Một số câu có thể không phân tích được đầy đủ, một phần của nó cũng được phân tích. Ví dụ trong hình 3.8. là phân tích cho câu “Mỗi một mùa trắng tay đều khó nuốt trôi”. Câu này là câu bị động nhưng ẩn từ. Những liên kết xây dựng được vẫn được hiển thị dù kết quả là câu sai cú pháp.

Hình 3.8. Kêt quả phân tích liên kết của câu “Mỗi một mùa trắng tay đều khó nuốt trôi”
Để đánh giá kết quả phân tích, khi chưa có bộ ngữ liệu mẫu, 200 câu mẫu được phân tích và chỉnh sửa bằng tay và lưu trữ thành ngân hàng phân tích. Với câu “Phần lớn bọ ngựa ăn côn trùng” và kết quả phân tích trong hình 3.9 dưới đây:
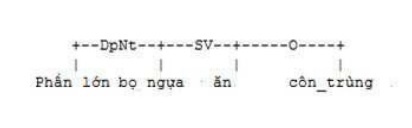
Hình 3.9. Kết quả phân tích liên kết của câu “Phần lớn bọ ngựa ăn côn trùng”
Kết quả phân tích được lưu trữ lại dưới dạng tương tự như trong [94]:
Công việc này đòi hỏi khá nhiều công sức, đặc biệt với những câu trong các bài báo viết, do vậy, luận án mới chỉ tạo lập được bộ ngữ liệu nhỏ. Chi tiết về bộ ngữ liệu như sau:
Bảng 3.1. Chi tiết bộ ngữ liệu mẫu cho bộ phân tích cú pháp liên kết
| STT | Chủ đề | Số câu | Số từ trung bình/câu |
| 1 | Hội thoại tiếng Việt | 50 | 7.6 |
| 2 | Thể thao | 50 | 12.7 |
| 3 | Khoa học thường thức | 50 | 8.7 |
| 4 | Du lịch | 50 | 10.5 |
| Tổng cộng | 200 |
Có thể bạn quan tâm!
-

 Liên Kết Các Mệnh Đề Trong Câu Ghép Đơn Giản
Liên Kết Các Mệnh Đề Trong Câu Ghép Đơn Giản -
 Ứng Dụng Giải Thuật Mở Rộng Từ Điển Tiếng Việt
Ứng Dụng Giải Thuật Mở Rộng Từ Điển Tiếng Việt -
 Kết Quả Thử Nghiệm Phân Tích Câu Đơn Và Câu Ghép Đơn Giản
Kết Quả Thử Nghiệm Phân Tích Câu Đơn Và Câu Ghép Đơn Giản -
 Mô hình văn phạm liên kết tiếng Việt - 17
Mô hình văn phạm liên kết tiếng Việt - 17 -
 Giải Thuật Phân Tích Cú Pháp Câu Ghép
Giải Thuật Phân Tích Cú Pháp Câu Ghép -
 Kết Quả Thử Nghiệm Phân Tích Câu Ghép
Kết Quả Thử Nghiệm Phân Tích Câu Ghép
Xem toàn bộ 305 trang tài liệu này.
Theo [94]. bộ phân tích cú pháp được đánh giá theo các tiêu chí:
Độ phủ (recall) là tỷ số giữa số lượng các thành phần/cấu trúc/quan hệ (chunks/constituents/relations – CCR) do bộ phân tích cú pháp trả ra phù hợp với CCR mẫu và tổng số lượng các CCR trong tập mẫu có chú giải
Độ chính xác (precision) là tỷ lệ giữa số lượng các CCR phù hợp do bộ phân tích cú pháp trả ra và tổng số CCR nhận được từ bộ phân tích cú pháp. CCR ở đây chính là các liên kết. Kết quả đạt được như trong bảng 3.2 dưới đây
Bảng 3.2. Kết quả phân tích liên kết cho các tập mẫu
| Tập mẫu | Độ chính xác | Độ phủ |
| 1 | 45.1% | 25.7% |
| 2 | 28.4% | 15.6% |
| 3 | 33.5% | 18.5% |
| 4 | 30.2% | 20.8% |
| Trung bình | 34.3% | 20.1% |
Trong số các tập mẫu này, tập câu hội thoại đạt được độ chính xác cao nhất vì chứa những mẫu câu cơ bản của tiếng Việt, dễ dàng thỏa mãn các kết nối của cú pháp liên kết. Tập mẫu về khoa học thường thức đạt tỷ lệ cao thứ hai vì nói chung các câu được dịch từ văn bản nước ngoài, cấu trúc câu khá đơn giản. Tập mẫu về du lịch lấy từ một số quảng cáo tour du lịch do người Việt viết nhưng cấu trúc cũng dễ hiểu, dễ phân tích. Trong các tập mẫu, tập mẫu câu thể thao, chủ yếu cũng là dịch từ tiếng Anh, nhưng văn phong khá trúc trắc, nhiều câu có sự hoán đổi thứ tự hoặc thiếu một số bộ phận nên kết quả đạt thấp nhất.
