Luận án xây dựng bộ từ điển văn phạm liên kết gồm trên 40.000 mục từ dựa trên giải thuật mở rộng của [113] với cách đánh giá tính phân biệt được dựa trên các thông tin trong từ điển tiếng Việt.
2.2.1. Giải thuật mở rộng từ điển
2.2.1.1 Ý tưởng của giải thuật
Szolovits [113] giả sử rằng w là một từ của từ vựng nguồn mà thông tin chưa được biết trong từ vựng đích. Nếu có một từ x trong từ vựng nguồn là không phân biệt (indiscernible) với w và nếu x có một định nghĩa từ vựng trong từ vựng đích thì gán định nghĩa của x cho w là hợp lý.

Từ vựng nguồn được nói tới ở đây là các từ xuất hiện trong UMLS Specialist Lexicon, còn từ vựng đích là từ vựng LP (Link grammar Parser), có cấu trúc tương tự như từ điển văn phạm liên kết của luận án. Hai từ trong tử vựng nguồn là không phân biệt nếu chúng có cùng mô tả từ vựng.
2.2.1.2. Hình thức hóa ánh xạ
Giả sử W là tập các nghĩa từ (từ – từ loại) trong từ vựng nguồn và V là tập các nghĩa từ trong từ vựng đích
Với mỗi w∈W, giả sử Xw= { x | x không phân biệt với w trong từ vựng nguồn }. Định nghĩa

Dw = { f(x) | x ∈ Xw, f(x) ≠ ⊥ } (Tập các định nghĩa trong từ vựng đích của các nghĩa không phân biệt với w trong từ vựng nguồn).
Mục đích của giải thuật là liên hệ w với một trong các định nghĩa của Dw. Vấn đề đặt ra là phải lựa chọn định nghĩa thích hợp nhất trong Dw.
Gọi I(d) = { v | f(v) = d } (tập định nghĩa trong từ vựng đích chia sẻ mô tả từ vựng d).
Với mỗi d ∈ ef, tính số nghĩa từ chung giữa I(d) và Xw và chọn định nghĩa cho giao lớn nhất:
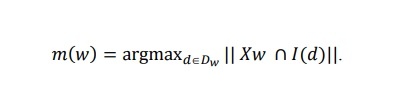
Hình 2.17. chỉ ra sơ đồ cho giải thuật ánh xạ theo [113].
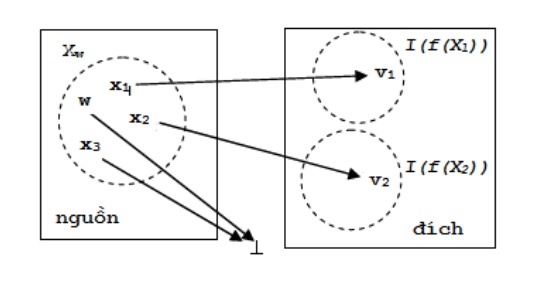
Hình 2.17. Ánh xạ trực cảm
2.2.2. Ứng dụng giải thuật mở rộng từ điển tiếng Việt
Với thông tin hạn chế của bộ từ điển tiếng Việt, luận án cũng định nghĩa hai nghĩa là không phân biệt nếu và chỉ nếu chúng có mô tả từ vựng hoàn toàn giống nhau như sau :
- Cùng loại từ (danh, động từ…)
- Cùng loại con
- Có cùng mẫu câu (với động từ)
Dựa trên phương pháp trực cảm, quá trình mở rộng từ điển văn phạm liên kết như sau:
- Duyệt lần lượt bộ dữ liệu từ điển tiếng Việt.Với mỗi từ tìm tập các từ không phân biệt với nó.
- Tìm trong tập hợp các từ không phân biệt đó những từ đã được định nghĩa trong bộ dữ liệu từ điển văn phạm liên kết rồi đưa ra những công thức của các từ đó.
- Duyệt từng công thức trong từ điển văn phạm liên kết hiện hành, công thức nào có số lượng các từ không phân biệt được với từ cần định nghĩa lớn nhất thì công thức đó được gán cho từ cần định nghĩa, và được thêm vào văn phạm.
Việc sử dụng giải thuật heuristic để xây dựng từ điển đã cho kết quả tốt với những loại từ cơ bản: danh từ cụ thể, nội động từ, ngoại động từ, tính từ tính chất. Với những loại từ khác, đặc biệt là từ chưa phân loại (loại “X”), cần chỉnh lại vị trí bằng tay. Ngoài ra còn phát sinh một số vấn đề khác:
- Một từ có thể thuộc nhiều loại từ khác nhau. Cách giải quyết của luận án là đưa mỗi nghĩa vào một mục khác nhau trong từ điển văn phạm liên kết. Điều đó sẽ dẫn đến xuất hiện nhiều phân tích hơn cho mỗi câu do bộ phân tích liên kết xác định sai công thức. Phần khử nhập nhằng của luận án sẽ giải quyết vấn đề này.
