đường dẫn x.dongCo.nhaSanXuat.ten truy xuất giá trị thuộc tính tên của các nhà sản xuất ra động cơ của đối tượng x. Chúng ta có thể tạo ra biểu thức đường dẫn chứa các thuộc tính cũng như phương thức. Tối ưu hóa biểu thức đường dẫn là một bài toán nhận được nhiều chú ý trong lĩnh vực xử lý truy vấn đối tượng.
Biểu thức đường dẫn đưa đến một ký pháp trừu tượng ngắn gọn để biểu diễn hành động duyệt qua các đồ thị hợp phần đối tượng, cho phép định hình các vị từ trên các giá trị được lồng sâu trong cấu trúc một đối tượng. Chúng cung cấp một cơ chế thống nhất cho việc định hình các truy vấn có chứa hợp phần và các hàm thành viên kế thừa. Biểu thức đường dẫn có thể thuộc loại đơn trị hoặc tập các giá trị, và có thể xuất hiện trong truy vấn như thành phần của một vị từ, một đích của một truy vấn, hoặc thành phần của danh sách tham chiếu. Một biểu thức đường dẫn là đơn trị nếu mỗi thành phần của biểu thức đường dẫn đều là đơn trị. Nếu ít nhất một thành phần của biểu thức đường dẫn là tập các giá trị thì toàn bộ biểu thức là tập các giá trị. Kỹ thuật duyệt tới và lui qua biểu thức đường dẫn đã được đề cập trong [31].
Bài toán tối ưu hóa biểu thức đường dẫn trải rộng trong toàn bộ quá trình tối ưu hóa truy vấn. Trong hoặc sau khi phân tích cú pháp cho một truy vấn, nhưng trước khi tối ưu hóa đại số, trình biên dịch phải nhận dạng được những biểu thức đường dẫn có khả năng tối ưu hóa được. Điều này thường đạt được qua các kỹ thuật viết lại (rewriting), biến đổi các biểu thức đường dẫn thành các biểu thức đại số logic tương đương. Khi biểu thức đường dẫn được biểu diễn ở dạng đại số, bộ tối ưu hóa truy vấn sẽ tìm ra phương án có chi phí nhỏ nhất. Cuối cùng, phương thức thực thi tối ưu có thể chứa những thuật toán tính toán các biểu thức đường dẫn một cách hiệu quả, gồm có các nối băm, tổng hợp đối tượng phức, hoặc quét có chỉ mục qua các chỉ mục đường dẫn.
Trước hết xem xét việc viết lại truy vấn và tối ưu hóa đại số. Xét biểu thức đường dẫn x.dongCo.nhaSanXuat.ten. Giả sử rằng mỗi thể hiện của một xe hơi có tham chiếu đến một đối tượng động cơ, mỗi động cơ có một tham chiếu đến đối tượng nhà sản xuất, và mỗi nhà sản xuất có một trường tên. Giả thiết rằng các kiểu DongCo và NhaSanXuat có một dòng tộc kiểu tương ứng. Hai đường nối đầu tiên của đường dẫn ở trên có thể phải truy tìm các đối tượng động cơ và nhà sản xuất
nằm trên đĩa. Đường dẫn thứ ba chỉ gồm một tìm kiếm của một trường bên trong một đối tượng nhà sản xuất. Vì thế chỉ hai đường nối đầu tiên là đưa ra cơ hội tối ưu hóa truy vấn trong việc tính toán đường dẫn đó. Một trình biên dịch truy vấn đối tượng cần một cơ chế để phân biệt những đường nối này trong một đường dẫn biểu diễn các khả năng tối ưu hóa.
Đã có một số nghiên cứu về tối ưu hóa biểu thức đường dẫn trong môi trường tập trung theo hướng tiếp cận heuristic của Ozkan trong [45], viết lại các biểu thức đường dẫn phức tạp về dạng đơn giản trong luận án tiến sĩ của Trương Bảo Châu [2]. Các thuật toán đưa ra trong [52], [34] đều là các thuật toán qui hoạch động. Hạn chế của thuật toán trong [52] là chỉ xét cho từng biểu thức đường dẫn, chưa kết hợp các biểu thức đường dẫn với nhau. Hạn chế của thuật toán trong [34] là chưa có cơ chế lọc trong quá trình truyền dữ liệu và thuật toán sinh đồ thị con chưa tối ưu. Trong phần 3.3 và 3.4 luận án sẽ trình bày các thuật toán tối ưu hóa biểu thức đường dẫn trong CSDL HĐT PT.
