Tính trên toàn văn bản (bao gồm cả mức câu, đoạn, mục), bộ phân tích diễn ngôn cho độ chính xác là 63%. Ở mức câu, độ chính xác đạt được xấp xỉ 80%. Xuất phát từ đặc điểm của câu ghép tiếng Việt là hầu hết các giới hạn mệnh đề có thể phát hiện nhờ dấu hiệu diễn ngôn kết hợp với một số đặc trưng cú pháp, luận án đã cải tiến giải thuật phân đoạn diễn ngôn ở mức câu để tách câu ghép thành các mệnh đề, sau đó xây dựng cây diễn ngôn của câu. Các mệnh đề sẽ được phân tích cú pháp riêng và quan hệ diễn ngôn giữa các mệnh đề sẽ được chuyên thành các kết nối lớn trong văn phạm liên kết thành một phân tích hoàn chỉnh cho toàn bộ câu. Điều này là khả thi vì đối với mô hình văn phạm liên kết, yêu cầu về liên kết chỉ xác định hướng liên kết, nên không cần những đánh giá quá phức tạp về quan hệ phụ thuộc. Do phạm vi phân tích là câu ghép nên giới hạn của các mệnh đề khá rõ ràng.
Luận án đã sử dụng tên của 18 mối quan hệ diễn ngôn giữa các mệnh đề được [1] và [9] nêu ra làm tên kết nối. Các kết nối này mang tính chất kết nối lớn vì chúng liên kết các cụm từ với nhau. Chúng được xây dựng giữa các cặp mệnh đề dựa theo cây diễn ngôn của câu. Hình 3.10 cho thấy cây diễn ngôn của câu “Trời mưa rất to và gió rất mạnh nên tôi phải nghỉ học, mẹ tôi phải nghỉ làm”. Câu này có 4 mệnh đề ký hiệu A1, B1, C1, D1. Các quan hệ diễn ngôn: nguyên nhân, kết hợp, liệt kê được chuyển thành kết nối. Kết nối giữa các mệnh đề vẫn phải thỏa mãn các yêu cầu sau:
- Mỗi kết nối phải nối hai từ
- Phân tích liên kết của câu phải thỏa mãn các tính chất của văn phạm liên kết: tính phẳng, tính liên thông, tinh thứ tự cũng như tính thỏa mãn, tính loại trừ.
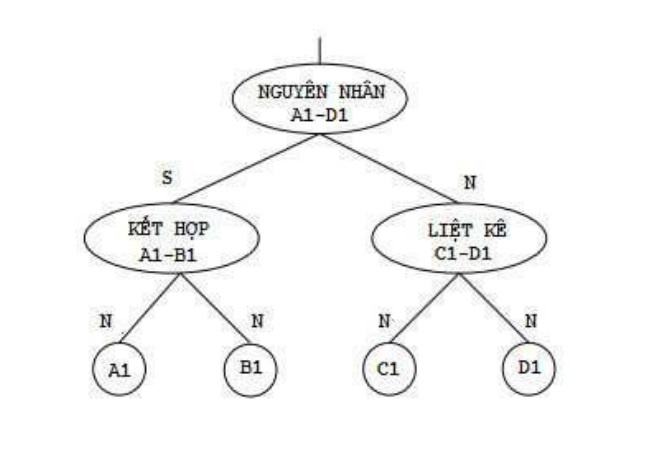
Hình 3.10. Cây phân tích diễn ngôn của câu “[trời mưa rất to vàA1] [gió rất mạnh nênB1] [tôi phải nghỉ học,C1] [mẹ tôi phải nghỉ làm.D1]”
Để đảm bảo tính phẳng, nghĩa là các liên kết không được giao nhau khi vẽ bên trên các từ, cần chọn ra trong mỗi mệnh đề một từ đại diện để liên kết. Mỗi từ trong mệnh đề sẽ được gắn với một trọng số (bậc). Từ có trọng số nhỏ nhất ứng với liên kết cao nhất sẽ được chọn đại diện cho mệnh đề.
