CHƯƠNG 1
TỔNG QUAN VỀ CÁC MÔ HÌNH VĂN PHẠM CHO NGÔN NGỮ TỰ NHIÊN

Theo Jurafsky [70], quan hệ văn phạm là cách hình thức hóa những tư tưởng của văn phạm truyền thống như chủ ngữ hay bổ ngữ và những mối quan hệ khác. Nhiều mô hình văn phạm đã được đưa ra theo các hướng tiếp cận: cấu trúc (constituency), quan hệ văn phạm (grammar relation), phân loại con (subcategorization) hay phụ thuộc (dependency). Hai hướng tiếp cận phổ biến nhất hiện nay là cấu trúc và phụ thuộc. Chương này sẽ giới thiệu các mô hình văn phạm phổ biến và vị trí của văn phạm liên kết trong hệ thống các mô hình văn phạm đó.
1.1. Cách tiếp cận cấu trúc và văn phạm phi ngữ cảnh
Vấn đề đầu tiên đặt ra khi mô tả các quy tắc cú pháp là biểu diễn được các quy luật để nhóm các từ lại thành câu. Nếu ngữ pháp tiếng Việt [28] quy định câu phải chứa một nòng cốt (đơn hoặc ghép), nòng cốt đơn phải chứa chủ ngữ, vị ngữ với chủ ngữ luôn đi trước vị ngữ, thì vấn đề mô tả quy tắc cú pháp sẽ chuyển thành vấn đề tạo lập các cấu trúc (constituent) và đưa ra các quy tắc về vị trí của các cấu trúc.
Mô hình cho phép nghiên cứu việc tạo lập các cấu trúc một cách đệ quy chính là mô hình văn phạm phi ngữ cảnh. Mô hình hình thức này tương đương với dạng chuẩn BNF (Backus Naur Form) của ngôn ngữ lập trình.
Mô hình cho phép nghiên cứu việc tạo lập các cấu trúc một cách đệ quy chính là mô hình văn phạm phi ngữ cảnh. Mô hình hình thức này tương đương với dạng chuẩn BNF (Backus Naur Form) của ngôn ngữ lập trình.
1.1.1. Văn phạm phi ngữ cảnh biểu diễn ngôn ngữ tự nhiên
Văn phạm phi ngữ cảnh bao gồm một tập các luật hay sản xuất, mỗi luật biểu diễn cách thức mà các ký hiệu của ngôn ngữ được nhóm lại rồi sắp theo thứ tự và một tập từ vựng bao gồm các từ và ký hiệu.
Có thể bạn quan tâm!
-

 Mô hình văn phạm liên kết tiếng Việt - 1
Mô hình văn phạm liên kết tiếng Việt - 1 -
 Mô hình văn phạm liên kết tiếng Việt - 2
Mô hình văn phạm liên kết tiếng Việt - 2 -
 Văn Phạm Phi Ngữ Cảnh Xác Suất Từ Vựng Hóa
Văn Phạm Phi Ngữ Cảnh Xác Suất Từ Vựng Hóa -
 Tiếp Cận Qua Cấu Trúc Nét Và Văn Phạm Hợp Nhất
Tiếp Cận Qua Cấu Trúc Nét Và Văn Phạm Hợp Nhất -
 Mô hình văn phạm liên kết tiếng Việt - 6
Mô hình văn phạm liên kết tiếng Việt - 6
Xem toàn bộ 305 trang tài liệu này.
Ví dụ: Một tập sản xuất của văn phạm phi ngữ cảnh tiếng Việt với ý nghĩa của các ký hiệu không kết thúc: S – câu, NP – danh ngữ, VP – động ngữ, N – danh từ, V – động từ, P – đại từ.
S → NP VP
NP → P
NP → N P
VP → V NP
Tập sản xuất này có thể mô tả cấu trúc cú pháp của câu “Tôi yêu mẹ tôi” với đại từ “tôi”, danh từ “mẹ” và động từ “yêu”.