Có thể thấy những dạng câu phân tích không thành công là những câu ghép hoặc những câu đơn có sự thay đổi vị trí các thành phần hay có một số thành phần ẩn.
3.2. Phân tích cú pháp cho câu ghép
Việc phân tích cú pháp câu nhiều nòng cốt phức tạp hơn nhiều so với câu đơn. Với những loại câu gồm hai nòng cốt trở lên, tiếng Anh phân loại theo mối quan hệ giữa hai mệnh đề. Nếu mối quan hệ là song song (dùng các liên từ “and”, “or”, “not only… but also”. . .), câu được gọi là “câu ghép” (compound sentence). Nếu các mối liên hệ có tính chất chính-phụ (dùng các liên từ “if”, “then”, “because”… ), câu được gọi là “câu phức hợp” (complex sentence). Câu ghép phức hợp (complex-compound sentence) phức tạp hơn nhiều khi chứa ít nhất hai mệnh đề song song và ít nhất một mệnh đề phụ. Phân loại câu tiếng Việt có chút khác biệt so với tiếng Anh. Diệp Quang Ban [1] phân biệt câu ghép là câu chứa từ hai nòng cốt trở lên, trong đó không nòng cốt nào bao nòng cốt khác và câu phức chứa hai nòng cốt trở lên nhưng tồn tại một nòng cốt bao các nòng cốt còn lại. Ví dụ, câu “Tôi đang đứng chờ xe thì một cậu bạn chạy đến” được xếp vào loại câu ghép trong khi câu “Con mèo tôi mua chạy mất rồi” được xếp vào loại câu phức. Việc phân định ranh giới mệnh đề trong câu phức có thể đòi hỏi một bộ ngữ liệu lớn với phương pháp học máy nên chưa được đề cập đến trong luận án.
Theo quan điểm của Diệp Quang Ban [1], Nguyễn Chí Hòa [9], Trần Ngọc Thêm [23], mệnh đề là đơn vị nhỏ nhất (nguyên tố) của văn bản, câu ghép được xây dựng nên từ các “khối”, mỗi “khối” là một mệnh đề. Nòng cốt ghép có thể là song song với hai hay nhiều vế, cũng có thể là qua lại (chính phụ) với đúng hai vế [23], [28]. Những kết luận này hoàn toàn phù hợp với lý thuyết cấu trúc diễn ngôn.
Đối với mô hình văn phạm phi ngữ cảnh truyền thống, mệnh đề phụ trong câu ghép có thể được sản sinh từ ký hiệu không kết thúc đặc biệt SBAR của văn phạm. Với một tập luật rất lớn, việc nhập nhằng về giới hạn của mệnh đề rất thường xảy ra. Cũng do tập ký hiệu không kết thúc lớn, cây phân tích cho câu ghép nhiều mệnh đề rất phức tạp. Điều đó sẽ ảnh hưởng đến tốc độ và kết quả của các xử lý khác như phân loại văn bản, tóm tắt văn bản, dịch máy – những bài toán xử lý dựa trên cấu trúc cú pháp của câu.
Các bộ phân tích cú pháp theo mô hình phụ thuộc chia câu ghép, câu phức thành các mệnh đề, phân tích cú pháp riêng từng mệnh đề rồi tìm mối quan hệ phụ thuộc giữa các mệnh đề để đưa ra phân tích tổng thể. Nhiều nghiên cứu về phân tích cú pháp câu ghép, câu phức trên văn phạm phụ thuộc tập trung vào dạng câu ghép, câu phức chính – phụ như của nhóm Ohno [99] , nhóm Utsuro [125] cho tiếng Nhật, Sang Soo Kim [74] cho tiếng Hàn. Quan hệ phụ thuộc giữa mệnh đề chính và mệnh đề phụ được xác định bởi các nhà ngôn ngữ học. Tuy nhiên không phải mô hình văn phạm phụ thuộc nào cũng cho phép thể hiện mối liên hệ giữa các mệnh đề, đặc biệt với câu ghép song song. Nhiều mở rộng của mô hình phụ thuộc đã được xây dựng như trong [65], [75] để biểu diễn cấu trúc của câu nhiều nòng cốt, tuy nhiên những biểu diễn đó trở nên khá phức tạp.