3.3. Thuật toán BloomOpt tối ưu hóa truyền dữ liệu trong biểu thức đường dẫn
3.3.1. Giới thiệu
Chi phí truy vấn trong một hệ thống phân tán bao gồm chi phí xử lý cục bộ tại mỗi trạm và chi phí truyền dữ liệu từ xa khi cần, trong đó chi phí truyền dữ liệu thông thường là chi phílớn nhất. Bài toán tối ưu hoá truy vấn phân tán qui về bài toán tối thiểu hóahai chi phí trên. Giảm chi phí xử lí cục bộ tại mỗi trạm chính là bài toán xử lý truy vấn trong mô hình tập trung mà một số nghiên cứu đã thực hiện. Để giảm chi phí truyền dữ liệu cần phải hạn chế tối đa việc truyền các dữ liệu không cần thiết. Có một số thuật toán lọc để hạn chế dữ liệu truyền trong đó có cơ chế lọc của bộ lọc Bloom [16]. Sử dụng bộ lọc Bloom để xử lý truy vấn phân tán trong các hệ thống cơ sở dữ liệu quan hệ đã được đề cập trong các bài báo [35], [46]. Trong phần này luận án đề xuất thuật toán tối ưu hóa truyền dữ liệu giữa các lớp khi xử lý truy vấn biểu thức đường dẫn trong CSDL HĐT PT bằng bộ lọc Bloom để giảm tải việc truyền dữ liệu.
3.3.2. Truy vấn có biểu thức đường dẫn
Các truy vấn trong CSDL hướng đối tượng được biểu diễn bởi ngôn ngữ OQL, là ngôn ngữ mở rộng và kế thừa từ ngôn ngữ SQL. Thiết kế của OQL ở dạng hàm, kết quả của truy vấn có kiểu, điều này cho phép kết quả truy vấn này lại là đầu vào cho một truy vấn khác, vì vậy có thể biểu diễn các truy vấn phức tạp.
Khi thực hiện truy vấn trong CSDL HĐT, nếu các lớp có các thuộc tính phức tạp sẽ dẫn dắt truy vấn tới các đối tượng lồng nhau theo một biểu thức đường dẫn.
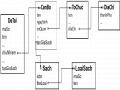
Ví dụ 3.3: Lược đồ cơ sở dữ liệu gồm các lớp: CanBoNghienCuu (Cán bộ nghiên cứu), ToChuc (Tổ chức), DiaChi (Địa chỉ). Lớp CanBoNghienCuu có thuoc tinh coQuan là một tập đối tượng của lớp ToChuc, lớp CoQuan co thuộc tính diaChi là một đối tượng của lớp DiaChi, lớp DiaChi có thuộc tính thanhPho.

Hình 3.3: Minh hoạ các lớp có thuộc tính phức hợp
Giả sử truy vấn ở đây là liệt kê họ tên các cán bộ nghiên cứu trong thành phố Hà nội và có thể viết dưới dạng:
SELECT c.ten
FROM CanBoNghienCuu as c
WHERE c.coQuan.diaChi.thanhPho =”Hà nội”
c.coQuan.diaChi.thanhPho là một biểu thức đường dẫn hay còn gọi là kết nối ẩn. Mỗi đối tượng của lớp có một định danh duy nhất (OID) được hệ thống khởi tạo, các kết nối ẩn được thực hiện thông qua các định danh này. Biểu thức đường dẫn có thể là đơn trị nếu mỗi thành phần của nó đều là đơn trị, ngược lại nếu có ít nhất một thành phần là tập các giá trị thì toàn bộ biểu thức là tập các giá trị. Tối ưu hoá biểu thức đường dẫn là một mục tiêu quan trọng trong xử lý truy vấn CSDL HĐT PT.