Như vậy, quá trình phân tích cú pháp cho câu ghép cần qua những bước sau:
- Phân đoạn diễn ngôn
- Phân tích cú pháp cho từng mệnh đề, thêm các liên kết nhận được vào liên kết tổng thể.
- Xây dựng cây phân tích diễn ngôn cho câu.
- Duyệt cây phân tích diễn ngôn theo thứ tự sau, thêm các kết nối ứng với từng quan hệ diễn ngôn.
3.2.1. Xây dựng cây diễn ngôn
3.2.1.1.Phân đoạn diễn ngôn
Đoạn văn bản nhỏ nhất mà giữa chúng tồn tại các quan hệ diễn ngôn được gọi là Đơn vị diễn ngôn nguyên tố (Elementary Discourse Units – EDU). EDU có thể là một mệnh đề hoặc tựa mệnh đề.
Luận án cải tiến giải thuật của Marcu [89] để phân đoạn diễn ngôn. Dấu hiệu để phân chia văn bản thành các đoạn nguyên tố về cơ bản khá giống với tiếng Anh. Bảng 3.3. dưới đây cho phép xác định các dấu hiệu diễn ngôn tiềm tàng trong văn bản cần phân tích.
Bảng 3.4. Các biểu thức chính quy biểu diễn một số dấu hiệu diễn ngôn tiềm tàng
| Dấu hiệu | Cách nhận biết |
| Mặc dù | [s ]Mặc dù(s| | ] |
| Bởi vì | [s ]bởi vì(s| |n) |
| Nhưng | [,][s ]nhưng(s| | ) |
| Mặt khác | [,][s ]mặt khác(s| | ) |
| Còn | [s ][,] còn (s| | ) |
| DẤU_PHẨY | ,[s| | ) |
| MỞ_NGOẶC | [,][s ]+( |
| ĐÓNG_NGOẶC | )(s| | ) |
| GẠCH_NGANG | [,][s ]+–(s| | ) |
| HẾT_CÂU | (“.”)|(“?”)|(“!”) |
Có thể bạn quan tâm!
-

 Ứng Dụng Giải Thuật Mở Rộng Từ Điển Tiếng Việt
Ứng Dụng Giải Thuật Mở Rộng Từ Điển Tiếng Việt -
 Kết Quả Thử Nghiệm Phân Tích Câu Đơn Và Câu Ghép Đơn Giản
Kết Quả Thử Nghiệm Phân Tích Câu Đơn Và Câu Ghép Đơn Giản -
 Mô hình văn phạm liên kết tiếng Việt - 16
Mô hình văn phạm liên kết tiếng Việt - 16 -
 Giải Thuật Phân Tích Cú Pháp Câu Ghép
Giải Thuật Phân Tích Cú Pháp Câu Ghép -
 Kết Quả Thử Nghiệm Phân Tích Câu Ghép
Kết Quả Thử Nghiệm Phân Tích Câu Ghép -
 Giải Thuật Kiểu Viterbi Để Tìm Phân Tích Tốt Nhất
Giải Thuật Kiểu Viterbi Để Tìm Phân Tích Tốt Nhất
Xem toàn bộ 305 trang tài liệu này.
Giải thuật phân đoạn diễn ngôn [89] cho phép đọc toàn bộ các dấu hiệu diễn ngôn của văn bản, mỗi dấu hiệu tương ứng với một trong 10 hành động NOTHING, NORMAL, NORMAL_THEN_COMMA, COMMA, END, MATCH_PAREN, COMMA_PAREN, MATCH_DASH, SET_AND, SET_OR. Sau đây là mô tả của một số hành động thường gặp nhất:
- Hành động NOTHING ra lệnh cho bộ phân tích xử lý cụm từ gợi ý được xét như là một từ đơn. Điều đó có nghĩa là không có giới hạn đơn vị văn bản nào được xác lập khi một cụm từ gợi ý với những hành động đó được xử lý.