Vấn đề phân tích câu ghép cũng đã được Sleator và Temperley [111] đề cập đến. Điểm đặc biệt của bộ phân tích cú pháp liên kết là có thể phân tích một số dạng câu ghép chính phụ thông qua một số liên kết đặc biệt như CO (liên kết giữa thành phần gợi mở và chủ ngữ của mệnh đề đứng sau), CC (liên kết các mệnh đề với liên từ kết hợp)… được xác lập cho các liên từ như “because”, “although”, “but”… Bộ phân tích cú pháp của luận án (được nói đến ở mục trước) cũng nhận được kết quả tương tự cho tiếng Việt. Tuy nhiên với loại câu ghép có nhiều mệnh đề, quan hệ phức tạp như “Nếu cán bộ, công chức được tuyển dụng lại vào làm việc ở cơ quan, đơn vị cũ, thì thời gian thực tế học tập theo chương trình đào tạo (ghi trên chứng chỉ hoặc bằng đào tạo được cấp) được tính vào thời gian xét nâng bậc lương thường xuyên”, bộ phân tích cú pháp liên kết không thực hiện được. Đó là vì các yêu cầu kết nối không chỉ ra được quan hệ giữa giữa các mệnh đề trong câu. Hơn nữa, việc chỉ sử dụng liên kết đơn thuần của liên từ sẽ đòi hỏi thời gian tính toán rất lớn. Nếu phân tích riêng từng mệnh đề của câu ghép rồi tổ hợp lại thành một phân tích tổng thể, những vấn đề nói trên có thể giải quyết được.
Lý thuyết cấu trúc diễn ngôn (Rhetorical Structure Theory) do Mann và Thompson [86] đưa ra, cho phép biểu diễn mối liên hệ giữa các thành phần trong một văn bản dưới dạng cây với lá là các mệnh đề. Điểm mấu chốt của lý thuyết cấu trúc diễn ngôn là những tiên đề về cấu trúc văn bản được Marcu nêu ra trong [89]:
Mọi văn bản có thể phân chia thành một dãy không giao nhau của các đơn vị văn bản nguyên tố và một cây cấu trúc diễn ngôn được liên hệ với văn bản thỏa mãn các điều kiện sau:
- Tồn tại ánh xạ 1-1 giữa các lá của cây và các đơn vị văn bản nguyên tố
- Cây tuân theo một tập ràng buộc có thể suy ra từ ngữ nghĩa và thực tế sử dụng các đơn vị nguyên tố cũng như các quan hệ giữa các đơn vị đó.Từ các ràng buộc có thể suy ra mối quan hệ diễn ngôn giữa các đơn vị văn bản có kích thước khác nhau.
- Quan hệ được sử dụng để nối các đơn vị văn bản được chia thành hai loại: đẳng lập và phụ thuộc cú pháp.
Nghiên cứu về cấu trúc diễn ngôn của văn bản tiếng Việt cũng được nhiều nhà ngôn ngữ học nổi tiếng quan tâm. Luận án đã sử dụng các kết quả về ngôn ngữ học của Nguyễn Chí Hòa [9], Trần Ngọc Thêm [23] để xây dựng bộ phân tích diễn ngôn cho văn bản tiếng Việt. Với bộ ngữ liệu thử nghiệm gồm 5 bài báo trên các website www.vnn.vn, www.vnexpress.net, www.dantri.com.vn đã được các chuyên gia ngôn ngữ phân tích, độ chính xác đạt được như sau:
Bảng 3.3. Kết quả thử nghiệm bộ phân tích diễn ngôn (chưa kết hợp phân tích cú pháp)
| Văn bản test | Số đoạn | Số câu | Số mệnh đề | Số đơn vị nguyên tố | Số quan hệ | Tỷ lệ % đúng |
| 1 | 11 | 29 | 54 | 46 | 52 | 64.27% |
| 2 | 8 | 21 | 21 | 25 | 37 | 58.43% |
| 3 | 5 | 12 | 30 | 19 | 29 | 62.78% |
| 4 | 10 | 32 | 50 | 37 | 40 | 59.20% |
| 5 | 1 | 3 | 6 | 6 | 15 | 95.09% |