3.3.3. Bộ lọc Bloom
3.3.3.1.Cấu trúc bộ lọc Bloom
Bộ lọc Bloom được giới thiệu trong [16], là một cấu trúc dữ liệu xác suất để kiểm tra xem một phần tử có nằm trong một tập hợp hay không. Cấu trúc của một bộ lọc Bloom bao gồm:
- Một dãy gồm n bit, được khởi tạo tất cả các giá trị là 0
- Một tập các hàm băm h1, h2,..hk. Mỗi hàm băm sẽ ánh xạ các giá trị khóa vào một giá trị trong khoảng từ 1 đến n, tương ứng bit của bộ lọc
- Một tập S gồm m giá trị khóa
Với mỗi giá trị khóa k trong S:băm nó theo các hàm băm, hàm băm thứ i có giá trị hi(k), thiết lập bit thứ hi(k) của bộ lọc Bloom thành giá trị 1.
Chứ c năng của bô ̣ loc
Bloom là xác điṇ h môt
phần tử x có thuôc
tâp
S hay
không. Nó đươc dùng là bước tiền xử lý của quá triǹ h tìm kiếm. Nếu sau khi loc
qua bô ̣ loc
Bloom trả về kết quả “không” thì không cần thưc
hiên
viêc
tìm kiếm
nữa, nếu trả về kết quả “có thể có” thì thưc
hiên
tìm kiếm.
Để xác điṇ h môt
phần tử x bất kỳ có thuôc
tâp
S hay không, chúng ta cũng
tính toán k giá tri ̣là h1(x),..., hk(x) từ x qua k hàm băm. Nếu k bit trong vector n- bit tại các vị trí tương ứ ng là h1(x), h2(x),…, hk(x) đều có giá trị là 1 thì x “có thể”
có trong tâp S vớ i một xác suất nào đó, còn nếu chỉ cần it́ nhất 1 bit có giá trị là 0
thì khẳng điṇ h là x không thuôc
tâp
S. Chúng ta chỉ có thể khẳng điṇ h là x “co
thể” thuôc
tâp
S là bở i vì trong vector bit, 1 bit có thể đươc
gán giá trị là 1 nhiều
lần bởi nhiều phần tử trong S khi khở i tao
bô ̣ loc. Chỉ cần môt
bit 0 chúng ta co
thể khẳng điṇ h x không thuôc
S bởi vì nếu x thuôc
S thì tất cả k bit tương ứng se
đươc
gán là 1 khi khởi tao Ví dụ 3.4:
bô ̣loc
với phần tử x đó.
Bộ lọc Bloom gồm 9 bit, ban đầu gán giá trị tất cả các bit bằng 0.
Sử dụng hai hàm băm: Hàm thứ nhất h1(k) lấy các giá trị tại các vị trí lẻ (tính từ trái sang) của k khi biểu diễn sang hệ nhị phân, chuyển về giá trị
thập phân rồi chia dư cho 9. Hàm h2(k) tương tự nhưng lấy giá trị tại các vị trí chẵn.
S = {23, 147, 352}
Quá trình xây dựng bộ lọc Bloom được minh hoạ như Bảng 3.2
Bảng 3.2: Minh hoạ xây dựng bộ lọc Bloom
Biểu diễn nhị phân của k | h1(k) | h2(k) | Bộ lọc Bloom | |
Khởi tạo | 000000000 | |||
k = 23 | 10111 | 7 | 1 | 010000010 |
k = 147 | 10010011 | 0 (9 mod 9) | 5 | 110001010 |
k = 352 | 101100000 | 6 (24 mod 9) | 4 | 110011110 |
Có thể bạn quan tâm!
