p |
2 | a, b, c, f, l, m, o | f, c, a, b, m |
3 | b, f, h, j, o | f, b |
4 | b, c, k, s, p | c, b, p |
5 | a, f, c, e, l, p, m, n | f, c, a, m, p |
Bảng 2.10 Minh họa các hạng mục phổ biến trong mỗi giao tác
Xây dựng FP-tree: mỗi giao tác tương ứng với một đường dẫn trong FP-Tree
f:1
{}
f:2
c:1
Giao tác 1: {f, c, a, m, p}
Giao tác 2: {f, c, a, b, m}
{}
a:2 | |
p:1
p:1
m:1
![]()
f:3
{}
b:1
f:3
b:1
c:1
b:1
f:4
{}
c:1
m:1
b:1
m:1
b:1
a:1
b:1 | |
p:1 | |
c:3 | |
a:3 | |
Giao tác 3: {f, b}
Giao tác 4: {c, b, p}
Giao tác 5: {f, c, a, m, p}
{}
c:2 | |
a:2 | |
c:2 | |
a:2 | |
p:1
m:1
b:1
m:1
b:1
p:1
m:1
p:1
m:2
b:1
p:2
m:1
Node-Link
m:1
Hình 2.4 Minh họa các bước xây dựng cây FP-Tree
Hạng
head of node-links
mục
f
4
f:4
c
4
b:1
a
3
b
3
m:2
b:1
m
3
p
3
p:2
{}
m:1
c:1
b:1
p:1
Từ tập dữ liệu ban đầu, ta xây dựng header table của cây FP-Tree như sau:
c:3 | |
a:3 | |
Hình 2.5 Header table của cây FP-Tree
Ý tưởng:
Xây dựng cây FP-Tree để nén dữ liệu. Những nút trong cây được gán nhãn bằng tên các hạng mục và được sắp xếp theo tần suất xuất hiện của các hạng mục.
Thiết lập cơ sở điều kiện cho mỗi phần tử phổ biến (mỗi nút trên cây FP- Tree). Thiết lập cây FP-Tree điều kiện từ cơ sở điều kiện đó.
Khai thác đệ quy cây FP-Tree điều kiện để xác định tập phổ biến.
Thuật toán:
Procedure FP-growth(Tree, α)
If Tree có chứa một đường đi đơn P then
for mỗi tổ hợp với sup=min(sup của các nút trong )
Else for mỗi I trên bảng header của cây (Tree) Tạo mẫu = I với sup =sup(I)
Xây dựng cơ sở điều kiện cho β và sau đó xây dựng cây FP Treeβ
theo điều kiện của β
if Treeβ ≠ then FP-growth(Treeβ, β)