- Hành động NORMAL ra lệnh cho bộ phân tích thêm một giới hạn văn bản ngay trước xuất hiện của dấu hiệu. Các dấu hiệu văn bản tương ứng với biên giới giữa các đơn vị văn bản nguyên tố.
- Hành động COMMA ra lệnh cho bộ phân tích thêm một giới hạn văn bản ngay sau xuất hiện của dấu phảy đầu tiên của xâu vào. Nếu dấu phảy đầu tiên có “và” hoặc “hoặc” đi ngay sau, biên của văn bản được đặt sau xuất hiện của dấu phảy tiếp sau. Nếu không tìm thấy dấu phảy nào trước khi kết thúc câu, một giới hạn văn bản được thiết lập tại điểm cuối của câu.
- Hành động NORMAL_THEN_COMMA ra lệnh cho bộ phân tích thêm một giới hạn văn bản ngay trước xuất hiện của dấu hiệu và một giới hạn văn bản khác ngay sau xuất hiện của dấu phảy đầu tiên trên văn bản vào. Nếu dấu phảy đầu tiên được nối tiếp bởi “và” hoặc “hoặc “, việc xử lý cũng như trong hành động COMMA.
Dựa trên giải thuật của Marcu [89], luận án phân đoạn văn bản tiếng Việt với các hành động: COMMA, NORMAL, NOTHING, NORMAL_THEN_COMMA, END, SET_ AND, SET_OR, MATCH_PAREN, COMMA_PAREN, MATCH_DASH, PH.
Sau khi đã xây dựng được bộ phân tích cú pháp trên văn phạm liên kết cho câu đơn, luận án đã sử dụng công cụ này để giải quyết triệt để hơn vấn đề nhập nhằng với từ “và”.
Bảng 3.5 dưới đây đưa ra một số dấu hiệu diễn ngôn phổ biến trong tiếng Việt và hành động xử lý tương ứng cho dấu hiệu diễn ngôn đó. Trong một số trường hợp, hành động xử lý của dấu hiệu sẽ không được dùng đến khi dấu hiệu được xử lý bởi hành động dấu hiệu diễn ngôn đi trước, chẳng hạn trong câu “Mặc dù nó không có tiền, nó cư tiêu xài hoang phí”, dấu phảy được xử lý bởi hành động COMMA của dấu hiệu “mặc dù”.
Bảng 3.5. Hành động ứng với một số dấu hiệu diễn ngôn
| Dấu hiệu | Vị trí | Hành động |
| mặc dù | B (Đầu câu) | COMMA |
| bởi vì | B | DUAL |
| Nhưng | M (Giữa câu) | NORMAL |
| Và | M | NORMAL_THEN_COMMA |
| Vì | B | DUAL |
| Nên | M | NORMAL |
| Dấu phẩy | M | PH |
| Mở ngoặc | M | MATCH_PAREN |
| Đóng ngoặc | E (Cuối câu) | NOTHING |
| Gạch ngang | B | MATCH_DASH |
| Hết câu | E | NOTHING |
Hành động NORMAL_THEN_COMMA, được liên hệ với từ “và”.Tư tưởng xử lý của luận án khi bộ phân đoạn diễn ngôn gặp từ “và” như sau:
Đọc dấu hiệu tiếp theo. Thêm một giới hạn văn bản sau dấu hiệu tiếp theo. Nếu câu được đọc hết, dấu hiệu biên của văn bản được đặt ở cuối câu. Tiến hành phân tích bằng văn phạm liên kết với cụm từ trước và sau từ “và”.
Nếu cả hai cụm từ nhận được: từ đầu văn bản đang xét đến trước từ “và” và từ đứng sau từ “và” đến trước dấu hệu diễn ngôn tiếp theo đều là các mệnh đề thì từ “và” có vai trò diễn ngôn trong câu. Thêm một giới hạn văn bản sau dấu hiệu “và”.Ngược lại từ “và” là liên từ các thành phần câu nên bỏ qua.
Xử lý của hành động NORMAL_THEN_COMMA, hành động gắn với từ “và” như trong giải thuật được nêu sau này.