- Việc xác định từ không phân biệt đến tận loại con gây ra lỗi với loại phụ từ như “đã”, “đang” vì trong từ điển tiếng Việt, chúng được xếp chung một mục nhưng trong từ điển tiếng liên kết, hai từ đó thuộc hai loại con khác nhau.
- Giống như [111], bộ phân tích bỏ qua các cảm từ, ví dụ “a ha”, “à ra thế”
Sau khi có được bộ từ điển “thô”, công việc hiệu chỉnh bằng tay được thực hiện để đưa ra một bộ từ điển văn phạm liên kết hoàn chỉnh.
2.2. Kết luận
Tóm lại, để xây dựng từ điển, luận án đã thực hiện qua các giai đoạn chính:
1. Xây dựng các công thức liên kết
- Nghiên cứu bộ từ điển liên kết tiếng Anh, tìm ra những công thức liên kết có thể sử dụng cho tiếng Việt và bổ sung vào từ điển liên kết.
- Nghiên cứu ngữ pháp và từ pháp tiếng Việt để xây dựng các công thức liên kết cho một số từ điển hình.
2. Gán công thức liên kết cho từ
- Xem xét văn bản mẫu, lần lượt từng từ. Tra cứu từ điển liên kết để tìm xem từ đang xét đã tương ứng với công thức liên kết nào chưa, nếu chưa, thêm từ và công thức mới vào từ điển một cách thủ công.
- Duyệt từ điển tiếng Việt, gán mỗi từ cho một công thức trong từ điển theo giải thuật của Szolovits với định nghĩa các từ không phân biệt riêng cho tiếng Việt. Quy trình xây dựng từ điển có thể mô tả trong hình 2.18.
- Quy trình xây dựng từ điển văn phạm liên kết tiếng Việt được mô tả trong hình 2.18.
Sau quá trình xây dựng và thử nghiệm, luận án đã xây dựng được một từ điển văn phạm liên kết với trên 150 công thức lớn (mỗi công thức lớn bao gồm một hoặc nhiều công thức con liên kết với nhau qua toán tử or hoặc xor) và 77 loại kết nối cho tất cả các loại từ trong tiếng Việt. Để có được từ điển này, luận án đã tổng kết từ nhiều tài liệu về ngữ pháp tiếng Việt, tham khảo cách xây dựng từ điển sử dụng trên máy tính của nhiều nhóm nghiên cứu: VLSP, Hồ Ngọc Đức, Vdict… Từ điển của luận án đã đáp ứng được yêu cầu phân tích các cấu trúc cơ bản và một số ngoại lệ thường gặp của tiếng Việt.
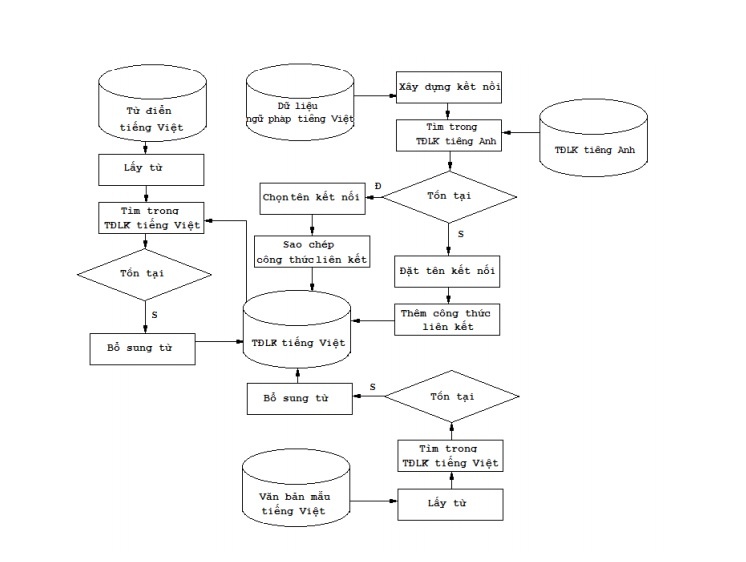
Hình 2.18. Quy trình xây dựng từ điển văn phạm liên kết tiếng Việt
Do được xây dựng trong một thời gian ngắn (2009 – 2012), còn nhiều ngoại lệ của tiếng Việt mà từ điển chưa bao quát hết được. So sánh với số lượng trên 1000 công thức lớn của từ điển liên kết tiếng Anh sau 21 năm (1991 – 2012) liên tục cập nhật các ngoại lệ, số lượng công thức của từ điển liên kết tiếng Việt còn nhỏ bé. Để phát triển thành một từ điển đầy đủ, chắc chắn cần thử nghiệm bộ phân tích với bộ ngữ liệu thật rộng lớn và sự hỗ trợ từ các nhà ngôn ngữ học.