-
 Phương Án Phân Mảnh Và Cấp Phát Sinh Ra Bởi Thuật Toán Fragallos
Phương Án Phân Mảnh Và Cấp Phát Sinh Ra Bởi Thuật Toán Fragallos -
 Tối Ưu Hóa Biểu Thức Đường Dẫn Trong Cơ Sở Dữ Liệu Hướng Đối Tượng Phân Tán
Tối Ưu Hóa Biểu Thức Đường Dẫn Trong Cơ Sở Dữ Liệu Hướng Đối Tượng Phân Tán -
 Xử Lý Truy Vấn Đối Tượng Phân Tán
Xử Lý Truy Vấn Đối Tượng Phân Tán -
 Tối Ưu Hóa Biểu Thức Đường Dẫn – Thuật Toán Pathexpopt
Tối Ưu Hóa Biểu Thức Đường Dẫn – Thuật Toán Pathexpopt -
 Đánh Giá Độ Phức Tạp Và Cài Đặt Thuật Toán
Đánh Giá Độ Phức Tạp Và Cài Đặt Thuật Toán -
 Xử lý và tối ưu hóa truy vấn trong cơ sở dữ liệu hướng đối tượng phân tán - 16
Xử lý và tối ưu hóa truy vấn trong cơ sở dữ liệu hướng đối tượng phân tán - 16
Xem toàn bộ 136 trang tài liệu này.

Nếu x = 15, biểu diễn x nhị phân là 1111, h1(x) = h2(x) =3. Tại bit số 3 của bộ lọc Bloom giá trị là 0 nên x chắc chắn không thuộc S.
3.3.3.2. Phân tích sai số
Với một bộ lọc có thể xảy ra hai lỗi sau:
Lỗi dương tính (false positive): Kiểm tra qua bộ lọc là có nhưng tìm kiếm thực thì lại không có
Lỗi âm tính(false negative): Kiểm tra qua bộ lọc là không có nhưng tìm kiếm thực thì lại có
Với bộ lọc Bloom sẽ không có khả năng xảy ra lỗi false negative mà chỉ có thể gặp phải lỗi false positive với xác suất rất nhỏ. Xác suất gặp phải lỗi false positive phụ thuộc vào mật độ các bit có giá trị 1 và số các hàm băm.
Xác suất để một bit ngẫu nhiên của mảng n bit được gán giá trị 1 bởi hàm
băm là 1/n, xác suất để bit đó không được gán giá trị 1 là (1 −
1). Xác suất để bit
đó không được gán giá trị 1 bởi bất kì hàm băm nào là (1 −
n
1)𝑘 trong đó k là số
𝑛
các hàm băm. Với m giá trị khóa xác suất để bit đó vẫn có giá trị 0 là
(1 −
1)mk,
n
và xác suất để bit đó được thiết lập thành 1 là (1 − (1 − 1)mk).
n
Xét quá trình kiểm tra một phần tử có nằm trong một tập hợp hay không. Thuật toán kiểm tra k vị trí trong mảng xem chúng có bằng 1 hay không, xác suất
]mk k −km/n k
tất cả chúng đều bằng 1 là (1 − [1 −1) ≈ (1 − e ) với n rất lớn. Xác
n
suất này không phụ thuộc vào phần tử được kiểm tra nên được gọi là xác suất false positive. Xác xuất false positive có thể giảm xuống nếu chọn giá trị n, k, và m thích hợp. Giá trị n cần phải khá lớn so với m, xác xuất này còn có thể giảm nếu tăng số
hàm băm. Trong trường hợp tốt nhất, giá trị k tối ưu là k = n ln2, khi đó xác suất
m
false positive được cực tiểu hóa theo k và sẽ là p = 2−k = 2−nln2/m =>n =
− mlnp . Nghĩa là để xác suất false positive là hằng số cố định, kích thước của
(ln2)2
mảng là tuyến tính với số phần tử của tập hợp.
3.3.4. Sử dụng bộ lọc Bloom để giảm chi phí giao tiếp
Chúng ta sẽ mô tả thuật toán sử dụng bộ lọc Bloom để xử lý truy vấn có biểu thức đường dẫn giữa hai lớp. Giả sử lớp Ci có một thuộc tính ak là một đối tượng của lớp Cj, lớp Ci đặt tại trạm S, lớp Cj đặt tại trạm R. Dễ nhận thấy rằng kích thước một đối tượng của lớp Cj nhỏ hơn kích thước một đối tượng lớp Ci. Giả sử có truy vấn chứa biểu thức đường dẫn từ lớp Ci sang lớp Cj. Gọi chi phí truyền một đơn vị dữ liệu từ trạm S đến trạm R là transCost(S, R), giả sử chi phí truyền này có tính đối xứng, nghĩa là transCost (S, R) = transCost (R, S).