Một cách hình thức, có thể mô tả văn phạm phi ngữ cảnh như sau:
Định nghĩa 1.1. [70] Văn phạm phi ngữ cảnh là bộ 4 G = (N, Σ, R, S), trong đó:
N: tập ký hiệu không kết thúc (biến).
Σ: tập ký hiệu kết thúc (không giao với N).
R: tập luật, hay tập sản xuất dạng A → β, A là ký hiệu không kết thúc, β là xâu gồm hữu hạn ký hiệu trên tập vô hạn (Σ ∪ N)* (tập tất cả các xâu trên bảng chữ Σ ∪ N).
S: ký hiệu đầu.
Trong mô hình văn phạm phi ngữ cảnh, bài toán phân tích cú pháp là bài toán tìm ra cây ngữ cấu cho câu đưa vào. Mỗi nút của cây ngữ cấu có nhãn là một ký hiệu không kết thúc biểu diễn một cấu trúc. Theo [56], cây ngữ cấu thể hiện những thông tin sau về cú pháp:
- Thứ tự tuyến tính của các từ trong câu.
- Tên các phạm trù cú pháp của các từ và nhóm từ.
- Cấu trúc phân cấp của các phạm trù cú pháp.
Các bộ phân tích cú pháp theo mô hình văn phạm phi ngữ cảnh cổ điển chủ yếu theo hai phương pháp CYK (Cocke – Younger – Kasami) và Earley. Đã có những bộ phân tích cú pháp tiếng Việt được xây dựng theo phương pháp CYK [12], Earley [5], [27] với những cải tiến thích hợp.
Trong hình 1.1 là cây ngữ cấu cho câu “Tôi thích chân gà”. Cây ngữ cấu này nếu không tính nhãn của các nút lá, thì giống hệt cây ngữ cấu của câu “Tôi thích áo lụa”, tuy nhiên, nếu đem dịch sang tiếng Anh, hai câu này phải dịch khác hẳn nhau. Quan hệ giữa danh từ chỉ bộ phận cơ thể động vật và danh từ chỉ động vật là quan hệ sở hữu, do vậy “chân gà” phải hiểu là “chân của gà”, trong khi quan hệ giữa “áo” và “lụa” lại là quan hệ về mặt chất liệu “áo bằng lụa”. Mô hình phi ngữ cảnh chưa thể hiện được mối liên hệ này.
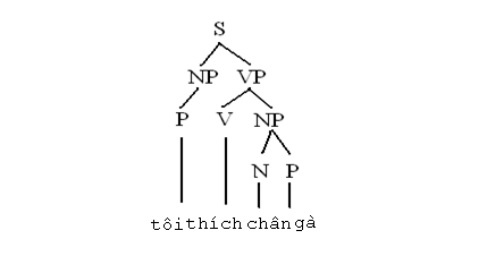
Hình 1.1. Cây ngữ cấu của câu “Tôi thích chân gà”.
Vấn đề nhập nhằng là một trong những vấn đề phức tạp nhất mà các bộ phân tích cú pháp phải giải quyết. Theo [70], trong giai đoạn phân tích cú pháp, vấn đề nhập nhằng hướng về cấu trúc (structural ambiguity). Giả thiết ta chỉ xét câu đơn, tức là câu chỉ có một nòng cốt và bỏ qua vấn đề nhập nhằng từ loại. Vấn đề nhập nhằng cấu trúc xảy ra khi một câu có nhiều hơn một cây phân tích. Trong hình 1.2 là hai cây ngữ cấu khác nhau cho câu “Họ sẽ không chuyển hàng xuống thuyền vào ngày mai” (câu ví dụ trong [20]) với văn phạm phi ngữ cảnh.