Dấu phảy cần xử lý phức tạp hơn.Trong [89], dấu phảy do bộ phân tích diễn ngôn xử lý trong hai hành động COMMA và NORMAL_THEN_COMMA xử lý, các trường hợp khác bị bỏ qua. Nay luận án xử lý thêm một số trường hợp khác. Khi gặp dấu phảy, dù cụm từ đang xét là mệnh đề đúng cú pháp, chưa chắc giới hạn văn bản đã được thêm ngay sau dấu phảy. Cần xem xét xem dấu hiệu ở sau cụm đó có là dấu phảy không. Nếu là dấu phảy thì giới hạn văn bản sẽ được điền sau dấu hiệu đầu tiên khác dấu phảy. Ví dụ trong câu ”tôi mua nhiêu đồ chơi, bánh, kẹo để con tôi tặng các bạn”, giới hạn văn bản phải được thêm vào sau từ “kẹo” thay vì thêm sau từ “đồ chơi”, dù cụm từ “tôi mua nhiều đồ chơi” đã là một mệnh đề hoàn chỉnh. Công việc này được thực hiện bởi hành động PH gắn với dấu phảy.
Dưới đây là toàn bộ giải thuật phân đoạn diễn ngôn. Đầu vào của giải thuật bao gồm câu cần phân tích và mảng các dấu hiệu diễn ngôn trong câu. Đầu ra của giải thuật là câu đưa vào được điền thêm các cặp [] để chỉ giới hạn của mệnh đề. Trong giải thuật này, luận án đã chỉnh sửa hành động NORMAL_THEN_COMMA và thêm hành động PH để xử lý nhập nhằng với “và”, “hoặc” và dấu phảy. Những xử lý khác theo [89].
| Vào: Câu S Mảng của n dấu hiệu diễn ngôn tiềm tàng có thế xuất hiện trong S: marker[n] Ra: Các đơn vị tựa mệnh đề của S Phương pháp: //Những đoạn in nghiêng là xử lý do luận án đề xuất { status := nil; clauses := nil; parentheticals := nil; currClauseStart := 1; currParentStart := 1; for i from 1 to n // Xử lý trường hợp có lưu lại status { if MATCH_PAREN ∈ status if markerTextEqual(i,”)”) { parentheticals:= parentheticals ∪ textFromTo(currParentStart,offset(i)); status := status {MATCH_PAREN}; currParentStart := -1; continue; } if MATCH_DASH ∈ status if makerTextEqual(i,”-”) { parentheticals := parentheticals ∪ textFromTo(currParentstart,offset(i)); status := status {MATCH_DASH}; currParentStart := -1; continue; } if COMMA_PAREN ∈ status if markerTextEqual(i,”,”) && NextAdjacentMarkerisNotAnd()&& NextAdjacentMarkerIsNotOr() { parentheticals := parentheticals ∪ textFromTo(currParentStart,offset(i)); status := status {COMMA_PAREN}; currParentStart := -1; continue; } if COMMA ∈ status^markerTextEqual(i,”,”) ^ NextAdjacentMarkerisNotAnd()^ NextAdjacentMarkerIsNotOr() { clauses := clauses ∪ textFromTo(currClauseStart,offset(i),parentheticals); currClauseStart := i; status := status {COMMA}; parentheticals := nil; currParentStart := -1; continue; } if SET_AND ∈ status if markerAdjacent(i-1,i) ^ currClauseStart < i-1 { clauses:= clauses ∪textFromTo(currClauseStart,offset(i-1),parentheticals); currClauseStart := i-1; setDiscourse(i-1,yes);setDiscourse(i,yes); parentheticals := nil; status := status {SET_AND}; } if SET_OR ∈ status if markerAdjacent(i-1,i) ^ currClauseStart < i-1 { clauses:=clauses ∪textFromTo(currClausesStart,offset(i-1),parentheticals); currClausesStart := i-1; setDiscourse(i-1,yes); setDiscourse(i,yes); parenthethicals := nil; status := status{SET_OR}; } if NORMAL_THEN_COMMA ∈ status