Ý tưởng chính ở đây là thay vì truyền toàn bộ các đối tượng của Cj từ R đến S đề kết hợp với Ci (hoặc ngược lại), chúng ta sẽ lọc một số đối tượng của Cj mà cần thiết cho việc kết nối với Ci. Như vậy khối lượng dữ liệu được truyền đi sẽ giảm đáng kể và đồng nghĩa với chi phí truyền dữ liệu sẽ giảm. Cơ chế lọc sẽ được thực hiện bởi bộ lọc Bloom. Có ba trường hợp xảy ra: (1) Truy vấn xảy ra tại trạm S (là trạm chứa Ci). (2) Truy vấn xảy ra tại trạm R (là trạm chứa Cj). (3) Truy vấn xảy ra tại một trạm khác cả S và R. Chúng ta sẽ xét lần lượt từng trường hợp.
Trường hợp 1: Truy vấn tại trạm S
- Xây dựng bộ lọc Bloom cho tất cả các đối tượng thuộc lớp Ci theo giá trị thuộc tính ak, gọi là BF(Ci).
- Gửi BF(Ci) đến R (trạm chứa Cj), BF(Ci) được sử dụng để lọc các đối tượng của Cj.
- Gửi các đối tượng của Cj mà thỏa mãn điều kiện lọc ở trên đến S
- Thực hiện việc truy vấn từ các đối tượng của Ci và Cj tại S
Thuật toán 3.1 - Case1(Ci, Cj, R, S)
Đầu vào:
- Lớp Ci ở trạm R và lớp Cj ở trạm S
- Thuộc tính ak lớp Ci là một đối tượng của lớp Cj
Đầu ra:
- result là kết quả của phép nối Ci và lớp Cj tại trạm S
Các bước thực hiện:
BF(Ci) = createBloomFilter(Ci,ak); send(BF(Ci),S, R);
tempClass = filter(Cj, BF(Ci)); send(tempClass, R, S);
result = join(Ci, tempClass); end; {Thuật toán 3.1}
Trường hợp 2: Truy vấn tại trạm R
Xây dựng bộ lọc Bloom cho tất cả các đối tượng thuộc lớp Cj theo giá trị thuộc tính định danh, gọi là BF(Cj).
Gửi BF(Cj) đến S (trạm chứa Ci), BF(Cj) được sử dụng để lọc các đối tượng của Ci.
Gửi các đối tượng của Ci mà thỏa mãn điều kiện lọc ở trên đến R
Thực hiện việc truy vấn từ các đối tượng của Ci và Cj tại R
Thuật toán 3.2 – Case2(Ci, Cj, R, S)
Đầu vào:
- Lớp Ci ở trạm R và lớp Cj ở trạm S
Đầu ra:
- result là kết quả của phép nối Ci và lớp Cj tại trạm R
Các bước thực hiện:
BF(Cj)= createBloomFilter(Ci, oid(Cj)); send(BF(Cj), R, S);
tempClass = filter(Ci, BF(Ci)); send(tempClass, S, R);
result = join(tempClass, Cj); end; {Thuật toán 3.2}
Trường hợp 3: Truy vấn tại trạm không chứa cả Ci và Cj, giả sử là trạm P (P ≠ S, P ≠ R)
So sánh chi phí để truyền một đơn vị dữ liệu trong 3 trường hợp:
o (a) transCost (S, R) + transCost (R, P)
o (b) transCost (R, S) + transCost (S, P)
o (c) transCost (S, P) + transCost (R, P)
Nếu chi phí nhỏ nhất là trường hợp (a), thực hiện các bước như trường hợp 1, sau đó truyền kết quả tử S đến P.
Nếu chi phí nhỏ nhất là trường hợp (b), thực hiện các bước như trường hợp 2, sau đó truyền kết quả tử R đến P
Nếu chi phí nhỏ nhất là trường hợp (c)
o Nếu transCost (S, P) <= transCost (R, P)
Xây dựng bộ lọc Bloom cho tất cả các đối tượng thuộc lớp Ci
theo giá trị thuộc tính ak, gọi là BF(Ci).
Gửi BF(Ci) đến P, rồi từ P gửi tiếp BF(Ci) đến R. BF(Ci) được sử dụng để lọc các đối tượng của Cj.