S → NP VP
NP → P
VP → R VP | R R V N PP PP PP-TMP | VP PP | V NP PP
PP → E NP
PP-TMP →E NP Ý nghĩa của các ký hiệu: S – câu, NP – danh ngữ, VP- động ngữ, PP – giới ngữ, N – danh từ, V – động từ, P – đại từ, R – phụ từ, E – giới từ, PP-TMP – giới ngữ chỉ thời gian.
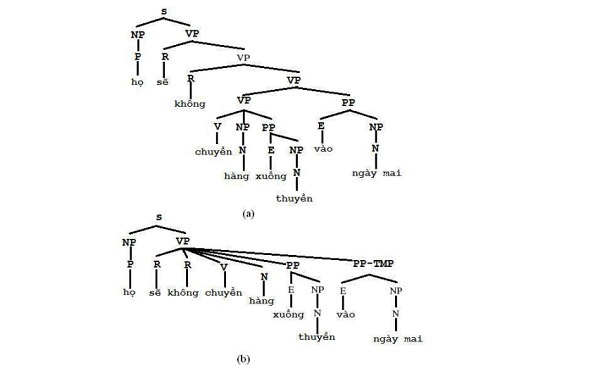
Hình 1.2. Hai cây ngữ cấu của câu “Họ sẽ không chuyển hàng xuống thuyền vào ngày mai”.
Một trong những cách tiếp cận đầu tiên để giải quyết vấn đề nhập nhằng khi phân tích cú pháp trên mô hình văn phạm phi ngữ cảnh là mô hình văn phạm phi ngữ cảnh xác suất (Probabilistic Context Free Grammar).
1.1.2. Văn phạm phi ngữ cảnh xác suất
Trong mô hình văn phạm phi ngữ cảnh xác suất, mỗi luật được gắn thêm một xác suất cho thấy luật đó có thường xuyên được sử dụng trong các cây ngữ cấu hay không.
Định nghĩa 1.2. [70] Văn phạm phi ngữ cảnh xác suất là bộ bốn
N: tập ký hiệu không kết thúc (biến).
Σ: tập ký hiệu kết thúc (không giao với N).
R: tập luật, hay tập sản xuất dạng A → β | p |, trong đó A là ký hiệu không kết thúc, β là xâu gồm hữu hạn ký hiệu trên tập vô hạn (Σ ∪ N)*, p là số trong đoạn [0,1] biểu thị xác suất Pr ( β | A ).
S: ký hiệu đầu.
Xác suất của một cây ngữ cấu là tích các xác suất của n luật được sử dụng để mở rộng n nút trong của nó:
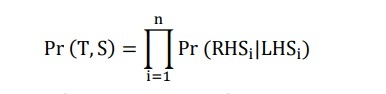
LHSi và RHSi là vế trái và vế phải của sản xuất được dùng cho nút thứ i của cây ngữ cấu.
Cây được chọn là cây có xác suất lớn nhất [41]
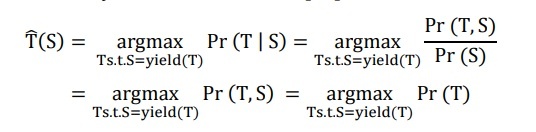
Biểu thức T.s.t.S = yield(T) yêu cầu tính trên tất cả các cây ngữ cấu T có kết quả là câu S.
Trong trường hợp lý tưởng, nếu có một treebank đủ lớn, có thể tính xác suất của mỗi luật theo công thức:
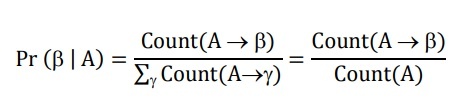
Vấn đề là khi bắt đầu công việc, treebank chưa có hoặc chưa đủ lớn. Do vậy cần chọn một bộ ngữ liệu, phân tích các câu của nó để bổ sung dần vào ngân hàng cây và tính ra các xác suất nói trên. Ta lại đối mặt với vấn đề khác, khi một câu có thể có nhiều phân tích: phân tích nào sẽ được chọn? Việc giải quyết vấn đề nhập nhằng lại rơi vào tình thế “con gà và quả trứng”.