if not markerTextEqual(i,”,”) {clauses:=clauses ∪ textFromTo(currClauseStart, offset(i), parentheticals); status:= status{NORMAL_THEN_COMMA} parentheticals := nil; currParentStart := -1;} if PH ∈ status ^ not markerTextEqual(i,”,”) {if not markerTextEqual(i,”và”) if (isClause(textFromTo(offset(i), offset(i+1)) { clauses:=clauses ∪ textFromTo(currClauseStart, offset(i),parentheticals); currClauseStart:=i+1; } else { clauses:=clauses ∪ textFromTo(currClauseStart, offset(i),parentheticals); status:=status{PH}; } } swithch getActionType(i)) case DUAL: if markerAdjcent(i-1,i) { status := status ∪ {DAU_PHAY}; setDiscourse(i-1,yes);setDiscourse(i,yes); } else { clauses := clauses ∪ textFromTo(currClauseStart,offset(i),parentheticals); currClausesStart := offset(i); parentheticals := nil; setDiscourse(i,yes); } case NORMAL: clauses := clauses ∪ textFromTo(currClauseStart, offset(i), parentheticals); currClauseStart := offset(i); parentheticals := nil; setDiscourse(i,yes); case COMMA: if markerAdjacent(i-1.i) {setDiscourse(i-1,yes);setDiscourse(i,yes);status := status ∪ {COMMA};} case NORMAL_THEN_COMMA if isClause(textFromTo(currClauseStart,offset(i))^ isClause(textFromTo(offset(i), offset(i+1)) {clauses:= clauses ∪ textFromTo(currClauseStart,offset(i),parentheticals); status := status ∪ {getActionType(i)}; currClauseStart := offset(i);parentheticals := nil; setDiscourse(i,yes); } case PH: if isClause(textFromTo(currClauseStart, offset(i))^ isClause(textFromTo(offset(i),offset(i+1)) {clauses:= clauses ∪ textFromTo(currClauseStart,offset(i),parentheticals); clauses:= clauses ∪ textFromTo(offset(i)+1,offset(i+1),parentheticals); } else status:= status ∪ {getActionType(i)}; case NOTHING: if signalsRhetoricalRelations(i) setDiscourse(i,yes); case MATCH_PAREN,COMMA_PAREN,MATCH_DASH: status := status ∪ {getActionType(i)}; currParentStart := offset(i); case SET_AND, SET_OR: if status is neither MATCH_PAREN nor MATCH_DASH status := status ∪ {getActionType(i)}; } finishUpParentheticalsAndClauses(); End For |
Hình 3.11. Giải thuật phân đoạn diễn ngôn (có khử nhập nhằng)
Giải thích ý nghĩa các đối tượng dùng trong giải thuật:
- Biến status ghi lại tập hợp những dấu hiệu đã được xử lý từ trước nhưng có thể vẫn còn ảnh hưởng đến việc xác định ranh giới các mệnh đề và những EDU trong dấu ngoặc đơn. Ban đầu, giá trị của biến đặt bằng NIL.
- Biến parentheticals ghi lại tập hợp những đơn vị trong dấu ngoặc đơn gắn liền với một mệnh đề cho trước. Ban đầu, giá trị của biến bằng NIL.
- Biến clauses ghi lại tất cả những EDU trong câu đang xét, trừ những EDU trong ngoặc đơn. Ban đầu, giá trị của biến bằng NIL.
- Biến currParentStart (Điểm bắt đầu ngoặc đơn) ghi lại vị trí của điểm bắt đầu đơn vị trong dấu ngoặc đơn. Ban đầu, giá trị của nó được đặt là -1, nghĩa là chưa có đơn vị trong dẫu ngoặc đơn nào được tìm thấy.
- Biến currClauseStart (Điểm bắt đầu mệnh đề) ghi lại vị trí mà EDU đang xét bắt đầu. Ban đầu, giá trị của nó là 1- vì EDU đầu tiên của câu bắt đầu tại offset 1.