CHƯƠNG 3
PHÂN TÍCH CÚ PHÁP TRÊN VĂN PHẠM LIÊN KẾT
3.1. Bộ phân tích cú pháp liên kết
3.1.1. Giải thuật phân tích cú pháp
Giải thuật phân tích câu trong văn phạm liên kết được [111] đưa ra dựa trên phương pháp quy hoạch động. Giải thuật tìm cách xây dựng một phân tích liên kết theo phương pháp từ trên xuống đảm bảo các tiêu chuẩn đã được nêu trong chương trước.
Khởi đầu, mục đích của giải thuật là tìm cách liên kết giữa từ đầu (từ thứ 0) và từ cuối (từ thứ n). Thật ra các từ trong câu được đánh số từ 0 đến n-1. Từ thứ n là một từ “ảo” với dạng tuyển (NIL)(NIL).
Một dạng tuyển d của từ nào đó sẽ có các con trỏ trỏ tới hai danh sách các kết nối. Các con trỏ này được ký hiệu là left[d] và right[d]. Nếu c là một kết nối, thì next[c] ký hiệu kết nối tiếp sau c trong danh sách của nó. Trường next của con trỏ cuối cùng trong danh sách có giá trị bằng NIL. Hình 3.1 dưới đây mô tả hoạt động của bộ phân tích sau khi xem xét kết nối l’ trên từ L và một kết nối r’ trên từ R. l là next[l’] và r là next[r’].
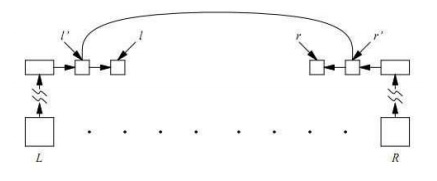
Hình 3.1. Giải thuật phân tích
Việc mở rộng lời giải cục bộ cho vùng nằm giữa L và R được thực hiện bằng cách xem xét lần lượt các từ W trong phạm vi giữa L và R được mô tả trong hình 3.2 dưới đây.
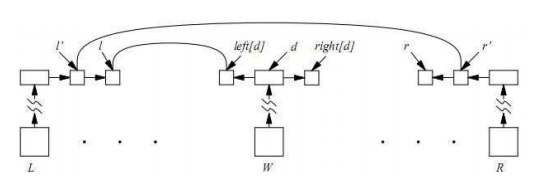
Hình 3.2. Lời giải cục bộ
Dưới đây là giải thuật phân tích cú pháp của [111]. Hàm COUNT cho tổng số các phương án có thể tạo ra kết nối.
| PARSE t ← 0 for each dạng tuyển d của từ 0 do if left [d] = NIL then t ← t + COUNT(0, n, right [d], NIL) return t |
Có thể bạn quan tâm!
-
 Xây Dựng Liên Kết Dựa Trên Cấu Trúc Động Ngữ
Xây Dựng Liên Kết Dựa Trên Cấu Trúc Động Ngữ -
 Xây Dựng Liên Kết Dựa Trên Cấu Trúc Tính Ngữ
Xây Dựng Liên Kết Dựa Trên Cấu Trúc Tính Ngữ -
 Liên Kết Các Mệnh Đề Trong Câu Ghép Đơn Giản
Liên Kết Các Mệnh Đề Trong Câu Ghép Đơn Giản -
 Kết Quả Thử Nghiệm Phân Tích Câu Đơn Và Câu Ghép Đơn Giản
Kết Quả Thử Nghiệm Phân Tích Câu Đơn Và Câu Ghép Đơn Giản -
 Mô hình văn phạm liên kết tiếng Việt - 16
Mô hình văn phạm liên kết tiếng Việt - 16 -
 Mô hình văn phạm liên kết tiếng Việt - 17
Mô hình văn phạm liên kết tiếng Việt - 17
Xem toàn bộ 305 trang tài liệu này.
Hình 3.3. Giải thuật phân tích cú pháp liên kết
Hàm COUNT [111] được mô tả như trong hình 3.4.dưới đây:
| COUNT(L, R, l, r) if L = R + 1 then if l = NIL and r = NIL then return 1 else return 0 else total ← 0 for W ← L + 1 to R – 1 do for each dạng tuyển d của từ W do if l ≠ NIL and left[d] ≠ NIL and MATCH(l,left[d]) then leftcount ← COUNT(L, W, next[l], next[left[d]]) else leftcount ← 0 if right[d] ≠ NIL and r ≠ NIL and MATCH(right[d],r)) then rightcount ← COUNT(W, R, next[right[d], next[r]) else rightcount ← 0 total ← total + leftcount * rightcount if leftcount > 0 then total ← total + leftcount *COUNT(W, R, right[d], r) if (rightcount > 0 and l = NIL then total ← total + rightcount * COUNT(L, W, l, left[d]) return total |
Hình 3.4.Hàm COUNT cho số phân tích của câu.