- Hàm dấu hiệu textEqual(i, s) có giá trị true nếu cụm từ dấu hiệu thứ i trong mảng dấu hiệu diến ngôn là s. Ngược lại, hàm có giá trị false.
- Hàm offset(i) trả về vị trí của từ gợi ý thứ i của mảng marker[n] trong câu s.offset phụ thuộc vào tham số “vị trí” của từ gợi ý. Nếu giá trị vị trí là B, hàm trả về giá trị là vị trí cụm từ gợi ý bắt đầu. Nếu giá trị của nó là E, hàm trả về vị trí cụm từ gợi ý kết thúc.
- Hàm textFromTo(i, j) trả về giá trị EDU ở giữa offset i và j trong câu S.
- Hàm textFromTo(i, j, parentheticals) trả về giá trị là đơn vị văn bản ở giữa offset i và j trong câu S có lưu thêm thông tin về những đơn vị trong ngoặc. Tập những đơn vị trong ngoặc được lưu trong biến parentheticals.
- Hàm setDiscourse(i, yes) đặt giá trị cờ có-chức-năng-diễn-ngôn của dấu hiệu diễn ngôn thứ i là “yes”, cho thấy dấu hiệu thứ i có chức năng diễn ngôn.
- Hàm getActionType(i) có giá trị là hành động của dấu hiệu diễn ngôn thứ i trong câu S.
- Hàm signalsRhetoricalRelations(i) (Có dấu hiệu có mối quan hệ diễn ngôn) có giá trị true nếu từ gợi ý thứ i có vai trò diễn ngôn trong câu.
- Hàm finishUpParentheticalsAndClauses() lưu lại những đoạn văn bản chưa xác định được là EDU sau khi xử lý mảng những dấu hiệu diễn ngôn tiềm tàng của câu.
- Hàm isClause(s) do luận án đề xuất sẽ thực hiện phân tích đoạn văn bản đưa vào bằng văn phạm liên kết và trả ra kết quả đúng nếu đoạn văn đúng cú pháp liên kết đồng thời có chứa nòng cốt (chứa ít nhất một trong ba liên kết SV, DT_LA và SA).
| boolean isClause (s) {linkage lnk;int n;connection c; n=NumberOfWord(s) if (PARSE(s,lnk)!=0) //s đúng cú pháp {for(i=1;i<=n;i++) for each c in lnk.linklist(i) {if(c.type=“SV” or c.type=“DT_LA” or c.type=“SA”)//s chứa nòng cốt {return true; break;} } return false; } return false;//s sai cú pháp } |
Hình 3.12. Hàm isClause
Ví dụ: Với câu S là “Trời mưa rất to và gió rất mạnh nên tôi phải nghỉ học, mẹ tôi phải nghỉ làm”, mảng marker[4] có giá trị các phần tử là “và”, “nên”, dấu phảy và kết thúc câu. Từ “và” được gắn với hành động NORMAL_THEN_COMMA. Trong xử lý của giải thuật ở hình 3.11, giá trị hàm isClause với các cụm từ “trời mưa rất to” và “gió rất mạnh” đều là true nên tập mệnh đề Clauses được thêm mệnh đề “trời mưa rất to và” và NORMAL_THEN_COMMA được lưu lại trong status. Khi xử lý đến dấu hiệu “nên” với hành động NORMAL, mệnh đề “gió rất mạnh nên” được thêm vào Clauses, status rỗng. Khi gặp dấu phảy, vì hàm isClause với cụm từ “tôi phải nghỉ học,” và cụm từ sau dấu phảy “mẹ tôi phải nghỉ làm” đều cho giá trị true nên hai mệnh đề này được thêm vào Clauses. Dấu hiệu kết thúc câu ứng với hành động NOTHING nên không thêm mệnh đề mới vào Clauses. Kết quả phân tích diễn ngôn khi thử nghiệm được trình bày trong hình 3.19.